心音表征学习:浅层模型与深层模型的比较研究

在过去的十年里,利用人工智能来促进心音的自动分析和监测已经吸引了大量的关注。然而,在首次发布PhysioNet CinC挑战数据集之前,缺乏标准的公开数据库,使得难以维持可持续和可比较的研究。并且,数据收集、标注、划分等方面的标准不统一,仍然制约着不同分析模型之间公平、高效的比较。

基于此,本研究引入并测试了第一版的深圳心音数据库(HSS)。在前人基于HSS的工作的激励和启发下,研究人员重新定义了任务,并对浅层模型和深层模型进行了全面的研究。首先,将心音录音分割成更短的录音(10秒),这使得它更类似于人类听诊的情况。其次,重新定义了分类任务。本研究除了使用HSS的正常、中度、轻度/重度三大类分类外,还增加了正常和异常的二元分类任务。在这项工作中,研究人员提供了基于经典机器学习和最先进的深度学习技术的详细基准,这些技术可以通过使用开源工具包来重现。相关研究近日以“Learning Representations from Heart Sound: A Comparative Study on Shallow and Deep Models”为题发表在中国科技期刊卓越行动计划高起点新刊Cyborg and Bionic Systems上。
01
数据库和任务
本研究使用的数据库基于HSS的完整原始数据,但具有更短的片段,其时长更短。HSS中所有的原始录音都被分割成基于10秒的长片段,其中有5秒的相邻重叠。本研究共170名受试者(女性55名,男性115名,年龄65.4±13.2岁)参与数据收集。这些研究对象患有各种健康状况,包括高血压、甲状腺功能亢进、心律失常、冠心病、心力衰竭、瓣膜性心脏病和先天性心脏病等。所有心音录音均通过电子听诊器从身体的四个位置(见图1),即听诊二尖瓣,主动脉瓣听诊,三尖瓣听诊区和肺动脉瓣听诊记录。

图1. 心脏的四个听诊位置:主动脉、肺动脉、三尖瓣和二尖瓣。
在这项研究中,共有两个子任务,即任务1:对150个正常、轻度和中度/重度心音进行分类;任务2:正常和异常(包括轻度或151中度/重度)心音的分类。
02
方法与工具集
经典机器学习(ML)模型
在经典的机器学习模式中,人类标定的特征在模型构建中至关重要,并且专家领域知识发挥着重要作用。本研究首先从音频信号(如心音)中提取低级描述符(LLDs),然后根据这些LLDs获得汇总统计信息的超音段特征。在这项研究中,研究者使用了流行的openSMILE工具包,其中包含了时间和频谱声学特性的LLDs特征集,该特征集已经成功应用于自2013年以来的几个ComParE挑战版本。在模型的后端部分,选择了流行的支持向量机(SVM)模型进行实现,这是因为在之前的研究中SVM表现稳定且高效。
Bag-of-Audio-Words方法
Bag-of-Audio-Words(BoAW)方法是基于词袋(bag-of-words, BoW)概念的一种方法,已成功应用于自然语言处理和计算机视觉领域。在本研究提出的BoAW方法中(见图2),首先使用k-means++ 聚类算法对音频特征(如声学LLDs和delta)进行初始化,生成一个码本。在计算直方图时,每个声学特征被分配给码本中与之欧几里得距离最小的10个音频单词。在本研究中,LLDs和它们的delta被连接起来表示BoAW。本研究使用了openSMILE工具包和ComParE特征集提取LLDs及其增量。BoAW方法由openXBOW工具包实现。为了优化码本的大小,本研究中研究了不同的码本大小,包括125、250、500、1000 和 2000。
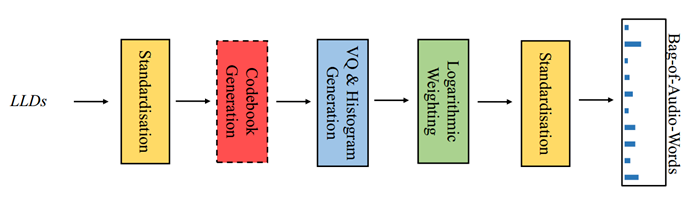
图2. BoAW方法的处理流程图
深度学习模型
深度学习是一种能够通过非线性变换从数据中提取更高级别表征的方法,正在极大地改变机器学习的范式。深度学习模型在处理大规模数据时能够学习到更鲁棒和泛化的特征。在本研究中,引入了三种典型的深度学习方法,包括使用预训练深度卷积神经网络的深度频谱迁移学习方法、循环序列到序列自编码器方法和端到端学习模型。
在深度频谱迁移学习方法中,首先将心音信号转换成梅尔谱图,然后通过预训练的深度卷积神经网络提取高级特征,最后使用这些特征构建支持向量机模型。本研究尝试了多种预训练的深度卷积神经网络模型,例如 ResNet 50、VGG 16、VGG 19、AlexNet 和 GoogLeNet。
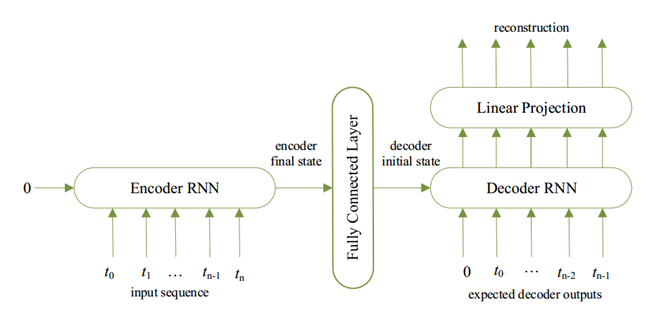
图3. 基于S2SAE方法的循环自动编码器示意图。在这种方法中,使用无监督场景来学习更高层次的特征。该网络被训练成最小化输入序列和重建之间的均方根误差。当训练完成后,将全连接层的激活作为输入序列的表示。
循环序列到序列自编码器(S2SAE)方法中,同样将心音数据转换成梅尔谱图,并通过裁剪功率电平来消除背景噪声。然后,训练一组不同的S2SAE模型来学习这些谱图的特征,最后将学习到的特征连接成实例的特征向量(见图3)。
端到端(E2E)学习模型利用卷积神经网络和/或递归神经网络直接从原始心音音频波形中提取更高级别的特征(见图4)。我们使用了DEEPSELF工具包来实现端到端模型,并采用了长短时记忆和门控循环单元来解决梯度消失问题。
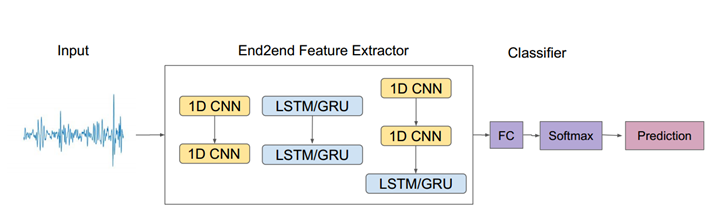
图4. 端到端学习方法的示意图。使用一系列深度CNN和/或RNN模型可以直接从原始心音时间波形中提取更高层次的特征
评价标准
在本研究中,考虑到数据不平衡性,使用未加权平均召回率(UAR)作为主要评价指标。相对于广泛使用的加权平均召回率(WAR),即准确率,UAR对于不平衡数据库更为合理和严格。另外,为了解释每个特征对预测的贡献,本研究使用SHAP来解释特征如何影响预测。
03
实验结果
为了确保实验结果的复现性,本研究中所有的实验均通过基于Python的脚本运行,并使用开源工具包来实现所述的方法。所有超参数均在验证集上进行了调整和优化,并应用于测试集。验证结果是由最优模型获得的结果,测试结果是由在验证集上优化超参数内的模型验证的结果。为了最大限度地减少数据不平衡的影响,本研究采用了上采样技术来复制数量更少的类别的实例。在输入分类器之前,对所有特征进行了标准化,使用了训练集的均值和标准差值。
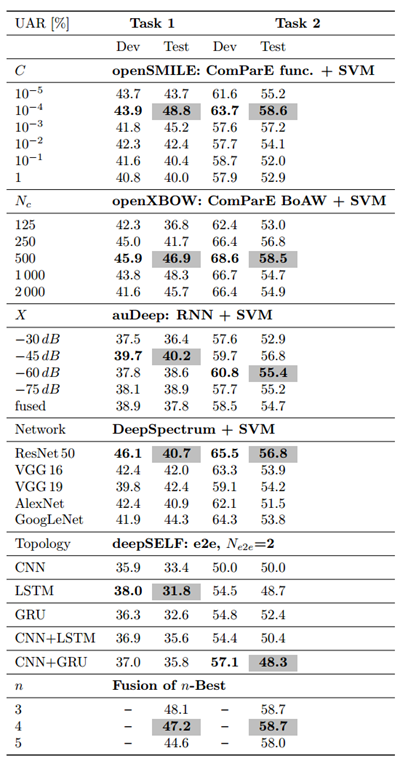
表1. 基准测试结果。C: SVM的惩罚因子。
五种方法的实验结果如表1所示。可以看到,对于任务1和任务2,基于ComParE特征集的模型的性能最好,与之前的研究一致,表明目前精心设计的人类专家标注的特征对于构建高效鲁棒的心音分类模型非常重要。对于任务1和任务2,最好的单个模型都是通过经典的ML模型,即ComParE特征集与SVM分类器的组合函数来实现的。对于三类和二类任务,相应的最佳UAR分别为48.8%(随机选择预期水平:33.3%)和58.6%(随机选择预期水平:50.0%)。这些结果均明显优于本研究的E2E模型。
最好的四种模型的后期融合(通过多数投票)达到了相当的性能。对于任务1,最佳融合模型低于最佳单一模型(UAR: 47.2% vs 48.8%)。对于任务2,最佳融合模型与最佳单一模型相比有非常轻微的提升(UAR: 58.7% vs 58.6%)。在所有测试集(815个样本)上进行SHAP解释实验,分析了基线中前两个结果的特征贡献。通过ComParE特征集实现的最佳性能的SHAP解释如图5所示。从图中可以看出,经过函数计算转换后的MFCC特征和RASTA滤波后的听觉谱特征贡献最高,PeakMeanRel(某一特征中峰值的相对平均值)函数特征的贡献通常更好。
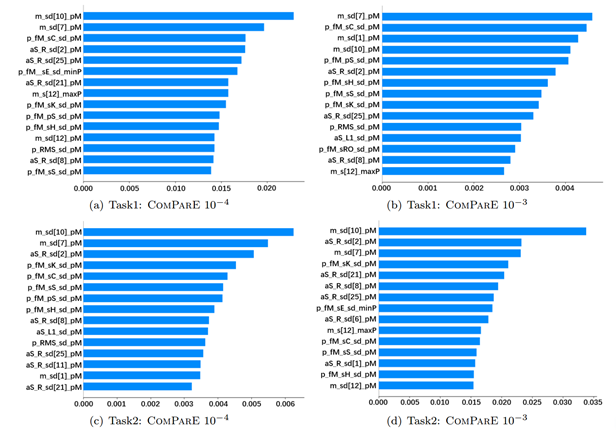
图5. openSMILE: ComParE func. + SVM 获得的最佳性能的SHAP解释。
表2和表3分别提供了Task 1和Task 2测试集上最佳四种模型的混淆矩阵,以及它们在融合后的结果。在任务1中,对于心音的分类,"轻度"和"中度/重度"类型的召回率要高于“正常”类型。通过模型的融合,对于"中度/重度"类型的召回率稍有提升,但对其他两种类型的心音的召回率仍然较低。在任务2中,对于异常检测,"异常"类型的召回率远高于"正常"类型。换句话说,正常的心音往往被错误地判定为异常。通过最佳四种模型的融合,可以得到"异常"类型的最高召回率。
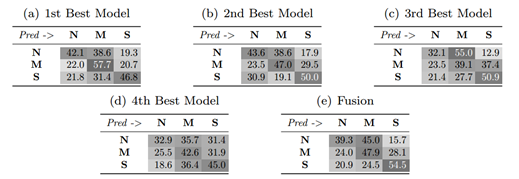
表2. 任务1的测试集中最佳模型的混淆矩阵,已进行了归一化(以百分比显示)。N: 正常类型,M:轻度类型,S: 中度/重度类型。

表3. 任务2的测试集中最佳模型的混淆矩阵,已进行了归一化(以百分比显示)。N: 正常类型,N:正常,A: 异常。
04
探讨与结论
本研究发现在心音分类中,基于特征集方法的表现优于其他方法,而深度学习方法效果一般。令人鼓舞的是,在准确率、灵敏度、精确度和F1-score等指标上取得了不错的成绩。然而,数据不足限制了深度学习模型的性能,特异度和G-mean仍需提高。当前面临的主要挑战是极端的数据不平衡特征,这限制了所有模型的性能。为了克服这一挑战,需要收集更多正常心音数据,引入先进技术如GANs,研究更高级的信号处理技术,克服数据集之间的性能差距,并开发更通用的模型以克服过度拟合的挑战。同时,还需要吸引更多关注和贡献到无创心音分析领域,计划举办公开挑战和讨论会以促进进一步的发展。
总而言之,本研究针对心脏状态的分类任务,将HSS数据集中的音频记录分割成10秒为基础的片段,从较短的音频记录中预测心脏状态。此外,还扩展了这项工作,添加了一个二元分类任务,即正常/异常检测作为子任务。经过使用开源工具包对机器学习和深度学习方法的比较和研究,本研究得出了三个分类任务的最佳结果:机器学习方法的48.8% UAR和深度学习方法的58.7% UAR(预测水平分别为33.3%和50.0%)。研究人员希望这个新的数据库以及基准研究的结果可以进一步在广泛的科学界中做出贡献。
—— End ——