04-快速入门:利用卷积神经网络识别图片
04-快速入门:利用卷积神经网络识别图片

本文为 PyTorch Computer Vision[1]的学习笔记,对原文进行了翻译和编辑,本系列课程介绍和目录在《使用PyTorch进行深度学习系列》课程介绍[2]。 文章将最先在我的博客[3]发布,其他平台因为限制不能实时修改。 在微信公众号内无法嵌入超链接,可以点击底部阅读原文[4]获得更好的阅读体验。
目录:
计算机视觉(computer vision)应用在哪里?
- 0.PyTorch中的计算机视觉相关库
- 1. 获取数据集
- 查看数据内容和属性
- 可视化数据
- 2. 准备DataLoader
- 3.构建神经网络模型
- 3.1 设置损失、优化器和评估指标
- 3.2 创建训练循环,批量训练模型
- 4. 进行预测并获得 Model 0 结果
- 5. 模型 1:建立更好的非线性模型
- 5.1 评估模型
- 5.2 修复过度拟合
- 6.模型2:构建卷积神经网络(CNN)
- 6.1 卷积层
- 6.2 池化层
- 6.3 为 `model_2` 设置损失函数和优化器
- 6.4 训练和测试 model_2
- 7.比较模型结果和训练时间
- 性能与速度的权衡
- 8. 使用最佳模型进行随机预测并进行评估
- 9. 制作混淆矩阵以进行进一步的预测评估
- 9.1 预测
- 9.2 创建并绘制
- 10.保存并加载最佳性能模型
- 10.1保存模型
- 10.2 加载模型
- 额外资料:
- 感谢
终于到了深度学习最引人注目的部分——图像处理!本章将介绍如何利用深度学习来处理和分类图像。我们将以一个极为有趣的数据集——FashionMNIST[5],作为我们的训练材料。这个数据集包含了各种时尚商品的图像,像裤子、鞋子、T恤等。我们要教会计算机如何区分它们,就像教小朋友认识不同的服装一样!
你可能要训练一个模型来分类照片是猫还是狗(二元分类)、或者一张照片是猫、狗还是鸡(多类分类)。识别汽车出现在视频帧中的位置(对象检测)或者找出图像中不同对象可以分离的位置(全景分割)。

二元分类、多类分类、对象检测和分割的示例计算机视觉问题。
在这个章节中,我们将引入一种非常强大的神经网络结构,名为卷积神经网络(Convolutional Neural Network,简称CNN)。CNN 在视觉领域有着卓越的表现,它能够自动地从图像中提取特征,并进行分类。就像一个火眼金睛的时尚专家,CNN 可以辨认出不同的服装款式和类型。无论是酷炫的鞋子、潮流的裤子还是时髦的T恤,CNN 都能一眼识别出它们。
加载 FashionMNIST 数据集后,我们将使用 CNN 模型进行训练。CNN 通过多层卷积和池化操作,可以捕捉到图像中不同位置的特征,并将它们有效地组合起来进行分类。这就像时尚界的奇幻大变身,将图像中的各种特征进行拼凑,然后告诉计算机这是一条裤子,那是一双鞋子。
计算机视觉(computer vision)应用在哪里?
如果您使用智能手机,那么您就已经使用了计算机视觉。相机和照片应用程序使用计算机视觉来增强和排序图像。现代汽车使用计算机视觉来避开其他汽车并保持在车道线内。制造商使用计算机视觉来识别各种产品中的缺陷。安全摄像头使用计算机视觉来检测潜在的入侵者。本质上,任何可以用视觉描述的东西都可能是潜在的计算机视觉问题。
0.PyTorch中的计算机视觉相关库
PyTorch 模块 | 作用 |
|---|---|
`torchvision`[6] | 包含常用于计算机视觉问题的数据集、模型架构和图像转换。 |
`torchvision.datasets`[7] | 在这里,您将找到许多示例计算机视觉数据集,用于解决图像分类、对象检测、图像描述(image captioning)、视频分类等一系列问题。它还包含一系列用于制作自定义数据集的Python类。[8] |
torchvision.models | 该模块包含在 PyTorch 中实现的性能良好且常用的计算机视觉模型架构,您可以将它们用于解决您自己的问题。 |
`torchvision.transforms`[9] | 在与模型一起使用之前,通常需要对图像进行转换(转换为数字/处理/增强),常见的图像转换可以在此处找到。 |
`torch.utils.data.Dataset`[10] | PyTorch 的基础数据集类。 |
`torch.utils.data.DataLoader`[11] | 在数据集上创建 Python 可迭代对象(使用 torch.utils.data.Dataset 创建)。 |
torch.utils.data.Dataset和torch.utils.data.DataLoader类不仅适用于 PyTorch 中的计算机视觉,它们还能够处理许多不同类型(音频等)的数据。
开始:
# 导入 PyTorch
import torch
from torch import nn
# 导入 torchvision
import torchvision
from torchvision import datasets
from torchvision.transforms import ToTensor
# 导入 matplotlib
import matplotlib.pyplot as plt
# Check versions
# Note: PyTorch >= 1.10.0 and torchvision version >= 0.11
print(f"PyTorch version: {torch.__version__}\ntorchvision version: {torchvision.__version__}")
PyTorch version: 2.0.1+cu118
torchvision version: 0.15.2+cu118
1. 获取数据集
我们将从 FashionMNIST 开始。
原始 MNIST 数据集[12]包含数千个手写数字示例(从 0 到 9),用于构建计算机视觉模型来识别邮政服务号码。

MNIST sample images
此处我们使用Zalando Research 制作的 FashionMNIST[13],但它包含 10 种不同服装的灰度图像。
Fashion MNIST 数据集是一个免费的大型时尚图像数据库,通常用于训练和测试各种机器学习系统。Fashion-MNIST 旨在替代原始 MNIST 数据库,用于基准机器学习算法,因为它共享相同的图像大小、数据格式和训练结构并测试分裂。

example image of FashionMNIST
torchvision.datasets包含许多示例数据集,您可以使用它们来练习编写计算机视觉代码。FashionMNIST 就是其中之一。由于它有 10 个不同的图像类别(不同类型的服装),因此这是一个多类别分类问题。
稍后,我们将构建一个计算机视觉神经网络来识别这些图像中不同风格的服装。
PyTorch 在 torchvision.datasets 中存储了一堆常见的计算机视觉数据集。我们通过torchvision.datasets.FashionMNIST() 函数将 FashionMNIST 包含在下载到本地。
# 下载训练数据集
train_data = datasets.FashionMNIST(
root="data", # 将数据下载到哪个文件夹
train=True, # 想要训练(True)还是 测试(False) 数据集
download=True, # 如果root文件夹下没有数据是否下载
transform=ToTensor(), # 想对数据进行什么转换?此处选择从Pillow数据转为torch的tensor数据。
target_transform=None # you can transform labels as well
)
# 下载测试数据集
test_data = datasets.FashionMNIST(
root="data",
train=False, # get test data
download=True,
transform=ToTensor()
)
注意datasets.FashionMNIST的变量,大多数数据集加载都使用相同的变量。
查看数据内容和属性
检查一下我们的数据,查看train_data的第一个样本:
image, label = train_data[0]
image, label
(tensor([[[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000],
.................................................................................
[0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000,
0.0000, 0.0000, 0.0000, 0.0000]]]),
9)
# 查看形状
image.shape
>>>
torch.Size([1, 28, 28])
图像张量的形状为 [1, 28, 28] ,具体来说:[color_channels=1, height=28, width=28], color_channels=1 表示图像是灰度图像。
如果
color_channels=3,则图像采用红色、绿色和蓝色的像素值(这也称为 RGB 颜色模型)。当前张量的顺序通常称为CHW(颜色通道、高度、宽度)。 还会看到NCHW和NHWC格式,其中N代表图像数量。例如,如果您有batch_size=32,您的张量形状可能是[32, 1, 28, 28]。稍后我们将介绍批量大小。
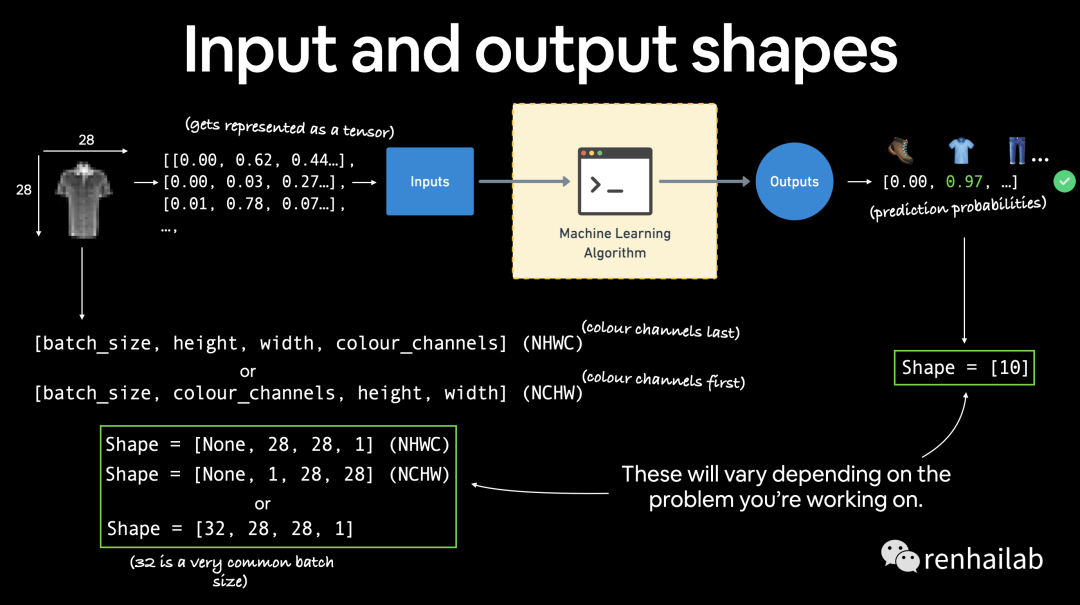
example input and output shapes of the fashionMNIST problem
不同的问题会有不同的输入和输出形状。但前提仍然是:将数据编码为数字,构建模型来查找这些数字中的模式,将这些模式转换为有意义的东西。
查看数据集的数量:
# How many samples are there?
len(train_data.data), len(train_data.targets), len(test_data.data), len(test_data.targets)
>>>
(60000, 60000, 10000, 10000)
我们有 60,000 个训练样本和 10,000 个测试样本。、
那么有多少类?通过 .classes 属性可以查看:
# See classes
class_names = train_data.classes
class_names
>>>
['T-shirt/top',
'Trouser',
'Pullover',
'Dress',
'Coat',
'Sandal',
'Shirt',
'Sneaker',
'Bag',
'Ankle boot']
看起来我们正在处理 10 种不同的衣服。
可视化数据
import matplotlib.pyplot as plt
image, label = train_data[0]
print(f"Image shape: {image.shape}")
plt.imshow(image.squeeze()) # image shape is [1, 28, 28] (colour channels, height, width)
plt.title(label);
Image shape: torch.Size([1, 28, 28])
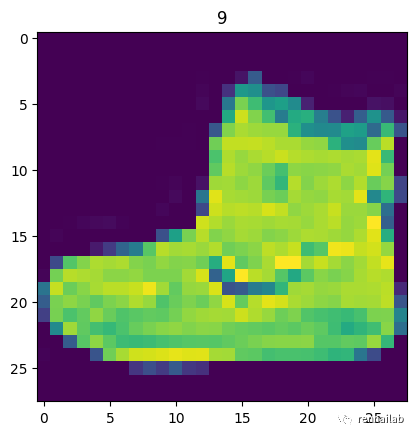
image sample
可以使用 plt.imshow() 的 cmap 参数将图像转换为灰度图像*(原始就是灰色的):
plt.imshow(image.squeeze(), cmap="gray")
plt.title(class_names[label]);
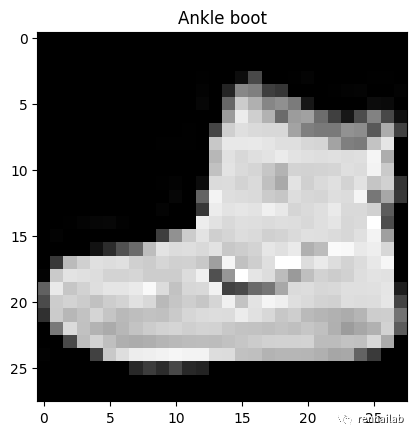
gray image
从计算机的角度看来,灰度图和有颜色的图大多数训练效果是一样的。
多看几张图:

more images in datasets
2. 准备DataLoader
我们已经准备好了数据集。下一步是用 `torch.utils.data.DataLoader`[14] 或简称 DataLoader 来分批次训练。
torch.utils.data.DataLoader 是 PyTorch 中用于加载数据的实用工具类。它提供了对数据集进行批量处理和并行加载的功能,方便进行训练和评估。
DataLoader 的主要作用是将数据集封装成一个可迭代的对象,每次迭代返回一个批次的数据。它具有以下常用参数:
dataset:要加载的数据集。通常是torch.utils.data.Dataset的子类对象,如torchvision.datasets.ImageFolder。batch_size:每个批次的样本数量。shuffle:是否在每个 epoch 重新打乱数据,以增加样本的随机性。num_workers:用于数据加载的子进程数量。可以利用多个 CPU 核心来加速数据加载。collate_fn:用于将样本列表组合成一个批次的函数。默认情况下,它使用torch.utils.data._utils.collate.default_collate函数进行默认的组合操作。pin_memory:是否将数据加载到 CUDA 固定内存中,以加速数据传输到 GPU。

an example of what a batched dataset looks like
对 FashionMNIST 进行批处理,批量大小为 32,并打开随机播放。其他数据集也会发生类似的批处理过程,但会根据批处理大小而有所不同。
让我们为我们的训练和测试集创建 DataLoader 。:
from torch.utils.data import DataLoader
# 设置BATCH_SIZE
BATCH_SIZE = 32
# 使用DataLoader加载
train_dataloader = DataLoader(train_data,
batch_size=BATCH_SIZE,
shuffle=True # shuffle:随机
)
test_dataloader = DataLoader(test_data,
batch_size=BATCH_SIZE,
shuffle=False # 测试数据不需要打乱
)
print(f"Dataloaders: {train_dataloader, test_dataloader}")
print(f"Length of train dataloader: {len(train_dataloader)} batches of {BATCH_SIZE}")
print(f"Length of test dataloader: {len(test_dataloader)} batches of {BATCH_SIZE}")
OUT:
Dataloaders: (<torch.utils.data.dataloader.DataLoader object at 0x7fc991463cd0>, <torch.utils.data.dataloader.DataLoader object at 0x7fc991475120>)
Length of train dataloader: 1875 batches of 32
Length of test dataloader: 313 batches of 32
查看单个dataloader:
train_features_batch, train_labels_batch = next(iter(train_dataloader)) # next() 函数用于获取可迭代对象的下一个元素,也就是一个批次的数据。
train_features_batch.shape, train_labels_batch.shape
>>>
(torch.Size([32, 1, 28, 28]), torch.Size([32]))
我们通过检查单个样本可以看到数据保持不变。
# 绘制出一个样本
torch.manual_seed(42)
random_idx = torch.randint(0, len(train_features_batch), size=[1]).item()
img, label = train_features_batch[random_idx], train_labels_batch[random_idx]
plt.imshow(img.squeeze(), cmap="gray")
plt.title(class_names[label])
plt.axis("Off");
print(f"Image size: {img.shape}")
print(f"Label: {label}, label size: {label.shape}")
OUT:
Image size: torch.Size([1, 28, 28])
Label: 6, label size: torch.Size([])

sample
3.构建神经网络模型
我们使用nn.Flatten() 压缩图像为单个向量,nn.Flatten() 层采用了从 [color_channels, height, width] 到 [color_channels, height*width] 的形状。我们看一个示例:
# 创建一个flatten layer
# nn.Flatten() 将张量的维度压缩为单个向量。
flatten_model = nn.Flatten() # all nn modules function as a model (can do a forward pass)
# 获取一个样本
x = train_features_batch[0]
# 使用
output = flatten_model(x) # perform forward pass
# Print out what happened
print(f"Shape before flattening: {x.shape} -> [color_channels, height, width]")
print(f"Shape after flattening: {output.shape} -> [color_channels, height*width]")
# Try uncommenting below and see what happens
#print(x)
#print(output)
OUT:
Shape before flattening: torch.Size([1, 28, 28]) -> [color_channels, height, width]
Shape after flattening: torch.Size([1, 784]) -> [color_channels, height*width]
为什么要这样做?
因为nn.Linear() 层喜欢其输入采用特征向量的形式。
让我们使用 nn.Flatten() 作为第一层来创建第一个模型。
from torch import nn
class FashionMNISTModelV0(nn.Module):
def __init__(self, input_shape: int, hidden_units: int, output_shape: int):
super().__init__()
self.layer_stack = nn.Sequential(
nn.Flatten(), # neural networks like their inputs in vector form
nn.Linear(in_features=input_shape, out_features=hidden_units), # in_features = number of features in a data sample (784 pixels)
nn.Linear(in_features=hidden_units, out_features=output_shape)
)
def forward(self, x):
return self.layer_stack(x)
我们已经有了一个可以使用的基线模型类,现在让我们实例化一个模型。
torch.manual_seed(42)
# 设置模型的参数
model_0 = FashionMNISTModelV0(input_shape=784, # 这是模型中拥有的特征数量,在我们的例子中,目标图像中的每个像素都有一个特征(28 像素高 x 28 像素宽 = 784 个特征)。
hidden_units=10, # 隐藏层中的单元/神经元数量,该数字可以是您想要的任何数字,但为了保持模型较小,我们将从 10 开始。
output_shape=len(class_names) # 由于我们正在处理多类分类问题,因此数据集中的每个类都需要一个输出神经元。
)
model_0.to("cpu") # 暂时用 CPU 处理
torch.manual_seed(42)
# Need to setup model with input parameters
model_0 = FashionMNISTModelV0(input_shape=784, # one for every pixel (28x28)
hidden_units=10, # how many units in the hiden layer
output_shape=len(class_names) # one for every class
)
model_0.to("cpu") # keep model on CPU to begin with
OUT:
FashionMNISTModelV0(
(layer_stack): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=784, out_features=10, bias=True)
(2): Linear(in_features=10, out_features=10, bias=True)
)
)
3.1 设置损失、优化器和评估指标
由于我们正在研究分类问题,因此让我们引入 `helper_functions.py`[15] 脚本中的 accuracy_fn() 。
注意:您可以从 TorchMetrics[16] 包导入各种评估指标,而不是导入和使用我们自己的准确性函数或评估指标。
import requests
from pathlib import Path
# 下载`helper_functions.py
if Path("helper_functions.py").is_file():
print("helper_functions.py already exists, skipping download")
else:
print("Downloading helper_functions.py")
# Note: you need the "raw" GitHub URL for this to work
request = requests.get("https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/helper_functions.py")
with open("helper_functions.py", "wb") as f:
f.write(request.content)
# Import accuracy metric
from helper_functions import accuracy_fn # Note: could also use torchmetrics.Accuracy(task = 'multiclass', num_classes=len(class_names)).to(device)
# 设置 loss function 和 optimizer
loss_fn = nn.CrossEntropyLoss() # this is also called "criterion"/"cost function" in some places
optimizer = torch.optim.SGD(params=model_0.parameters(), lr=0.1)
3.2 创建训练循环,批量训练模型
我们的数据批次包含在 DataLoader 、 train_dataloader 和 test_dataloader 中,分别用于训练和测试数据分割。批次是 X (特征)和 y (标签)的 BATCH_SIZE 个样本,因为我们使用 BATCH_SIZE=32 ,所以我们的批次有32 个图像和目标样本。由于我们正在计算批量数据,因此我们的损失和评估指标将按批次计算,而不是在整个数据集上计算。这意味着我们必须将损失和准确度值除以每个数据集各自的数据加载器中的批次数。
# tqdm用于在控制台显示进度条
from tqdm.auto import tqdm
# 设置随机值的种子值
torch.manual_seed(42)
# 设置训练批次
epochs = 3
# 创建训练和测试循环
for epoch in tqdm(range(epochs)):
print(f"Epoch: {epoch}\n-------")
### 训练
train_loss = 0
# 遍历dataloader,每次会返回一个批次(32个)的数据
for batch, (X, y) in enumerate(train_dataloader):
model_0.train()
# 1. 向前传播
y_pred = model_0(X)
# 2. 每个批次 计算损失
loss = loss_fn(y_pred, y)
train_loss += loss # accumulatively add up the loss per epoch
# 3. 归零梯度
optimizer.zero_grad()
# 4. 反向传播
loss.backward()
# 5. 优化
optimizer.step()
# 打印进度
if batch % 400 == 0:
print(f"Looked at {batch * len(X)}/{len(train_dataloader.dataset)} samples")
# 计算每批次的平均存世
train_loss /= len(train_dataloader)
### 测试
test_loss, test_acc = 0, 0
model_0.eval()
with torch.inference_mode():
for X, y in test_dataloader:
# 1. 向前传播
test_pred = model_0(X)
# 2. 计算损失
test_loss += loss_fn(test_pred, y) # 累加
# 3. 计算准确度
test_acc += accuracy_fn(y_true=y, y_pred=test_pred.argmax(dim=1))
# 计算测试结果需要再torch.inference_mode()内部运行
# 计算预测的测试数据的平均损失
test_loss /= len(test_dataloader)
# 计算预测的测试数据的平均准确度
test_acc /= len(test_dataloader)
## 打印测试结果
print(f"\nTrain loss: {train_loss:.5f} | Test loss: {test_loss:.5f}, Test acc: {test_acc:.2f}%\n") # :.5f表示格式化到小数点后5位
out:
0%| | 0/3 [00:00<?, ?it/s]
Epoch: 0
-------
Looked at 0/60000 samples
Looked at 12800/60000 samples
Looked at 25600/60000 samples
Looked at 38400/60000 samples
Looked at 51200/60000 samples
Train loss: 0.59039 | Test loss: 0.50954, Test acc: 82.04%
Epoch: 1
-------
Looked at 0/60000 samples
Looked at 12800/60000 samples
Looked at 25600/60000 samples
Looked at 38400/60000 samples
Looked at 51200/60000 samples
Train loss: 0.47633 | Test loss: 0.47989, Test acc: 83.20%
Epoch: 2
-------
Looked at 0/60000 samples
Looked at 12800/60000 samples
Looked at 25600/60000 samples
Looked at 38400/60000 samples
Looked at 51200/60000 samples
Train loss: 0.45503 | Test loss: 0.47664, Test acc: 83.43%
Train time on cpu: 32.349 seconds
看起来我们的基线模型表现得相当不错。
训练的时间也不是太长,即使只是在CPU上训练,不知道在GPU上会不会加速?
让我们编写一些代码来评估我们的模型。
4. 进行预测并获得 Model 0 结果
torch.manual_seed(42)
def eval_model(model: torch.nn.Module,
data_loader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
accuracy_fn):
"""返回一个包含模型在数据加载器上预测结果的字典。
参数:
model (torch.nn.Module): 能够对数据加载器进行预测的PyTorch模型。
data_loader (torch.utils.data.DataLoader): 目标数据集用于预测。
loss_fn (torch.nn.Module): 模型的损失函数。
accuracy_fn: 用于将模型的预测与真实标签进行比较的准确率函数。
返回:
(dict): 模型在数据加载器上进行预测的结果。
"""
loss, acc = 0, 0
model.eval()
with torch.inference_mode():
for X, y in data_loader:
# 使用模型进行预测
y_pred = model(X)
# 累积每个批次的损失和准确率值
loss += loss_fn(y_pred, y)
acc += accuracy_fn(y_true=y,
y_pred=y_pred.argmax(dim=1)) # 对于准确率,需要预测标签 (logits -> pred_prob -> pred_labels)
# 缩放损失和准确率以计算每个批次的平均值
loss /= len(data_loader)
acc /= len(data_loader)
return {"model_name": model.__class__.__name__, # 仅在模型是通过类创建时有效
"model_loss": loss.item(),
"model_acc": acc}
# 计算模型0在测试数据集上的结果
model_0_results = eval_model(model=model_0, data_loader=test_dataloader,
loss_fn=loss_fn, accuracy_fn=accuracy_fn
)
model_0_results
out:
{'model_name': 'FashionMNISTModelV0',
'model_loss': 0.47663894295692444,
'model_acc': 83.42651757188499}
5. 模型 1:建立更好的非线性模型
我们将通过重新创建与之前类似的模型来实现此目的,但这次我们将在每个线性层之间放置非线性函数 ( nn.ReLU() )。
# 创建一个有非线性和线性层的模型
import torch
class FashionMNISTModelV1(nn.Module):
def __init__(self, input_shape: int, hidden_units: int, output_shape: int):
super().__init__()
self.layer_stack = nn.Sequential(
nn.Flatten(), # flatten inputs into single vector
nn.Linear(in_features=input_shape, out_features=hidden_units),
nn.ReLU(),
nn.Linear(in_features=hidden_units, out_features=output_shape),
nn.ReLU()
)
def forward(self, x: torch.Tensor):
return self.layer_stack(x)
设置损失、优化器并且评估指标:
device = "cuda" if torch.cuda.is_available() else "cpu"
torch.manual_seed(42)
# 实例化模型
model_1 = FashionMNISTModelV1(input_shape=784, # number of input features
hidden_units=10,
output_shape=len(class_names) # number of output classes desired
).to(device) # send model to GPU if it's available
# 设置损失、优化器
from helper_functions import accuracy_fn
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model_1.parameters(),
lr=0.1)
from helper_functions import accuracy_fn
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model_1.parameters(),
lr=0.1)
def train_step(model: torch.nn.Module,
data_loader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
optimizer: torch.optim.Optimizer,
accuracy_fn,
device: torch.device = device):
train_loss, train_acc = 0, 0
model.to(device)
for batch, (X, y) in enumerate(data_loader):
# 发送到 GPU
X, y = X.to(device), y.to(device)
# 1. 向前传播
y_pred = model(X)
# 2. 计算损失
loss = loss_fn(y_pred, y)
train_loss += loss
train_acc += accuracy_fn(y_true=y,
y_pred=y_pred.argmax(dim=1)) # Go from logits -> pred labels
# 3. 归零梯度
optimizer.zero_grad()
# 4. 反向传播
loss.backward()
# 5. 优化
optimizer.step()
# 打印训练损失和准确度
train_loss /= len(data_loader)
train_acc /= len(data_loader)
print(f"Train loss: {train_loss:.5f} | Train accuracy: {train_acc:.2f}%")
def test_step(data_loader: torch.utils.data.DataLoader,
model: torch.nn.Module,
loss_fn: torch.nn.Module,
accuracy_fn,
device: torch.device = device):
test_loss, test_acc = 0, 0
model.to(device)
model.eval() # put model in eval mode
# Turn on inference context manager
with torch.inference_mode():
for X, y in data_loader:
# Send data to GPU
X, y = X.to(device), y.to(device)
# 1. 向前传播
test_pred = model(X)
# 2. 计算损失
test_loss += loss_fn(test_pred, y)
test_acc += accuracy_fn(y_true=y,
y_pred=test_pred.argmax(dim=1) # Go from logits -> pred labels
)
# 打印测试损失和准确度
test_loss /= len(data_loader)
test_acc /= len(data_loader)
print(f"Test loss: {test_loss:.5f} | Test accuracy: {test_acc:.2f}%\n")
out:
0%| | 0/3 [00:00<?, ?it/s]
Epoch: 0
---------
Train loss: 1.09199 | Train accuracy: 61.34%
Test loss: 0.95636 | Test accuracy: 65.00%
Epoch: 1
---------
Train loss: 0.78101 | Train accuracy: 71.93%
Test loss: 0.72227 | Test accuracy: 73.91%
Epoch: 2
---------
Train loss: 0.67027 | Train accuracy: 75.94%
Test loss: 0.68500 | Test accuracy: 75.02%
Train time on cuda: 36.878 seconds
5.1 评估模型
torch.manual_seed(42)
def eval_model(model: torch.nn.Module,
data_loader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
accuracy_fn,
device: torch.device = device):
"""在给定数据集上评估给定的模型。
参数:
model (torch.nn.Module): 能够对数据加载器进行预测的PyTorch模型。
data_loader (torch.utils.data.DataLoader): 目标数据集用于预测。
loss_fn (torch.nn.Module): 模型的损失函数。
accuracy_fn: 用于将模型的预测与真实标签进行比较的准确率函数。
device (str, 可选): 计算设备的目标位置。默认为设备。
返回:
(dict): 模型在数据加载器上进行预测的结果。
"""
loss, acc = 0, 0
model.eval()
with torch.inference_mode():
for X, y in data_loader:
# Send data to the target device
X, y = X.to(device), y.to(device)
y_pred = model(X)
loss += loss_fn(y_pred, y)
acc += accuracy_fn(y_true=y, y_pred=y_pred.argmax(dim=1))
# Scale loss and acc
loss /= len(data_loader)
acc /= len(data_loader)
return {"model_name": model.__class__.__name__, # only works when model was created with a class
"model_loss": loss.item(),
"model_acc": acc}
# 评估
model_1_results = eval_model(model=model_1, data_loader=test_dataloader,
loss_fn=loss_fn, accuracy_fn=accuracy_fn,
device=device
)
model_1_results
{'model_name': 'FashionMNISTModelV1',
'model_loss': 0.6850008964538574,
'model_acc': 75.01996805111821}
对比model_0基线模型:
# Check baseline results
model_0_results
out:
{'model_name': 'FashionMNISTModelV0',
'model_loss': 0.47663894295692444,
'model_acc': 83.42651757188499}
在这种情况下,看起来向我们的模型添加非线性使其性能比基线更差。
从表面上看,我们的模型似乎对训练数据过度拟合。过度拟合意味着我们的模型很好地学习了训练数据,但这些模式无法推广到测试数据。
5.2 修复过度拟合
修复过度拟合的几种主要方法包括:
- 数据增强(Data Augmentation):通过对训练数据进行随机变换和扩充,生成新的训练样本,以增加数据的多样性。这可以帮助模型更好地泛化,并减少过度拟合的风险。
- 正则化(Regularization):通过在模型的损失函数中添加正则化项,限制模型的复杂度。常用的正则化方法包括L1正则化和L2正则化,它们可以防止模型过度拟合训练数据。
- 早停(Early Stopping):在训练过程中监控模型在验证集上的性能,并在验证集上的性能不再提升时停止训练。这可以避免模型在训练数据上过度拟合,并选择具有较好泛化能力的模型。
- Dropout:在模型的训练过程中,随机地将一部分神经元的输出设置为0,以减少神经元之间的依赖关系。这样可以强制模型学习更加鲁棒的特征表示,并减少过度拟合的风险。
- 模型复杂度调整:通过减少模型的复杂度,例如减少网络层数、减少隐藏单元的数量等,可以降低模型的拟合能力,从而减少过度拟合的问题。
- Dropout、Batch Normalization等正则化技术:使用正则化技术,如Dropout和Batch Normalization,可以帮助模型更好地泛化并减少过度拟合的风险。
- 增加训练数据量:增加训练数据量可以有效减少过度拟合的问题,因为更多的数据可以提供更多的样本多样性,帮助模型更好地泛化。
这些方法可以单独或结合使用,根据具体问题和数据集的特点选择适合的方法来修复过度拟合问题。
6.模型2:构建卷积神经网络(CNN)
是时候创建一个卷积神经网络(CNN 或 ConvNet)了。
在机器学习中,分类器为数据点分配类标签。例如,图像分类器为图像中存在的对象生成类标签(例如,鸟、飞机)。卷积神经网络(简称CNN)是一种分类器,它擅长解决这个问题!
CNN 是一种神经网络:一种用于识别数据模式的算法。神经网络通常由分层组织的神经元集合组成,每个神经元都有自己的可学习权重和偏差。
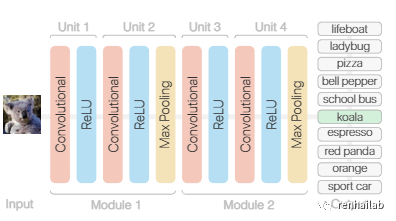
TinyVGG 卷积神经网络模型简化图
卷积神经网络中最大的不同就是卷积层了,下面是一个卷积层的动画示例:
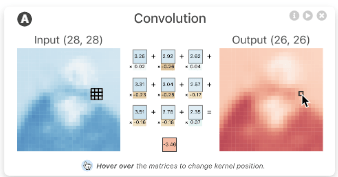
一个可视化网站让你瞬间弄懂什么是卷积网络
卷积神经网络可视化可以看看我的另一篇文章:一个可视化网站让你瞬间弄懂什么是卷积网络[17]
现在让我们构建一个 CNN,复制 CNN 解释器网站[18]上的模型:
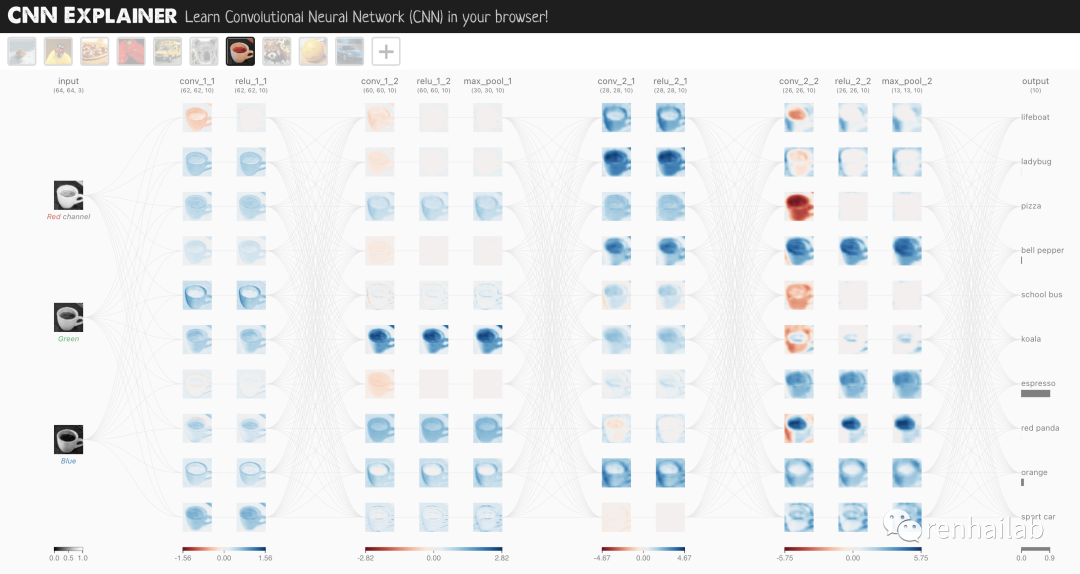
TinyVGG architecture, as setup by CNN explainer website
我们将利用 torch.nn 中的 `nn.Conv2d()`[19] 和 `nn.MaxPool2d()`[20] 层构建卷积神经网络,完整代码如下,后文会一步步拆解
#构建卷积神经网络
class FashionMNISTModelV2(nn.Module):
"""
Model architecture copying TinyVGG from:
https://poloclub.github.io/cnn-explainer/
"""
def __init__(self, input_shape: int, hidden_units: int, output_shape: int):
super().__init__()
self.block_1 = nn.Sequential(
nn.Conv2d(in_channels=input_shape,
out_channels=hidden_units,
kernel_size=3, # how big is the square that's going over the image?
stride=1, # default
padding=1),# options = "valid" (no padding) or "same" (output has same shape as input) or int for specific number
nn.ReLU(),
nn.Conv2d(in_channels=hidden_units,
out_channels=hidden_units,
kernel_size=3,
stride=1,
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,
stride=2) # default stride value is same as kernel_size
)
self.block_2 = nn.Sequential(
nn.Conv2d(hidden_units, hidden_units, 3, padding=1),
nn.ReLU(),
nn.Conv2d(hidden_units, hidden_units, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.classifier = nn.Sequential(
nn.Flatten(),
# Where did this in_features shape come from?
# It's because each layer of our network compresses and changes the shape of our inputs data.
nn.Linear(in_features=hidden_units*7*7,
out_features=output_shape)
)
def forward(self, x: torch.Tensor):
x = self.block_1(x)
# print(x.shape)
x = self.block_2(x)
# print(x.shape)
x = self.classifier(x)
# print(x.shape)
return x
torch.manual_seed(42)
model_2 = FashionMNISTModelV2(input_shape=1,
hidden_units=10,
output_shape=len(class_names)).to(device)
model_2
out:
FashionMNISTModelV2(
(block_1): Sequential(
(0): Conv2d(1, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(10, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(block_2): Sequential(
(0): Conv2d(10, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU()
(2): Conv2d(10, 10, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU()
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=490, out_features=10, bias=True)
)
)
6.1 卷积层
- `nn.Conv2d()`[21], 也称为卷积层。
- `nn.MaxPool2d()`[22], 也称为最大池化层。 创建演示数据来看看卷积层内部发生了什么:
torch.manual_seed(42)
# 创建和图片大小一样、批次大小一样的随机数据
images = torch.randn(size=(32, 3, 64, 64)) # [batch_size, color_channels, height, width]
test_image = images[0] # 测试
print(f"Image batch shape: {images.shape} -> [batch_size, color_channels, height, width]")
print(f"Single image shape: {test_image.shape} -> [color_channels, height, width]")
print(f"Single image pixel values:\n{test_image}")
Image batch shape: torch.Size([32, 3, 64, 64]) -> [batch_size, color_channels, height, width]
Single image shape: torch.Size([3, 64, 64]) -> [color_channels, height, width]
Single image pixel values:
tensor([[[ 1.9269, 1.4873, 0.9007, ..., 1.8446, -1.1845, 1.3835],
[ 1.4451, 0.8564, 2.2181, ..., 0.3399, 0.7200, 0.4114],
[ 1.9312, 1.0119, -1.4364, ..., -0.5558, 0.7043, 0.7099],
...,
[-0.5610, -0.4830, 0.4770, ..., -0.2713, -0.9537, -0.6737],
[ 0.3076, -0.1277, 0.0366, ..., -2.0060, 0.2824, -0.8111],
[-1.5486, 0.0485, -0.7712, ..., -0.1403, 0.9416, -0.0118]],
[[-0.5197, 1.8524, 1.8365, ..., 0.8935, -1.5114, -0.8515],
[ 2.0818, 1.0677, -1.4277, ..., 1.6612, -2.6223, -0.4319],
[-0.1010, -0.4388, -1.9775, ..., 0.2106, 0.2536, -0.7318],
...,
[ 0.2779, 0.7342, -0.3736, ..., -0.4601, 0.1815, 0.1850],
[ 0.7205, -0.2833, 0.0937, ..., -0.1002, -2.3609, 2.2465],
[-1.3242, -0.1973, 0.2920, ..., 0.5409, 0.6940, 1.8563]],
[[-0.7978, 1.0261, 1.1465, ..., 1.2134, 0.9354, -0.0780],
[-1.4647, -1.9571, 0.1017, ..., -1.9986, -0.7409, 0.7011],
[-1.3938, 0.8466, -1.7191, ..., -1.1867, 0.1320, 0.3407],
...,
[ 0.8206, -0.3745, 1.2499, ..., -0.0676, 0.0385, 0.6335],
[-0.5589, -0.3393, 0.2347, ..., 2.1181, 2.4569, 1.3083],
[-0.4092, 1.5199, 0.2401, ..., -0.2558, 0.7870, 0.9924]]])
Let's create an example nn.Conv2d() with various parameters: 让我们创建一个带有各种参数的示例 nn.Conv2d() :
in_channels(int) - 输入图像中的通道数。out_channels(int) - 卷积产生的通道数。kernel_size(int 或 tuple)- 卷积内核/过滤器的大小。stride(整数或元组,可选)- 卷积内核一次采取多大的步长。默认值:1。padding(int, tuple, str) - 添加到输入的所有四个边的填充。默认值:0。
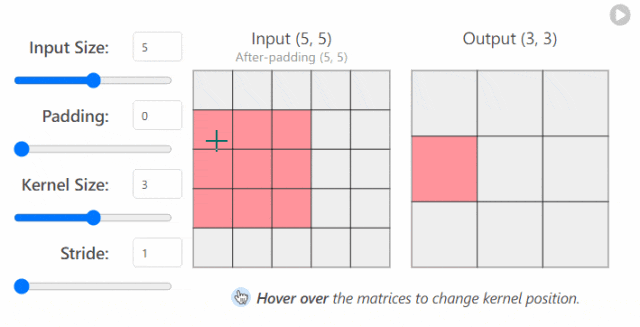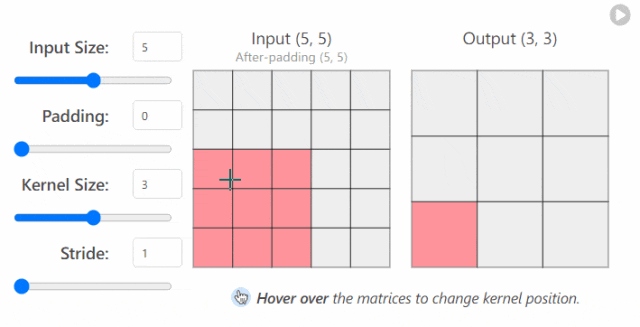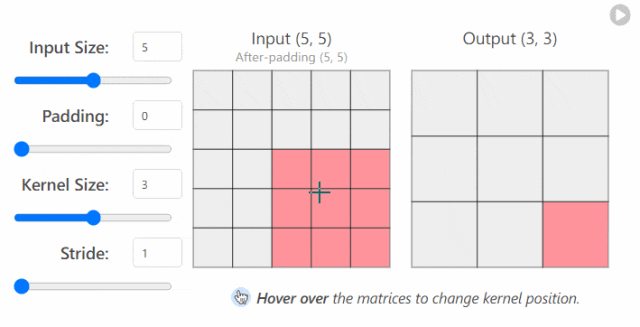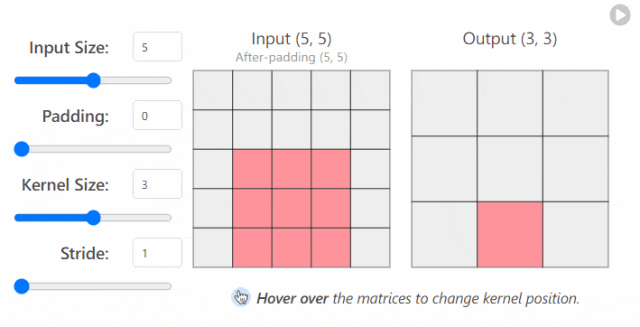
更改 nn.Conv2d()`层的超参数时发生的情况示例1
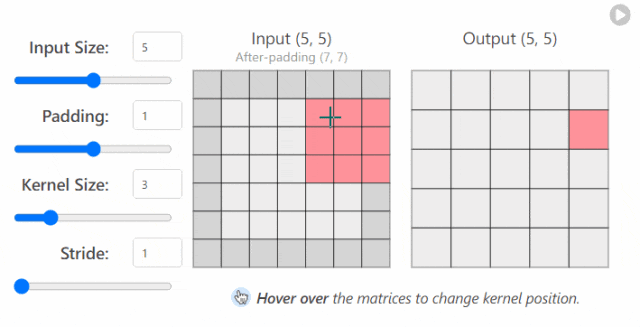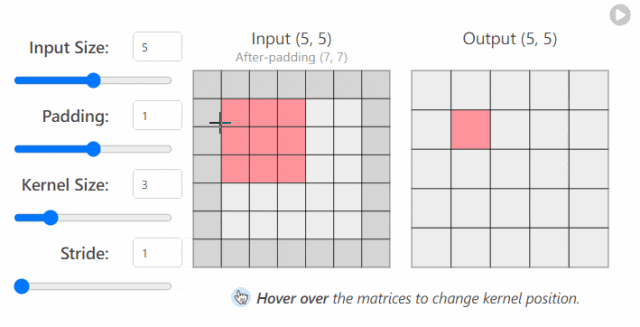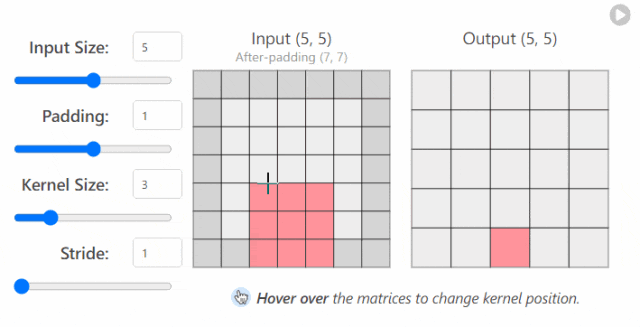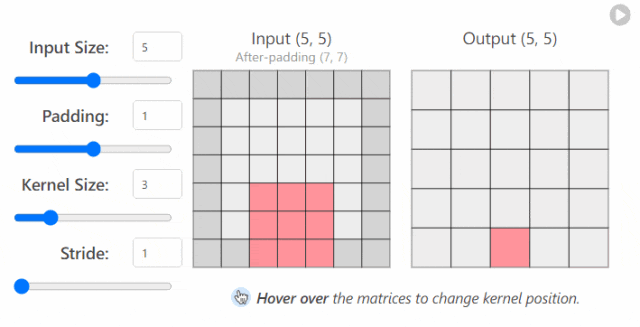
更改 nn.Conv2d()`层的超参数时发生的情况示例2
torch.manual_seed(42)
# 创建一个与TinyVGG相同尺寸的卷积层
conv_layer = nn.Conv2d(in_channels=3,
out_channels=10,
kernel_size=3,
stride=1,
padding=0)
# 通过卷积层传递数据
conv_layer(test_image) # Note::如果运行PyTorch <1.11.0,这将因为形状问题而出错(nn.Conv.2d()期望一个4d张量作为输入),使用conv_layer(test_image.unsqueeze(dim=0))以避免此问题
out:
tensor([[[ 1.5396, 0.0516, 0.6454, ..., -0.3673, 0.8711, 0.4256],
[ 0.3662, 1.0114, -0.5997, ..., 0.8983, 0.2809, -0.2741],
[ 1.2664, -1.4054, 0.3727, ..., -0.3409, 1.2191, -0.0463],
...,
[-0.1541, 0.5132, -0.3624, ..., -0.2360, -0.4609, -0.0035],
[ 0.2981, -0.2432, 1.5012, ..., -0.6289, -0.7283, -0.5767],
[-0.0386, -0.0781, -0.0388, ..., 0.2842, 0.4228, -0.1802]],
[[-0.2840, -0.0319, -0.4455, ..., -0.7956, 1.5599, -1.2449],
[ 0.2753, -0.1262, -0.6541, ..., -0.2211, 0.1999, -0.8856],
[-0.5404, -1.5489, 0.0249, ..., -0.5932, -1.0913, -0.3849],
...,
[ 0.3870, -0.4064, -0.8236, ..., 0.1734, -0.4330, -0.4951],
[-0.1984, -0.6386, 1.0263, ..., -0.9401, -0.0585, -0.7833],
[-0.6306, -0.2052, -0.3694, ..., -1.3248, 0.2456, -0.7134]],
[[ 0.4414, 0.5100, 0.4846, ..., -0.8484, 0.2638, 1.1258],
[ 0.8117, 0.3191, -0.0157, ..., 1.2686, 0.2319, 0.5003],
[ 0.3212, 0.0485, -0.2581, ..., 0.2258, 0.2587, -0.8804],
...,
[-0.1144, -0.1869, 0.0160, ..., -0.8346, 0.0974, 0.8421],
[ 0.2941, 0.4417, 0.5866, ..., -0.1224, 0.4814, -0.4799],
[ 0.6059, -0.0415, -0.2028, ..., 0.1170, 0.2521, -0.4372]],
...,
[[-0.2560, -0.0477, 0.6380, ..., 0.6436, 0.7553, -0.7055],
[ 1.5595, -0.2209, -0.9486, ..., -0.4876, 0.7754, 0.0750],
[-0.0797, 0.2471, 1.1300, ..., 0.1505, 0.2354, 0.9576],
...,
[ 1.1065, 0.6839, 1.2183, ..., 0.3015, -0.1910, -0.1902],
[-0.3486, -0.7173, -0.3582, ..., 0.4917, 0.7219, 0.1513],
[ 0.0119, 0.1017, 0.7839, ..., -0.3752, -0.8127, -0.1257]],
[[ 0.3841, 1.1322, 0.1620, ..., 0.7010, 0.0109, 0.6058],
[ 0.1664, 0.1873, 1.5924, ..., 0.3733, 0.9096, -0.5399],
[ 0.4094, -0.0861, -0.7935, ..., -0.1285, -0.9932, -0.3013],
...,
[ 0.2688, -0.5630, -1.1902, ..., 0.4493, 0.5404, -0.0103],
[ 0.0535, 0.4411, 0.5313, ..., 0.0148, -1.0056, 0.3759],
[ 0.3031, -0.1590, -0.1316, ..., -0.5384, -0.4271, -0.4876]],
[[-1.1865, -0.7280, -1.2331, ..., -0.9013, -0.0542, -1.5949],
[-0.6345, -0.5920, 0.5326, ..., -1.0395, -0.7963, -0.0647],
[-0.1132, 0.5166, 0.2569, ..., 0.5595, -1.6881, 0.9485],
...,
[-0.0254, -0.2669, 0.1927, ..., -0.2917, 0.1088, -0.4807],
[-0.2609, -0.2328, 0.1404, ..., -0.1325, -0.8436, -0.7524],
[-1.1399, -0.1751, -0.8705, ..., 0.1589, 0.3377, 0.3493]]],
grad_fn=<SqueezeBackward1>)
如果我们更改 conv_layer 的值会怎样?
torch.manual_seed(42)
conv_layer_2 = nn.Conv2d(in_channels=3,
out_channels=10,
kernel_size=(5, 5), #
stride=2,
padding=0)
conv_layer_2(test_image.unsqueeze(dim=0)).shape
out:
torch.Size([1, 10, 30, 30])
6.2 池化层
让我们看看当我们通过 nn.MaxPool2d() 处理数据会发生什么。
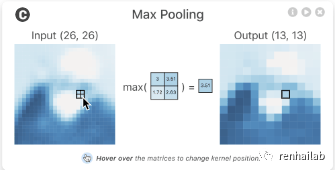
池化层动画演示
# 打印原始图形的形状
print(f"测试图像的原始形状: {test_image.shape}")
print(f"对测试图像进行维度扩展之后: {test_image.unsqueeze(dim=0).shape}")
# 使用最大池化层行数nn.MaxPoo2d() 创建池化层
max_pool_layer = nn.MaxPool2d(kernel_size=2)
# 传入卷积层
test_image_through_conv = conv_layer(test_image.unsqueeze(dim=0))
print(f"传入卷积层之后的图形大小: {test_image_through_conv.shape}")
# 传入最大池化层
test_image_through_conv_and_max_pool = max_pool_layer(test_image_through_conv)
print(f"传入卷积层和最大池化层后的图形大小:{test_image_through_conv_and_max_pool.shape}")
out:
测试图像的原始形状:torch.Size([3, 64, 64])
对测试图像进行维度扩展之后: torch.Size([1, 3, 64, 64])
传入卷积层之后的图形大小: torch.Size([1, 10, 62, 62])
传入卷积层和最大池化层后的图形大小:torch.Size([1, 10, 31, 31])
nn.MaxPool2d() 层的 kernel_size 将影响输出形状的大小。在我们的例子中,形状从 62x62 图像减半为 31x31 图像。nn.MaxPool2d() 的 kernel_size 的不同值,变化会有所不同。
本质上,神经网络中的每一层都试图将数据从高维空间压缩到低维空间。从人工智能的角度来看,您可以考虑神经网络压缩信息的整体目标。
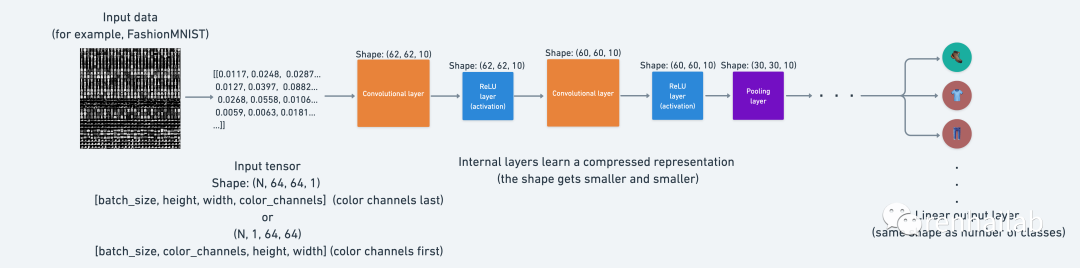
each layer of a neural network compresses the original input data into a smaller representation that is (hopefully) capable of making predictions on future input data
使用 nn.MaxPool2d() 层的想法:从张量的一部分中获取最大值并忽略其余部分。本质上,降低张量的维数,同时仍然保留(希望)重要的信息部分。对于 nn.Conv2d() 层来说也是同样的情况。除了仅取最大值之外, nn.Conv2d() 对数据执行卷积运算(请参阅 CNN 解释器网页[23]上的实际操作)。
除了最大池化函数nn.MaxPool2d() 还有平均池化层函数nn.AvgPool2d(),用于在卷积神经网络中进行下采样操作。它通过在输入张量的局部区域中计算平均值来减小特征图的空间尺寸。与nn.MaxPool2d()类似,nn.AvgPool2d()函数默认使用非重叠的窗口进行池化操作。如果需要使用重叠的窗口进行池化,可以设置stride参数大于等于kernel_size。
更多常见的预训练卷积神经网络模型在 `torchvision.models`[24]中都有说明,比如:
from torchvision.models import resnet50, ResNet50_Weights
# 实例化一个ResNet50_Weights V1模型
resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)
# 实例化一个ResNet50_Weights V2模型
resnet50(weights=ResNet50_Weights.IMAGENET1K_V2)
# DEFAULT模型表现最好
# 实例化一个ResNet50_Weights DEFAULT模型
resnet50(weights=ResNet50_Weights.DEFAULT)
在06-PyTorch迁移学习:在预训练模型上进行训练[25]中会着重学习使用预训练模型进行迁移学习。
6.3 为 model_2 设置损失函数和优化器
我们将像以前一样使用函数 nn.CrossEntropyLoss() 作为损失函数(因为我们正在处理多类分类数据)。将 torch.optim.SGD() 作为优化器,以 0.1 的学习率优化 model_2.parameters() 。
# 设置损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(params=model_2.parameters(),
lr=0.1)
6.4 训练和测试 model_2
torch.manual_seed(42)
# 训练和测试
epochs = 3
for epoch in tqdm(range(epochs)):
print(f"Epoch: {epoch}\n---------")
train_step(data_loader=train_dataloader,
model=model_2,
loss_fn=loss_fn,
optimizer=optimizer,
accuracy_fn=accuracy_fn,
device=device
)
test_step(data_loader=test_dataloader,
model=model_2,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn,
device=device
)
out:
0%| | 0/3 [00:00<?, ?it/s]
Epoch: 0
---------
Train loss: 0.59302 | Train accuracy: 78.41%
Test loss: 0.39771 | Test accuracy: 86.01%
Epoch: 1
---------
Train loss: 0.36149 | Train accuracy: 87.00%
Test loss: 0.35713 | Test accuracy: 87.00%
Epoch: 2
---------
Train loss: 0.32354 | Train accuracy: 88.28%
Test loss: 0.32857 | Test accuracy: 88.38%
Train time on cuda: 44.250 seconds
看起来卷积层和最大池化层有助于提高性能。
让我们使用 eval_model() 函数评估 model_2 的结果。
# Get model_2 results
model_2_results = eval_model(
model=model_2,
data_loader=test_dataloader,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn
)
model_2_results
out:
{'model_name': 'FashionMNISTModelV2',
'model_loss': 0.3285697102546692,
'model_acc': 88.37859424920129}
7.比较模型结果和训练时间
我们训练了三个模型:
- model_0
- 我们的基线模型有两个nn.Linear()` 层。 model_1- 与我们的基线模型相同的设置,除了nn.Linear()层之间有nn.ReLU()层。model_2- 我们的第一个 CNN 模型,模仿 CNN 解释器网站上的 TinyVGG 架构。
构建多个模型并执行多个训练实验,看看哪个模型表现最好。让我们将模型结果字典合并到 DataFrame 中并找出答案。
import pandas as pd
compare_results = pd.DataFrame([model_0_results, model_1_results, model_2_results])
compare_results
out:

compare_results
原文测试了运行时间,含有训练时间的表格结果如下:

image-20230929174029768
看起来我们的 CNN ( FashionMNISTModelV2 ) 模型表现最好(损失最低,准确率最高),但训练时间最长。我们的基线模型 ( FashionMNISTModelV0 ) 比 model_1 ( FashionMNISTModelV1 ) 表现更好。
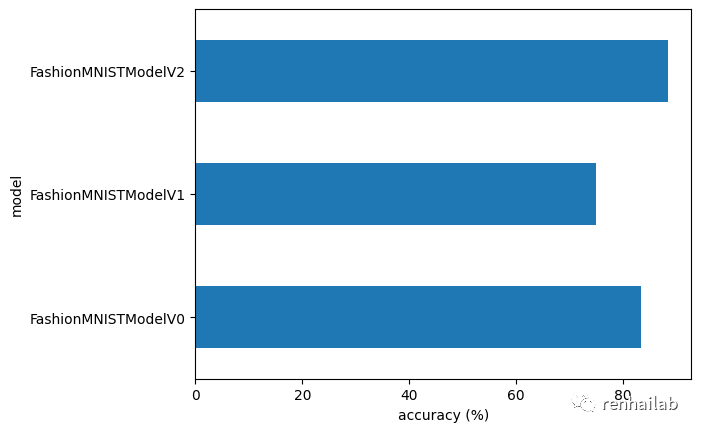
性能与速度的权衡
在机器学习中需要注意的是性能与速度的权衡。一般来说,您可以从更大、更复杂的模型中获得更好的性能,然而,这种性能提升通常是以牺牲训练速度和推理速度为代价的。
8. 使用最佳模型进行随机预测并进行评估
已经对模型进行了相互比较,让我们进一步评估性能最佳的模型 model_2。为此,我们创建一个函数 make_predictions() ,我们可以在其中传递模型和一些数据以供其预测。
def make_predictions(model: torch.nn.Module, data: list, device: torch.device = device):
pred_probs = []
model.eval()
with torch.inference_mode():
for sample in data:
# 准备样本
sample = torch.unsqueeze(sample, dim=0).to(device) # 添加一个额外的维度并将样本发送到设备
# 前向传播(模型输出原始logit)
pred_logit = model(sample)
# 获取预测概率(logit -> 预测概率)
pred_prob = torch.softmax(pred_logit.squeeze(), dim=0) # 注意:在“logits”维度上执行softmax,而不是“batch”维度(在这种情况下,我们的批次大小为1,所以可以在dim=0上执行)
# 将pred_prob从GPU取出以进行进一步计算
pred_probs.append(pred_prob.cpu())
# 将pred_probs堆叠起来,将列表转换为张量
return torch.stack(pred_probs)
import random
random.seed(42)
test_samples = []
test_labels = []
for sample, label in random.sample(list(test_data), k=9):
test_samples.append(sample)
test_labels.append(label)
# 检查样本的第一个数据
print(f"测试样本的图像形状:{test_samples[0].shape}\n测试样本的图像标签:{test_labels[0]} ({class_names[test_labels[0]]})")
Test sample image shape: torch.Size([1, 28, 28])
Test sample label: 5 (Sandal)
在我们可以使用 make_predictions() 函数来预测 test_samples 。
# 用模型2做预测
pred_probs= make_predictions(model=model_2,
data=test_samples)
# 查看前两次预测结果
pred_probs[:2]
tensor([[2.4012e-07, 6.5406e-08, 4.8069e-08, 2.1070e-07, 1.4175e-07, 9.9992e-01,
2.1711e-07, 1.6177e-05, 3.7849e-05, 2.7548e-05],
[1.5646e-02, 8.9752e-01, 3.6928e-04, 6.7402e-02, 1.2920e-02, 4.9539e-05,
5.6485e-03, 1.9456e-04, 2.0808e-04, 3.7861e-05]])
现在我们可以通过获取 torch.softmax() 激活函数输出的 torch.argmax() 从预测概率到预测标签。
# 通过argmax()函数将预测概率转为标签
pred_classes = pred_probs.argmax(dim=1)
pred_classes
tensor([5, 1, 7, 4, 3, 0, 4, 7, 1])
我们的删结果和真实结果对比:
test_labels, pred_classes
([5, 1, 7, 4, 3, 0, 4, 7, 1], tensor([5, 1, 7, 4, 3, 0, 4, 7, 1]))
可视化结果
# 绘制预测结果
plt.figure(figsize=(9, 9))
nrows = 3
ncols = 3
for i, sample in enumerate(test_samples):
# 创建一个子图
plt.subplot(nrows, ncols, i+1)
# 绘制目标图像
plt.imshow(sample.squeeze(), cmap="gray")
# 查找预测标签(以文本形式,例如“凉鞋”)
pred_label = class_names[pred_classes[i]]
# 获取真实标签(以文本形式,例如“T恤”)
truth_label = class_names[test_labels[i]]
# 创建子图的标题文本
title_text = f"预测: {pred_label} | 真实: {truth_label}"
# 检查是否相等并相应地更改标题颜色
if pred_label == truth_label:
plt.title(title_text, fontsize=10, c="g") # 如果正确,标题为绿色文本
else:
plt.title(title_text, fontsize=10, c="r") # 如果错误,标题为红色文本
plt.axis(False);

Pred
9. 制作混淆矩阵以进行进一步的预测评估
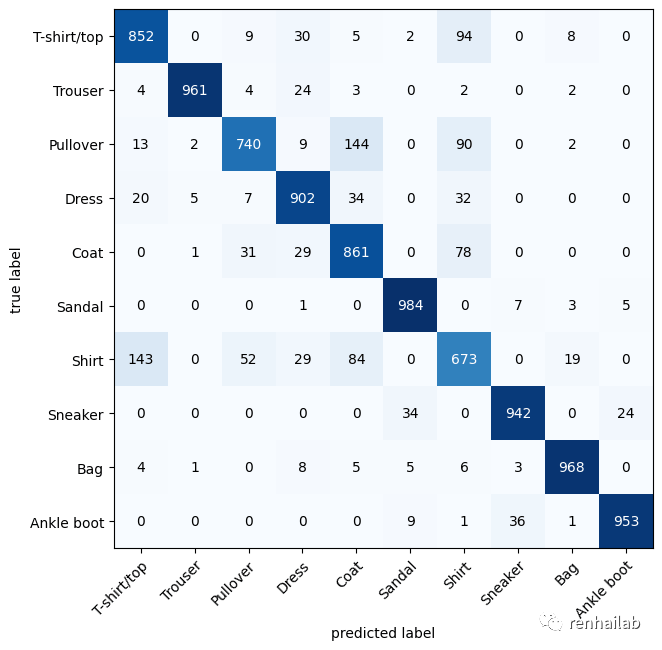
我们可以使用许多不同的评估指标来解决分类问题,最直观的之一是混淆矩阵。
混淆矩阵向您显示分类模型在预测和真实标签之间发生混淆的位置。
制作混淆矩阵分为三个步骤:
- 使用我们训练的模型进行预测,
model_2(混淆矩阵将预测与真实标签进行比较)。 - 使用 `torchmetrics.ConfusionMatrix`[26] 制作混淆矩阵。
- 使用 `mlxtend.plotting.plot_confusion_matrix()`[27] 绘制混淆矩阵。
我们需要安装mlxtend和torchmetrics库:
try:
import torchmetrics, mlxtend
print(f"mlxtend version: {mlxtend.__version__}")
assert int(mlxtend.__version__.split(".")[1]) >= 19, "mlxtend verison should be 0.19.0 or higher"
except:
!pip install -q torchmetrics -U mlxtend
import torchmetrics, mlxtend
print(f"mlxtend version: {mlxtend.__version__}")
9.1 预测
# 导入tqdm用于显示进度条
from tqdm.auto import tqdm
# 1. 使用训练好的模型进行预测
y_preds = []
model_2.eval()
with torch.inference_mode():
for X, y in tqdm(test_dataloader, desc="进行预测"):
# 将数据和目标发送到目标设备
X, y = X.to(device), y.to(device)
# 进行前向传播
y_logit = model_2(X)
# 将预测从logits转换为预测概率 -> 预测标签
y_pred = torch.softmax(y_logit, dim=1).argmax(dim=1) # 注意:在“logits”维度上执行softmax,而不是“batch”维度(在这种情况下,我们的批次大小为32,所以可以在dim=1上执行)
# 将预测放在CPU上进行评估
y_preds.append(y_pred.cpu())
# 将预测列表连接成一个张量
y_pred_tensor = torch.cat(y_preds)
9.2 创建并绘制
from torchmetrics import ConfusionMatrix
from mlxtend.plotting import plot_confusion_matrix
# 2. 创建一个 torchmetrics.ConfusionMatrix 实例
# 设置 num_classes=len(class_names) 告诉它我们正在处理多少个类
confmat = ConfusionMatrix(num_classes=len(class_names), task='multiclass')
# 将通过向实例传递模型的预测 ( preds=y_pred_tensor ) 和目标 ( target=test_data.targets ) 来创建混淆矩阵(张量格式)
confmat_tensor = confmat(preds=y_pred_tensor,
target=test_data.targets)
# 3. 我们可以使用 mlxtend.plotting 中的 plot_confusion_matrix() 函数绘制我们的配置矩阵。
fig, ax = plot_confusion_matrix(
conf_mat=confmat_tensor.numpy(), # matplotlib likes working with NumPy
class_names=class_names, # turn the row and column labels into class names
figsize=(10, 7)
);
confusion_matrix
我们可以看到我们的模型表现得相当好,因为大多数黑色方块都位于从左上角到右下角的对角线下方(理想模型只有这些方块中的值,其他地方都为 0)。
该模型在相似的物体识别得不准,例如为实际标记为“衬衫”的图像预测为“套衫”。
10.保存并加载最佳性能模型
回想02-PyTorch工作流程基础知识[28],我们可以使用以下组合来保存和加载 PyTorch 模型:
torch.save- 保存整个 PyTorch 模型或模型的state_dict()的函数。torch.load- 加载已保存的 PyTorch 对象的函数。torch.nn.Module.load_state_dict()- 将保存的state_dict()加载到现有模型实例中的函数。
10.1保存模型
让我们保存 model_2 的 state_dict() 然后将其重新加载并对其进行评估以确保保存和加载正确。
from pathlib import Path
# 创建模型目录(如果不存在),参考:https://docs.python.org/3/library/pathlib.html#pathlib.Path.mkdir
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, # 如果需要,创建父目录
exist_ok=True # 如果模型目录已经存在,则不报错
)
# 创建模型保存路径
MODEL_NAME = "03_pytorch_computer_vision_model_2.pth"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
# 保存模型的状态字典
print(f"正在保存模型至:{MODEL_SAVE_PATH}")
torch.save(obj=model_2.state_dict(), # 只保存state_dict(),即只保存学习到的参数
f=MODEL_SAVE_PATH)
现在我们已经保存了模型 state_dict() 我们可以使用 load_state_dict() 和 torch.load() 的组合将其加载回来。
10.2 加载模型
由于我们使用的是 load_state_dict() ,因此我们需要创建一个 FashionMNISTModelV2() 的新实例,其输入参数与保存的模型 state_dict() 相同。
# 创建FashionMNISTModelV2的新实例(与我们保存的state_dict()相同的类)
# 注意:如果这里的形状与保存的版本不同,加载模型将会报错
loaded_model_2 = FashionMNISTModelV2(input_shape=1,
hidden_units=10, # 尝试将其更改为128,看看会发生什么
output_shape=10)
# 加载保存的state_dict()
loaded_model_2.load_state_dict(torch.load(f=MODEL_SAVE_PATH))
# 将模型发送到GPU
loaded_model_2 = loaded_model_2.to(device)
额外资料:
- 观看:麻省理工学院的深度计算机视觉简介讲座。[29]
- 花 10 分钟浏览 PyTorch 视觉库[30]的不同选项,有哪些不同的模块可用?
- 搜索“最常见的卷积神经网络”,你发现了什么架构?它们中的任何一个都包含在
[torchvision.models](https://pytorch.org/vision/stable/models.html "torchvision.models`") 库中吗? - CNN 解释器[31]:一个可视化网站让你瞬间弄懂什么是卷积网络。
感谢
感谢原作者 Daniel Bourke,访问https://www.learnpytorch.io/[32]可以阅读英文原文,点击原作者的Github仓库:https://github.com/mrdbourke/pytorch-deep-learning/[33]可以获得帮助和其他信息。
本文同样遵守遵守 MIT license[34],不受任何限制,包括但不限于权利
使用、复制、修改、合并、发布、分发、再许可和/或出售。但需标明原始作者的许可信息:renhai-lab:https://cdn.renhai-lab.tech/。
参考资料
[1]
PyTorch Computer Vision: https://www.learnpytorch.io/03_pytorch_computer_vision/
[2]
《使用PyTorch进行深度学习系列》课程介绍: https://cdn.renhai-lab.tech/archives/DL-Home
[3]
我的博客: https://cdn.renhai-lab.tech/categories/deep-learning
[4]
阅读原文: https://cdn.renhai-lab.tech/archives/DL-04-pytorch_computer_vision
[5]
FashionMNIST: https://github.com/zalandoresearch/fashion-mnist
[6]
torchvision: https://pytorch.org/vision/stable/index.html
[7]
torchvision.datasets: https://pytorch.org/vision/stable/datasets.html
[8]
它还包含一系列用于制作自定义数据集的Python类。: https://pytorch.org/vision/stable/datasets.html#base-classes-for-custom-datasets
[9]
torchvision.transforms: https://pytorch.org/vision/stable/transforms.html
[10]
torch.utils.data.Dataset: https://pytorch.org/docs/stable/data.html#torch.utils.data.Dataset
[11]
torch.utils.data.DataLoader: https://pytorch.org/docs/stable/data.html#module-torch.utils.data
[12]
原始 MNIST 数据集: https://en.wikipedia.org/wiki/MNIST_database
[13]
FashionMNIST: https://github.com/zalandoresearch/fashion-mnist
[14]
torch.utils.data.DataLoader: https://pytorch.org/docs/stable/data.html#torch.utils.data.Dataset
[15]
helper_functions.py: https://github.com/mrdbourke/pytorch-deep-learning/blob/main/helper_functions.py
[16]
TorchMetrics: https://torchmetrics.readthedocs.io/en/latest/
[17]
一个可视化网站让你瞬间弄懂什么是卷积网络: https://cdn.renhai-lab.tech/archives/cnn-explainer
[18]
CNN 解释器网站: https://poloclub.github.io/cnn-explainer/
[19]
nn.Conv2d(): https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
[20]
nn.MaxPool2d(): https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html
[21]
nn.Conv2d(): https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
[22]
nn.MaxPool2d(): https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html
[23]
CNN 解释器网页: https://poloclub.github.io/cnn-explainer/
[24]
torchvision.models: https://pytorch.org/vision/stable/models.html
[25]
06-PyTorch迁移学习:在预训练模型上进行训练: https://cdn.renhai-lab.tech/archives/DL-06-pytorch-transfer_learning
[26]
torchmetrics.ConfusionMatrix: https://torchmetrics.readthedocs.io/en/latest/references/modules.html?highlight=confusion#confusionmatrix
[27]
mlxtend.plotting.plot_confusion_matrix(): http://rasbt.github.io/mlxtend/user_guide/plotting/plot_confusion_matrix/
[28]
02-PyTorch工作流程基础知识: https://cdn.renhai-lab.tech/archives/DL-02-pytorch-workflow
[29]
麻省理工学院的深度计算机视觉简介讲座。: https://www.youtube.com/watch?v=iaSUYvmCekI&list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI&index=3
[30]
PyTorch 视觉库: https://pytorch.org/vision/stable/index.html
[31]
CNN 解释器: https://poloclub.github.io/cnn-explainer
[32]
https://www.learnpytorch.io/: https://www.learnpytorch.io/
[33]
https://github.com/mrdbourke/pytorch-deep-learning/: https://github.com/mrdbourke/pytorch-deep-learning/
[34]
MIT license: https://github.com/renhai-lab/pytorch-deep-learning/blob/cb770bbe688f5950421a76c8b3a47aaa00809c8c/LICENSE
[35]
我的博客: https://cdn.renhai-lab.tech/
[36]
我的GITHUB: https://github.com/renhai-lab
[37]
我的GITEE: https://gitee.com/renhai-lab
[38]
我的知乎: https://www.zhihu.com/people/Ing_ideas