yolov5小目标检测-提高检测小目标的检测精度

yolov5小目标检测-提高检测小目标的检测精度

机器学习AI算法工程
发布于 2024-02-05 17:35:12
发布于 2024-02-05 17:35:12
向AI转型的程序员都关注了这个号👇👇👇
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
YOLOv5的网络结构

github 链接 https://github.com/ultralytics/yolov5
下载之后按照其中的README.md文件进行配置和设置。
YOLOv5数据集的设置
对yolov5/data/buy.yaml文件进行配置
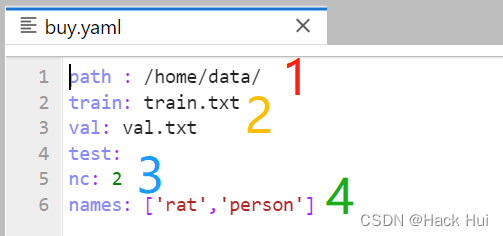
其中 1:yours数据集的根目录
2:代表生成yolo要求的txt文件
3: 你需要识别的类别数
4:你识别类别的名称
小目标检测的难点
当前的检测算法对于小物体并不友好,体现在以下4个方面:
过大的下采样率:假设当前小物体尺寸为15×15,一般的物体检测中卷积下采样率为16,这样在特征图上,过大的下采样率使得小物体连一个像素点都占据不到。
过大的感受野:在卷积网络中,特征图上特征点的感受野比下采样率大很多,导致在特征图上的一个点中,小物体占据的特征更少,会包含大量周围区域的特征,从而影响其检测结果。
语义与空间的矛盾:当前检测算法,如Faster RCNN,其Backbone大都是自上到下的方式,深层与浅层特征图在语义性与空间性上没有做到更好的均衡。
SSD一阶算法缺乏特征融合:SSD虽然使用了多层特征图,但浅层的特征图语义信息不足,没有进行特征的融合,致使小物体检测的结果较差。
提高小目标检测的基本思想
1、数据加强 2、滑动窗口检测:将图片分割为n个小区域分别检测,最后在concat成正常图像大小。本文也是主要介绍这种思想。
相关代码



只需要对yolo下的yaml文件进行如上的配置,就可以大大地提高小目标监测的精度,但是处理时间可能会有所上升。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-01-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号