CoMoGAN: continuous model-guided image-to-image translation

CoMoGAN: continuous model-guided image-to-image translation

狼啸风云
发布于 2023-10-17 16:54:04
发布于 2023-10-17 16:54:04
摘要
CoMoGAN是一个依赖于函数流形上目标数据的无监督重组的连续GAN。为此,我们引入了一种新的函数实例归一化层和残差机制,它们将图像内容从目标流形上的位置中分离出来。我们依靠原始的物理模型来指导训练,同时允许私有的模型/翻译功能。CoMoGAN可以与任何GAN主干一起使用,并允许新类型的图像翻译,例如循环图像翻译(如延时生成)或分离线性翻译。在所有数据集上,它都优于文献。
1、介绍
图像到图像(i2i)翻译网络学习域之间的翻译,将从数据集学习的目标外观应用于源图像的上下文。这实现了神经照片编辑等应用,以及面向机器人的任务,如一天中的时间或天气选择、领域自适应等。尽管在非配对、多目标或连续i2i方面取得了令人印象深刻的进步,但仍存在重要的局限性。具体来说,为了学习复杂的连续翻译,现有作品需要对中间领域点进行监督。此外,它们假设域流形的分段线性或整体线性。这样的约束很难满足循环平移(例如白天)或连续平移(例如雾、雨)。
相反,我们引入了CoMoGAN,这是第一个使用无监督目标数据学习非线性连续翻译的i2i框架。它使用简单的物理启发模型进行训练,同时通过域特征的连续解纠缠来放松模型依赖性。一个有趣的结果属性是CoMoGAN发现了目标数据的流形排序,无监督。为了进行评估,我们提出了新的翻译任务,如图1所示。要么是循环的/线性的,要么是附加的/脱离的。我们的贡献是:
•用于连续i2i的新型模型引导设置,
•CoMoGAN:一个无监督的框架,用于使用简单的模型指导来解开生成图像中不断演变的特征,
•一个新的功能实例规范化(FIN)层,
•根据最近的基线和新任务对CoMoGAN的评估,在所有方面都优于文献。

2、相关工作
与早期的i2i不同,[75,70]中的开创性工作实现了不成对的源/目标训练。在此基础上,出现了多模态或多目标i2i。额外的监督也提高了性能。
模型引导翻译
可以利用模型来改进i2i。在[61]中,他们将基于物理的渲染[15]与GANs相结合,以实现可控的雨天翻译。类似地,[46]通过在训练中注射模型来解开闭塞。所有这些都依赖于模型集成,而不是指导。模型可以以输出空间条件[49]、损失函数[25]或特定数据扩充[68]的形式影响许多训练方面。它们已被广泛用于图像恢复[43,28,69],但很少用于GAN图像合成。尽管如此,[23]使用简单的模型来学习基本的图像变换(旋转、亮度等)。
纠缠的表示
解纠缠通常用于通过分离图像内容和样式来获得对生成的控制。其他人的目标是控制输出图像的粒度[56]或特定特征,如模糊或视点。一些人利用解纠缠来实现少镜头泛化能力。领域特征解纠缠也统一了跨领域的表示。虽然有些人根本不使用标签,但他们都没有学习翻译的顺序性。
连续的图像翻译
连续i2i的一种常见做法是通过加权鉴别器、使用中间状态的损失或混合解纠缠样式表示来使用中间域。属性向量插值能够连续控制几个特征。其他人则通过发现的路径不断探索潜在空间。最后,提出了特征[63]或核[64]插值。尽管如此,他们还是假设线性插值——并不总是有效的(例如,从白天到晚上包括黄昏)。GANimation[48]相反,使用非线性插值,但需要中间域标签。
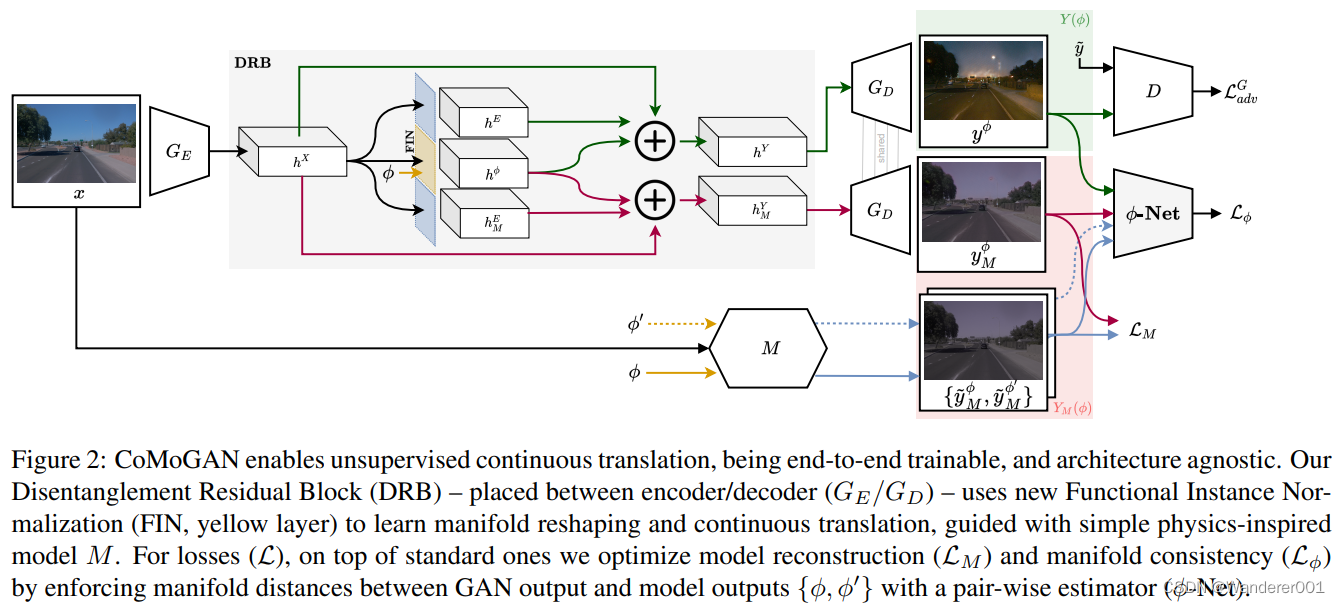
3、CoMoGAN
不是点对点映射
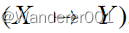
,CoMoGAN学习由
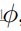
控制的连续域翻译,即
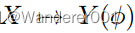
。训练使用源数据(固定
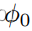
)和无监督目标数据(未知
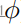
)。它重塑了受天真物理学启发的模型(如色调映射、模糊等)指导的数据流形。我们不是模仿,而是放松模型,让网络通过我们对输出、
和风格的解开来发现私人图像特征。
图2是我们的架构不可知提议的概述。它依赖于三个关键组成部分。我们首先介绍了函数实例规范化层(第3.1节),它可以实现
-流形的重塑。其次,我们的解纠缠残差块(第3.2节)负责输入数据中的
解纠缠。最后,我们详细介绍了
-Net,一个成对的
回归网络(第3.3节),它增强了流形距离的一致性。
模型指导
我们用简单的非神经模型
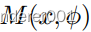
来指导学习,
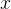
是源图像。因此,根据可以通过粗略引导发现目标流形的直觉:夜晚类似于黑暗的白天,雾看起来像模糊的灰色清晰的图像,等等。我们脱离了复杂物理引导的需要,因为我们将共享和私有特征与模型/转译区分开来,从而能够发现复杂的非建模特征(例如夜间光源)。模型在第4.1节和支持中进行了描述。
3.1、函数化的示例一致性
为了利用我们的模型引导,它本质上是连续的,我们必须允许我们的网络对
连续性进行编码。为此,我们在先前的实例规范化(IN)的基础上进行构建,该规范化允许携带与样式相关的信息。它为输入
写入,
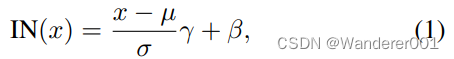
其中,
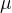
和
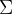
是输入特征统计,
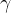
和
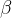
学习了仿射变换的参数。作为扩展,我们提出了功能实例规范化(FIN)
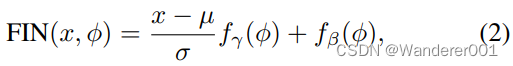
其中,我们学习
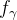
和
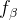
变换的分布,而不是学习一个唯一的
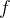
变换参数值。直觉是根据变换的演变来塑造
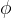
-流形。与其他人相比,这使我们能够更好地解释所学的流形。根据
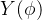
的性质,我们可以对FIN层进行相应的编码。在这项工作中,我们研究了线性和循环编码。通常会遇到线性编码,并假定以线性方式重新组织特征。例如,考虑到不利的天气现象,恶劣的条件(如大雾)总是位于轻度条件(如轻雾)之后。我们将线性FIN参数建模为
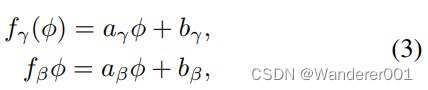
其中
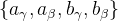
是层可学习的参数。
相反,一些翻译路径循环回到源,就像白天一样,从白天到黄昏7,白天是循环的→ 第7晚→ 黎明又到了。在这种情况下,我们使用参数对循环FIN层进行编码
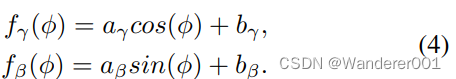
3.2、解纠缠残差块
严格模型依赖性的缺陷在于,GAN只会学习模仿模型。为了防止这种情况,我们必须允许目标域
和模型域
分别具有共享的建模特征
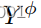
以及私有的非建模特征
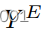
和
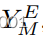
。这写
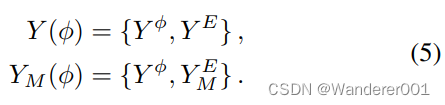
我们用我们的解纠缠残差块(DRB,如图所示)在任一域中启用私有特征。2)其目标是提取给定
的解纠缠表示。DRB由残差块组成,残差块将编码器特征图
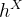
映射到输出图像的解纠缠表示。使
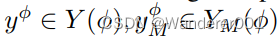
,我们有
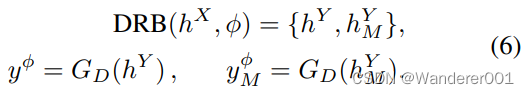
DRB的工作原理如下。如图2所示,输入表示
由残差块处理,每个残差块提取与先前引入的原子特征相关的特征,如

,每个残差一个。特别地,用于
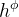
提取的残差块使用我们的FIN层进行归一化,以对连续特征进行编码。隐藏的潜在表示
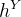
和
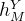
是从解纠缠特征和
的总和中获得的,以简化梯度传播,如[16]所示。在公式中,
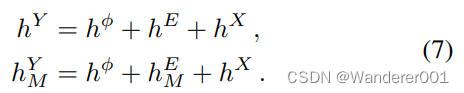
直观地说,为了优化,我们需要来自真实数据相似性和模拟模型输出的反馈。由于使用了不成对的图像,第一种方法必须依赖于对抗性训练,但我们可以在成对建模的
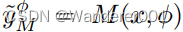
上强制进行重建。假设LSGAN[38]训练和鉴别器D,我们得到
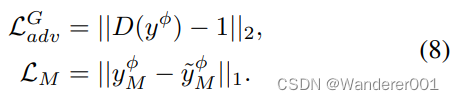
在生成器更新步骤期间,
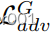
和
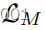
的最小化使得
和
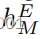
能够解纠缠。
3.3、成对的回归网络(
-Net)
DRB在特征级别上强制解纠缠和流形形状,但它需要特别的训练策略来实际解纠缠真实图像的连续特征,并且不会陷入容易的陷阱,例如网络只利用
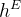
进行目标翻译而忽略
。因此,我们引入了一种基于相似性的训练策略,该策略迫使网络既利用提取的连续信息,又遵循模型指导。假设一个输入图像
,映射到
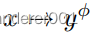
。如图2所示,我们对
和
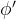
进行随机采样,并将M(.)应用于
,得到偶
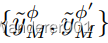
。我们使用CNN(φ-Net)进行领域相似性发现。它将一对图像作为输入,并回归它们的
差,例如
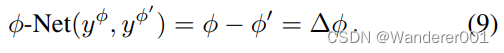
我们通过增强真实和建模目标域图像之间的一致性,在端到端设置中联合优化
-Net和生成器(G)参数。在公式中,
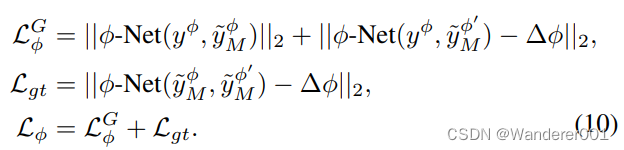
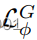
迫使
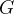
根据物理模型的反馈来组织流形,最终导致生成的
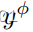
和
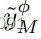
映射到
-Net发现的流形上的同一
。这样,网络可以识别出,尽管模型输出和学习的翻译之间存在差异,但图像遵循一些相似性标准,从而在物理模型的指导下组织潜在空间。
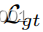
仅利用建模数据,因此用于避免训练崩溃。对于线性FIN,我们在
和
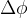
上训练,尽管对于循环FIN,通过评估φ的sin/cos投影上的每个损失来增加稳定性。
3.4、训练策略
CoMoGAN是端到端可训练的,只需在编码器和解码器之间添加DRB,就可以与任何i2i框架一起使用,但我们会损失。生成器的最终目标取决于源和目标是否分离,即
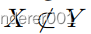
(可视化见图1)。如果已分离,则生成器更新步骤写入
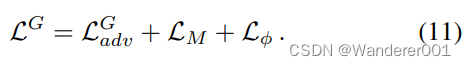
对于附加的源/目标,我们强制执行源(
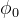
)标识:
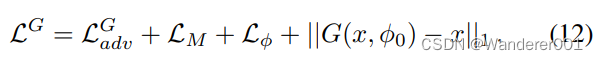
使用任意一种
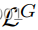
定义,有时与正则化成对损失结合使用,以简化训练(参见supp)。使用来自目标的真实数据
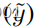
,鉴别器最小化
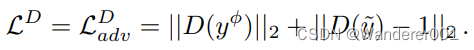
循环一致性
除了
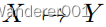
,许多网络执行
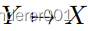
以保持循环一致性的上下文。为了处理后者,我们在每个编码器/解码器之间插入一个共享的DRB,以从多个来源中获益。如图3所示。我们还使用了另一个无监督网络,称为
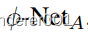
,它在目标数据集上回归
。从上图(左)来看,因为
是在
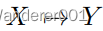
变换中中注入的,我们通过将
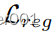
添加到生成器目标来强制所有
值的正确扩展,
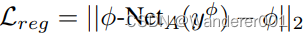
。
4、实验
我们展示了CoMoGAN在新的连续图像到图像翻译任务
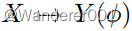
上的效率,其中我们认为源数据位于
-流形的不动点(
)和未知的
目标数据上。潜在的优化挑战是同时学习
流形和连续图像翻译。由于连续模型引导翻译是新的,我们首先描述了通过利用最近的数据集获得的三个新颖的翻译任务(第4.1节)。每项任务都包含其自身的挑战,如线性/循环目标流形、附加/分离流形(即

或
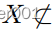
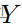
)和单模态/多模态。具体而言,我们使用骨干MUNIT(多模)或CycleGAN(单模)进行训练,并分别铸造我们的替代品CoMo MUNIT和CoMo CycleGAN。我们从GAN度量和代理任务中评估了歧管组织(第4.2节)和翻译质量(第4.3节)。连续平移(第4.4节)单独评估,我们以消融研究(第4.5节)结束。我们主要使用默认骨干超参数进行训练,更多细节在补充中。
4.1、翻译任务
Day→Timelapse.
使用最近的Waymo Open数据集,我们将一天的复杂任务框定为任何时间,从而学习通过白天/黄昏/夜晚/黎明的时间推移。Waymo图像标签仅用于将清晰的图像分割为源{天}和目标{黄昏/黎明,夜晚},分别获得105307/28165和27272/7682图像的序列/val集。我们为多模态训练CoMo MUNIT。为了尊重时间的循环性质,我们利用循环FIN(等式4)编码
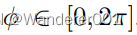
,它映射到太阳高度
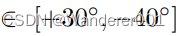
。仅用于评估,我们从带有图像GPS位置和时间戳的天文模型[1]中获得地面实况高程。为了提供指导,我们利用了一个简单的昼夜色调映射(Ω) 使用Hosek辐射模型(HSK)进行插值以解释颜色的逐渐损失,并添加不对称色调校正(corr)以解释温度变化——即在模拟太阳高度,黄昏呈现红色,黎明呈现紫色。完整的模型在补充中。它写道
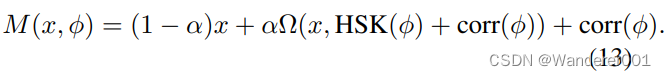
iPhone→DSLR
我们从CycleGAN那里得到启发,将他们的初始任务调整为连续设置,学习将具有大景深的iPhone图像映射到具有浅景深的单反图像。我们还使用iphone2dslr数据集,分为源1182/569和目标3325/480。我们用CoMo CycleGAN训练这个任务进行比较,并使用线性FIN(等式3),其中
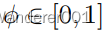
编码级数。
为了指导,我们通过卷积(*)核大小映射到
的高斯(G)来渲染模糊。这就是
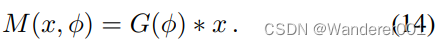

在这里,我们提出了一个分离的源/目标任务,在这个任务中,除了源是合成的,目标是真实的数据之外,我们从清晰到模糊地学习。对于来源,我们利用合成Synthia数据集的春季序列,分为3497/959张图像。作为目标,我们将原始城市景观[10]和4个最大能见度距离为{750米、350米、150米、75米}的雾天城市景观[15]混合在一起。在目标中,5个城市景观版本中的每一个都有2975/500张图像。我们在这里训练具有线性FIN层的CoMo MUNIT(等式3),并将最大可见性编码为
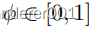
,即可见性
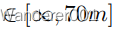
。作为指导,我们简单地利用了[15]的雾模型。出于篇幅考虑,补充部分提供了模型细节、样本输出和模型实验。
4.2、流形组织
我们在第7天使用CoMo MUNIT评估了无监督流形发现的质量→ 时间流逝。图4显示了源日图像(中心)和我们对均匀采样
(中间圆圈)的延时平移。除了吸引人的翻译之外,请注意网络发现的重要特征,如正面太阳(当太阳接近地平线时)、日落/日出、物质反射(夜间)和稳定的夜间外观。所有这些特征都不在模型M(.)中,尽管存在于目标图像(外圈)中。这就提倡网络去纠缠模式特征和翻译特征。还要注意,图4中的顶部翻译准确地类似于源,评估目标是否附着在源上。从数量上讲,我们通过在真实Waymo验证集上用φ-NetA-CNN(参见第3.4节)回归
来测量流形精度,并计算地面实况高程的误差。我们得到19.8的平均误差◦ (标准8.56◦) 在无人监督和4.05◦ (标准4.20◦) 如果受到监督。即使在无监督的情况下,我们的流形发现也是可以接受的,并为无监督的翻译开辟了道路,在这种情况下,
地面真相是不切实际的(例如雨、雪)。
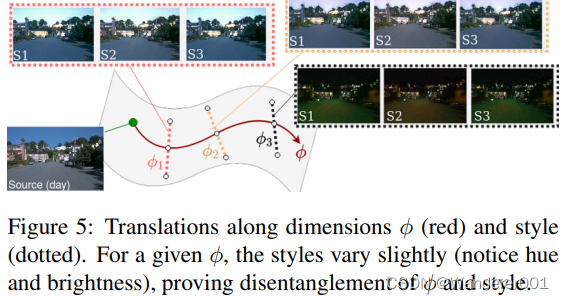
混乱的维度
由于MUNIT在设计上是多模态的,因此评估CoMo MUNIT将
与MUNIT的风格维度正确地分开是很重要的。我们通过采样
和样式来实现这一点。从图5中可以看出,后者在不同的轴上正确地进化,这是预期的,因为
是由模型引导的特征调节的。同样,使用
-NetA,我们回归了100个固定φ翻译的φ值,每个翻译有100种不同的风格,得到1.06◦
——沿样式维度的方差。这证明了
和型流形的正交性。
4.3、翻译质量
我们测量了MUNIT和CycleGAN骨干的所有翻译任务的质量和可变性,如表1所示。我们总是表现得更好或不相上下。在表中,IS[54]评估了所有数据集的图像质量和多样性,CIS评估了多模式翻译,LPIPS仅评估了绝对多样性。我们推测我们的性能结果是我们拥有更高程度的控制,因为我们以解纠缠的方式控制
特征(即极为增加的可变性),而纠缠的主干倾向于最容易的平移。用于IS/CIS评估的InceptionV3网络针对源/目标分类任务进行了培训。IS在所有验证集上进行评估,而对于CIS/LPIPS,我们遵循[21]评估程序。

语义分割
我们衡量Syntheticclear的有效性→ 通过使用MUNIT或CoMoMUNIT输出训练PSPNet-50,实现图6中清晰、模糊的翻译。为了进行比较,我们还使用清晰源Synthia或基于物理的雾模型训练分割作为指导。对于MUNIT和CoMoMUNIT,我们采用了5种固定风格的多模态风格采样策略。此外,对于CoMoMUNIT和允许它的模型翻译,我们对统一
进行了采样。我们遵循设置并训练150个时期,每个设置使用3498个训练图像。表6a报告了Cityscapes(CS,500幅图像)和Foggy Driving[53](FD,101幅图像)验证集真实图像上共享SynthiaCityscapes类的标准mIoU。虽然转换很微妙,但它仍然减少了域偏移,因为即使Model显著优于source,但我们仍以+4.7/+1.6/+3.2的额外优势击败了所有人。值得注意的是,我们改进了清晰(CS)和模糊(FD)数据集,显示CoMo MUNIT保留了准确的清晰和模糊翻译。相反,我们推测MUNIT专注于目标数据集雾强度,这些雾强度是离散的,可能与FD不同,而我们的FIN层能够实现连续表示,从而实现更好的泛化。图中两个数据集的定性评估。6b考虑mIoU性能。
4.4、连续翻译质量
为了评估翻译的连续性,我们展示了第7天的等距
翻译→ 时间推移(图7,底行),合成→ 真实(图8)和iPhone→ 单反(图9)。总之,无论骨干和任务如何,我们的翻译都很有吸引力,因为我们的网络发现了模型指南中没有的独特视觉特征。这在单反相机中非常明显(图9),尽管有简单的模糊引导,但它还是学习了景深,或者在分离雾实验中(图8),因为随着雾的增加,平移包含了所需的真实外观。
4.4.1、基准评估
我们评估具有挑战性的一天→ 随着文学的流逝。这并非微不足道,因为据我们所知,我们的提案是第一个连续循环GAN。虽然以前的一些工作可以适用于循环平移(例如DLOW),但它们都需要中间标记的目标点。因此,为了在Waymo Open中实现补偿数据稀缺性的公平比较,我们将所有基线的时间推移公式化为线性{天,黄昏/黎明,夜晚},并使用循环网络在黄昏或黎明分支之间随机采样。请记住,所有基线都比我们的基线更有监督性,因为它们使用中间黄昏/黎明点,而CoMoGAN则从无监督的目标数据中发现流形。我们现在详细介绍基线。 StarGAN v2是一种最先进的多目标i2i架构,从同一源点学习多重映射。我们在当天对其进行了正式实施培训→黎明/黄昏→Nightpath,并利用其风格代码解纠缠功能实现连续i2i。 DLOW在设计上是连续的。我们用2个单峰DLOW日训练它→ 黎明/黄昏和黎明/黄昏7→ 夜注意,它可以是多目标的,但我们已经与最近的StarGAN v2进行了比较。DNI[64]应用深度网络插值在连续i2i的未调谐网络的核之间进行插值。我们调整了两个基线DNI-CycleGAN和DNI-MUNIT都在第7天训练→ 黎明/黄昏→ 夜。
比较
从图7中可以看出,基线(第1-4行)在插值点(StarGAN v2/DNI)或不切实际的结果(例如,夜间的DLOW)中表现出有限的可变性。一个关键的限制是,他们依赖(分段)线性插值,无法发现夜晚的静止方面(最后3列)。相反,CoMo MUNIT(最下面一行)的翻译在晚上既逼真又静止。我们还使用Frechet Inception Distance[17](FID)来测量生成图像和真实图像之间的特征距离,研究了所有翻译的真实性。为此,我们统一划分高程范围[+30◦, −40◦] 在70个重叠的7个箱中◦ 并且通过比较100个平移和自组织真实图像来计算每个仓FID。我们将其称为“滚动FID”,如图10a所示。
从后者来看,我们的方法优于其他方法,尤其是在复杂的中间条件下。注意精确的“黎明/黄昏”中心的基线性能(监督它们的地方),以及它们的FID在接近夜晚时如何退化(约−18◦). 即使在无监督的情况下,我们较低的FID显示CoMoMUNIT更好地学习了这些复杂的视觉过渡。提出了一种具有代理任务的替代精度评估方法,该方法是一个InceptionV3网络,该网络经过训练,可以从真实图像和
地面实况中回归太阳高程。对于每种方法,我们在100个
位置生成100个图像,并用InceptionV3测量输入
和推理之间的误差。表10b显示,我们以3.96的成绩优于其他方法◦ 由于我们更好的地图绘制。

4.5、消融研究
架构更改
我们通过去除
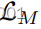
和
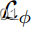
中的任何一个来消融它们的使用。评估一天的多样性→延时翻译,我们对100幅图像的10对随机
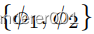
进行采样,并评估翻译对之间的LPIPS距离。我们获得了0.020 w/o LM和0.044 w/o
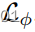
的LPIPS,而使用两者证明是最好的,为0.236。
混乱的重建
当我们解开实域
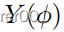
和模型域
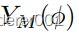
时(参见图2),可操纵GAN[23]直接在
。为了研究其中一个好处,我们将
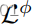
和
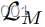
替换为
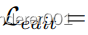
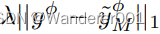
,如[23]所示。图11显示了我们和[23]的离散FID,λ=1.5,根据真实数据(蓝色)或模型翻译(橙色)进行评估。情节复杂但有趣。具体而言,黎明/黄昏时的低FID推断出该模型在那里是可靠的,而夜间的发散FID则意味着相反。当λ=1时,i2i缺乏指导,表现不佳,但更高的λ增加了模型模拟,降低了真实FID。相反,我们的模型是以模型为指导的,但随着独家目标特征的发现,我们学会了偏离模型。
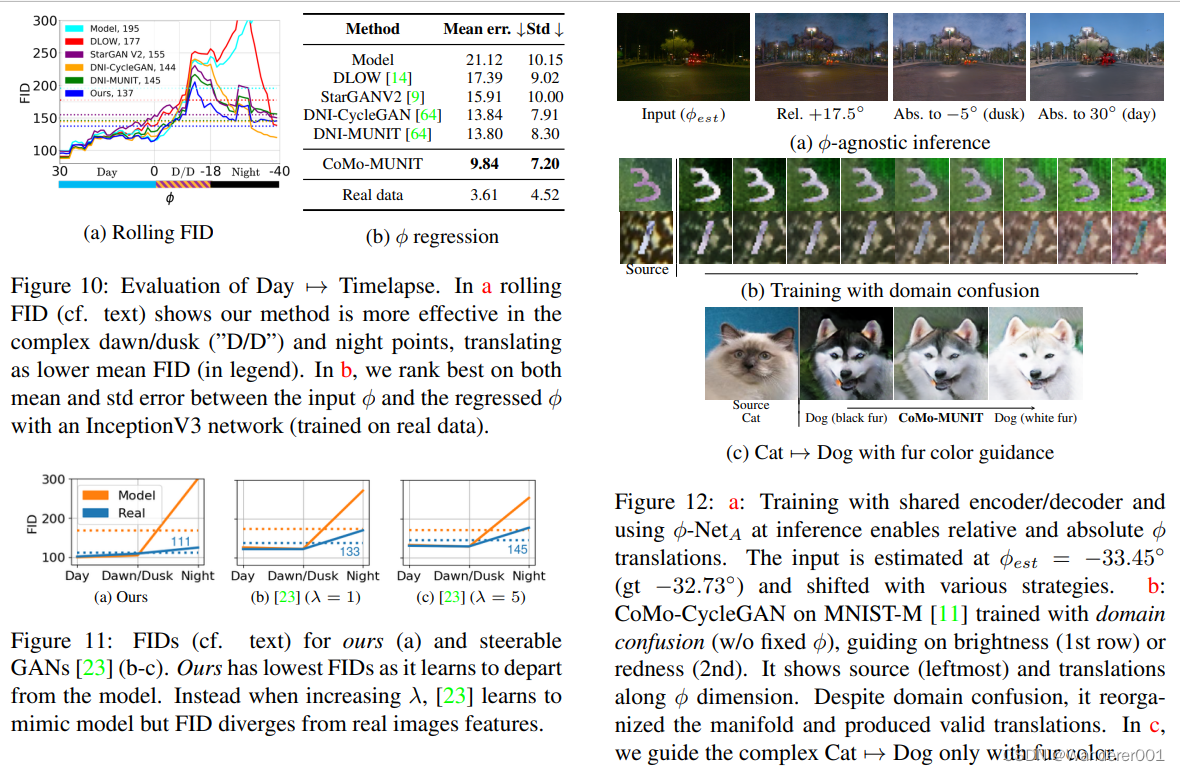
5、讨论
-不可知推理。在所有的实验中,翻译都假定源为
,尽管不可知论推理是有意义的。为了测试这一点,我们用循环一致性和X的共享参数训练了我们的方法X→Y和Y→X个编码器/解码器(参见第3.4节)。在推断时,我们使用
-NetA来估计输入上的
,从而实现了与输入无关的绝对翻译(例如,anytime→daytime),还有相对翻译(例如+5◦). 图12a中的示例结果显示了具有挑战性的夜间输入的令人兴奋的结果。
源/目标域混淆
大多数GAN的一个局限性是需要源/目标分割,而真正无监督的GAN可以从混合的源/目标数据中发现连续流形(即
或域混淆)。有趣的是,如果模型不强制φ输入,则模型引导的GANs允许这样做。虽然没有双边之夜的实体模型↔ 白天或有雾↔ 很明显,我们证明了MNIST-M玩具任务、学习亮度或红色流形的可行性。图12b显示了我们正确地实现了翻译,为真正无监督的GAN铺平了道路。
模型和数据限制
由于缺乏模型,模型引导的GAN不适用于一些复杂的场景(例如面对面),但可以引导肤色等特征,如我们的实验图12c第7类→ 使用毛发颜色指导的狗。与[23]一样,我们也经历了数据稀缺对多方面发现和训练时间的影响,而没有黄昏和黎明的情况下,训练时间会彻底失败。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-10-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号