TEMPO:谷歌提出基于Prompt的预训练时序预测模型

在过去的十年里,深度学习在时间序列建模方面取得了重大进展。在取得最先进成果的同时,表现最佳的架构在应用和领域之间差异很大。同时,对于自然语言处理,生成式预训练Transformer (GPT) 已经通过跨各种文本数据集训练一个通用模型,展现出了令人印象深刻的性能。探索GPT类型的架构是否可以有效应用于时间序列,捕捉其内在的动态属性,并显著提高准确性,这是一件非常有趣的事。
本文介绍一篇谷歌与南加州大学联合发表的时间序列预测工作。该论文提出了一个新的框架TEMPO,它可以有效地学习时间序列表示。研究者利用时间序列任务的两个基本归纳偏置来训练模型:(1) 分解趋势、季节和残差分量之间的复杂相互作用;(2) 引入基于选择的提示,以促进非平稳时间序列中的分布适应。TEMPO扩展了从多个领域内的数据中动态建模现实世界时间现象的能力。

论文地址:https://arxiv.org/abs/2310.04948
论文源码:暂未公布
论文概要
研究者认为现有主干结构和语言模型中的提示技术并不能完全捕捉时间序列中时间模式的发展和相互关联动态的进展,而这些是时间序列建模的基础。
基于此,研究者开发了一个基于提示的生成预训练转换器用于时间序列,即TEMPO(Time sEries proMpt POol)。具体而言,TEMPO首先通过局部加权散点图平滑将时间序列输入分解为三个加性组件,即趋势、季节性和残差。然后,将这些时间输入映射到相应的隐藏空间,以构建生成预训练转换器的时序输入嵌入。研究者进行理论分析,将时间序列域与频域联系起来,强调分解这些组件对于时间序列分析的必要性。此外,还在理论上揭示了注意力机制很难自动实现这种分解。
第二,TEMPO利用提示池有效地调整GPT以进行预测任务,通过指导重用一系列可学习的连续向量表示,这些表示编码趋势和季节性的时间知识。这一过程允许通过将类似的时间序列实例映射到类似的提示来适应不断变化的时间分布,同时保持生成过程演变时的预测能力。此外,研究者利用时间序列数据的三个关键加性组件:趋势、季节性和残差,构建了一个广义加性模型(GAM)。
论文的主要贡献包括:
(1)介绍了一种基于提示调优的生成转换器TEMPO,用于时间序列表示学习。它进一步推动了时间序列预测的范式转变——从传统的深度学习方法到预训练的基础模型。
(2)通过关注两个基本归纳偏差来适应预训练模型:首先,研究者利用分解的趋势、季节性和残差信息。其次,采用提示选择策略来适应非平稳时间序列数据的动态性质。
(3)通过对七个基准数据集和一个提议的数据集进行大量实验,研究者提出的模型表现出优越的性能。值得注意的是,对跨域预训练的稳健结果,显示出所有预测长度平均MAE改善30.8%,突显了基础模型在时间序列预测领域的潜力。
模型介绍
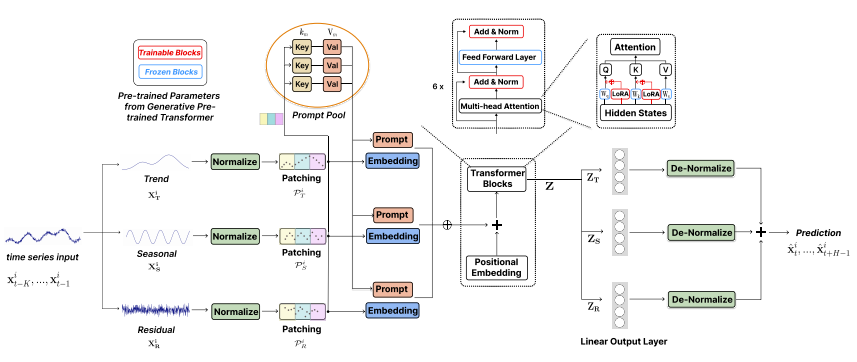
TEMPO-GPT的结构
多为时间序列预测任务的定义如下:
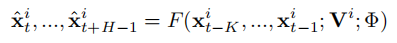
与常规的时序预测模型不同的是,研究者参考语言模型,在预测过程中为要预测的输入窗口添加了提示词
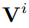
。
01
时间序列输入处理
在时间序列输入上,文中采用的是序列分解+Patch的形式。首先将时间序列分解成趋势项、季节项和残差,得到3个子序列。对于每个子序列,在归一化后,使用Patch的方式分别进行处理,得到3个子序列的Patch embedding。
02
Prompt设计
以前的工作主要集中在利用固定的提示来通过微调提高预训练模型的性能。考虑到现实世界时间序列数据通常的非平稳性以及分布变化,该方法引入了一个共享的提示池,这些提示被存储为不同的键值对。
理想情况下,研究者希望模型利用相关的过去经验,其中相似的输入时间序列往往会从池中检索相同的提示组。这将允许模型在单个时间序列实例输入的级别上有选择地回忆最具有代表性的提示。
此外,这种方法可以提高建模效率和预测性能,因为模型将更好地识别和应用通过共享表示池在不同数据集上学习的模式。提示池中的提示可以编码时间依赖性、趋势或与不同时间段相关的季节性效应。具体来说,提示池中的提示键值对被定义为:
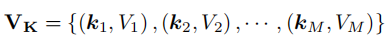
其中,M表示提示词的个数,
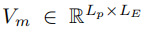
表示单个提示词,
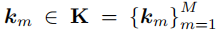
与注意力机制中的Key相同,与序列编码得到的embedding进行相似度计算,即:
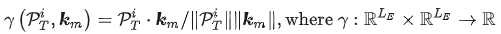
基于
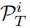
根据上述计算,将从提示词集合中找到k个与本序列相关的提示,并将提示词与原始序列的embedding进行拼接得到最终有关趋势项的输入:
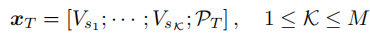
03
Transformer预训练
Transformer预训练模型,采用的是经典的GPT结构,主要区别在于引入了LoRA结构,用来适配不同类型时间序列数据的分布。其中,趋势项、季节项、残差的embedding拼接到一起输入Transformer,然后每个时间步分别预测3个部分的结果。最终分别做反向归一化再相加后,得到预测结果。
实验结果
实验部分,文中对比了与Transformer类型模型、大语言模型、线性模型、TimesNet等多种类型模型在长周期时间序列预测中的效果,本文提出的模型都取得了比较显著的提升。此外,也对比了在0样本学习中的效果(即在Transformer上使用一些数据集预训练,再使用另一部分数据进行预测评估),也取得了显著效果。
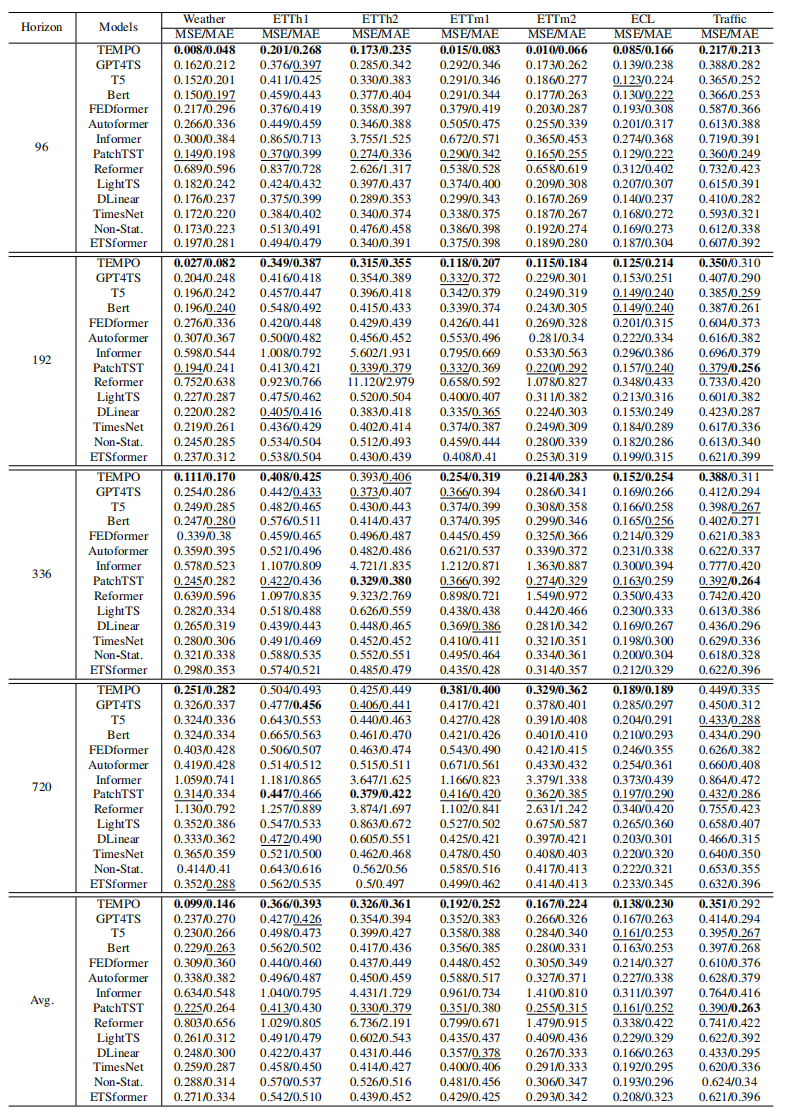
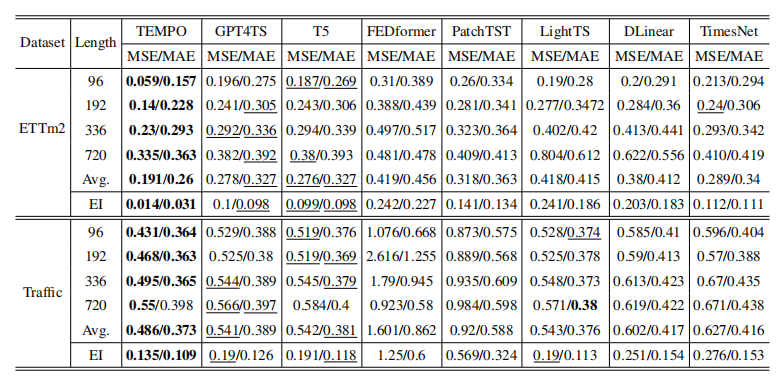
此外,对于单个数据集,TEMPO的效果还是表现不错的。traffic数据集不同于模型之前遇到的任何数据,而TEMPO也优于所有基准模型,实现了最低的MSE和MAE。
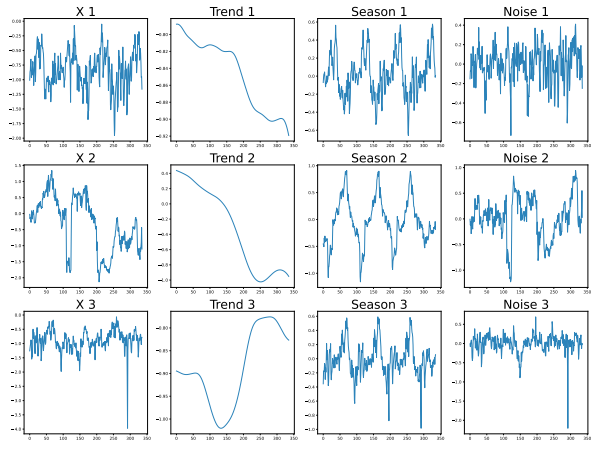
这种预测方法,也保证了模型的可解释性,可以生成趋势项、季节项、残差3个部分的预测结果,文中也给出了一些case(如下图):
结论
该论文提出了一种基于提示选择的生成转换器TEMPO,它在时间序列预测中实现了最先进的表现。研究者引入了新颖的集成提示池和季节性趋势分解,结合预训练的基于Transformer的主干,使模型能够根据时间序列输入相似性,专注于从相关过去时间段适当地回忆知识,考虑到不同的时间语义成分。此外,研究者还展示了TEMPO在多模型输入方面的有效性,有效地利用时间序列预测中的上下文信息。最后,通过广泛的实验,强调了TEMPO在准确性、数据效率和泛化性方面的优势。值得进一步调查的一个潜在限制是,具有更好数值推理能力的先进LLM可能产生更好的结果。研究者认为,从文中的跨域实验中可看出,这项工作的一个潜在未来轨迹是进一步开发时间序列分析的基础模型。

点击下方名片关注时序人
设为星标,快速读到最新文章
欢迎投稿
转载请联系作者
觉得不错,那就点个赞吧

腾讯云开发者
