AutoTimes:利用LLM重新定义自回归时间序列预测

鉴于模态和任务目标之间的共性,大语言模型(LLM)自然可以作为时间序列的基础模型。然而,先前的方法可能忽视了时间序列与自然语言对齐的一致性,导致未能充分利用LLM的潜力。
本文介绍一篇来自清华大学软件学院的论文,研究者为了充分利用从语言建模中学习到的通用标记转换,提出了AutoTimes。该方法将LLM重新定位为自回归时间序列预测器,同时保持了与LLM获取和利用的一致性,而无需更新参数。

论文标题:AutoTimes: Autoregressive Time Series Forecasters via Large Language Models
论文地址:https://arxiv.org/abs/2402.02370
论文源码:https://github.com/thuml/AutoTimes
论文概述
研究者提出的AutoTimes确保了与LLM能力的一致性,从而使自回归预测器作为时间序列的基础模型。这种一致性包括:
(1)训练和推理:采用与LLM获取一致的训练目标,即下一个标记预测,以建立包含局部序列变化的时间序列段标记化。在推理过程中,利用LLM的可变上下文长度和自回归生成能力来处理任意长度的序列;
(2)参数:利用LLM的标记转换,这是通过在大量文本语料库上进行训练来参数化的,并将其应用于时间序列标记。从技术上讲,研究者冻结了重新利用的LLM的Transformer层,并建立了时间序列的标记器和去标记器,占总参数的最多0.1%。除了提高适应效率外,还旨在实现时间序列的同胚嵌入,以便在标记级别无缝地与文本混合。
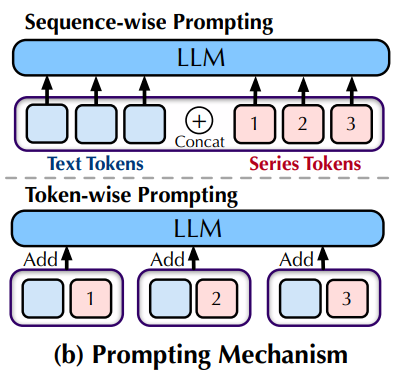
在此基础上,研究者引入了下图(b)所示的标记级提示,它利用时间序列的关联文本锚点(时间戳)来进一步增强预测。虽然之前连接不同模态的序列级提示可能导致序列长度过长和标记差异,但研究者的预测器结合标记级提示和上下文学习可以利用指导性文本和时间序列,以应对更广泛的预测场景。
该工作的贡献可以概括如下:
• 深入探讨了时间序列和自然语言之间的模态对齐,以利用LLM的标记生成能力作为现成的预测器。
• 提出了AutoTimes,这种简单有效的方法可以在不改变任何参数的情况下重新利用LLM。它将时间序列标记化为LLM的嵌入空间,并有效利用固有的标记转换来预测时间序列的自回归。 • 与最先进的方法相比,重新利用的预测器在无需针对特定序列长度进行训练的情况下实现了具有竞争力的性能,并进一步展示了由LLM赋予的零样本泛化能力、上下文学习能力以及多模态可用性。
模型方法
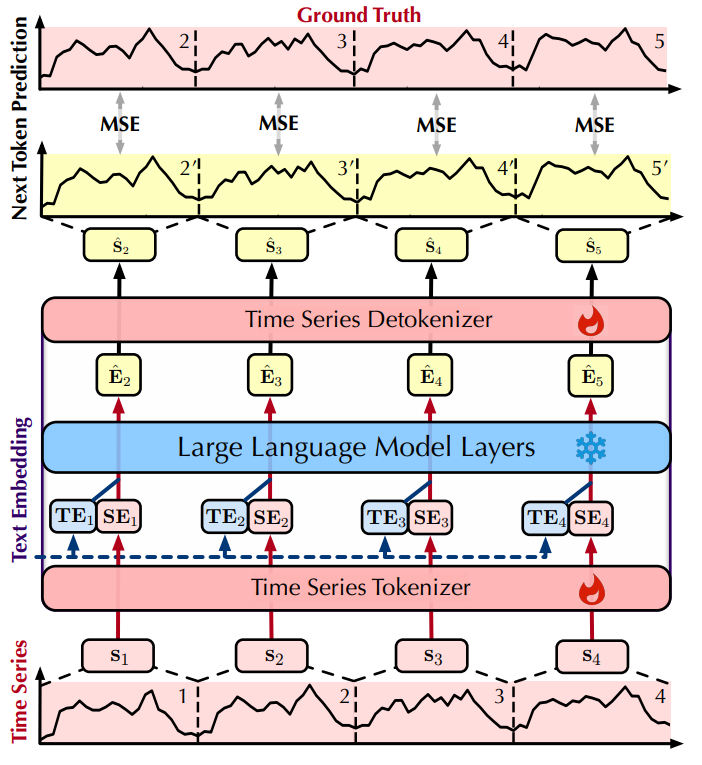
研究者提出的AutoTimes方法旨在将大语言模型重新用于多元时间序列预测,上图为AutoTimes框架图。
给定回溯观测值
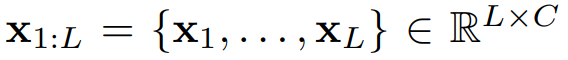
,其中
表示时间步长,
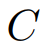
表示变量数,目标是预测未来
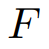
个时间步长的
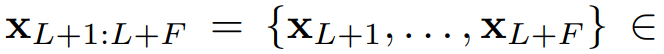
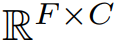
。此外,还可以使用协变量作为辅助指令进行预测,协变量可以分为动态和静态两类。考虑到一般的预测场景,我们假设最常见的动态协变量是时间戳,记作
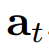
,它与同时发生的多元时间点
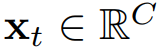
对齐。我们保留时间戳作为文本,而不是其数值编码。任务是学习一个预测器
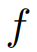
,该预测器根据长度为
的回溯长度对长度为
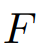
的序列进行预测:
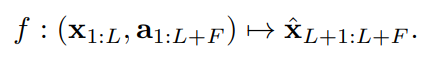
01
模态对齐
1)时间序列标记化
为了使预测器能够处理任意长度的时间序列,研究者重新引入了自回归生成风格到时间序列预测中。在此之前,定义时间序列标记为段,即一个变量的连续时间点,这扩大了局部感受野以包含序列变化,并减少了过多的自回归步骤。研究者通过采样单变量回溯窗口来独立看待每个变量。这使得预测器更专注于时间变化建模,并通过对齐时间戳来发现同时间点的多元相关性。因此,简化了
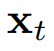
作为特定变量的时间点
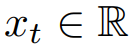
,第
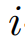
个长度为
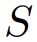
的标记表示为:
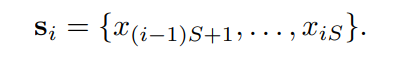
为了充分利用预训练期间大语言模型(LLM)学习的固有标记转换,通过建立
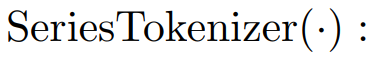
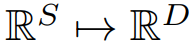
将时间序列段与语言标记对齐,将每个段投影到大语言模型相同的嵌入空间中:
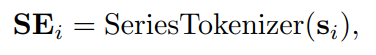
在这里,
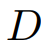
表示的是与重新利用的LLM的维度相一致的嵌入空间维度。
2)标记级提示
由于时间序列的文本协变量通常是在每个时间戳上记录的,先前工作中的序列级提示可能导致语言提示的长度过长,从而阻碍LLM关注序列标记,并导致耗时较长的前向传播。考虑到语言和时间序列共享的序列格式,研究者提出在对应的时间序列段内聚合文本协变量:
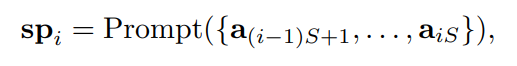
为了获取融合了文本协变量的标记嵌入,采用标记级提示策略,将序列-文本对
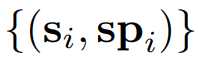
作为输入。这样做能够利用LLM固有的转换能力。提示模板 Prompt(·) 如下图所示,它默认由起始和结束时间戳组成。
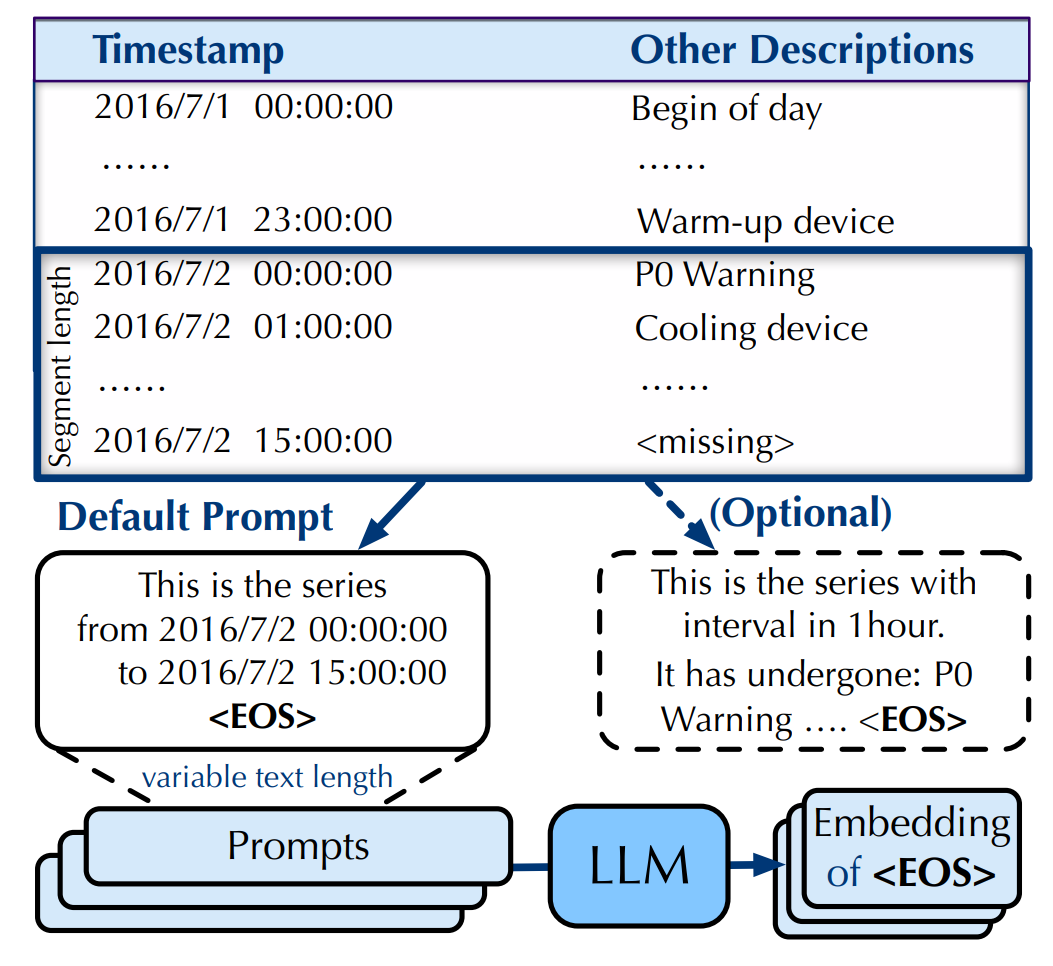
为了得到一个能够感知可变长度标记级提示的嵌入,研究者在提示的末尾添加了一个特殊标记 <EOS>。由于在整个因果注意力机制中,之前的所有标记对特殊标记 <EOS> 都是可见的,研究者选择 <EOS> 的嵌入作为
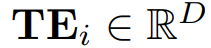
,它集成了一个段内的文本协变量。通过这种方式,能够将文本协变量有效地融入时间序列预测模型中,同时保持模型对时间序列数据本身的关注。
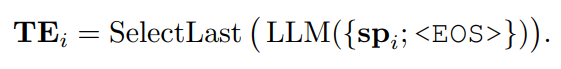
值得注意的是,文本嵌入
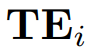
可以由LLM预计算,并且如果提供了可选的描述,它是可以组合的。由于时间序列段的同胚对齐,文本嵌入
可以相应地与序列嵌入
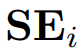
集成。嵌入向量
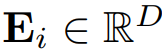
是文本嵌入和序列嵌入的和,其中
作为LLM的位置嵌入,包含了丰富的时间序列周期性和采样信息。
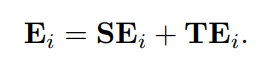
02
下一个标记的预测
由于流行的LLM具备基于前面的标记
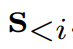
自回归地预测目标标记
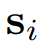
的能力,研究者将其重新用作预测器,并以完全一致的方式完成预测。给定标记数量
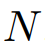
,其中上下文长度为
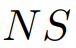
的时间序列被标记化并嵌入为
个标记嵌入
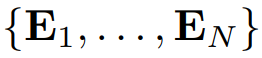
,目标是使用 LLM 独立地预测下一个标记序列
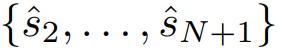
。为了利用预训练期间学习到的语言建模转换,输入这些嵌入并保持 LLM 的参数冻结:
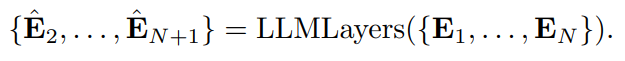
为了将每个获得的嵌入向量重新投影回时间序列段,建立
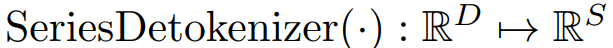
,即:
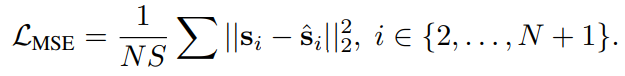
通过采用相同的生成目标,改造后的预测器展现出了与LLM相似的特性,如利用RoPE实现灵活的上下文长度,以及自回归的标记生成方式。
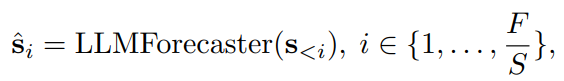
这样做使得一个模型能够处理可变的历史数据长度和预测范围,而无需为每个预测范围分别训练仅包含编码器的预测器。此外,通过建立时间序列标记化并充分利用LLM的参数,AutoTimes保留了LLM的高级功能。
实验数据
对于长期时间序列预测,研究者在实验中使用真实世界的数据集,其中包括iTransformer所使用的ETTh1、ECL、Traffic、Weather和Solar-Energy。对于短期预测,研究者则在广受认可的M4竞赛上评估了性能。
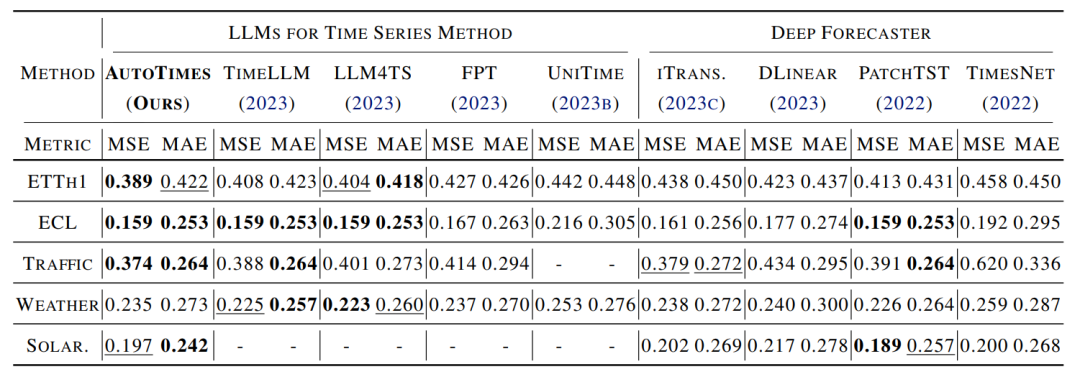
长时预测
AutoTimes在长期预测场景中表现出竞争力,在60%的预测设置下超过了最先进的 LLM4TS 方法和深度预测器,而无需调整历史数据长度。

短时预测
在短期预测中,AutoTimes一致地优于所有其他方法。值得注意的是,AutoTimes是唯一一种通过自回归生成训练单个模型以应对可变预测长度的方法,而所有其他预测器都需要在不同长度上分别进行训练,并在固定的预测长度上作为固定函数工作。训练预测器的时间和资源消耗高昂以及序列长度的不灵活性,可能是实际应用中的主要障碍。

零样本预测
随着模型容量的增强,LLM4TS方法在这项任务上通常取得了更好的表现,与高效的预测器DLinear相比,SMAPE降低了15%。基于相同的Transformer主干,由于从大量序列语料库中预训练的可迁移知识,LLM4TS方法仍然比PatchTST取得了更好的结果。这证实了利用LLM进行时间序列预测的有利优势。此外,AutoTimes保持了LLM在训练、推理和参数上的一致性,因此即使不进行昂贵的微调,也能优于FPT。
总结
与以往在训练、推理和参数方面使用LLM时存在不一致性的方法不同,研究者的方法是通过下一个标记预测来建立时间序列的类似标记化,采用相同的自回归生成进行推理,并冻结LLM的块以充分利用固有的标记转换。实验上,研究者重新利用的预测器与现有基准相比展示了具有竞争力的结果,并显示出处理可变序列长度的熟练能力。进一步的分析表明,该方法有效地保留了诸如零样本泛化和上下文学习等高级能力,使其能够利用指导性的时间序列和时间戳。
腾讯云开发者
