ICLR 2024 | FTS-Diffusion:针对金融时序中不规则特征的生成学习
ICLR 2024 | FTS-Diffusion:针对金融时序中不规则特征的生成学习

对于金融应用中的深度学习模型,训练数据有限是一个大问题。因为金融时间序列有不规则和尺度不变的特点,很难合成真实数据。
本文介绍一篇来自ICLR 2024的论文,作者开发了一个新的生成框架FTS-Diffusion,将金融时间序列生成分解为模式识别-生成-演化过程,以更好地模拟不规则和尺度不变属性。

论文标题:Generative Learning for Financial Time Series with Irregular and Scale-Invariant Patterns
论文地址:https://openreview.net/forum?id=CdjnzWsQax
论文源码:暂未公布
论文概述
论文作者提出了FTS-Diffusion,这是一个用于合成具有不规则和尺度不变模式的金融时间序列的生成框架。作者将具有挑战性的金融时间序列生成分解为模式识别-生成-演化方案。为了促进这一过程,并设计了三个专用模块:
(1)模式识别模块,利用提出的SISC算法设计,用于识别这些模式;
(2)模式生成模块,使用基于扩散的网络合成模式的各个部分;
(3)模式演变网络,用于将生成的片段以适当的时间演化组装在一起。
实验结果证实了FTS-Diffusion在合成与观测数据相似的金融时间序列方面的有效性,并证明了其对下游任务的实用性。据我们所知,这是首次生成包含不规则和尺度不变模式的复杂而关键的时间序列,这为金融领域以外的多个领域提供了广泛的潜在应用。
总体来看,该论文有三大贡献:
- 识别并定义了金融时间序列的两个属性:不规则性和尺度不变性。
- FTS-Diffusion的独特架构旨在处理不规则性和尺度不变性。
- 证明了FTS-Diffusion在捕获真实世界金融数据方面的有效性,并说明了生成数据对于下游应用的价值。
模型框架
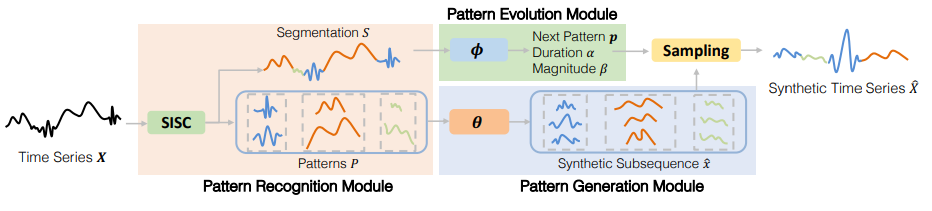
FTS-Diffusion框架
01
模式识别
识别不规则和尺度不变的模式
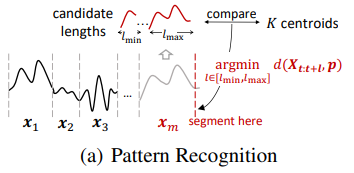
作者提出了一个新的尺度不变子序列聚类(SISC)算法,将整个金融时间序列划分为长度可变的段,并将它们分组为K个不同的簇。同一簇内的段在经过适当的持续时间和幅度缩放后呈现出相似的形状。然后,每个簇的质心表示金融时间序列中的尺度不变模式。
这个想法类似于传统的K-Means聚类,它主要对相同长度的段进行聚类,在这种情况下无法处理长度和幅度不同的段。因此,作者没有像通常那样将时间序列划分为等长度的段,而是通过简单而有效的贪婪分割策略自适应地确定最佳段长度。
02
模式生成
学习模式条件下的时序动态
作者设计了一个模式生成模块,即FTS-Diffusion框架图中的θ。该模块的目的是合成模式的片段,生成新的片段,模仿观察到的片段中的时序动态。考虑到金融时间序列是一组尺度不变的模式,数据生成过程可以解释为捕获参考模式的分布,并在持续时间和幅度上通过适当的尺度进行变换。因此,使用两个专用网络实现这一数据生成过程。
第一个网络是模式条件下的扩散网络,用于模拟受模式影响的随机过程——通过在N个步骤中逐渐添加噪声来逐渐扰动模式表示,直到它变成纯噪声(扩散),然后通过在相同步骤中逐渐去除噪声来恢复原始表示的纯噪声(去噪)。扩散过程是通过逐步增加高斯噪声的预指定程序实现的,而去噪过程由一个神经网络近似,该神经网络学习在每个步骤中去除噪声,即去噪梯度。近似逐步去噪梯度相当于学习从潜在的高斯空间到模式空间的映射。因此,给定一个高斯噪声,可以生成一个模式表示。高斯空间的连续性意味着可以采样无限数量的高斯噪声并产生相应的新模式表示。基于DDPM构建了这个扩散网络。具体来说,对观察到的片段应用以下扩散过程以将其破坏为纯噪声:
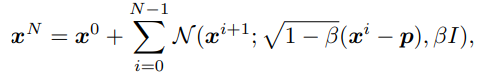
其中,β表示各段的大小。再设计一个条件去噪过程,该过程在
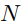
个步骤中从先验高斯噪声中恢复目标时序动态,该噪声以参考模式为条件:
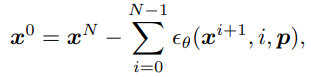
第二个网络是缩放自编码器(AE),用于学习使用模式条件下的扩散网络捕获参考模式表示后,可变长度段
和固定长度表示

之间的转换。缩放自编码器的编码器将可变长度段拉伸为与参考模式维度对齐的固定长度表示。另一方面,解码器负责从固定长度表示中重构可变长度段。
03
模式演变
模拟模式的时序转换,以便将生成的片段进行聚合,合成整个金融时间序列。
首先,从训练数据中采样一个初始段。然后,使用模式生成模块和模式演变模块迭代生成后续的段。这一过程将持续到合成数据达到所需的总长度。
在每次迭代中生成一个段时,首先使用模式演变网络预测下一个模式、其长度缩放因子和幅度缩放因子,这些预测决定了即将出现的段的特征。接着,使用模式生成模块根据预测的模式和缩放因子生成该段。生成的段被追加到合成的时序数据中,重复此过程直到达到所需长度。
通过利用学到的模式及其时序动态,该方法可以生成金融时间序列,这些序列展现出随时间推移的逼真模式演变。进而能够创建可用于各种金融任务的合成数据,例如模拟市场行为、训练交易算法或评估金融风险模型。
实验效果
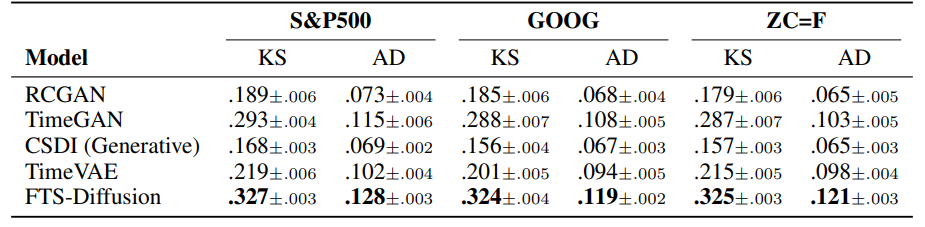
来自三个真实数据集的实验结果表明,在几种替代模型中,FTS-Diffusion生成了最接近真实的金融时间序列。
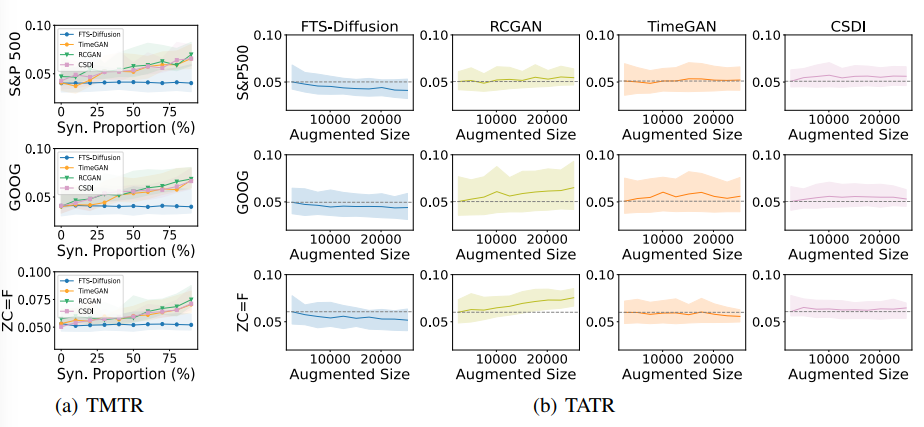
随着更多的来自FTS-Diffusion的合成数据添加到训练集中,预测误差呈下降趋势。添加100年的合成数据将三个资产的MAPE分别降低了17.9%、15.3%和17.4%。相比之下,当使用其他基线生成合成数据时,预测误差要么增加,要么基本上保持不变。
总结展望
该工作通过探索金融时间序列的内在属性(如不规则性和尺度不变性),为复杂的金融时间序列的生成提供了新的广阔视角。作者认为未来有前景的研究方向是将该工作扩展到更具有挑战性的问题设置,例如包含多个时间序列之间交互依赖的多元建模。该方法可以处理由模式数量的变化引起的潜在分布偏移,扩展后的方法可能能够解决模式之间转换的偏移。
腾讯云开发者
