AAAI 2024 | DiffShape:基于时序 Shapelets 的扩散模型
AAAI 2024 | DiffShape:基于时序 Shapelets 的扩散模型

半监督时间序列分类可以有效地缓解标记数据缺乏的问题。然而,现有的方法通常忽略了模型的解释性,使得人类难以理解模型预测背后的原理。Shapelets是一组具有高度解释性的判别子序列,可用于时间序列分类任务。基于Shapelets学习的方法已显示出有前景的分类性能。遗憾的是,在没有足够的标记数据的情况下,通过现有方法学习的Shapelets通常判别性较差,甚至与原始时间序列的任何子序列都不相似。
本文介绍一篇来自由华南理工大学、大连理工大学联合发表的论文,目前已被AAAI 2024接收。该工作提出了用于半监督时间序列分类的Diffusion Language Shapelets 模型(DiffShape),有效解决了上述问题。

论文标题:Diffusion Language-Shapelets for Semi-supervised Time-Series Classification
论文地址:https://www2.scut.edu.cn/_upload/article/files/3e/ad/9dd713894e5e84c910f2f03a804a/29c80cf8-ed6f-4032-b3c7-f3717bc4f22d.pdf
论文源码:https://github.com/qianlima-lab/DiffShape
论文概述
在这篇论文中,研究者为半监督时间序列分类提出了Diffusion Language-Shapelets 模型(DiffShape)。与许多现有的时间序列SSC方法不同,DiffShape会为每个时间序列自动生成 Shapelets,从而提高了解释性。
具体来说,DiffShape结合了两种机制。第一种是基于真实子序列作为扩散条件的自监督学习机制,增加了生成的Shapelets与原始子序列之间的相似性。第二种是对比语言Shapelets学习机制,旨在提高生成的Shapelets的判别性。通过结合这两种机制,DiffShape在训练过程中有效地利用了时间序列的文本描述和分类器的分类信息,使得生成的Shapelets在提高分类性能方面更加有效。
最后,研究者在UCR时间序列档案上进行了广泛的实验,结果表明,所提出的 DiffShape方法在分类性能和可解释性方面均优于现有的时间序列SSC方法。
模型框架
DiffShape的插图如下图所示。DiffShape结合了两种机制:(i)自我监督的扩散学习;(ii)对比语言-shapelets学习。
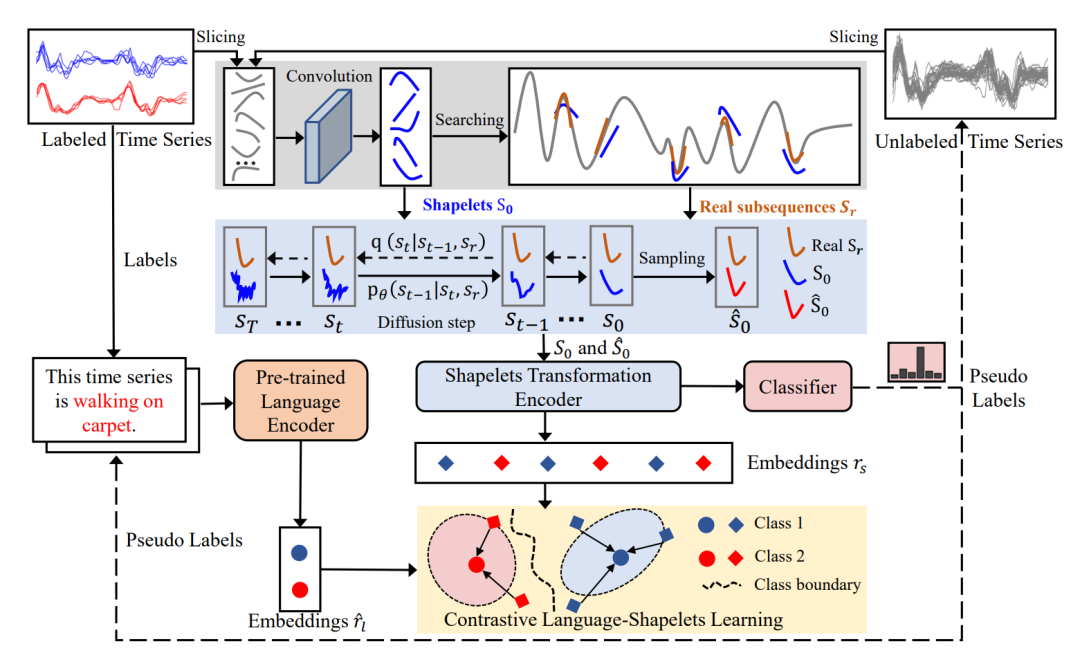
对于前者,首先使用固定的滑动窗口对所有标记和未标记的时间序列进行切片以提取真实的子序列。这些真实的子序列被送入卷积层以获取学习到的shapelets(表示为
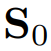
)。然后,计算
与每个时间序列的所有真实子序列之间的相似度,以寻找一组最相似的真实子序列,表示为
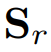
。
最后,将
和
送入一维U-Net 网络
进行自我监督学习。值得注意的是,DiffShape 使用
作为扩散条件来指导模型生成shapelets
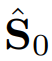
。
在对比语言-shapelets学习中,首先使用
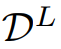
中标记样本的标签和
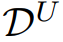
中未标记样本的伪标签为时间序列生成自然语言描述。然后,一个冻结的预训练语言编码器将生成的文本描述转换为嵌入
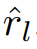
。同时,采用shapelet转换编码器将
和
转换为嵌入
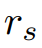
。最后,使用对比学习来最小化
和
之间的距离,并将
输入到分类器中进行训练。
01
Shapelet生成的扩散
为了提高在无标记数据的情况下生成的shapelets的可解释性,研究者设计了一种基于每个时间序列的最相似真实子序列的自我监督扩散学习机制。
这个机制包括2个部分:寻找相似的真实子序列、Shapelet扩散。
- 寻找相似的真实子序列
即使用长度为
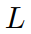
的滑动窗口对
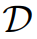
中的时间序列样本进行切片,以获得所有可能的子序列。时间序列
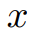
可以表示为
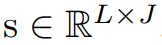
。将
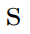
输入到卷积层中以得出
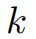
个shapelets
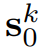
进行分类。此外,利用每个时间序列的
和
中的所有真实子序列
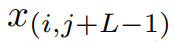
来计算它们的相似性,公式如下:
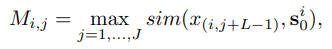
- Shapelet扩散
DiffShape的扩散过程通过结合前向和逆过程来实现。在前向过程中,向shapelets添加噪声以创建扩散样本。然后在逆过程中,使用这些扩散样本和真实子序列作为条件来训练模型生成与真实子序列相似的shapelets。通过这种方式,DiffShape可以利用未标记数据来提高shapelets的可解释性,并在没有标签的情况下发现时间序列数据中的有用模式。
02
对比性语言-Shapelets学习
讨论对比性语言shapelets学习机制如何增强生成shapelets的辨别力。
- 自然语言构建
在这个过程中,研究者利用时间序列的标签信息,结合预定义的文本模板,为每个样本生成了自然语言描述。这样做的目的是为了将时间序列的标签信息融入到对比学习中,使得模型能够更好地理解和利用这些标签信息。对于未标记的数据,采用伪标签的方法,选择分类器预测的高置信度软标签作为伪标签,以减少错误标签对分类性能的影响。通过这种方法,研究者成功地构建了自然语言描述,并将其用于对比学习中,以提高时间序列分类的性能和可解释性。
- 语言-shapelets训练
这个训练目标鼓励模型将同一类的shapelets和自然语言描述嵌入到相近的空间中,而将不同类的嵌入推开。通过这种方式,模型可以学习到更具判别力的shapelets表示,从而提高时间序列分类的性能。同时,利用自然语言描述的语义信息还可以增强模型的可解释性,因为shapelets可以直接与自然语言描述相关联。
03
整体训练过程
回看上面的模型框架图,DiffShape利用
和
,通过公式:
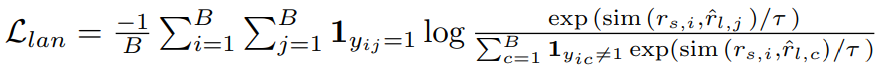
进行对比语言-shapelets学习。另一方面,
被输入到分类器中以进行
分类训练。对于伪标记的样本,伪标记被用作训练的真实标记。实际上,分类器由一层线性神经网络组成。因此,整体训练目标如下:
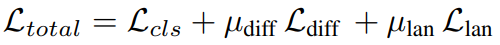
其中
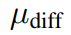
和
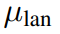
的值在[0,1]范围内,它们是用于调整训练损失比的超参数。为了在整个模型训练过程中增加shapelets的多样性,研究者引入了一个正则化项
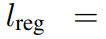
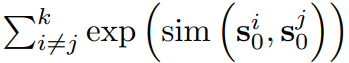
到
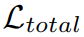
中,以增加不同shapelets之间的差异。
实验效果
研究者使用了UCR时间序列存档来评估所提出的方法。与先前的时间序列SSC工作类似,选择了106个UCR时间序列数据集进行实验。
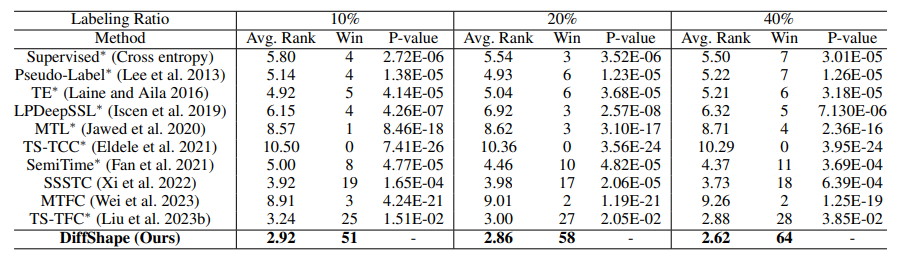
在106个UCR时间序列数据集上,DiffShape在不同标记比例下实现了最佳的分类性能。
在基准方法中,MTL和MTFC都采用了无监督的时间预测损失来学习未标记数据,但未能提高模型的分类性能。SemiTime和SSSTC使用时间预测损失作为一致性正则化策略,在时间序列半监督分类的背景下证明是有效的。与有监督方法相比,Pseudo-Label和TS-TFC使用伪标记技术,可以有效地缓解缺乏标记数据的问题。此外,研究者应用Wilcoxon符号秩检验来评估测试分类准确率的显著性。结果表明,DiffShape的分类性能显著优于所有考虑的基准方法(P值<0.05)。
下图是在标记比例为10%的ArrayHead数据集上shapelet的可视化,其中DiffShape的测试准确率为72.3%。

更多的实验效果及细节可以自行查阅论文了解。
腾讯云开发者
