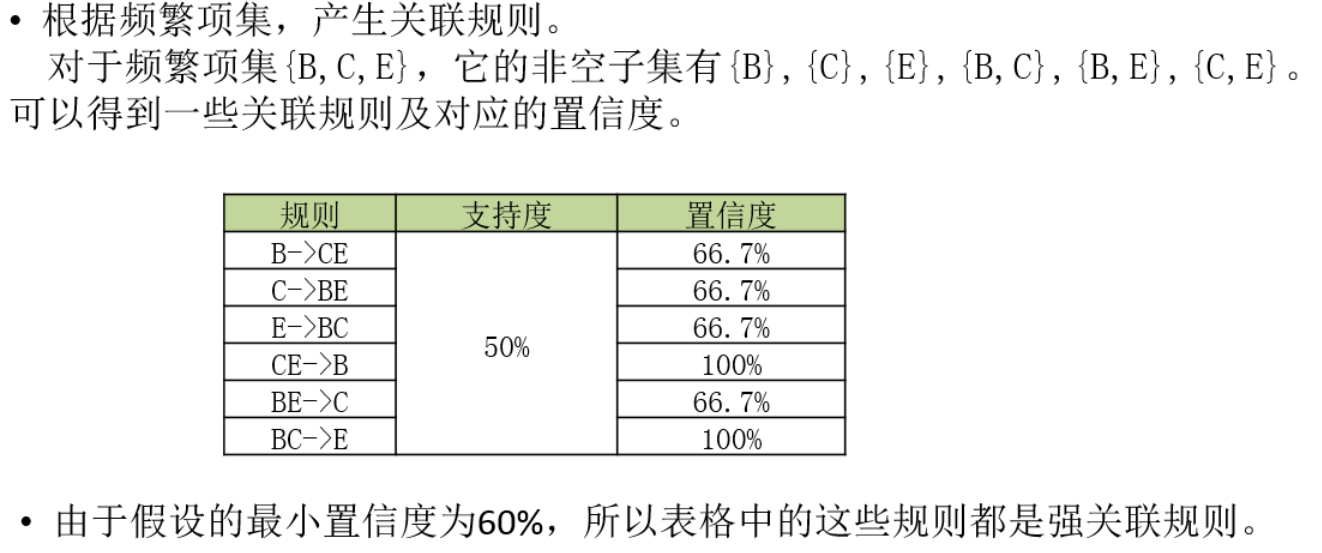
机器学习-08-关联规则和协同过滤

总结
本系列是机器学习课程的系列课程,主要介绍机器学习中关联规则和协同过滤。
参考
本门课程的目标
完成一个特定行业的算法应用全过程:
懂业务+会选择合适的算法+数据处理+算法训练+算法调优+算法融合 +算法评估+持续调优+工程化接口实现
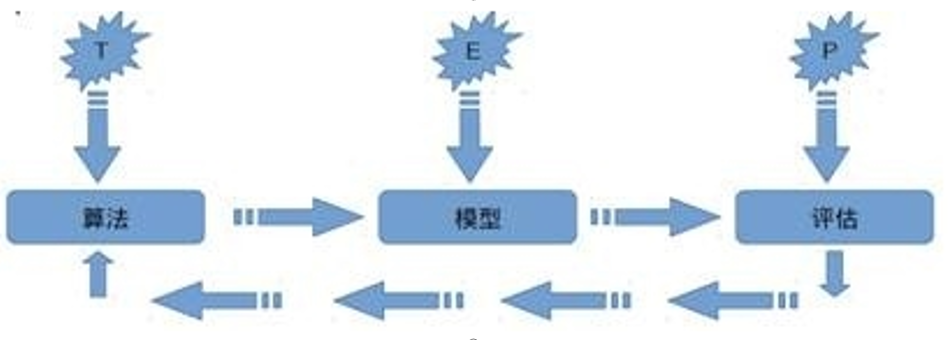
机器学习定义
关于机器学习的定义,Tom Michael Mitchell的这段话被广泛引用: 对于某类任务T和性能度量P,如果一个计算机程序在T上其性能P随着经验E而自我完善,那么我们称这个计算机程序从经验E中学习。
关联规则
啤酒与尿布
“啤酒与尿布” 的故事相信很多人都听过,年轻爸爸去超市购买尿布时,经常会买点啤酒犒劳自己。因此,沃尔玛将这两种商品进行了捆绑销售,最终获得了更好的销量。

“啤酒与尿布”的故事

这个故事背后的理论依据就是 “推荐算法”,因为尿布和啤酒经常出现在同一个购物车中,那么向购买尿布的年轻爸爸推荐啤酒确实有一定道理。
关联规则算法
获得啤酒与尿布的关系的一种算法就是关联规则算法:
1.关联规则推荐算法:这种算法基于关联规则挖掘的技术。它通过分析用户行为数据中的项集之间的关联关系,找出频繁项集和关联规则,然后根据这些规则进行推荐。比如,根据用户购买商品的历史记录,可以挖掘出购买商品之间的关联规则,然后根据规则推荐其他相关商品给用户。
关联规则算法最开始是面向购物篮分析问题:

如何在消费者购买了特定商品,比如PC机和一台数码相机后,作为销售人员的你针对该消费者已购买的商品进行分析(购物篮分析),可以继续给该消费者推荐什么产品,该消费者才能更感兴趣。
关联规则算法可以帮助我们在大量历史销售数字中发现“已有的多数客户在购买PC机和数码相机后,还经常购买哪些产品”这样的一个规律。关联规则就是通过发现顾客放入“购物篮”中的不同商品之间的关联,分析顾客的购物习惯,而物品见的某种联系我们称为关联。 这种关联的发现可以帮助零售商了解哪些商品频繁的被顾客同时购买,从而帮助他们开发更好的营销策略。
关联规则 (Association Rules,又称 Basket Analysis) 是形如X→Y的蕴涵式,
其中, X和Y分别称为关联规则的先导(antecedent或left-hand-side, LHS)和后继(consequent或right-hand-side, RHS) 。
在这当中,关联规则X→Y,利用其支持度和置信度从大量数据中挖掘出有价值的数据项之间的相关关系。
关联规则解决的常见问题如:“如果一个消费者购买了产品A,那么他有多大机会购买产品B?”以及“如果他购买了产品C和D,那么他还将购买什么产品?”
关联规则定义:
假设
I = {I1,I2,。。。Im}是包含所有商品(item)的集合, 包含k个项的项集称为k项集(k-itemset)。 给定一个交易数据库D,其中每个事务(Transaction)T是I的非空子集,即每一个交易都与一个唯一的标识符TID(Transaction ID)对应。关联规则挖掘的目的即通过已发生的事务数据,找到其中有效关联性较高的项集所构成的规则。 那么,如何度量关联规则的有效性及关联性呢? 首先,该关联规则本身所对应的商品应当具有一定的普遍推荐价值,即支持度较高;关联规则在D中的支持度(support)是D中事务同时包含X、Y的百分比,即概率; 其次该规则的发生应当具有一定的可能性,即置信度较高。置信度(confidence)是D中事务已经包含X的情况下,包含Y的百分比,即条件概率。
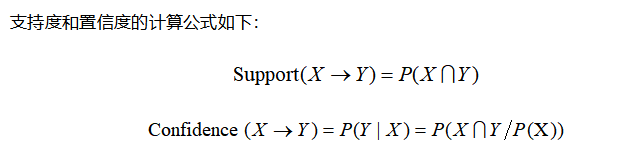
如果满足最小支持度阈值min_support和最小置信度阈值min_confidence,则认为关联规则是重要的。
当一个项集(XY)的支持度大于等于min_support,这个项集就被称为频繁项集(Frequent Itemset)。
当以频繁项集(XY)构成的关联规则(X→Y)的置信度大于等于min_confidence,这个关联规则就被称为强关联规则。强关联规则也是关联规则挖掘的最终产出。
关联规则挖掘过程主要包含两个阶段:
第一阶段必须先从资料集合中找出所有的频繁项集(Frequent Itemsets), 第二阶段再由这些高频项目组中产生强关联规则(Association Rules)。
举个栗子🌰说明下
TID | 牛奶 | 面包 | 尿布 | 啤酒 | 鸡蛋 | 可乐 |
|---|---|---|---|---|---|---|
1 | 1 | 1 | 0 | 0 | 0 | 0 |
2 | 0 | 1 | 1 | 1 | 1 | 0 |
3 | 1 | 0 | 1 | 1 | 0 | 1 |
4 | 1 | 1 | 1 | 1 | 0 | 0 |
5 | 1 | 1 | 1 | 0 | 0 | 1 |
上表格是顾客购买记录的数据库D,包含
5个事务, 即D=5,有5个订单。 项集I={牛奶,面包,尿布,啤酒,鸡蛋}。 若给定最小支持度in_support=0.5,最小置信度min_confidence=0.6, 考虑一个二项集:{牛奶,面包}, 事务1,4,5同时包含牛奶和面包,那么说明包含牛奶和面包的有3个事务,即X∩Y=3,支持度(X∩Y)/D=3/5=0.6>min_support,则{牛奶,面包}是一个频繁项集。 对于关联规则(牛奶→面包),在数据库D中4个事务是包含牛奶的,即X=4, 因而置信度(X∩Y)/X=3/4=0.75>min_confidence,则认为购买牛奶和购买面包之间存在强关联。
关联规则算法Apriori实现
Apriori算法实现原理
R.Agrawal 和 R. Srikant于1994年在文献中提出了Apriori算法,该算法的描述如下图所示:

1)令k = 1 2)统计每个k项集的支持度,并找出频繁k项集 3)利用频繁k项集生成候选k+1项集 4)令k=k+1,重复第 2)步
// 尺寸为k的候选项目集
C_k:Candidate itemsets of size k
//大小为k的频繁项目集
L_k:frequent itemsets of size k
L1={frequent 1-itemsets}; // 大小为1的频繁项目集
// k从1开始,频繁项目集不为0
for (k=1;L_k≠0;k++)
// 从 L_k频繁项目集 中生成 C_k+1候选项目集
C_k+1=GenerateCandidates(L_k)
// 对于每一个数据库D中的事务t
for each transaction t in database do
// 包含在t中的C_k+1中的候选者的增量计数
increment count of candidates in C_k+1 that are contained in t
endfor
// 在 C_k+1中的候选集中找到大于最小支持度的作为L_K+1频繁候选项集
L_k+1=candidates in C_k+i with support >= min_sup
endfor
return U_kL_k;举例🌰:说明下


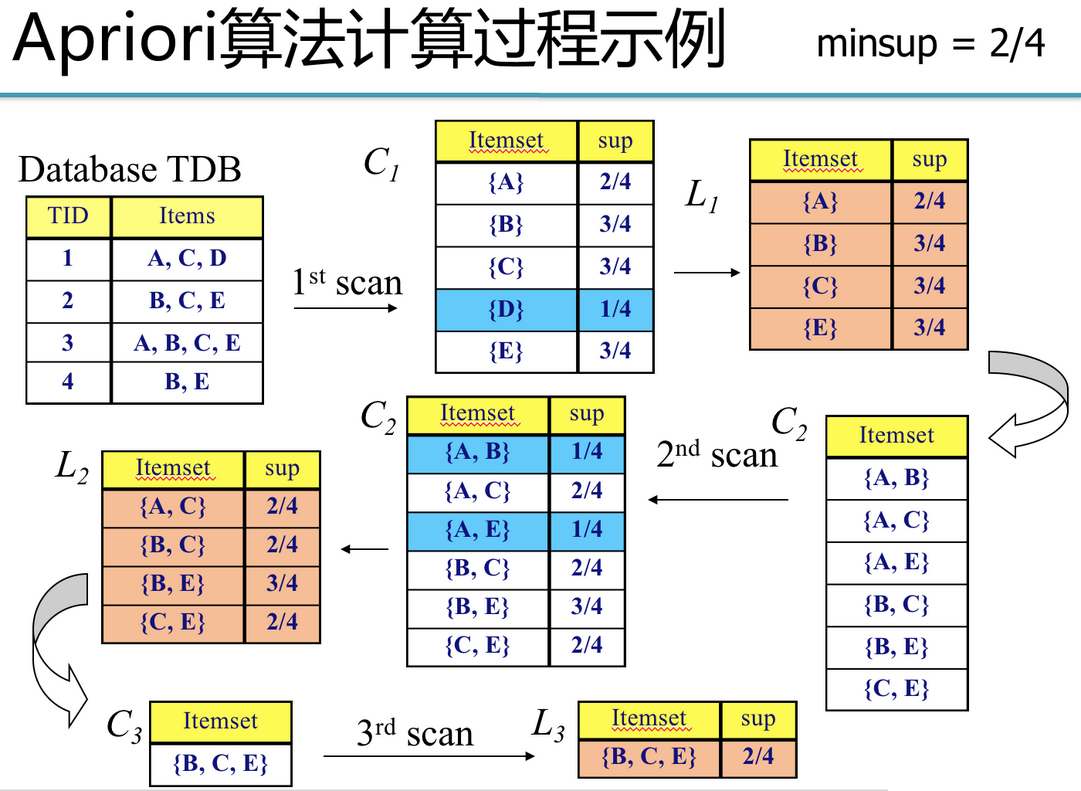
Apriori算法实例—产生频繁项集
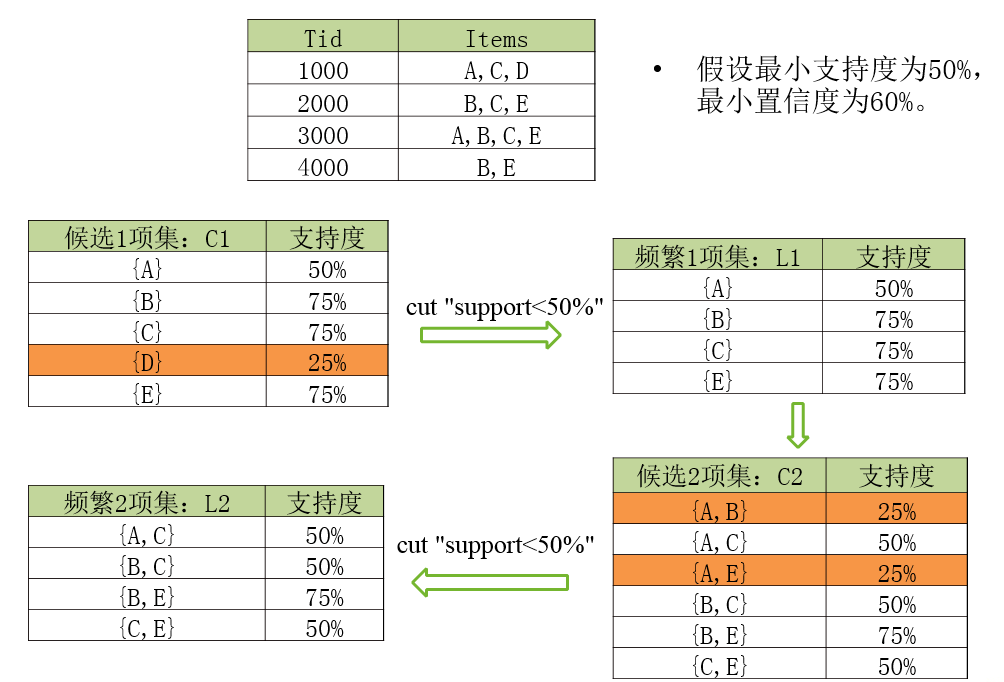
Apriori算法实例—产生关联规则
Apriori算法思想总结

协同过滤算法

协同过滤的基本流程: 首先,要实现协同过滤,需要以下几个步骤 (1)收集用户偏好 (2)找到相似的用户或物品 (3)计算推荐
基于用户的协同过滤
案例:基于用户的协同过滤。
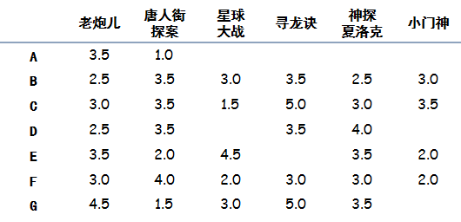
假设有几个人分别看了如图电影并且给电影有如下评分(5分最高,没看过的不评分),我们目的是要向A用户推荐一部电影:
协同过滤的整体思路只有两步,非常简单:寻找相似用户,推荐电影。
(1)
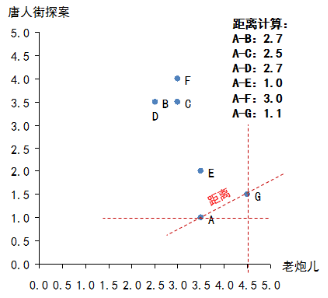
寻找相似用户:所谓相似,其实是对于电影品味的相似,也就是说需要将A与其他几位用户做比较,判断是不是品味相似。有很多种方法可以用来判断相似性,我们使用“欧几里德距离”来做相似性判定。当把每一部电影看成N维空间中的一个维度,这样每个用户对于电影的评分相当于维度的坐标,那么每一个用户的所有评分,相当于就把用户固定在这个N维空间的一个点上,然后利用欧几里德距离计算N维空间两点的距离。距离越短说明品味越接近。 本例中A只看过两部电影(《老炮儿》和《唐人街探案》),因此只能通过这两部电影来判断品味了,那么计算A和其他几位用户的距离,如下图所示:

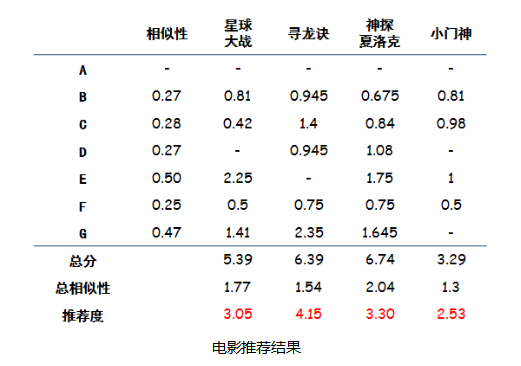
(2)推荐电影: 要做电影加权评分推荐。意思是说,品味相近的人对于电影的评价对A选择电影来说更加重要,具体做法可以列一个表,计算加权分,如图所示:
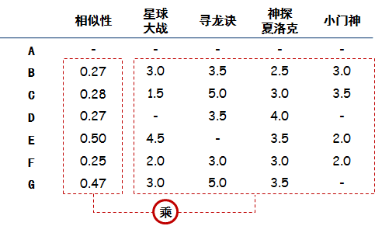
把相似性和对于每个电影的实际评分相乘,就是电影的加权分,如下图所示:

基于物品协同过滤
基于用户的协同过滤,适用于物品较少,用户也不太多的情况。 如果用户太多了,针对每个用户的购买情况来计算哪些用户和他品味类似,效率很低下。 如果商品很多,每个用户购买的商品重合的可能性很小,这样判断品味是否相似也就变得比较困难了。
“基于物品的协同过滤”。消费者每天都在买买买,行为变化很快,但是物品每天虽然也有变化,但是和物品总量相比变化还是少很多。这样,就可以预先计算物品之间的相似程度,然后再利用顾客实际购买的情况找出相似的物品做推荐。这就是“基于物品的协同过滤”。
由于物品整体变化不大,所以这个相似程度不用每天都算,节省计算资源;同时,可以只给某一样商品只备选5个相似商品,推荐时只做这5个相似物品的加权评分,避免对所有商品都进行加权评分,以避免大量计算。这么说有点抽象,还是看一个例子吧。
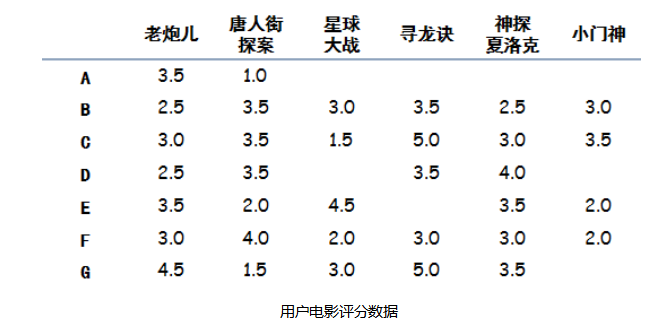
还是用上一章节的例子,目的是给A推荐一部电影。
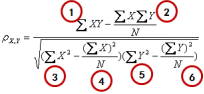
首先是计算电影之间的相似度,方法还是有很多,这次用Pearson相关系数来做,公式为:
公式看起来复杂,其实可以分成6个部分分别计算就好了,我们选《寻龙诀》(X)和《小门神》(Y)作为例子,来算一下相似度,则: X=(3.5,5.0,3.0) Y=(3.0,3.5,2.0) 数字就是评分,因为只有三个人同时看了这两个电影,所以X,Y两个向量都只有三个元素。按照公式逐步计算:

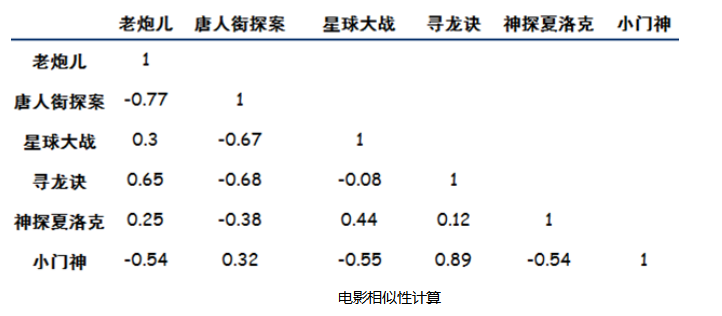
相关系数取值为(-1,1),1表示完全相似,0表示没关系,-1表示完全相反。 结合到电影偏好上,如果相关系数为负数,比如《老炮儿》和《唐人街探案》,意思是说,喜欢《老炮儿》的人,存在厌恶《唐人街探案》的倾向。 然后就可以为A推荐电影了,思路是:A只看过两个电影,然后看根据其他电影与这两个电影的相似程度,进行加权评分,得出应该推荐给A的电影具体方法如下图:
协同过滤算法案例
构建数据集
# A dictionary of movie critics and their ratings of a small#
critics = {
'A': {'老炮儿':3.5,'唐人街探案': 1.0},
'B': {'老炮儿':2.5,'唐人街探案': 3.5,'星球大战': 3.0, '寻龙诀': 3.5,
'神探夏洛克': 2.5, '小门神': 3.0},
'C': {'老炮儿':3.0,'唐人街探案': 3.5,'星球大战': 1.5, '寻龙诀': 5.0,
'神探夏洛克': 3.0, '小门神': 3.5},
'D': {'老炮儿':2.5,'唐人街探案': 3.5,'寻龙诀': 3.5, '神探夏洛克': 4.0},
'E': {'老炮儿':3.5,'唐人街探案': 2.0,'星球大战': 4.5, '神探夏洛克': 3.5,
'小门神': 2.0},
'F': {'老炮儿':3.0,'唐人街探案': 4.0,'星球大战': 2.0, '寻龙诀': 3.0,
'神探夏洛克': 3.0, '小门神': 2.0},
'G': {'老炮儿':4.5,'唐人街探案': 1.5,'星球大战': 3.0, '寻龙诀': 5.0,
'神探夏洛克': 3.5}
}STEP1:编写函数计算欧式距离字典数据中两两用户的欧式距离。
from math import sqrt
# Returns a distance-based similarity score for person1 and person2
# 返回 person1 and person2基于距离的相似度
def sim_distance(prefs, person1, person2):
# Get the list of shared_items
si = {}
for item in prefs[person1]:
if item in prefs[person2]: si[item] = 1
# if they have no ratings in common, return 0 如果没有共同评分返回0
if len(si) == 0: return 0
# Add up the squares of all the differences 所有差异平方相加
sum_of_squares = sum([pow(prefs[person1][item] - prefs[person2][item], 2)
for item in prefs[person1] if item in prefs[person2]])
return 1 / (1 + sqrt(sum_of_squares))
# 打印'B'对'星球大战'的评分
print(critics['B']['星球大战'])
# 打印相识分数
print(sim_distance(critics, 'A', 'B'))输出为:
在STEP1基础上,编写函数依据欧式距离大小以及协同过滤算法(用户)实现电影的推荐。
# Gets recommendations for a person by using a weighted average of every other user's rankings
# 通过加权平均为一个人推荐
def getRecommendations(prefs, person, similarity=sim_distance):
# 定义两个空字典
totals = {}
simSums = {}
# 对传入的数据进行循环
for other in prefs:
# don't compare me to myself
# 不与自己比较
if other == person: continue
# 计算这个人与其它人的评分
sim = similarity(prefs, person, other)
# ignore scores of zero or lower
# 忽略<=0的分数
if sim <= 0: continue
# 对过滤后的数据再次遍历
for item in prefs[other]:
# only score movies I haven't seen yet
# 只给没看过的电影打分
if item not in prefs[person] or prefs[person][item] == 0:
# Similarity * Score
# 相似度 * 得分
totals.setdefault(item, 0)
totals[item] += prefs[other][item] * sim
# Sum of similarities
# 相似度总和
simSums.setdefault(item, 0)
simSums[item] += sim
# Create the normalized list
# 创建规范化列表
rankings = [(total / simSums[item], item) for item, total in totals.items()]
# Return the sorted list
# 返回排序后的列表
rankings.sort()
rankings.reverse()
return rankings
print(getRecommendations(critics, 'A'))输出为:
基于surprise的协同过滤算法实现
电影数据集介绍
数据获取:
MovieLens数据集可以从MovieLens网站上免费下载。不同版本的数据集具有不同的规模和数据量,可以根据研究或应用的需求选择适当的版本。 下载地址:https://grouplens.org/datasets/movielens/
按照依赖:
pip install scikit-surpriseSTEP1:导入库 导入surprise库中的算法,数据集,网格搜索。
# 导入库
from surprise import SVD
from surprise import Dataset
from surprise import Reader
from surprise.model_selection import GridSearchCV
import osSTEP2:加载数据集 加载movielens-100K数据集,默认在线下载数据集,也可以加载本地数据
# 加载 movielens-100K
# 定义推荐数据集文件路径 绑定你的数据集地址
file_path = '/xxx/u.data'
# 指定分隔符
reader = Reader(line_format='user item rating timestamp', sep='\t')
# 导入文件
data = Dataset.load_from_file(file_path, reader=reader)STEP3:网格搜索 设置网格搜索参数
# 网格搜索
param_grid = {'n_epochs': [5, 10], 'lr_all': [0.002, 0.005],
'reg_all': [0.4, 0.6]}
gs = GridSearchCV(SVD, param_grid, measures=['rmse', 'mae'], cv=3)STEP4:训练并获得最佳模型
# 训练模型
gs.fit(data)
# 输出最佳RMSE(均方根误差)得分
print('The best RMSE:',gs.best_score['rmse'])
# 输出最佳RMSE得分的参数组合
print('The best params:',gs.best_params['rmse'])
# 获得最佳算法
algo = gs.best_estimator['rmse']
algo.fit(data.build_full_trainset())STEP5:模型预测
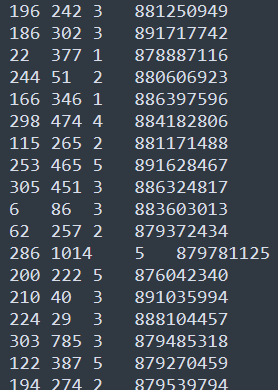
# 模型预测
uid = str(196) # 原始user id (在评分文件中的)
iid = str(302) # 原始item id (在评分文件中的)
#对某一个具体的user和item给出预测
pred = algo.predict(uid, iid, r_ui=4, verbose=True)STEP6:输出结果解释
The best RMSE 0.9629441271618542
The best params {'n_epochs': 10, 'lr_all': 0.005, 'reg_all': 0.4}
user: 196 item: 302 r_ui = 4.00 est = 4.01 {'was_impossible': False}
# 说明:user为用户id,item为项目id,r_ui为真实评分,est为预测评分推荐系统
推荐系统到底解决的是什么问题
推荐系统从20世纪90年代就被提出来了。随着移动互联网的发展,越来越多的信息开始在互联网上传播,产生了严重的信息过载。因此,如何从众多信息中找到用户感兴趣的信息,这个便是推荐系统的价值。精准推荐解决了用户痛点,提升了用户体验,最终便能留住用户。推荐系统本质上就是一个
信息过滤系统,通常分为:召回、排序、重排序这3个环节,每个环节逐层过滤,最终从海量的物料库中筛选出几十个用户可能感兴趣的物品推荐给用户。
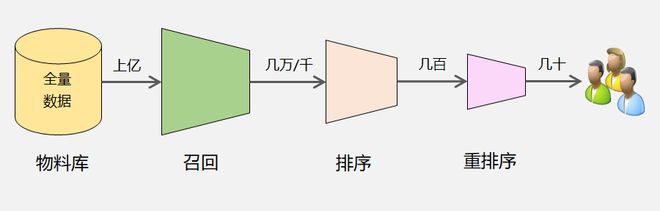
推荐系统的分阶段过滤流程
推荐系统的应用场景
哪里有海量信息,哪里就有推荐系统,我们每天最常用的APP都涉及到推荐功能:
资讯类:今日头条、腾讯新闻等 电商类:淘宝、京东、拼多多、亚马逊等 娱乐类:抖音、快手、爱奇艺等 生活服务类:美团、大众点评、携程等 社交类:微信、陌陌、脉脉等
头条、京东、网易云音乐中的推荐功能
推荐系统的应用场景通常采用协同过滤算法:
协同过滤推荐算法:这种算法基于用户行为数据的协同过滤技术。它通过分析用户之间的相似性或物品之间的相关性,为用户生成个性化的推荐结果。协同过滤算法主要分为基于用户的协同过滤和基于物品的协同过滤两种方法。基于用户的协同过滤通过比较用户之间的行为数据,找出兴趣相似的用户,并为用户推荐与这些相似用户喜欢的物品。基于物品的协同过滤则是根据物品之间的相似性,为用户推荐与其历史喜欢物品相似的其他物品。
基于协同过滤的推荐算法:
这种算法基于用户行为数据的协同过滤技术。它通过分析用户之间的相似性或物品之间的相关性,为用户生成个性化的推荐结果。协同过滤算法主要分为基于用户的协同过滤和基于物品的协同过滤两种方法。
基于用户维度的推荐:根据用户的历史行为和兴趣进行推荐,比如淘宝首页的猜你喜欢、抖音的首页推荐等。基于物品维度的推荐:根据用户当前浏览的标的物进行推荐,比如打开京东APP的商品详情页,会推荐和主商品相关的商品给你。
除了关联规则和协同过滤,还有其他一些常见的推荐算法,如基于内容的推荐、基于矩阵分解的推荐、深度学习推荐等。这些算法都有各自的优缺点和适用场景,根据实际需求选择合适的算法进行推荐。
搜索、推荐、广告三者的异同
搜索和推荐是AI算法最常见的两个应用场景,在技术上有相通的地方。这里提到广告,主要考虑很多没做过广告业务的同学不清楚为什么广告和搜索、推荐会有关系,所以做下解释。
搜索:有明确的搜索意图,搜索出来的结果和用户的搜索词相关。推荐:不具有目的性,依赖用户的历史行为和画像数据进行个性化推荐。广告:借助搜索和推荐技术实现广告的精准投放,可以将广告理解成搜索推荐的一种应用场景,技术方案更复杂,涉及到智能预算控制、广告竞价等。
推荐系统的整体架构
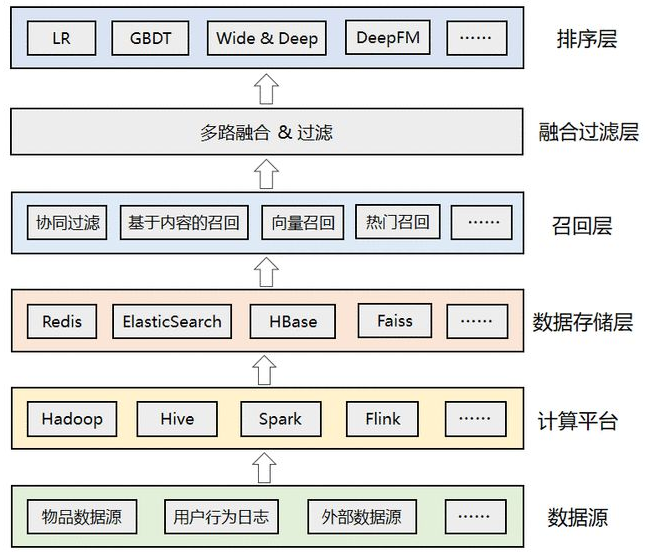
推荐系统的整体架构
上面是推荐系统的整体架构图,自下而上分成了多层,各层的主要作用如下:
数据源:推荐算法所依赖的各种数据源,包括物品数据、用户数据、行为日志、其他可利用的业务数据、甚至公司外部的数据;计算平台:负责对底层的各种异构数据进行清洗、加工,离线计算和实时计算;数据存储层:存储计算平台处理后的数据,根据需要可落地到不同的存储系统中,比如Redis中可以存储用户特征和用户画像数据,ES中可以用来索引物品数据,Faiss中可以存储用户或者物品的embedding向量等;召回层:包括各种推荐策略或者算法,比如经典的协同过滤,基于内容的召回,基于向量的召回,用于托底的热门推荐等。为了应对线上高并发的流量,召回结果通常会预计算好,建立好倒排索引后存入缓存中;融合过滤层:触发多路召回,由于召回层的每个召回源都会返回一个候选集,因此这一层需要进行融合和过滤;排序层:利用机器学习或者深度学习模型,以及更丰富的特征进行重排序,筛选出更小、更精准的推荐集合返回给上层业务。
从数据存储层到召回层、再到融合过滤层和排序层,候选集逐层减少,但是精准性要求越来越高,因此也带来了计算复杂度的逐层增加,这个便是推荐系统的最大挑战。
其实对于推荐引擎来说,最核心的部分主要是两块:特征和算法。
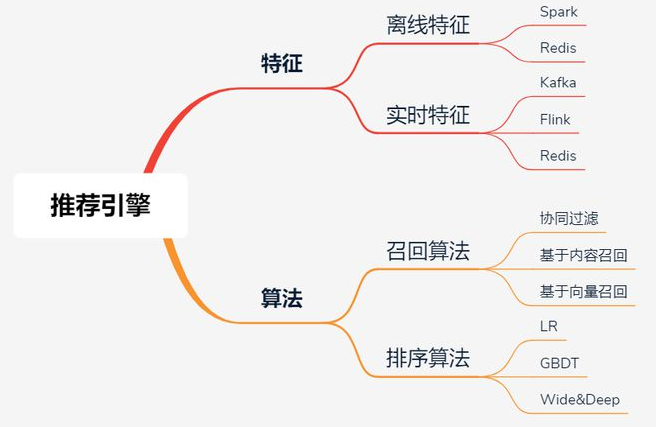
推荐引擎的核心功能和技术方案
特征计算由于数据量大,通常采用大数据的离线和实时处理技术,像Spark、Flink等。然后将计算结果保存在Redis或者其他存储系统中(比如HBase、MongoDB或者ES),供召回和排序模块使用。
召回算法的作用是:从海量数据中快速获取一批候选数据,要求是快和尽可能的准。这一层通常有丰富的策略和算法,用来确保多样性,为了更好的推荐效果,某些算法也会做成近实时的。
排序算法的作用是:对多路召回的候选集进行精细化排序。它会利用物品、用户以及它们之间的交叉特征,然后通过复杂的机器学习或者深度学习模型进行打分排序,这一层的特点是计算复杂但是结果更精准。
图解经典的协同过滤算法
协同过滤(Collaborative Filtering,CF)是一个简单同时效果很好的算法,只要你有初中数学的基础就能看懂。协同过滤算法的核心就是「找相似」,它基于用户的历史行为(浏览、收藏、评论等),去发现用户对物品的喜好,并对喜好进行度量和打分,最终筛选出推荐集合,它又包括两个分支:
1)基于用户的协同过滤 User-CF,核心是找相似的人。 比如下图中,用户 A 和用户 C 都购买过物品 a 和物品 b,那么可以认为 A 和 C 是相似的,因为他们共同喜欢的物品多。这样,就可以将用户 A 购买过的物品 d 推荐给用户 C。
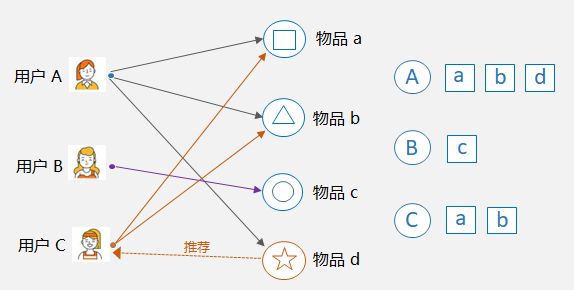
基于用户的协同过滤示例
2)基于物品的协同过滤 Item-CF,核心是找相似的物品。比如下图中,物品 a 和物品 b 同时被用户 A,B,C 购买了,那么物品 a 和 物品 b 被认为是相似的,因为它们的共现次数很高。 这样,如果用户 D 购买了物品 a,则可以将和物品 a 最相似的物品 b 推荐给用户 D。
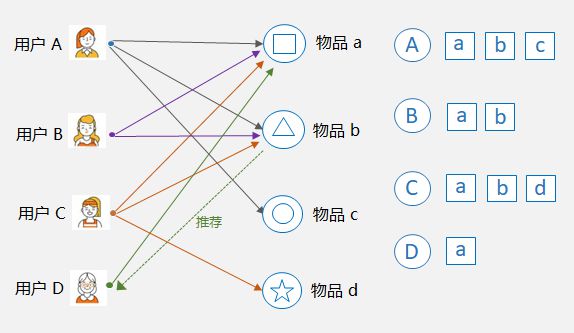
基于物品的协同过滤示例
如何找相似?
前面讲到,协同过滤的核心就是找相似,User-CF是找用户之间的相似,Item-CF是找物品之间的相似,那到底如何衡量两个用户或者物品之间的相似性呢? 我们都知道,对于坐标中的两个点,如果它们之间的夹角越小,这两个点越相似,这就是初中学过的余弦距离,它的计算公式如下:
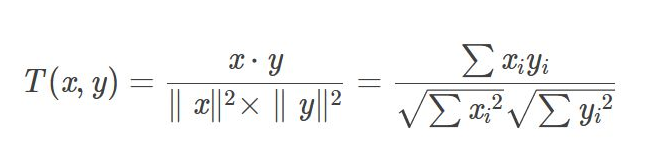
举个例子,A坐标是(0,3,1),B坐标是(4,3,0),那么这两个点的余弦距离是0.569,余弦距离越接近1,表示它们越相似。
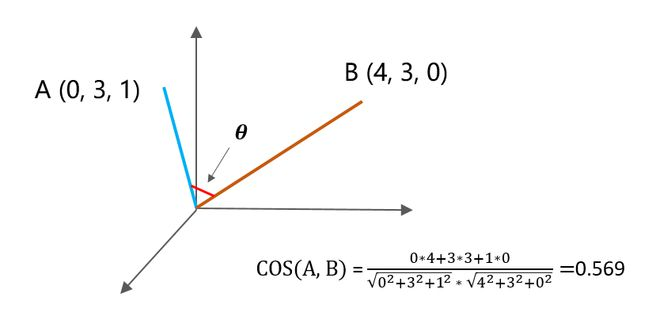
除了余弦距离,衡量相似性的方法还有很多种,比如:欧式距离、皮尔逊相关系数、Jaccard 相似系数等等,这里不做展开,只是计算公式上的差异而已。
Item-CF的算法流程
清楚了相似性的定义后,下面以Item-CF为例,详细说下这个算法到底是如何选出推荐物品的?
第一步:整理物品的共现矩阵 假设有 A、B、C、D、E 5个用户,其中用户 A 喜欢物品 a、b、c,用户 B 喜欢物品 a、b等等。
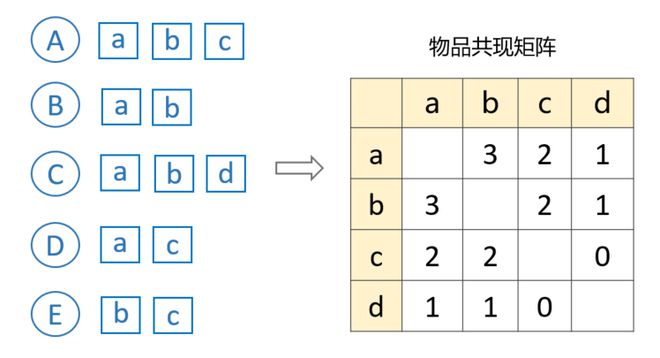
所谓共现,即:两个物品被同一个用户喜欢了。比如物品 a 和 b,由于他们同时被用户 A、B、C 喜欢,所以 a 和 b 的共现次数是3,采用这种统计方法就可以快速构建出共现矩阵。
第二步:计算物品的相似度矩阵 对于 Item-CF 算法来说,一般不采用前面提到的余弦距离来衡量物品的相似度,而是采用下面的公式:
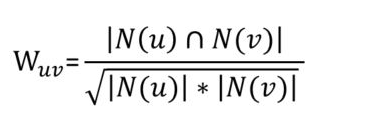
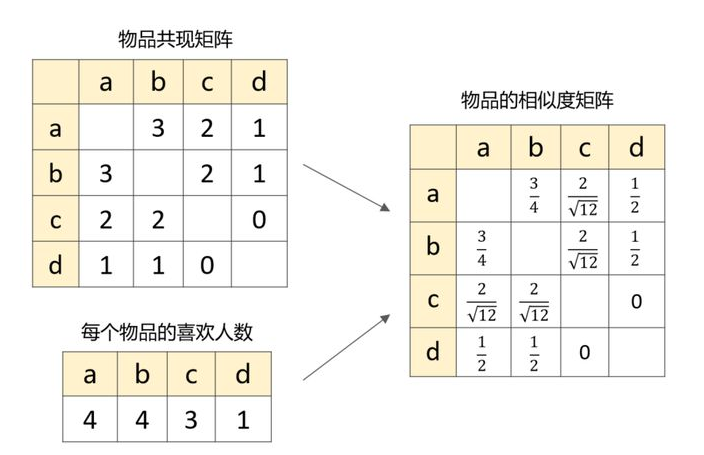
其中, N(u) 表示喜欢物品 u 的用户数,N(v) 表示喜欢物品 v 的用户数, 两者的交集表示同时喜欢物品 u 和物品 v 的用户数。 很显然,如果两个物品同时被很多人喜欢,那么这两个物品越相似。 基于第1步计算出来的共现矩阵以及每个物品的喜欢人数,便可以构造出物品的相似度矩阵:
第三步:推荐物品 最后一步,便可以基于相似度矩阵推荐物品了,公式如下:
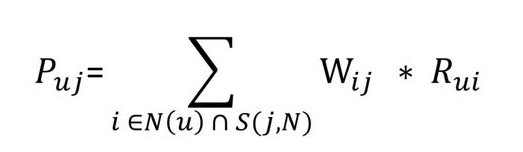
其中,Puj 表示用户 u 对物品 j 的感兴趣程度,值越大,越值得被推荐。N(u) 表示用户 u 感兴趣的物品集合,S(j,N) 表示和物品 j 最相似的前 N 个物品,Wij 表示物品 i 和物品 j 的相似度,Rui表示用户 u 对物品 i 的兴趣度。
上面的公式有点抽象,直接看例子更容易理解,假设我要给用户 E 推荐物品,前面我们已经知道用户 E 喜欢物品 b 和物品 c,喜欢程度假设分别为 0.6 和 0.4。那么,利用上面的公式计算出来的推荐结果如下:
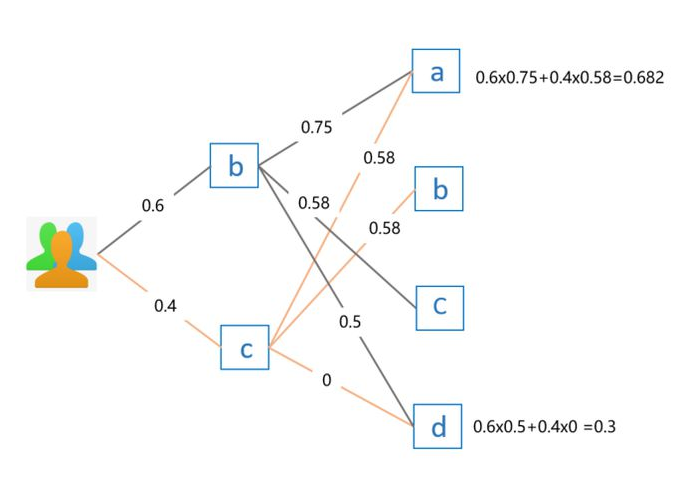
因为物品 b 和物品 c 已经被用户 E 喜欢过了,所以不再重复推荐。最终对比用户 E 对物品 a 和物品 d 的感兴趣程度,因为 0.682 > 0.3,因此选择推荐物品 a。
从0到1搭建一个推荐系统
有了上面的理论基础后,我们就可以用 Python 快速实现出一个推荐系统。
- 选择数据集
这里采用的是推荐领域非常经典的 MovieLens 数据集,它是一个关于电影评分的数据集,官网上提供了多个不同大小的版本,下面以 ml-1m 数据集(大约100万条用户评分记录)为例。
下载解压后,文件夹中包含:ratings.dat、movies.dat、users.dat 3个文件,共6040个用户,3900部电影,1000209条评分记录。各个文件的格式都是一样的,每行表示一条记录,字段之间采用 :: 进行分割。
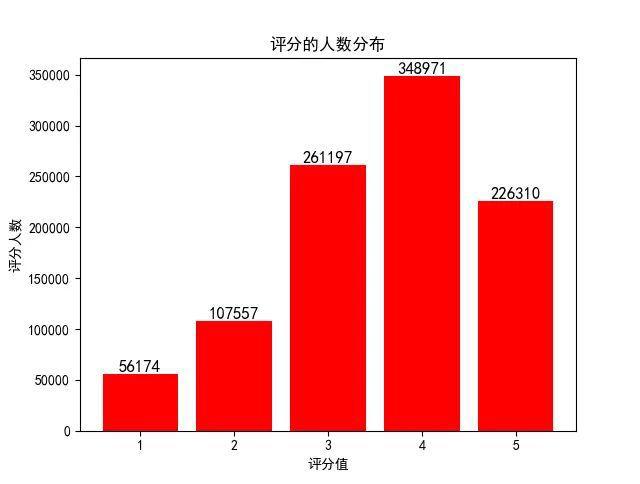
以ratings.dat为例,每一行包括4个属性:UserID, MovieID, Rating, Timestamp。通过脚本可以统计出不同评分的人数分布:
- 读取原始数据
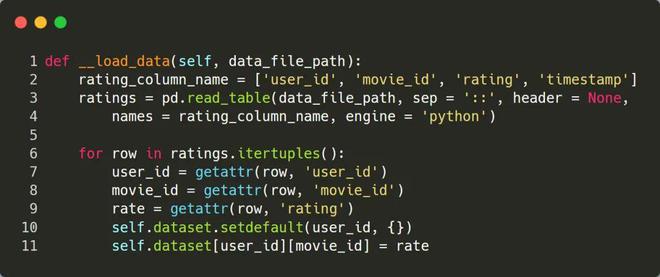
程序主要使用数据集中的 ratings.dat 这个文件,通过解析该文件,抽取出 user_id、movie_id、rating 3个字段,最终构造出算法依赖的数据,并保存在变量 dataset 中,它的格式为:dict[user_id][movie_id] = rate
- 构造物品的相似度矩阵 基于第 2 步的 dataset,可以进一步统计出每部电影的评分次数以及电影的共生矩阵,然后再生成相似度矩阵。
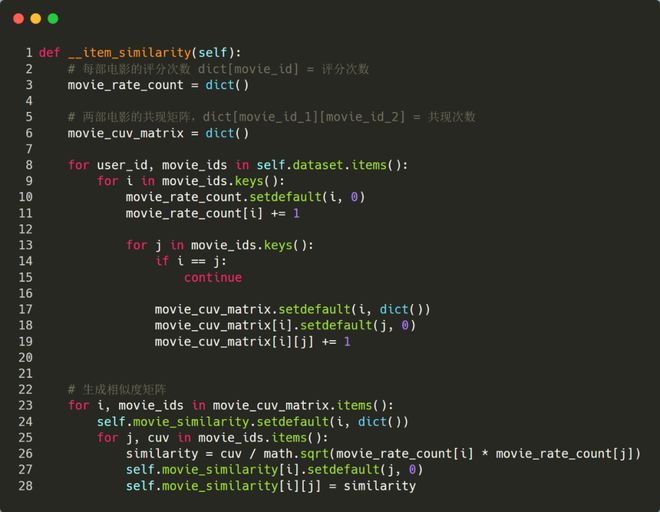
- 基于相似度矩阵推荐物品 最后,可以基于相似度矩阵进行推荐了,输入一个用户id,先针对该用户评分过的电影,依次选出 top 10 最相似的电影,然后加权求和后计算出每个候选电影的最终评分,最后再选择得分前 5 的电影进行推荐。
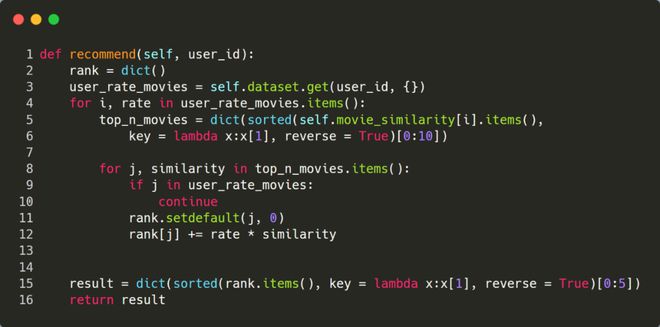
- 调用推荐系统 下面选择UserId=1 这个用户,看下程序的执行结果。由于推荐程序输出的是 movieId 列表,为了更直观的了解推荐结果,这里转换成电影的标题进行输出。
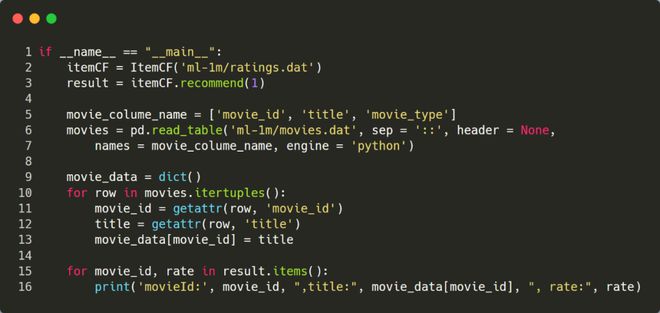
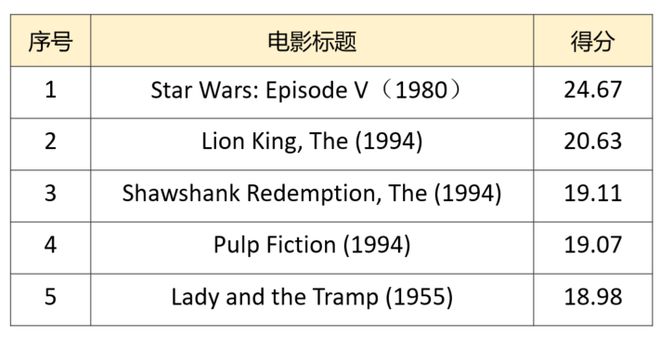
最终推荐的前5个电影为:
线上推荐系统的挑战

确定方向过程
针对完全没有基础的同学们 1.确定机器学习的应用领域有哪些 2.查找机器学习的算法应用有哪些 3.确定想要研究的领域极其对应的算法 4.通过招聘网站和论文等确定具体的技术 5.了解业务流程,查找数据 6.复现经典算法 7.持续优化,并尝试与对应企业人员沟通心得 8.企业给出反馈
腾讯云开发者
