ICLR 2023 | PatchTST : 谁说 Transformer 在时序预测中不如线性模型?
ICLR 2023 | PatchTST : 谁说 Transformer 在时序预测中不如线性模型?

预测是时间序列分析中最重要的一项任务之一。随着深度学习模型的快速发展,关于这个话题的研究工作数量也大幅增加。在深度学习模型中,Transformer在自然语言处理(NLP)、计算机视觉(CV)、语音等应用领域取得了巨大成功。近期在时间序列中也取得了成功,这得益于其注意力机制可以自动学习序列中元素之间的联系,因此成为序列建模任务的理想选择。
Informer、Autoformer和FEDformer是Transformer模型中成功应用于时间序列数据的最佳变体之一。然而,尽管基于Transformer的模型设计复杂,但最近的论文表明,一个非常简单的线性模型可以在各种常见基准测试中胜过之前所有的模型,这挑战了Transformer对于时间序列预测的实用性。
本文介绍一篇来自美国普林斯顿大学和IBM研究实验室的论文,也是ICLR 2023中的文章。作为Transformer-based预测模型,它是和计算机视觉中的ViT最相似的一篇论文。它成功超过了DLinear,也证明了DLinear中认为Transformer可能不适合于序列预测任务的声明是值得商榷的。
在该论文中,研究者提出了基于Transformer时序预测和时序表示学习新方法,将时间序列数据转换成类似Vision Transformer中的Patch形式,取得了非常显著的效果。下面为大家介绍具体方法。

论文地址:https://arxiv.org/abs/2211.14730
代码链接:https://github.com/yuqinie98/patchtst
核心思路 在这篇文章中,研究者提出了一种基于Transformer设计的有效模型,用于多变量时间序列预测和自监督表征学习。该模型基于两个关键部分:
- Patching:将时间序列分割成子序列级Patch,作为Transformer的输入token。这和Preformer中的核心思想很相似,只不过效果要比 Preformer 好不少。具体来说,它们都是将时间序列分成若干个时间段(Preformer 里用的术语是segment,本文用的是Patch,实际上是差不多的),每一个时间段视为一个token(这不同于很多Transformer-based 模型将每一个时间点视为一个token)。
- Channel-independence:多变量时间序列是一个多通道信号,模型的输入token可以由来自单通道或多通道的数据表示。Channel-independence意味着每个通道仅包含一个单变量时间序列,它们共享相同的嵌入和Transformer权重。这已被证明适用于CNN和线性模型,但尚未应用于基于Transformer的模型中。
Patch
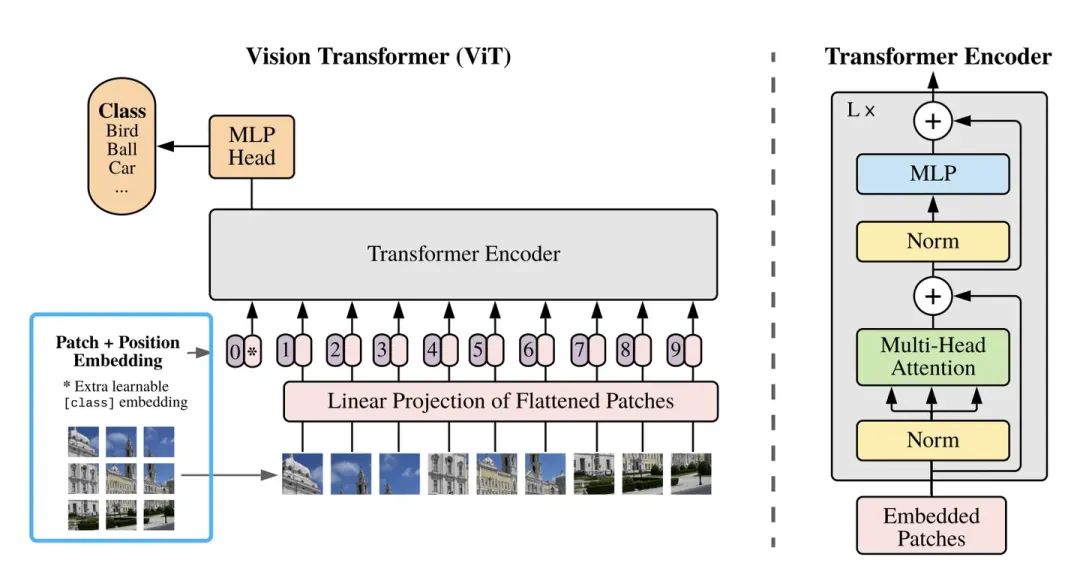
VIT(Vision Transformer)模型是视觉领域的重要模型,2020年由Google提出。在VIT中,"Patch" 是指将输入图像分割成均匀大小的小区域。这些小区域通常是正方形或矩形,并且被视为模型的基本单位。并且在输入到Transformer模型之前,通常会进行一些变换(如嵌入层),以便将它们转换为Transformer可接受的格式。每个图像块都被视为一个“标记”(token),它们被重新排列并输入到Transformer的注意力机制中进行处理,以捕获图像内部和区域之间的关系。如下图所示。
而在PatchTST中,“Patch”则是将输入时间序列按照一定大小的窗口和步长分割。并以分割形成的“时序块”作为输入,传输到Transformer进行建模的方式。
模型结构
PatchTST如下图所示,该模型使用Vanilla Transformer编码器作为其核心架构。
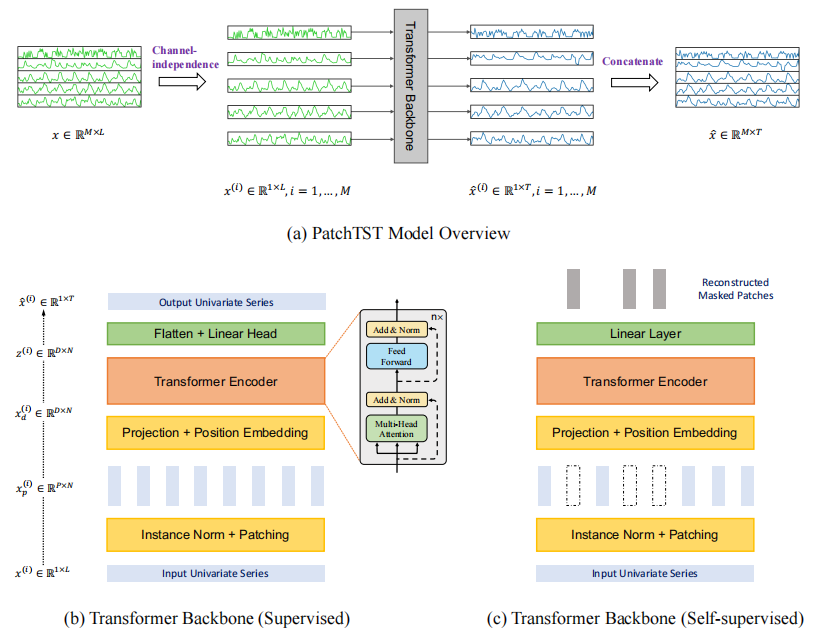
上图a展示的多元时间序列数据被分为不同的通道,它们共享相同的Transformer主干网络,但正向过程是独立的。图b为每个通道的单变量序列通过实例归一化操作符,并分割为多个Patch。这些Patch被用作Transformer的输入token。图c为使用PatchTST进行掩码自监督表示学习,其中随机选择patch并将其设置为零。模型将重建被掩码的Patch。
PatchTST模型对每个输入的单变量时间序列进行分割,形成Patch,这些Patch可以是重叠的或非重叠的。Patch长度为P,步长为 S(两个连续patch之间的不重叠区域),那么,Patch的数量可以表示为
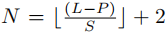
。通过Patch,输入的数量可以从 L 减少到大约
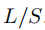
。而注意力机制的内存使用和计算复杂度是成平方减少的。
图b和图c所示的结构的区别在于:图b的结构最后进行了Flatten,然后进行预测。而在训练方法上的主要区别在于,图c通过随机赋值为0的方式遮盖了部分Patch,然后通过self-supervised重建被遮盖的数据。通过这种自监督学习的方式,模型可以更好地捕捉时间序列中的模式和特征。
自监督学习
自监督表示学习已成为从未标记数据中提取高层抽象表示的热门方法。在PatchTST中,研究者也是故意随机移除输入序列的一部分内容,并训练模型恢复缺失的内容。然而,不同于文本,如果我们不进行Patch,直接把时序数据输入则会存在两个潜在问题:
- 当前时间步的遮罩值可以通过与紧随前后的时间值进行插值轻易推断,而不需要对整个序列有高层次的理解,这与我们学习整个信号的重要抽象表示的目标不符合。
- 已知有 L 个时间步的表示向量,D维空间, M个变量,每个变量具有预测范围 T。则输出需要一个维度为 (L⋅D)×(M⋅T)的参数矩阵 。如果这四个值中的任何一个或所有值都很大,那么这个矩阵可能会特别大。当下游训练样本数量稀缺时,这可能导致过拟合问题。
但是进行Patch后可以自然地克服前面提到的问题,采用这种方式遮住的是“数据块”,而非数据点”。预测的也是一个Patch块,自然也就不存在插值的问题了。
实验结果
实验数据方面,研究者评估了文章提出的PatchTST在8个流行数据集上的性能,包括天气、交通、电力、ILI和4个ETT数据集(ETTh1、ETTh2、ETTm1、ETTm2)。这些数据集已被广泛用于基准测试并在(Wu et al., 2021)上公开可用。文章想重点介绍几个大型数据集:天气、交通和电力。它们具有更多数量的时间序列,因此与其他较小的数据集相比,结果会更稳定并且更不容易过度拟合。
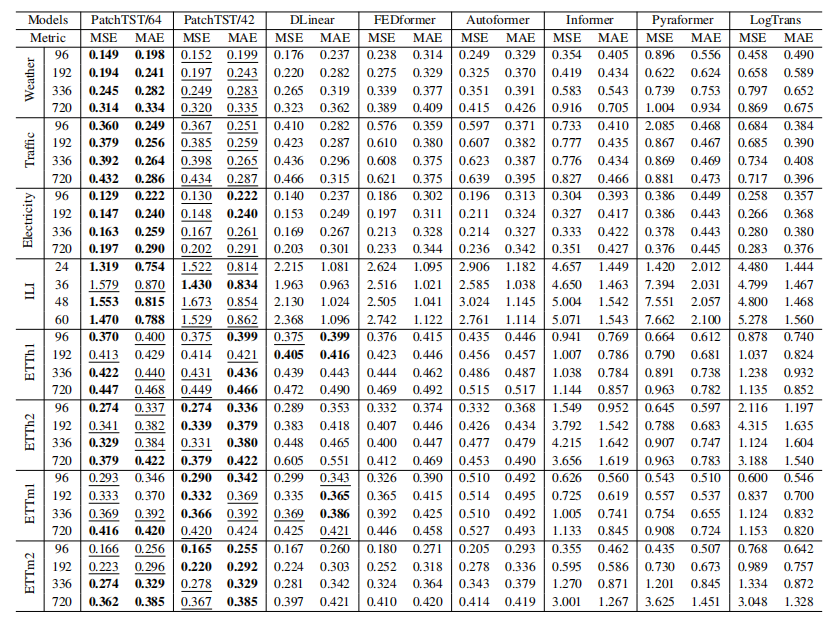
实验过程方面,首先在直接进行时序预测任务的对比实验中,对比了不同预测长度的效果,以及PatchTST使用不同历史序列长度的效果(64和42代表patch数,对应的使用的历史序列长度分别为512个336)。可以看到,首先PatchTST模型取得了非常显著的效果提升,其次使用更长的历史序列信息也会提升预测效果。
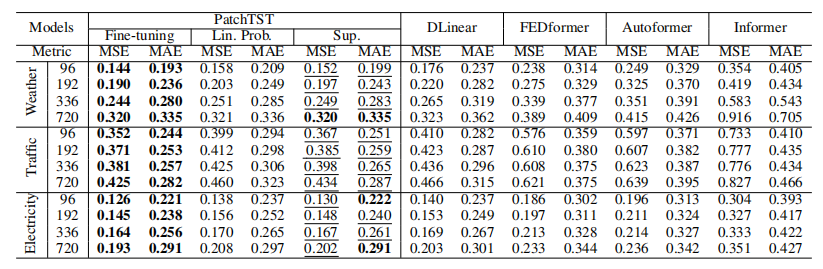
下图是引入预训练后的效果,引入预训练再进行finetune可以进一步提升PatchTST在时序预测上的效果。
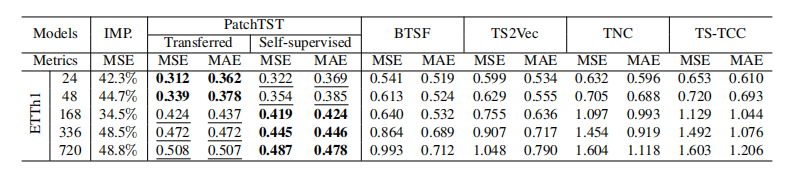
最后,文中也对比了PatchTST与不同时间序列预测表示学习方法的效果,也展现出了本文提出的表示学习方法在效果上的优越性。
总结
该论文提出了基于Transformer的模型的有效设计,用于时间序列预测任务,其中引入了两个关键组件:Patching和Channel-independence。与之前的工作相比,它可以捕获局部语义信息,并从更长的回溯窗口中受益。 研究者不仅证明
腾讯云开发者
