【论文解读】GPT-4-LLM,微软发布基于GPT-4生成的指令数据,基于此训练了LLaMA和奖励模型,并进行了全面评估

【论文解读】GPT-4-LLM,微软发布基于GPT-4生成的指令数据,基于此训练了LLaMA和奖励模型,并进行了全面评估

唐国梁Tommy
发布于 2023-09-01 09:53:38
发布于 2023-09-01 09:53:38

注:本图由stable diffusion生成
# ① 论文链接
https://arxiv.org/pdf/2304.03277.pdf
# ② github
https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM1.1 摘要
在本文中,我们首次尝试使用 GPT-4 生成用于 LLM 微调的指令跟随数据。我们对指令调优的 LLaMA 模型的早期实验表明,由 GPT-4 生成的 52K 英语和中文指令跟随(instruction following)数据在新任务上的零样本性能优于由先前最先进模型生成的指令跟随数据。我们还从 GPT-4 收集反馈和比较数据,以便进行全面评估和奖励模型训练。
1.2 引言
我们的论文作出了以下贡献:
① GPT-4 数据
我们发布了由 GPT-4 生成的数据,包括 52K 的英语和中文指令跟随数据集,以及 GPT-4 生成的评价三种指令调优模型输出的反馈数据。
② 模型和评价
基于 GPT-4 生成的数据,我们开发了指令调优的LLaMA 模型和奖励模型。为了评估指令调优LLM的质量,我们在测试样本(即未见过的指令)上使用三种指标进行评估:对三个对齐标准的人类评估,使用GPT-4反馈的自动评估,以及在非自然指令(unnatural instruction)上的ROUGE-L。
1.3 数据集
1.3.1 数据收集
① 重复使用在Alpaca数据集中收集的52K独特指令。
② 使用GPT-4生成以下四个数据集:
(1) 英语指令执行数据:对于在 Alpaca 中收集的52K指令,为每个指令提供一个GPT-4的英文答案。
(2) 中文指令执行数据:我们使用ChatGPT将52K指令翻译成中文,并要求GPT-4用中文回答它们。这使我们能够基于LLaMA构建一个中文指令执行模型,并研究指令调优的跨语言泛化能力。
(3) 比较数据:我们让GPT-4对自己的回应打1到10的分。此外,我们让GPT-4比较并评价来自三个模型,包括GPT-4、GPT-3.5和OPT-IML(Iyer等人,2022)的回应。这被用于训练奖励模型。
(4) 对非自然指令(unnatural instructions)的回答:GPT-4的回答是根据68K指令输入输出三元组的核心数据集(Honovich等人,2022)解码的。该子集被用来量化GPT-4与我们的指令调优模型在大规模上的差距。
1.3.2 数据统计
png-01
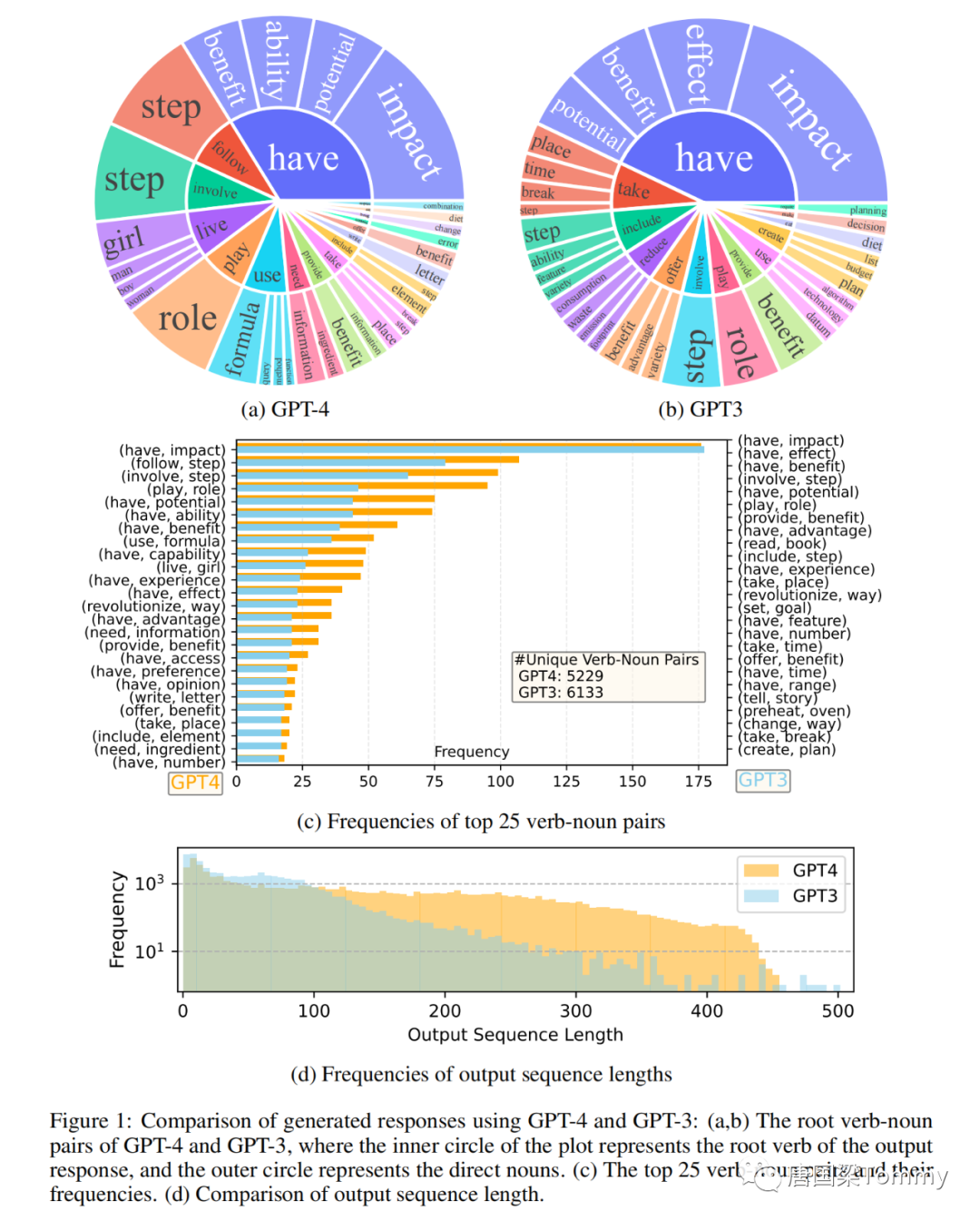
1.4 指令调优语言模型
1.4.1 self-instruct调优(self-instruct tuning)
我们使用LLaMA 7B模型进行有监督的微调训练两个模型:
(i) LLaMA-GPT4 在GPT-4生成的52K英语指令执行数据上进行训练
(ii) LLaMA-GPT4-CN 在GPT-4的52K中文指令执行数据上进行训练。
1.4.2 奖励模型
① 人类反馈的强化学习(RLHF)旨在将LLM的行为与人类的偏好相对齐,以使其更有用。
② RLHF的一个关键组成部分是奖励建模,其中问题被制定为一个回归任务,以预测给定提示和一个回应的标量奖励(scalar reward)。
1.5 实验结果
1.5.1 基准测试
• 用户导向指令(user-oriented-instructions-252)是一个手工策划的包含252个指令的集合,受到了Grammarly、StackOverflow、Overleaf等71种用户导向应用的启发,而不是被广泛研究的NLP任务。
https://github.com/yizhongw/self-instruct/blob/main/human_eval/user_oriented_instructions.jsonl• Vicuna指令(vicuna-instructions-80)是由gpt-4合成的一个数据集,包含80个对基线模型具有挑战性的问题。除了通用指令,还有8个类别,包括知识、数学、费米问题、反事实、角色扮演、通用、编码、写作、常识。
https://github.com/lm-sys/FastChat/blob/main/fastchat/eval/table/question.jsonl• 非自然指令(unnatural instructions)是一个由text-davinci-002使用3次in-context-learning从15个手动构造的例子中合成的68,478个样本的数据集。
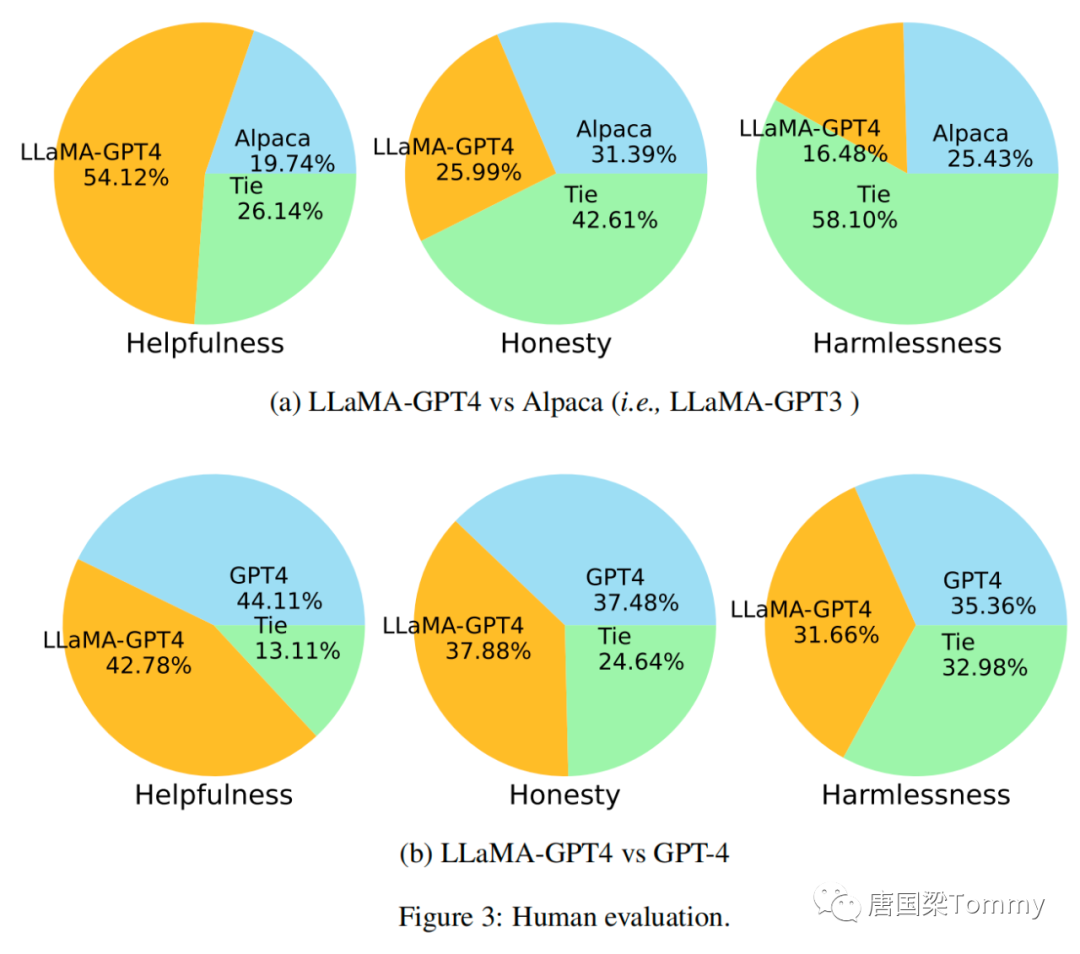
https://github.com/orhonovich/unnatural-instructions1.5.2 以对齐标准进行人类评价
• 有助性 helpfulness:它是否有助于人类实现他们的目标。能准确回答问题的模型是有帮助的。
• 诚实性 honesty :它是否提供真实信息,以及在必要时表达其不确定性,以避免误导人类用户。提供虚假信息的模型是不诚实的。
• 无害性 harmlessness:它是否不会对人类造成伤害。生成仇恨言论或者鼓动暴力的模型是有害的。
png-03
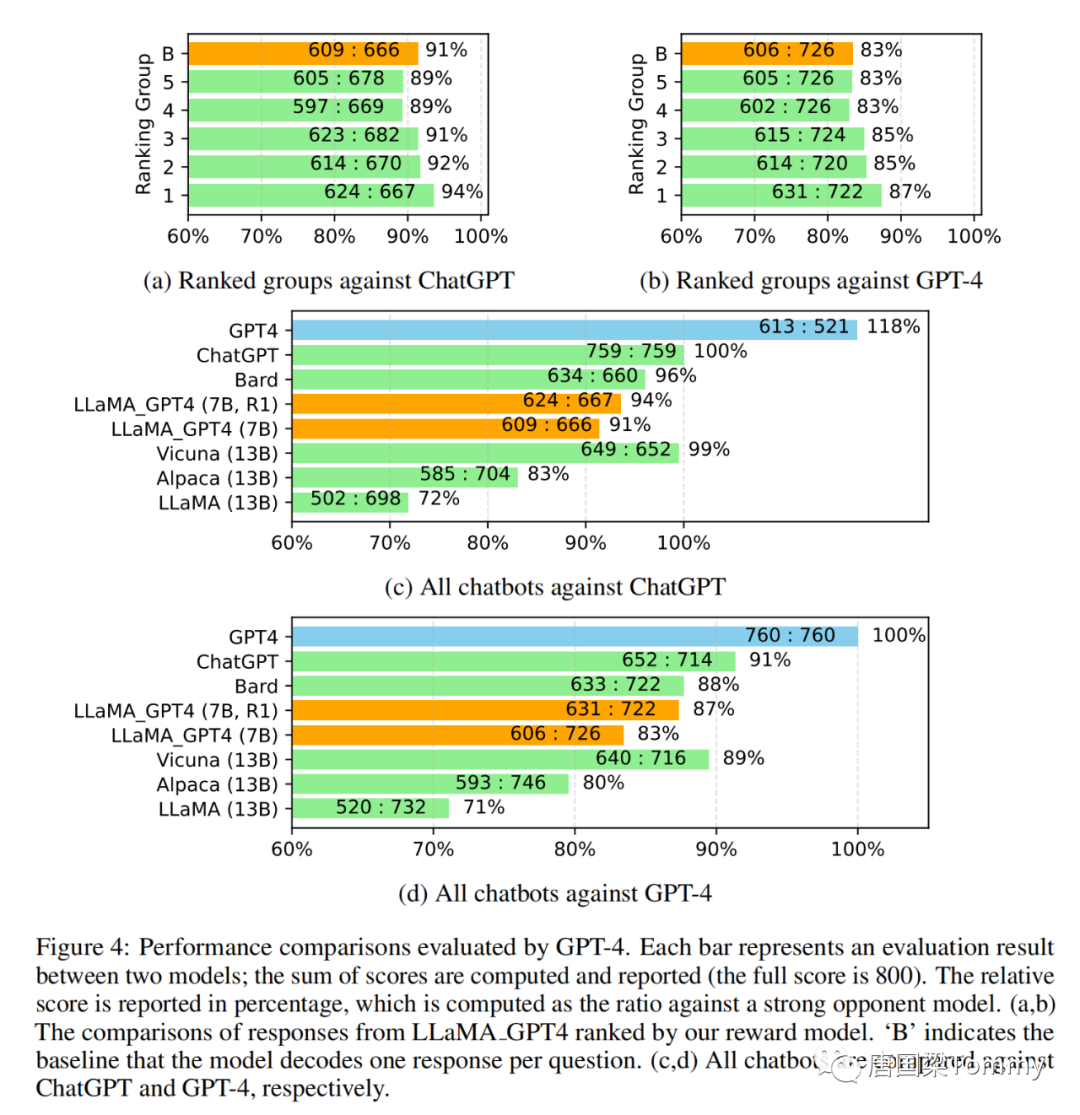
1.5.3 使用自动评估与最新技术进行比较
使用GPT-4进行自动评估。遵循Vicuna的步骤,我们使用GPT-4自动评估不同模型在Vicuna中80个未见过的问题的生成回答。
png-04
png-05
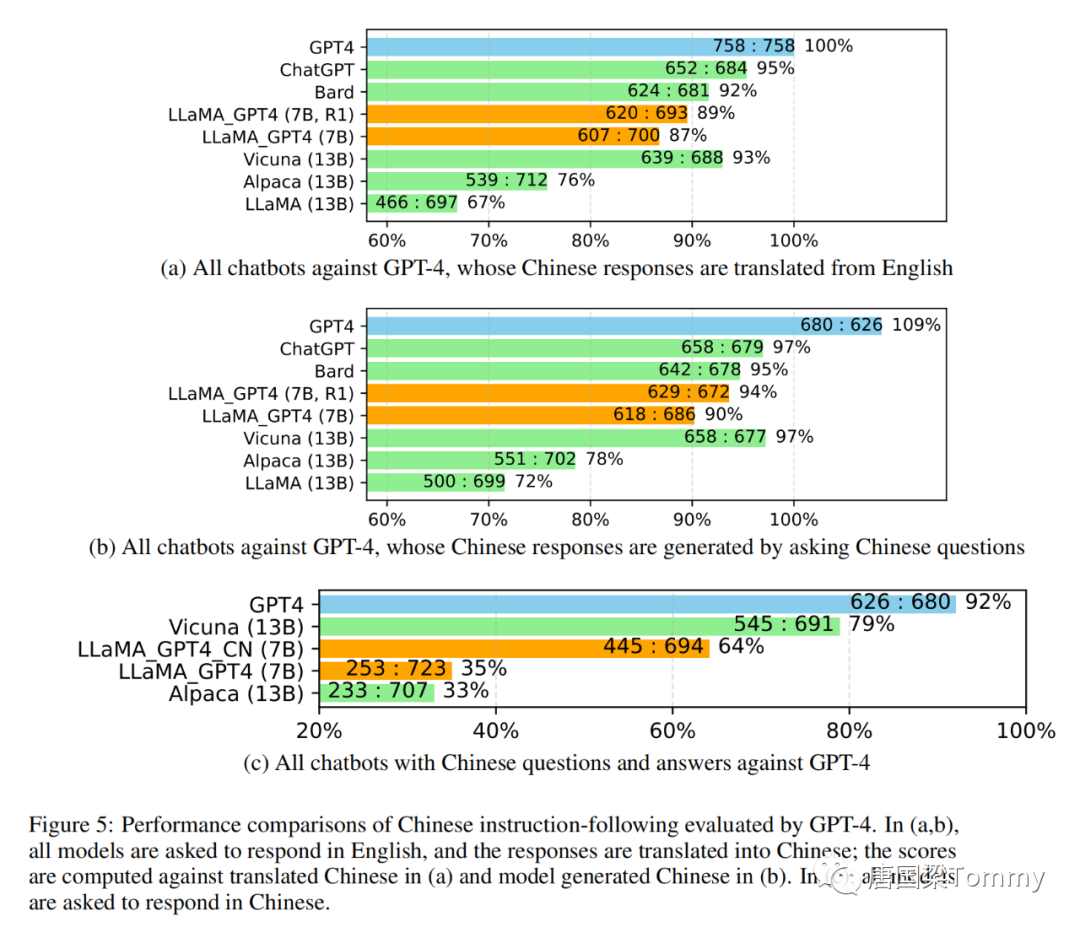
png-06
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-05-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号