Nat Commun|知识引导的分子表示学习预训练框架


2023年11月21日,清华大学曾坚阳教授(西湖大学教授)、赵诞老师团队,在Nature Communications上发表文章A knowledge-guided pre-training framework for improving molecular representation learning。

作者提出了知识引导的预训练图Transformer (Knowledge-guided Pre-training of Graph Transformer,KPGT),这是一个自监督学习框架,可以学习可泛化和鲁棒的分子表示。KPGT框架集成了专门为分子图设计的图Transformer和知识引导的预训练策略,以充分捕获分子的结构和语义知识。通过计算测试,KPGT在预测分子性质方面表现出卓越的性能,在药物发现中具有实际适用性。总的来说,KPGT可以为推进人工智能辅助药物发现过程提供强大而有用的工具。
背景
学习有效的分子特征表示,便于分子性质预测,对药物发现具有重要意义。近年来,人们对通过自监督学习技术进行预训练的图神经网络(GNN)产生了极大的兴趣,以克服分子性质预测中数据稀缺的挑战。
然而,目前基于自监督学习的方法存在两个主要障碍,一是缺乏定义良好的自监督学习策略,二是GNN的容量有限。
方法
KPGT框架(图1)包括两个主要组成部分:一个称为线形图Transformer(Line Graph Transformer, LiGhT)的主干模型和一个知识引导的预训练策略(图1a)。LiGhT可以全面捕捉分子图结构中的复杂图案(图1b),将分子线形图作为输入,以充分利用化学键的固有特征,这些特征在先前定义的Transformer结构中通常被忽略。此外,为了精确建模分子的结构信息,在多头注意模块中引入了两个位置编码模块,即距离编码模块和路径编码模块。
LiGhT是建立在一个经典的Transformer编码器上的,它由多个Transformer层组成,通过多层感知器层输出,进行知识预测和掩膜节点预测。知识引导预训练策略是基于掩膜图模型的目标,该目标最初随机屏蔽分子图中的节点子集,随后学习预测这些掩膜节点(图1a)。KPGT纳入了额外的知识作为分子标签,为预测掩膜节点提供指导。这种机制使模型能够有效地捕获分子图中的结构和语义信息。利用ChEMBL数据集中的大约200万个分子使用知识引导的预训练策略对LiGhT进行预训练。然后将迁移学习应用于预训练的LiGhT模型,以执行下游分子性质预测任务。在LiGhT模型之上集成了一个多层感知器作为预测器。根据预训练的LiGhT模型参数是否可训练,迁移学习方法可以分为两种设置:微调(图1c)和特征提取(图1d)。
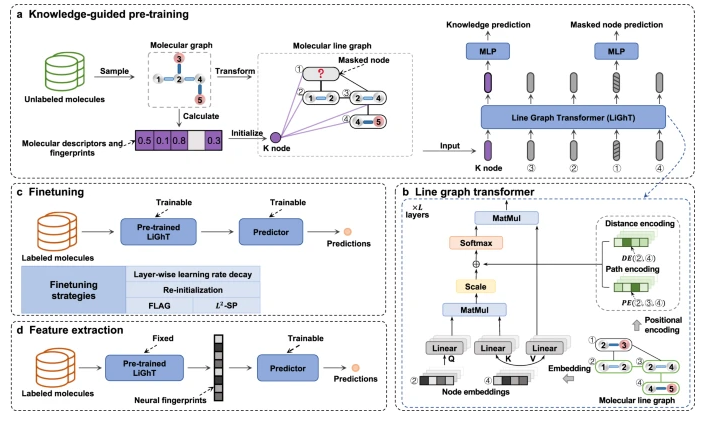
图1 KPGT结构图
如图1a所示,给定分子的SMILES表示,首先将其抽象为分子图,节点集合代表原子,边的集合代表化学键,通过RDKit中的分子描述符和指纹初始化分子图中节点和边的特征。为了充分利用分子的结构信息,特别是在先前定义的Transformer结构中被忽略的化学键,对分子图进行了掩膜节点变换,得到分子线形图。作者提出了线形图Transformer(LiGhT)来编码分子线形图的特征。LiGhT是建立在一个经典的Transformer编码器上的,它由多个Transformer层组成,通过多层感知器层输出,进行知识预测和掩膜节点预测。
如图1b所示,由于直接应用经典的Transformer架构会导致分子结构信息的严重丢失,作者采用路径编码和距离编码模块将结构信息引入多头自注意层。在分子线形图中,路径编码模块首先找到节点之间的最短路径,然后将路径特征编码为一个注意力尺度。距离编码模块则利用节点对之间的距离来进一步编码分子线形图的空间特征。最终注意力矩阵为原始注意力编码矩阵、路径编码矩阵与距离编码矩阵的和。
如图1c所示,在本研究中,知识定义为表征分子特征的任何可量化信息。这包括各种类型的信息,如分子描述符和指纹,很容易通过RDKit等化学信息学工具访问。此外,知识可以包含分子的实验测量特征,例如预处理ChEMBL数据集中的分子的生物活性的综合信息。这些知识可作为分子标签。LiGhT的预训练策略基于生成式自监督学习方案,该方案首先在图中随机选择一定比例的节点。然后,对于每一个被选中的节点,以8:1:1的比例替换为掩模令牌、随机节点或未更改的节点。预训练后,下游预测器模型通过交叉熵损失来学习预测原始节点的类型。在预训练中,还随机屏蔽K个节点的一定比例的初始特征,以在下游任务学习预测被屏蔽的分子描述符和指纹。其中,掩膜分子描述符的预测是一个回归任务,而指纹的预测是一个带有交叉熵损失的二值分类任务。
为了充分利用在预训练阶段捕获的丰富知识,KPGT引入了四种微调策略,包括分层学习率衰减(LLRD)、重新初始化(ReInit)、FLAG和L2-SP。LLRD和ReInit的提出主要是基于模型的不同层捕获不同类型的信息,其中底层倾向于编码与下游任务更通用的信息,而顶层倾向于编码与预训练任务相关的信息。更具体地说,LLRD实现了模型不同层的判别学习率。这是通过设置顶层的初始学习率并使用乘法衰减率从上到下逐层降低初始学习率来实现的。在微调之前,ReInit重新初始化模型的顶层参数。FLAG是一种数据增强方法,它通过在微调过程中注入基于梯度的对抗扰动来迭代增强节点特征。L2-SP提出了一种正则化方案,在微调过程中显式地提高了微调模型与初始模型的相似性。
如图1d所示,另一种迁移学习策略是特征提取,预训练结束后,固定LiGhT的权重,继续训练下游任务的预测器模型,进行输出预测结果。
结果
作者将KPGT与一些具有代表性的方法进行了比较,如图2所示。在采用特征提取(图2a)和微调(图2b)两种策略时,采用三折交叉验证(n=3),KPGT在分类任务上具有最高的AUROC,在回归任务上具有最低的RMSE,超越了现有的方法。在ADMET预测任务上(图2c),KPGT预测结果在所有任务上均排名前六,在大多数任务上排名第一。在30个分子(采用留一交叉验证,n=30)的活性悬崖估计(molecule activity cliff estimation,MoleculeACE)问题上,KPGT在所有分子组成的数据集(图2d)和由活性悬崖附近分子组成的数据集(图2e)上均具有最低的RMSE。
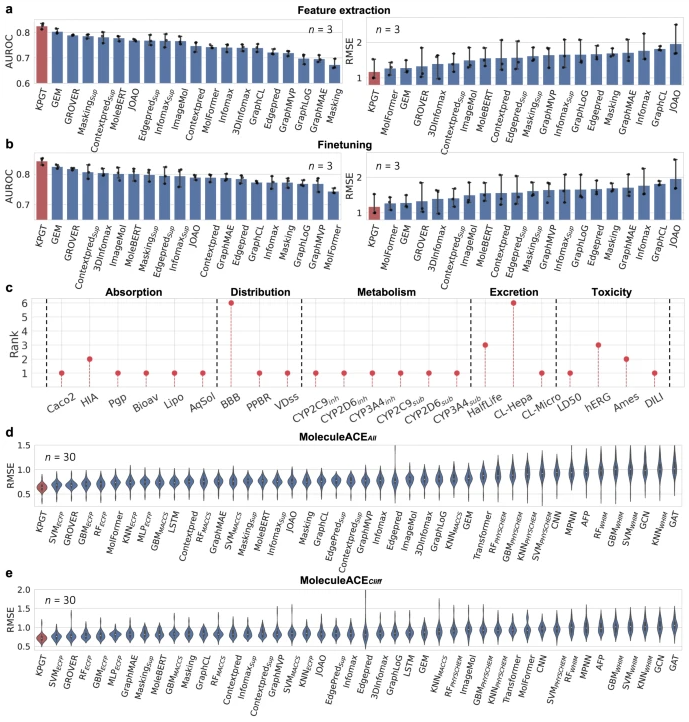
图2 与其他方法对比
作者设计了模型消融实验。为验证KPGT提出的预训练分子表示策略的有效性,作者以KNN为基础,将其与KPGT和其他的分子表示策略相组合,包括两种经典的分子指纹RDKFP和ECFP,以及两种基于GNN的分子表示GROVER和GraphCL,不同的分子表示策略在图3中以不同颜色表示。采用三折交叉验证(n=3),对于KNN中不同的K值,KPGT在分类任务上具有最高的AUROC和准确度(图3a),在对MolLogP等多个指标的回归预测中具有最高的斯皮尔曼相关系数(图3b)。作者取200个分子构建一个单独的测试集,验证KPGT和GROVER以及GraphCL三种基于GNN的分子表示与RDKFP或ECFP的斯皮尔曼相关系数,直方图如图3c所示。KPGT在更多分子上与传统指纹具有更高的相关性。
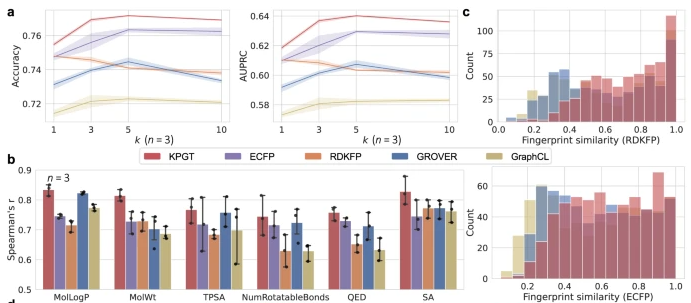
图3 消融实验
作者还进行了案例分析。本研究收集了4442个具有实验确定的抗HPK1效价的分子,以最大半数抑制浓度(pIC50)的负对数进行测量。使用三种不同的数据集分割方法(包括按分子骨架进行分割、按时间进行分割,按领域迁移进行分割)全面评估了KPGT在该数据集上的预测性能(图4b-d)。结果表明,KPGT在皮尔逊相关系数方面显著优于基线方法。值得注意的是,即使在训练集和测试集的分子结构显著不同的时间分割和领域迁移场景中(图4a), KPGT也始终获得较高的相关分数。这些观察结果验证了KPGT在预测HPK1抑制剂方面优越的通用性和可靠性。
接下来,作者利用KPGT通过药物重新定位来鉴定潜在的HPK1抑制剂。首先获得了从DrugBank76收集的2718种FDA批准的药物(表示为FDA数据集)。然后在pIC50 HPK1抑制剂数据集上对KPGT进行了微调,并对来自FDA数据集的分子进行了预测。补充表11报告了以往研究对KPGT前20个预测的实验证据。结果显示,20种药物中有12种被先前的实验验证为HPK1的潜在抑制剂。作者给出了其中排名前10的分子的TSNE降维分布和分子结构(图4e)。
进一步,Autodock vina对KPGT的前20个预测进行了对接分析,参考蛋白配体结构(PDB ID: 7SIU80)指导了结合口袋的识别。如图4f所示,所有分子的对接能量都低于-7kcal/mol,这是类药物分子常用的阈值,这表明这些分子即使有一部分尚未被文献报道,但也具有作为HPK1抑制剂的巨大潜力。
此外,作者使用一种蛋白质-配体相互作用分析工具PLIP,对分子的蛋白质-配体相互作用进行了深入分析。图4g显示了Gilteritnib配体与蛋白HPK1的蛋白质-配体相互作用谱。分析显示配体和蛋白质之间形成了三个疏水相互作用和六个氢键。值得注意的是,参考蛋白配体结构(PDB ID: 7SIU80)中也报道了与残基94A和97A形成的氢键。这些观察结果表明,这些分子可以与HPK1紧密结合,验证了对接结果的可靠性。
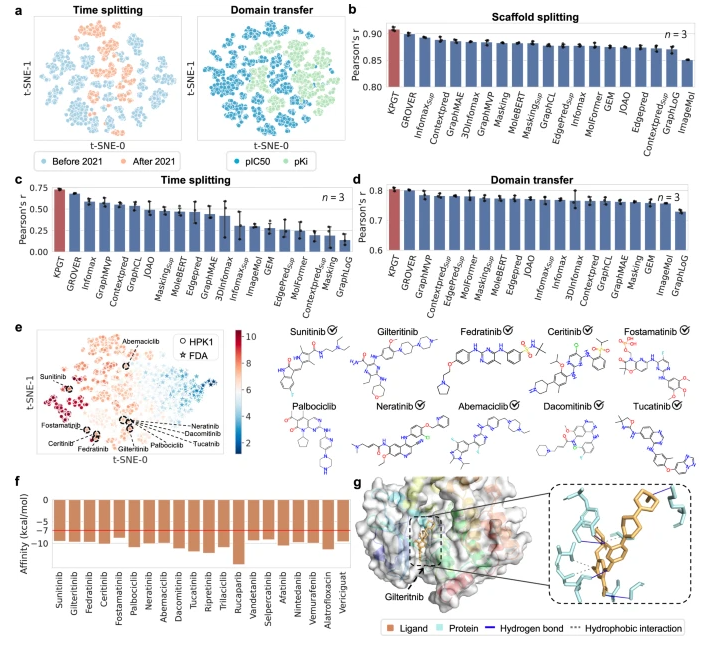
图4 案例分析
总结
在本研究中,作者提出了KPGT,这是一个自监督学习框架,通过显着增强的分子表示学习提供改进的、可推广的和鲁棒的分子性质预测。通过利用称为LiGhT的高容量骨干模型,KPGT全面捕获分子图中的固有结构信息。更重要的是,KPGT引入了一种知识引导的预训练策略,可以鲁棒地解决以前定义不清的预训练方法的局限性,使模型能够提供语义丰富的分子表示。此外,KPGT结合了几种微调策略,有效地整合了从预训练模型中获得的知识,从而提高了下游分子性质预测任务的性能。
尽管KPGT在有效预测分子性质方面具有优势,但仍存在一些局限性。首先,附加知识的集成是KPGT最显著的特征。除了在KPGT中使用的分子描述符外,还可以纳入各种其他类型的其他附加信息知识。此外,进一步的研究可以将三维(3D)分子构象整合到预训练过程中,从而使模型能够捕获有关分子的重要3D信息,并潜在地增强表征学习能力。此外,虽然KPGT目前使用了大约1亿个参数的骨干模型,以及200万个分子的预训练,但探索更大规模的预训练可以为分子表示学习提供更实质性的好处。总的来说,KPGT将为加速人工智能辅助药物发现提供一个通用的自我监督学习框架。
参考文献
[1] Li et al. A knowledge-guided pre-training framework for improving molecular representation learning. Nat Commun. 2023
--------- End ---------
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-12-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号