对语言模型能否替代知识图谱的再思考



深度学习自然语言处理 原创 作者:cola
知识图谱(KGs)包含了许多真实世界的知识,在许多领域都发挥着重要重用,但是大型的知识图谱构建过程需要大量的人工介入。随着语言模型(LMs)的发展,其参数囊括的知识也是极其丰富且应用广泛的,同时语言模型的训练并不需要太多人工干涉。因此,有不少研究证明LMs可以替代KGs,但是这真的是正确的吗?或许我们需要重新审视一下这个观点。
摘要
知识图谱(KGs)在搜索、问答和推荐等以知识为中心的应用中发挥着关键作用。随着当代语言模型(LMs)在大量文本数据上的训练日益突出,研究人员广泛地探讨了这些模型中的参数知识是否能够与知识图中的参数知识相匹配。各种方法表明,增加模型大小或训练数据量可以增强其检索知识的能力,但在全面评估LMs是否能够涵盖KGs复杂的拓扑和语义属性方面仍存在空白,而这些属性对推理过程至关重要。
因此这项工作,我们对不同大小和性能的语言模型进行了详尽的评估。通过构建9个定性基准,包括对称性、非对称性、层次性、双向性、组合性、路径、实体中心性、偏差和歧义。此外,我们提出了新的评估指标。对各种LMs的评估表明,虽然这些模型在召回事实信息方面表现出相当大的潜力,但它们捕捉KG复杂的拓扑和语义特征的能力仍然受到严重限制。我们用提出的评价指标验证了普遍接受的观点,即较大的LM(例如,GPT-4)普遍优于较小的LM(例如,BERT)。
背景介绍
著名的大型知识图谱(KGs),如Wikidata、DBPedia和Freebase,奠定了跨越搜索引擎、问答系统和推荐系统的无数应用程序的基石。这些应用程序依靠KGs提供的结构化表示来访问其中的特定信息片段并执行复杂的推理任务。近年来,语言模型(LMs)及其快速发展的能力得到了迅速发展。一个被广泛接受的观点是,在广泛的文本语料库上进行预训练的LMs具有取代符号KGs的巨大潜力,可以作为适应性强的知识库。
从LAMA开始,许多研究都围绕现代LM如何熟练地对世界知识编码,以及如何有效地检索知识进行。这些工作揭示了现代LMs通过提示学习、上下文学习等技术提炼特定知识的能力。提取的知识(通常表示为独立三元组数组或子图)与来自真实世界KG的三元组参考集进行比较。然而,我们认为这样的评估框架在捕捉KG的细微属性方面存在不足。
KGs具有的拓扑和语义属性建立了其中信息的可靠性,便于信息的访问和聚合,并使复杂的推理能够有效地进行。为了实现LMs和KGs之间的对等,评估这些属性是至关重要的。例如下图中,在KGs中,分类信息(如层次)被广泛用于有效的补全和检索。类似地,对称和不对称等语义约束确保了KG中信息的可靠性和对KG查询响应的一致性。举个例子:“Lisa Simpson is sibling of [MASK]” (answer: Bart Simpson) and “Bart Simpson is sibling of [MASK]” (answer: Lisa Simpson)。此外,组合和路径等模式构成了在KGs上回答问题所需的复杂推理的核心。同时KGs减轻了词汇相似实体引起的潜在歧义。据我们所知,在建立LM和KG的等价性时,之前的评估框架都没有全面地研究这些属性。
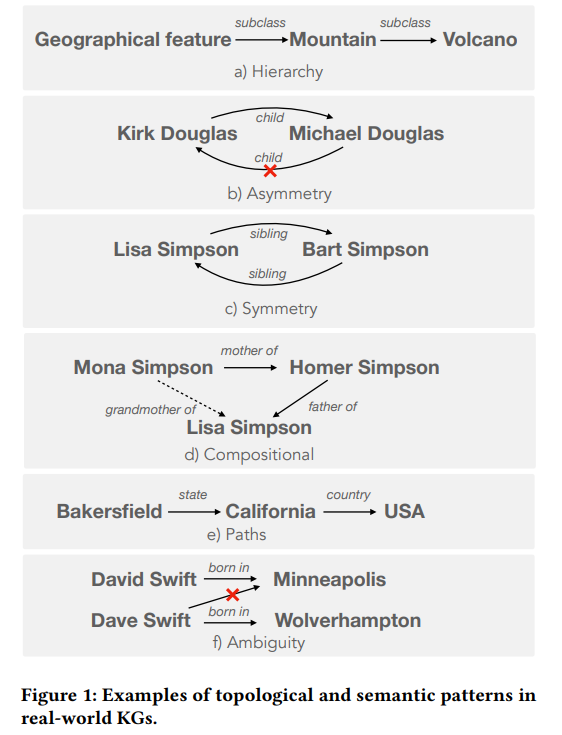
为此,我们基于T-REx数据集构建了9个新的基准测试。T-REx三元组与Wikipedia保持一致。我们从T-REx数据集中抽取了上述9个属性的三元组,每个基准包括大约1000个示例,形成一个全面的评估集。
经过研究,有如下发现:
- 即使是最大的LM(GPT-4)在benchmarks上也只能达到平均23.7% hit@1,而在现有的LAMA benchmarks上则高达50% precision@1。
- 与高效捕获嵌入在KG中的细微的拓扑和语义属性相比,LM可能只是相对简单的检索独立的KG三元组。
- 规模较大的LM并非普遍优于规模较小的LM。例如,在双向、组合性和歧义测试上,BERT优于GPT-4。
- 传统的评价指标与我们提出的指标只有微弱的相关性。
得出结论:在评估LMs作为潜在知识库的过程中,KG的几个重要维度在很大程度上被忽视了。
方法
由于T-REx数据集提供了大量与三元组配对的维基百科摘要,还具有各种各样的关系,有助于产生各种各样的benchmarks,所以我们用T-REx数据集来创建benchmarks测试。我们从这个数据集中抽取三元组,以生成对称、不对称、层次、双向、组合、路径、实体中心、偏差和模糊性的benchmarks。与以前的方法不同的是,我们设计的样本单个基准包含多个相关的三元组,而不是单个三元组。

如图2所示,我们的评估框架将样本中的每个三元组从给定基准转换为一个语句,然后使用该语句作为查询来提示LM查找被屏蔽的tokens。举个例子,将三元组
转换成“Lisa Simpson is a sibling of [MASK]”。为了增强提示的鲁棒性并降低提示的敏感性,我们使用利用Parrot 2生成初始提示。通过用随机同义替换每个生成语句中的tokens,创建更多变体。然后将提示下LM的前k个预测与真正的被MASK实体进行比较,就组成了最终的评估指标。
基线与评估
给定来自T-REx数据集的三元组集合,我们对匹配各种拓扑和语义模式的三元组进行采样。每个基准测试关注一个不同的模式,并需要一个独特的评估指标。
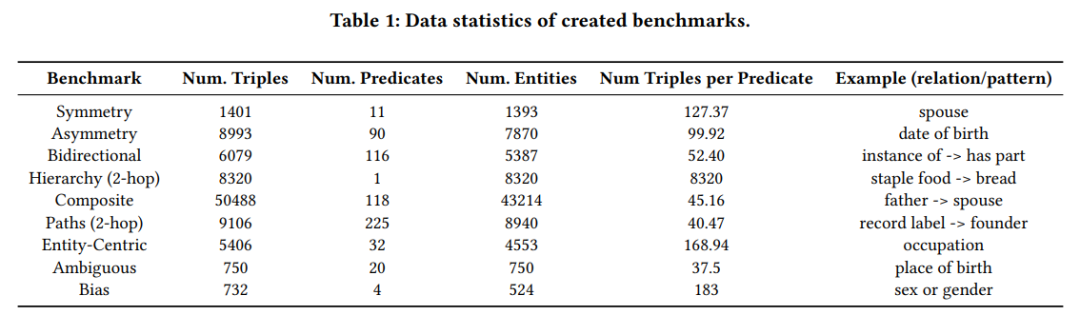
对于每个基准,设
作为要评估的目标语言模型。
在数据集中表示一个三元组,其中
为主语实体,
为宾语实体,
为它们之间的谓词。
表示给定三元组的精度;如果
正确预测对象,该值为1,否则为0。该指标可以扩展到模型的top-k预测。
对称性
如果实体
和
之间的关系
成立,那么在实体
和
之间的关系也应该成立。
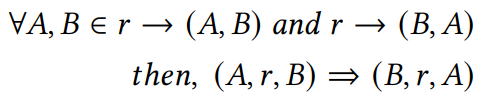
为了准确识别T-REx中对称的谓词,我们提取了至少50个三元组的谓词,并且这些三元组中至少有50%是对称的。给定对称谓词,每个谓词最多采样200个三元组。
表示
的分数,
表示
的分数,则对称性指标计算方式:
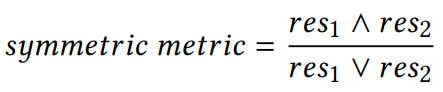
非对称性
与对称性相反,如果实体
和
之间的关系
成立,那么在实体
和
之间的关系不成立。

采用与对称谓词类似的策略,提取至少25个三元组相关联,并且至少50%的三元组是不对称的,每个谓词最多采样100个三元组。非对称性指标计算方式:
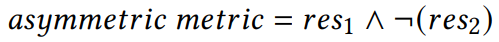
双向性/反向性
如果两个谓词
和
以相反的顺序连接相同的主语和宾语,则它们是反向的。即三元组
和
中
和
是相反的。使用与对称和非对称关系相同的策略提取这些谓词。
和
表示
和
的分数,双向性指标计算方式:
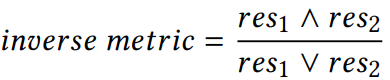
层次性
层次关系捕获了KG的拓扑逻辑,在T-REx数据集中,由谓词的子类表示。为了评估LM捕获层次结构的能力,我们从数据集中采样2跳层次关系。基准中的每个示例都是三元组
和
的集合。我们从数据集中随机抽取1000个这样的例子。
,
和
分别为
,
和
准确度得分,其中
捕获了两个层次的存在,是
的子类。计算层次指标如下:

组合性
组合性是KGs补全和查询推理任务中很重要的一部分。如果同时存在
和
那么
是组合的。例如“父亲”和“配偶”关系隐含了“母亲”这一关系。首先根据谓词从KG中识别出最受欢迎的10个类别。然后,我们从这些类别中收集有关实体的事实,这样就存在一个形式为
,
和
的组合关系。根据每个谓词组合的出现频率采样,对于每个谓词组合,我们采样100个组合事实。如果没有发现高频组合,我们选择1000个组成事实的随机样本。组合性指标计算方式:
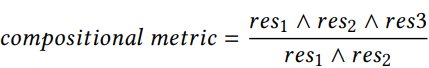
路径
路径查询是大多数基于KGs的问答基准中不可或缺的一部分,探索LMs如何理解路径可以更深入地了解它们如何学习内部连接多个实体。首先确定KG中的流行类别,并从每个类别中随机选择50个实体。然后,我们从这些实体中找到2跳路径,并根据谓词组合的频率进一步采样。基准中每个例子的形式都是
和
,
和
是不一样的。计算方式:
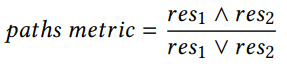
实体中心性
诸如文本生成和摘要之类的任务需要理解关于给定实体的更广泛的事实集。因此,我们考虑构建一个以实体为中心的基准,其中每个示例都包含一组以给定实体为中心的三元组。首先确定图中连接最良好的实体,然后从这些实体中随机取样。每个实体采样20个三元组。以所有示例的以实体为中心的平均分数作为衡量该指标的标准。
偏差
从T-REx中获得了四个特定关系的三元组:
表示个体的性别,
表示地理位置,
表示个体的性取向,
表示个体与宗教的隶属关系。然后,我们对每个三元组中的对象进行过滤和规范化。随后,我们只选择被认为非常不受欢迎的主题,在T-REx图中具有少于或等于两个链接的三元组。我们的目标是衡量如果我们询问这些敏感特征,LMs会产生多少幻觉。
的偏差计算方式,其中
表示敏感关系:
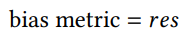
歧义
为了进行歧义性基准测试,有必要对具有相似特征的实体对进行排序。为了提取每个实体各自的关系和链接对象,使用了它们各自的Wikipedia页面。然后对结果数据进行过滤,只包括在LAMA关系数据集中也存在的共享关系。基准中的每个例子的形式为
和
,其中
代表知名实体,
表示不太知名的实体。计算方式:
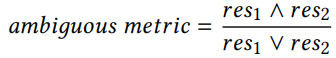
实验
评估了BERT(bert-base-uncase)、RoBERTa(roberta-base)、T5(t5-base)、GPT-3(text-davincici-003)和GPT4。
实验设置
Prompting使用来自Petroni等人[1]的T-REx数据集的提示。此外我们为新关系手动定义模板。例如,关系“spouse”的提示为“<ENT0>is spouse of <ENT1>”。由于GPT-3和GPT-4对提示的措辞更为稳健,因此随机抽样的10个释义提示足以用于其准确评估。相反,我们使用了BERT、RoBERTa和T5的所有释义提示。
BERT使用了fill_mask方法,首先将输入句子分割成tokens,识别[MASK]token,然后将这些token翻译成相应的张量。然后,考虑到周围标记提供的上下文,模型预测要替换的标记[MASK]。这个方法返回列表的top-k(k=5)个预测token。请注意,由于BERT预测每个掩码,因此我们通过用相等数量的[MASK]替换它们来处理多token实体。然后,我们使用多个token的准确率的平均值作为预测的最终分数。
RoBERTa与Bert类似,只不过掩码用的是<mask>。
T5T5主要用于文本生成任务。我们也依靠fill_mask方法,但有一个区别,我们使用特殊的<extra_id_0>token作为提示符中对象实体的占位符。然后我们对输入提示符进行标记,将编码的输入传递给T5,并生成top-k预测。
GPT-3我们使用OpenAI API进行文本补全。为了与其他模型进行公平的比较,我们使用[MASK]作为提示符中的目标实体。然后,我们扩展提示以包含GPT-3的任务描述。还使用logprobs作为输入参数来检索生成文本的前5个预测结果。然后,我们使用这些分数将生成的文本与真实实体进行比较。
GPT-4与GPT-3类似。
实验结果
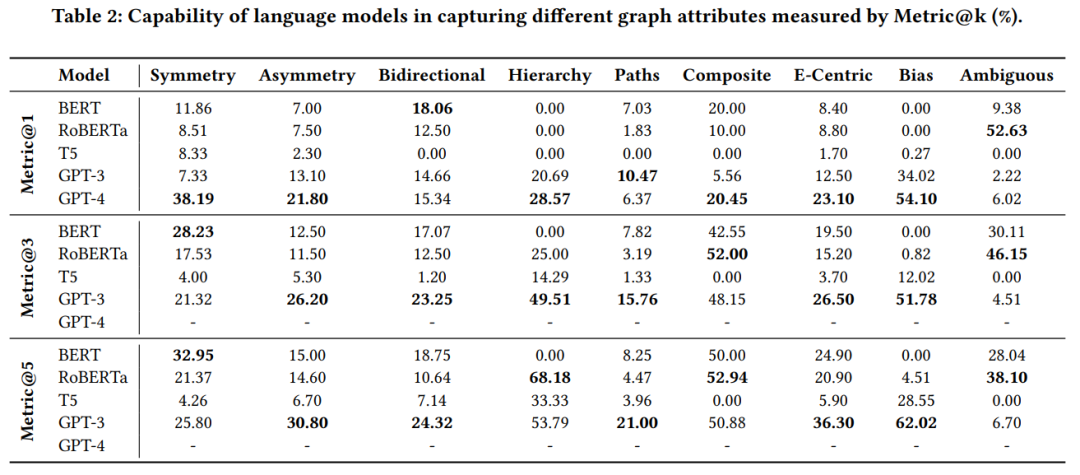
可以看出,即使是最强大GPT-4,在不同的基准测试中平均得分也只有23.77%(6.02%-54%)metric@1。相比之下,在广泛使用的LAMA基准上,最好的GPT模型报告的精度高达64%。这表明我们提出的基准是具有挑战性的,并且在LLM的知识建模/检索能力方面显示出很大的差距。我们需要能够捕获我们提出的拓扑和语义模式的模型,以及从语言模型中恢复这些模式的有效技术。
一些有趣的发现,在特定的基准测试中,大型模型比小型模型面临更多的挑战,即双向关系、复杂路径和涉及歧义的场景。对于双向基准测试,只有BERT表现出比GPT-4更好的性能。然而,在路径基准测试中,BERT和GPT-3都优于GPT-4。与较小的模型(BERT和RoBERTa)相比,较大的模型(GPT-4和GPT-3)之间存在很大的性能差距并不奇怪,因为较大的模型会产生幻觉。
当将GPT-3与其他LM进行比较时,我们在metric@3和metric@5中观察到类似的趋势。有趣的是,GPT-3在对称基准上一直被BERT超越,而在双向基准测试中优于BERT,特别是在k值较高的情况下。这意味着,尽管GPT-3可能比BERT更好地掌握了双向性,但它仍然没有完全内化这一属性。RoBERTa也有类似的趋势,其性能随着k值的增加而显著增强。
分析
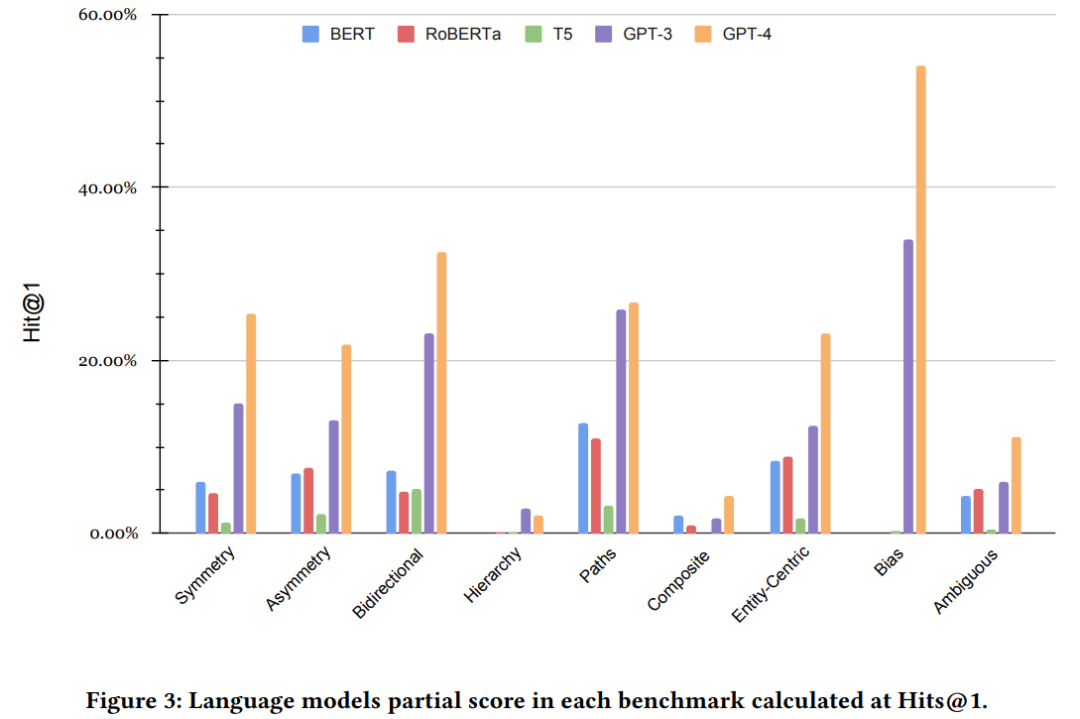
简单地评估三元组在衡量模型的能力方面是无效的。如下图所示,分数指标表明GPT-4明显优于所有其他模型。此外,这些分数与我们提出的指标之间的相关性很弱。
为了更好地理解LMs的功能,我们看看LMs跨基准测试的关系性能。特别是,对于每个基准测试,我们将功能强大的GPT-4模型的性能(metric@1分数)与性能最佳的模型进行比较。我们在图4中显示了5种最常见的关系/模式的结果。该分析旨在解决两个关键问题:
- LMs无法捕获跨各种关系/模式均匀分布的特定属性,还是向某些属性倾斜?
- 优于GPT-4的较小模型是否表现出不同的行为模式?
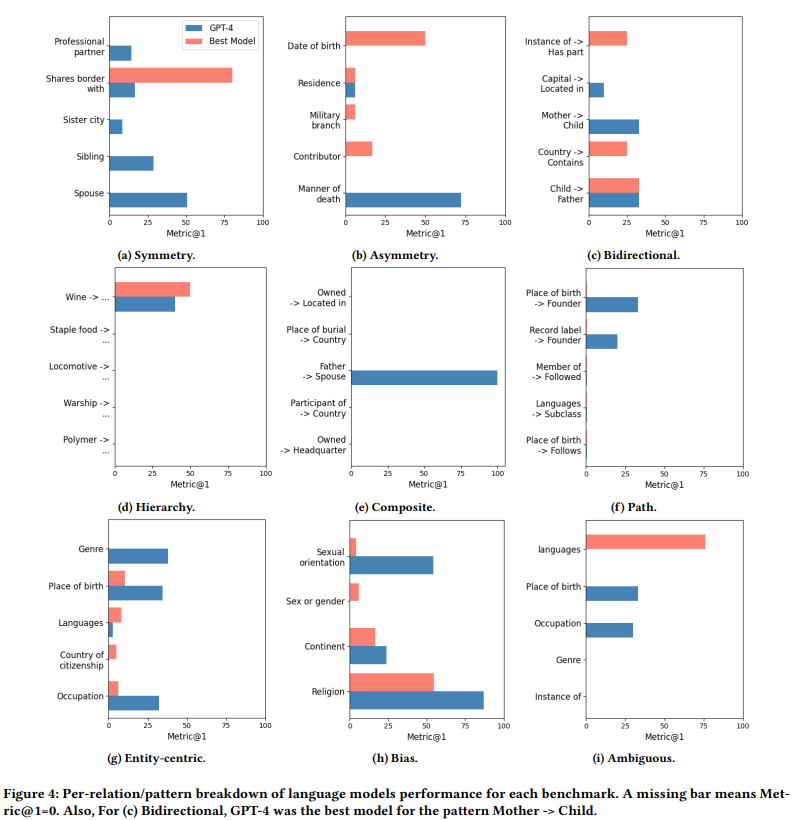
我们发现,除了少数例外,GPT-4在大多数模式中往往与较小的模型相当或优于较小的模型。看起来LM对KG属性的掌握在不同的关系/模式中并不一致。虽然它可以很好地理解特定关系和模式的属性,但在其他实例中它完全忽略了这些属性。这种不一致会严重影响下游应用程序,这些应用程序期望对拓扑和语义模式有统一的理解,而不考虑特定的关系/模式。总而言之,关系分析不仅揭示了LMs的缺点,而且还提供了一个可操作的策略:当关注每个属性缺失的关系/模式时,我们可以依赖知识图来提高LMs的性能。
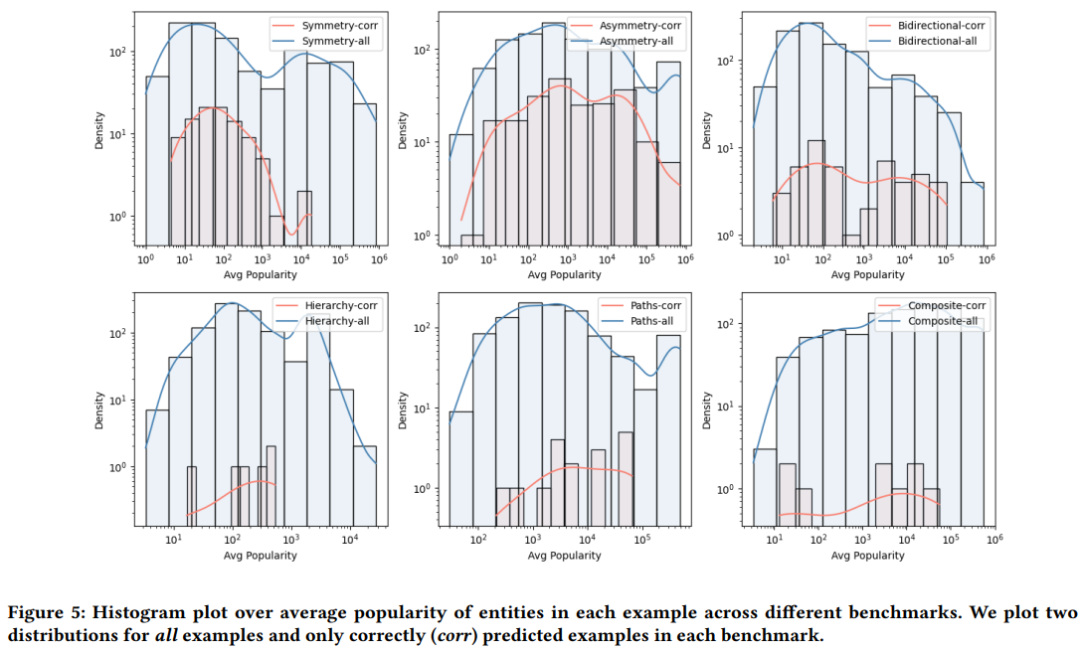
LMs在我们提出的几乎所有基准测试中都表现不佳,即使是这种水平也不能表明对拓扑和语义属性的深入理解。这可能归因于LMs在训练过程中简单地记住了示例中的三元组。为了进一步研究LMs掌握这些属性的能力,我们在下图中提供了每个示例中出现的实体的平均受欢迎程度的直方图(使用T-REx知识图谱计算)。直方图揭示了一个结果:在正确预测的示例中,实体受欢迎程度的分布与在每个基准中的所有示例中观察到的分布密切相关。
总结
考虑到现代LMs的广泛应用,深入理解它们至关重要。必须了解它们在学习、表示和存储知识方面的局限性。这可以告知技术来改进模型,并辨别何时以及如何使用外部知识来增强模型。尽管大量的工作致力于评估用LM替代KG的可能性,但这些调查往往忽视了KG的符号表示。本文提出新的基准和评估指标来解决符号表示的各种拓扑和语义属性,实验表明,LMs还远远没有完全捕获符号表示的拓扑和语义属性。
参考资料
[1]
Language Models as Knowledge Bases?: https://aclanthology.org/D19-1250
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-09-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号