使用Python获取某个时间段的深圳共享单车数据集完整教程【纯小白向】附常见问题、可导出为csv

使用Python获取某个时间段的深圳共享单车数据集完整教程【纯小白向】附常见问题、可导出为csv

本文目的是为了让不会代码的人能够快速的提取深圳市政府数据开放平台中的“深圳共享单车企业每日订单表””数据,甚至改改还能提取平台的其他数据。 相较于旧版本的方法,更新之后的文章不使用数据库,专注于提取某个时间段、某天的数据,并可以导出csv,不建议用此文的方法去获取全量数据,原因在后文会提到。 如果你想获取全量数据,可以参考高并发、多线程、包含数据库的新版本源代码Github:深圳共享单车 2.4 亿级数据获取与 PostGIS 分析流水线(适用于深圳市政府开放平台的大部分数据的获取)。如果你无法访问Github,可以使用Gitee镜像。
上期深圳市共享单车数据分析【文末附共享单车数据集清单】简单分享了如何使用共享单车数据进行数据分析,有很多人问如何才能获取数据,以及没学过 Python,如何获取?
接下来我把代码分享出来,你拿着我的代码,修改三个变量,就可以获取相应日期的深圳共享单车数据了。
1.数据集介绍
- 数据集概览:该数据集名为“深圳共享单车企业每日订单表”,来源于深圳市政府数据开放平台。它包含2021年1月至8月的部分共享单车订单信息,用户ID、开始时间、开始经度、开始纬度、结束时间、结束经度、结束纬度、企业ID共8个数据项,总计约2.4亿条记录。
- 获取子集: 可通过“startDate”和“endDate”参数限定时间范围,查询对应时间范围内的入库数据。格式yyyymmdd,示例:startDate=20240624&endDate=20240626。
2.获取方式
1)直接下载
如此大量的数据,直接下载的文件仅包含本数据集的前 10 万条数据,无法下载全部的数据,想获取某天的完整数据,只能通过Api的方式获取。
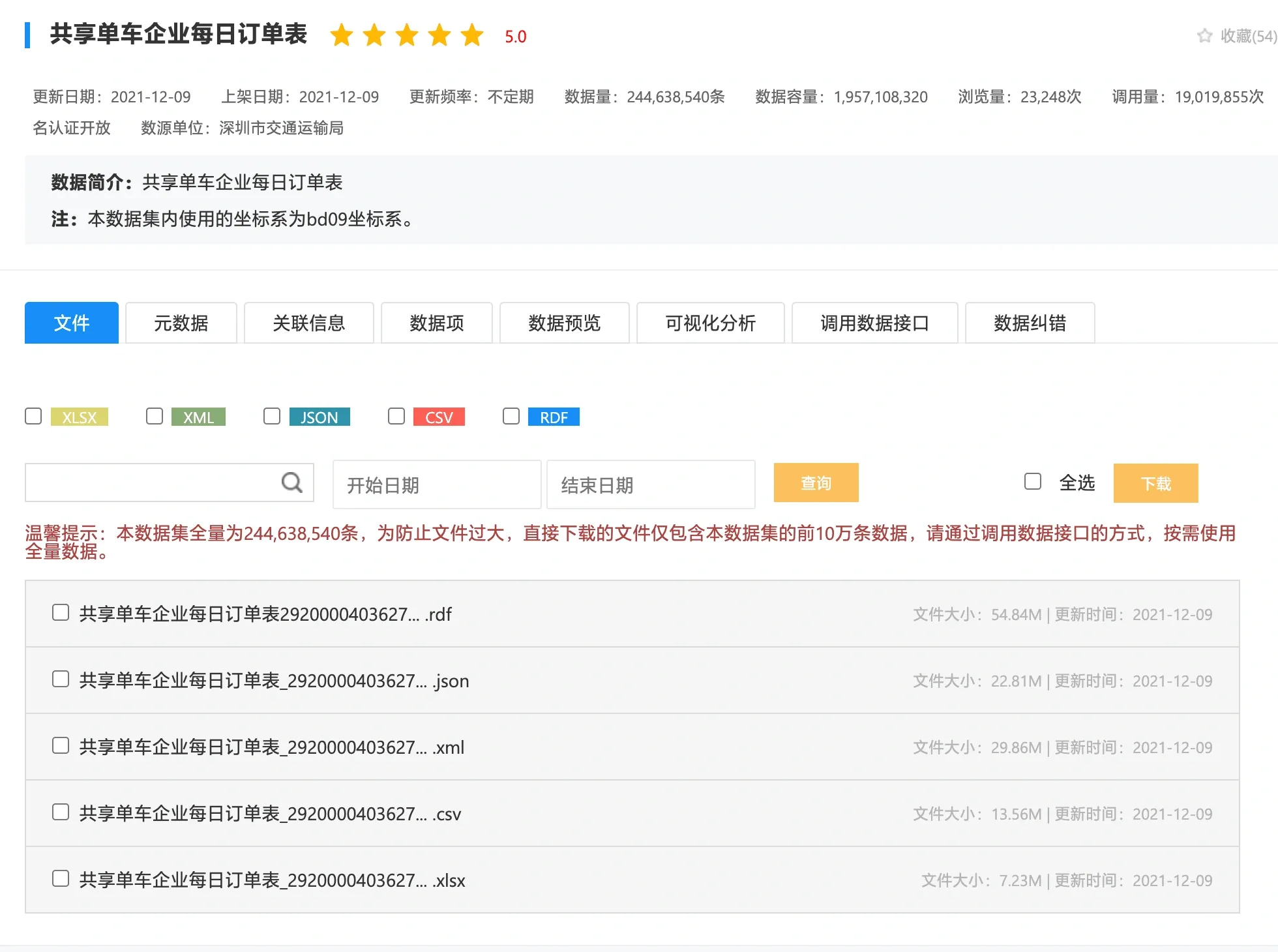
每条数据包含的字段:
USER_ID | 用户 id |
|---|---|
COM_ID | 企业 id |
START_TIME | 开始时间 |
START_LNG | 开始经度 |
START_LAT | 开始纬度 |
END_TIME | 结束时间 |
END_LNG | 结束经度 |
END_LAT | 结束纬度 |
2)调用 API 接口
深圳数据开放平台也提供调用数据接口的方式进行下载:
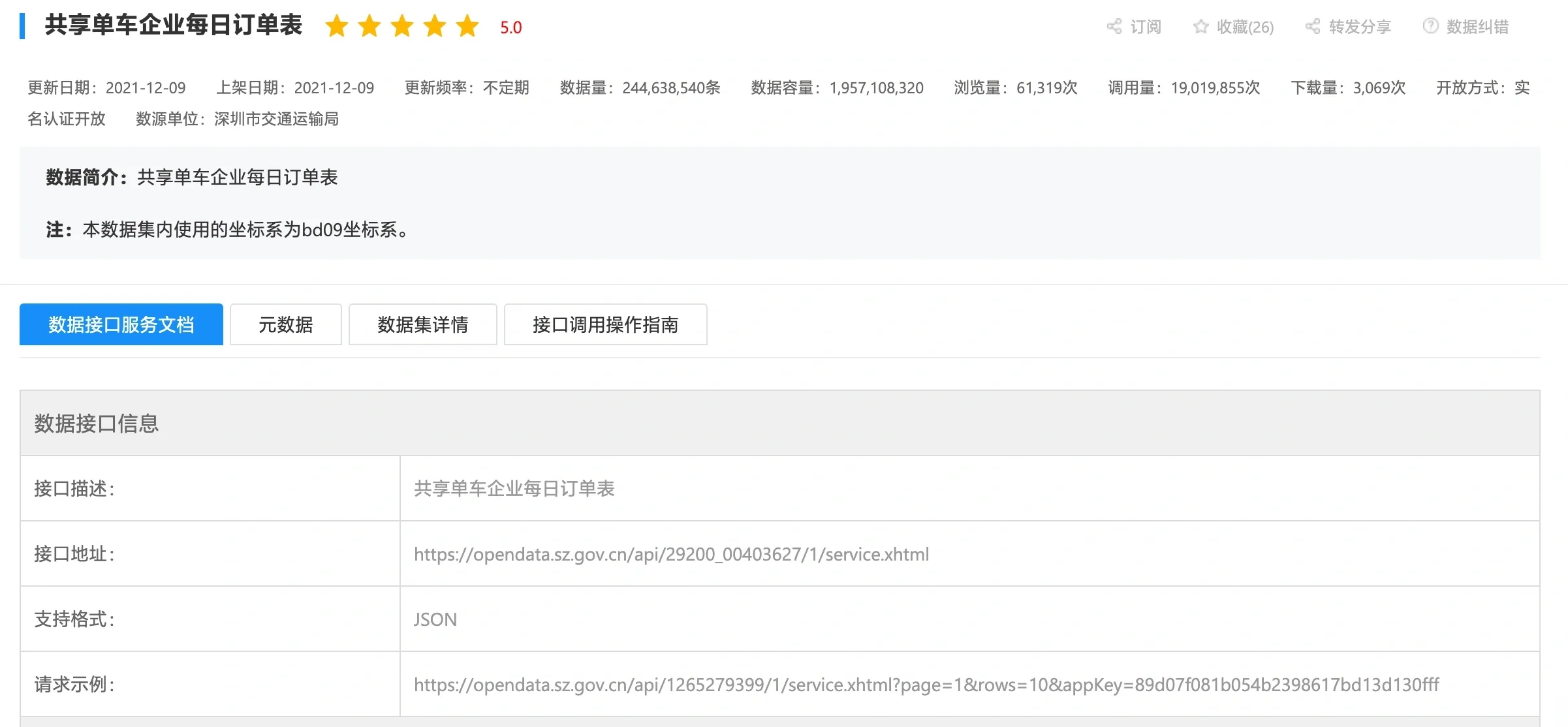
我们选用简洁性、受欢迎的 Python 来进行数据获取,使用的方法是requests库,或者可以使用http.client或第三方库如aiohttp(异步请求)。
👉 网站:https://opendata.sz.gov.cn/data/api/toApiDetails/29200_00403627)上提供了相应的【调用说明】:

登录网站,完成前两步:
根据提示填写相关信息,点击提交应用上传,提交成功后可在个人中心-我的应用-我的应用查看 appKey。
测试接口
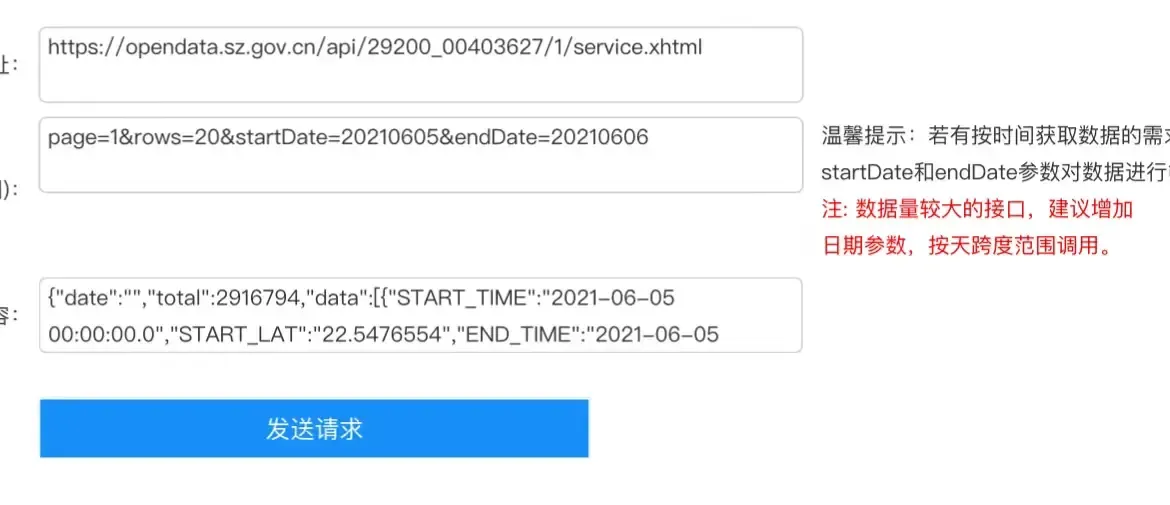
!!!若有按时间获取数据的需求,可通过增加 startDate 和 endDate 参数对数据进行筛选。
所以我们只需用 Python 写一个requests请求,然后将数据储存到数据库或者csv(表格)文档。
3.配置数据库(获取少量数据不需要)
如果你只想获取几天的数据,可以跳过这一步!
为什么数据库很重要
如果你需要储存整个数据集(2.4 亿条共享单车订单数据),不建议将数据保存在单个 Json 或 csv 文件中,因为一个超过电脑内存的文件根本无法一次性读取到内存中,更没办法查询,所以有的人会按照日期分多个子集保存。但是,多个分散的文件不利于维护,也不利于查询,如果只想获取某个共享单车企业的某个时间跨度内的内容,使用数据库就很高效,所以强烈建议选择数据库。
4.配置 python 环境
对于新手,千万不要使用 Anaconda管理环境,直接使用 python 安装包进行安装。
新手应该直接使用 Python 官方安装包,而不是 Anaconda,原因如下:
- 简化学习过程:避免了环境管理工具的复杂性,集中精力学习 Python 本身。
- 理解基础:帮助新手掌握如何配置环境、使用 pip 等基础技能。
- 节省资源:Anaconda 包含许多不必要的预安装包,直接安装 Python 更轻量。
- 灵活控制:可以自由选择所需的库和版本,减少依赖冲突。
直接从基础开始,可以为后续学习打下更坚实的基础。
当然,这并不是说 Anaconda 没有其优势,特别是在科学计算和数据分析领域,Anaconda 提供了许多便利。然而,对于刚开始学习 Python 的新手来说,直接从基础开始学习往往能提供更坚实的基础。随着学习的深入,可以根据需要选择更高级的工具和环境。 经过我几个月的uv项目管理器的使用经验,非常建议进阶的用户将uv作为Anaconda的替代品使用,非常快!
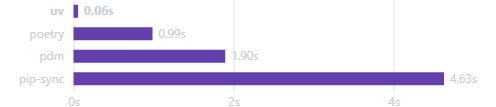
1)Windows 安装 Python
- 下载 Python:
- 访问 Python 官网。
- 选择适合 Windows 的 Python 版本进行下载(通常会自动推荐最新版本)。
- 安装 Python:
- 打开下载的安装程序。
- 重要:在安装过程开始时,确保选中“Add Python to PATH”选项,然后点击“Install Now”。
- 验证安装:
- 打开命令提示符(CMD)。
- 输入
python --version并按回车。如果安装成功,将显示 Python 的版本信息。
2)macOS 安装 Python
- 下载 Python:
- 访问 Python 官网。
- 选择适合 macOS 的 Python 版本进行下载。
- 安装 Python:
- 打开下载的
.pkg安装文件,然后遵循安装向导的指示完成安装。
- 打开下载的
- 验证安装:
- 打开终端(Terminal)。
- 输入
python3 --version并按回车。如果安装成功,将显示 Python 的版本信息。
5.安装依赖
pip 是 Python 的包管理工具,用于安装和管理 Python 包。以下是使用 pip 安装依赖的基本步骤:
1)确保安装了 pip
大多数现代 Python 安装都自带 pip。要检查 pip 是否已安装,可以在命令行或终端中运行以下命令:
pip --version如果 pip 已安装,该命令将显示 pip 的版本信息。如果没有安装 pip,您需要先安装它。安装方法依赖于您的操作系统,通常在 Python 官网上有详细的安装指南。
2)使用 pip 安装包
要使用 pip 安装一个 Python 包,可以在命令行或终端中使用以下命令格式:
pip install <package_name>本次环境需要在终端运行以下命令:
pip install pandas requests -i https://pypi.tuna.tsinghua.edu.cn/simple简要说明:
pandas: 一个强大的数据分析和处理库。requests: 用于发送 HTTP 请求的库,非常适合与 API 交互。-i https://pypi.tuna.tsinghua.edu.cn/simple这部分指定了一个自定义的包索引源,即清华大学提供的 PyPI 镜像。这个镜像源在中国大陆访问速度更快,有助于解决由于网络问题导致的慢速或失败的包安装问题。
6.准备代码
我们新建一个文件夹,比如就叫shenzhen_data,然后新建一个文本文件,重命名为main.py,之后用记事本打开,复制以下代码:
"""
深圳共享单车数据研究——获取数据(无数据库版,适合初学者)
数据名称:共享单车企业每日订单表
更新日期:2021-12-09 上架日期:2021-12-09
更新频率:不定期
数据量:244,638,540条
数据容量:1,957,108,320
开放方式:实名认证
开放数源单位:深圳市交通运输局
数据简介:共享单车企业每日订单表
说明:
- 本脚本不再依赖 MongoDB,数据将直接保存为 CSV 文件;
- 时间字段保留接口返回的原始本地时间字符串(不做时区转换);
- 按页追加写入 CSV,首页写入表头,其余页不写入表头。
"""
import time
from pathlib import Path
import pandas as pd
import requests
def _build_output_csv(start_date: str, end_date: str) -> Path:
"""根据日期范围生成输出 CSV 路径,位于项目 data 目录。"""
project_root = Path(__file__).resolve().parent.parent.parent
csv_dir = project_root / "data" / "raw"
csv_dir.mkdir(parents=True, exist_ok=True)
filename = (
f"bike_orders_{start_date}_{end_date}.csv"
if start_date != end_date
else f"bike_orders_{start_date}.csv"
) # 如果你要修改导出的csv的文件吗,请修改这里。
return csv_dir / filename
# 主函数
if __name__ == "__main__":
# 环境变量和初始化
app_key = "4xxxxxxxxxxxxxxxxxxxxxxxxxx5" # TODO: 替换为你从深圳开放数据平台申请的 app_key
page_num = 1
rows = 4000
# 日期范围 可以选择你要爬取的范围
startDate = "20210820" # TODO: 替换为你要爬取的开始日期,格式 YYYYMMDD
endDate = "20210820" # TODO: 替换为你要爬取的结束日期,格式 YYYYMMDD
url = "https://opendata.sz.gov.cn/api/29200_00403627/1/service.xhtml"
# 请求头 不加请求会被拒绝
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
"Accept": "application/json, text/javascript, */*; q=0.01",
}
# 输出 CSV
output_csv = _build_output_csv(startDate, endDate)
print(f"数据将保存到: {output_csv}")
# 数据请求和处理循环
while True:
params = {
"appKey": app_key,
"page": page_num,
"rows": rows,
"startDate": startDate,
"endDate": endDate,
}
response = requests.get(url, headers=headers, params=params)
if response.status_code != 200:
print(f"请求错误,状态码:{response.status_code}")
break
items = response.json().get("data", [])
if not items:
print("没有更多数据或数据为空,结束。")
break
# 将本页数据追加写入 CSV
df = pd.DataFrame(items)
write_header = (page_num == 1) and (not output_csv.exists())
df.to_csv(
output_csv, mode="a", index=False, encoding="utf-8-sig", header=write_header
)
print(f"已写入第 {page_num} 页,共 {len(df)} 条。")
# 判断是否继续
if len(items) < rows:
print("最后一页已写完。")
break
else:
page_num += 1
# 轻微休眠,避免请求过快
time.sleep(0.5)上述代码放在了github:fetcher-legacy.py
你需要修改三处代码:
app_key = "4137xxxxxxxxxxxxxxxx68d0d5" # <<<<<<<< 填写从深圳开放数据平台申请的app_key
startDate = "20210820" # TODO: 替换为你要爬取的开始日期,格式 YYYYMMDD
endDate = "20210820" # TODO: 替换为你要爬取的结束日期,格式 YYYYMMDD7.运行
在终端(命令提示符),定位到代码所在文件夹:
cd /path/to/shenzhen_data # TODO 修改为你的文件夾地址 如果有空格和特殊字符 请用英文引号如
cd "/my path/to/shenzhen_data"运行 Python:
python main.py查看输出,如下图所示则成功运行

8.查看数据
根据运行成功的文本定位到csv文件,用excel打开。
9.常见问题
为了集中讨论,欢迎在Github Issue上面提出问题。
(1)如何获取全量2.4亿条数据
深圳共享单车 2.4 亿级数据获取与 PostGIS 分析流水线(适用于深圳市政府开放平台的大部分数据的获取)
(2)数据字段相关:
参考官方的说明:
本数据集内使用的坐标系应该为 WGS1984 或者 GCJ02 😂。
你没看错,虽然官方标注的数据集为 bd09 坐标系,但是实测发现并不是。需要验证当日的坐标是否正确。
如果你感兴趣,欢迎查看另一文章文章:共享单车数据坐标系排查实录:从文档、测试到结论 | Ren...
并不是所有数据都有企业 id 字段。
(3)Python 学习相关
- 非编程专业如何快速入门 Python 数据分析与可视化
(4)用浏览器直接访问链接出错,但是使用 python 调用接口则有数据。
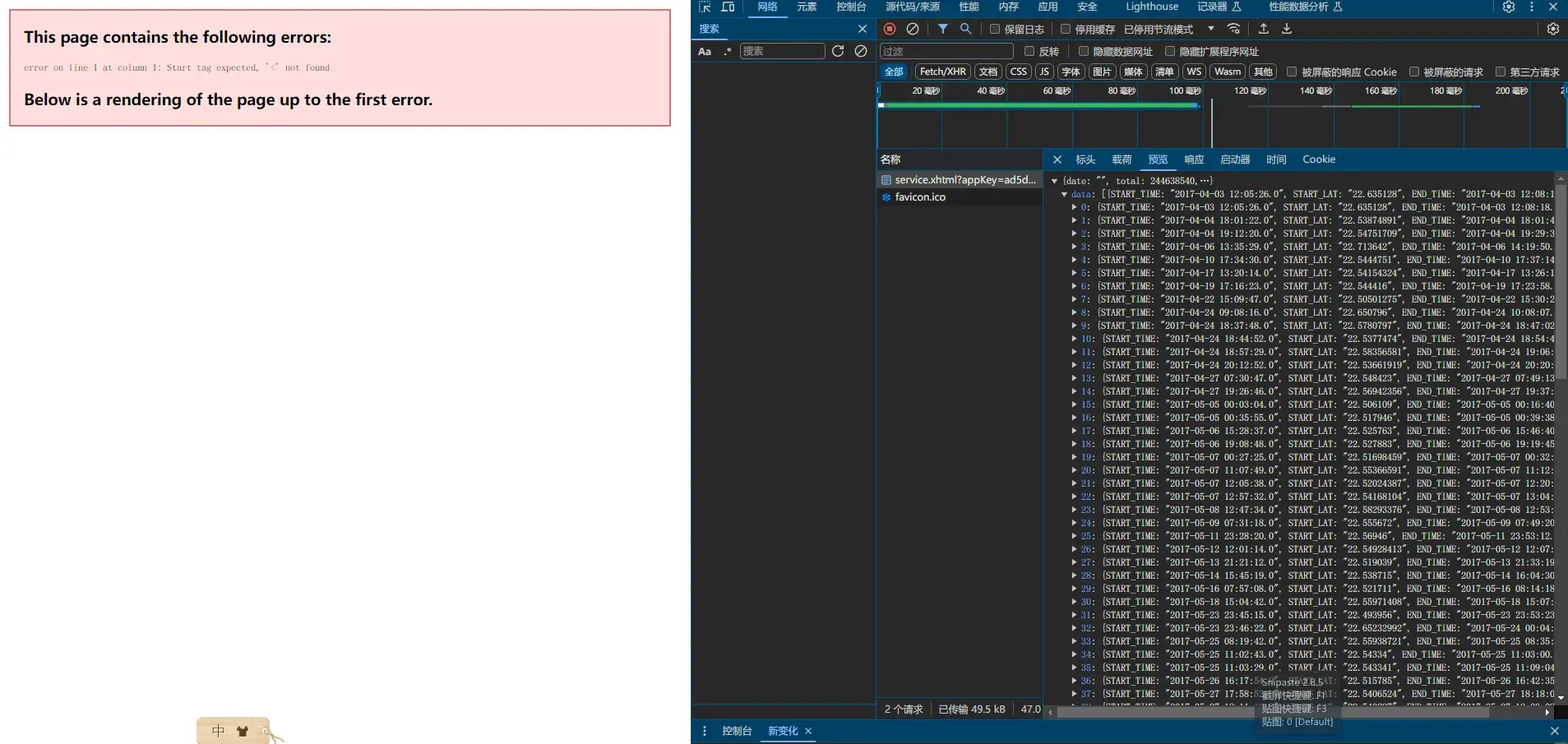
这属于正常“现象”。
这通常是因为浏览器预期得到的响应格式与实际返回的格式不匹配。这里提到的错误 这里提到的错误 Start tag expected, '<' not found'
指出浏览器正在尝试解析返回的数据作为 XML,但是它并没有找到期望的开始标签 <。
简单来说就是返回的是数据而不是 html 文件,浏览器无法渲染输出。按 f12 打开开发者菜单,找到如图所示的响应页面,可以查看链接返回的数据。
(遗留问题)无法查询到数据
- 如果你是看过我以前的文章,使用的mongodb储存数据,需要注意数据库里的时间是UTC时区的时间。
- 需要检查数据库中的日期字段(START_TIME)类型是 Date 还是 str 字符串,如果不是Date类型,最好进行类型转换,并创建START_TIME索引,加快检索速度。整个数据库2.4亿条数据进行字段的类型转换需要一定时间,如果图简便可以使用下面的方法:
# 如果数据库的START_TIME字段是字符串,则用下面的方法。
query = {
'START_TIME': {
'$gte': '2021-08-04 16:00:00', # 使用字符串比较
'$lt': '2021-08-05 16:00:00' # 使用字符串比较
}
}写在最后
支持
如果你也想直接获取全部的共享单车数据可以访问爱发电 · 完整的共享单车zip文件(非按照每日分类的单个json文件)支持我并获取国内(阿里云盘)下载链接。
按照每日分类的数据正在上传中......
如果你对本文章有什么意见、对如何制作文中的图表感兴趣、或者有其它任何问题建议在本文的博客评论区留言,说不定你的问题别人也遇到了。
本文在我的个人网站同步发布和更新,你可以在微信公众号中点击阅读原文跳转。
如果你也觉得这事儿有意思,给我一点反馈吧————点下赞、再看或者转发,让算法知道有人想看;
欢迎在评论区里疯狂吐槽你在 ArcGIS 里遇到的烦心事,或者聊聊你对这个系列、对哪个技术方向最感兴趣。你们的反馈会直接影响我后续内容的侧重点!
- 我的知乎
- 我的博客
- 我的 GITHUB
- 我的 GITEE
- RSS
腾讯云开发者
