TPAMI 2023 | 检测时间序列边界的通用框架:Temporal Perceiver
TPAMI 2023 | 检测时间序列边界的通用框架:Temporal Perceiver

我们能否在一个通用的检测框架中解决不同语义层次的自然时序边界检测?
这里分享一篇来自TPAMI 2023的论文,研究者提出了一种对视频中一类因为语义不连贯而自然产生的时序边界 (Generic Boundary) 的通用检测方法,基于 Transformer Decoder 建立了一个编码器-解码器结构,希望解决对任意自然时序边界的检测问题。具体内容我们一起来看看。

论文地址:https://arxiv.org/abs/2203.00307
论文源码:https://github.com/MCG-NJU/TemporalPerceiver
论文概述
通用边界检测(GBD)旨在定位将视频划分为语义连贯且不受分类学限制的单元的一般边界,并可作为长格式视频理解的重要预处理步骤。
先前的工作通常使用从简单CNN到LSTM的特定设计的深度网络来分别处理不同类型的通用边界。相反,本文提出了Temporal Perceiver,这是一种具有Transformer的通用架构,为任意通用边界的检测提供了一体化解决方案,包括镜头级、事件级和场景级GBD。
核心设计是通过跨注意力块引入一小组潜在特征查询作为锚点,将冗余的视频输入压缩到固定维度。由于这个固定数量的潜在单元,它将注意力操作的二次复杂度大大降低到输入帧的线性形式。
方法介绍
研究者提出了一种基于Transformers的Temporal Perceiver,用于有效定位长格式视频中的任意通用边界。给定一个未修剪的视频X,Temporal Perceiver 预测一个自然边界集合
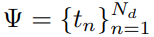
来定位视频中的边界真值
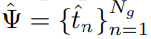
,其中
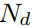
为预测边界的数量,
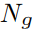
为视频中gt边界的数量。
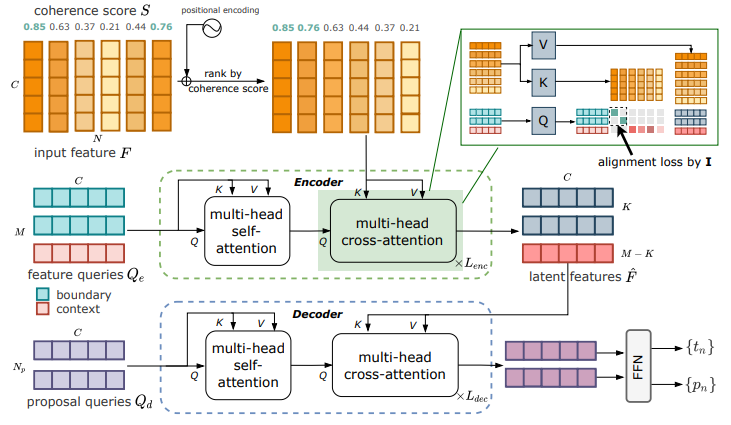
上图展示了 Temporal Perceiver 模型结构:
该模型采用 backbone 网络,从原始视频中抽取逐帧的RGB特征
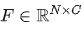
和连贯性打分(coherence scores)
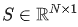
, N为视频帧数量、C为通道数量。连贯性打分是一个度量当前时序位置是否为边界的分数, 研究者基于每帧的连贯性打分对当前视频帧特征
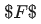
进行分数从大到小的重排序。连贯性分数越高的帧越大概率为时序边界, 排列在序列的前部。此外,研究者也为每个时序位置构造了基于
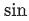
函数的位置编码,和RGB特征一起被重新排序后送入网络。
实验效果
研究者分别在镜头级别 (shot-level)、事件级别 (event-level)和场景级别 (scene-level)的generic boundary benchmark上进行了测试,并与过往工作进行性能对比。
01
镜头级别
对于镜头切换检测,研究者选择了基于足球赛事的 SoccerNet-v2[6]数据集上的 camera segmentation benchmark 进行测试。
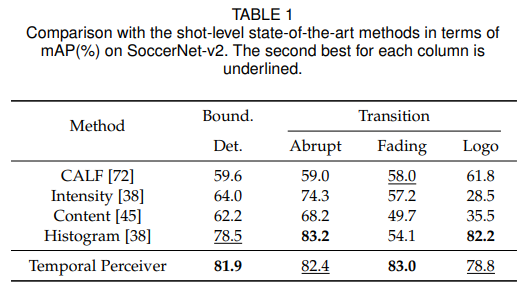
02
事件级别
对于事件转换检测,研究者在基于日常行为视频的Kinetics-GEBD数据集和基于奥林匹克体育赛事的TAPOS数据集上进行测试。
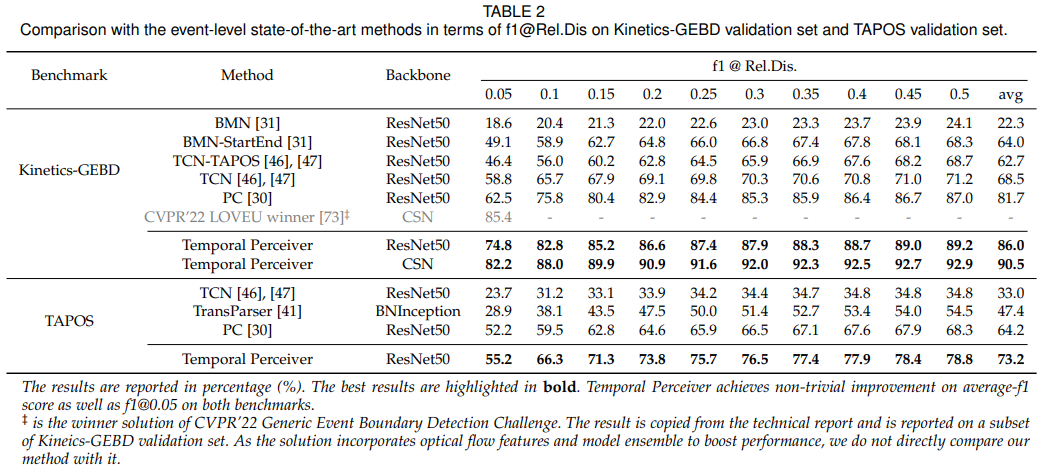
上表给出了该模型方法在两个数据集上和过往工作的对比。
结果表明,研究者的方法在较小的Rel.Dis阈值(较小的误差容忍度)下轻松超越了当前最佳方法。此外,研究者还提供了使用CSN主干网络的Temporal Perceiver在Kinetics-GEBD上的结果,以显示其模型的性能上限。这也证明了TP模型在使用图像编码器和视频编码器主干网络时,都能产生更精确和准确的边界预测。
03
场景级别
研究者使用平均精度(AP)和Miou来评估检测到的场景边界的质量,其中Miou计算了相对于其与最近地面真实场景的距离的检测场景的交集除以并集的加权和。
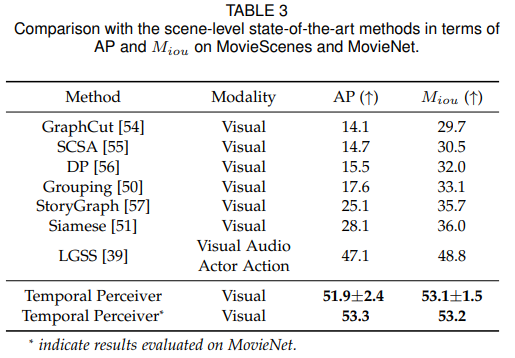
与最先进方法的比较。在上表中,研究者将Temporal Perceiver与MovieScenes上的当前最佳方法进行了比较。
为了计算平均精度,研究者构建了以稀疏预测的边界位置为中心的高斯分布,以近似每个视频的密集分数序列。基于近似密集分数报告AP。仅使用视觉模态,Temporal Perceiver将AP提高了4.8%,Miou提高了4.3%。这一显著提升证明了TP模型在各种粒度下进行通用边界检测时的泛化能力和有效性。
论文中还展示了消融实验、efficiency比较和结果可视化等信息,感兴趣的朋友可自行查阅论文。

点击下方名片关注时序人
设为星标,快速读到最新文章
欢迎投稿
转载请联系作者
时间序列学术前沿系列持续更新中 ⛳️
腾讯云开发者
