综述 | 深度学习在多维时间序列插补中的应用

无处不在的缺失值导致多元时间序列数据只能部分观测,破坏了时间序列的完整性,阻碍了有效的时间序列数据分析。近年来,深度学习插补方法在提升损坏时间序列数据质量方面取得了显著的成功,从而提高了下游任务的性能。
本文介绍一篇来自香港科技大学与华为诺亚方舟实验室的研究工作,研究者主要对近期提出的深度学习插补方法进行了全面的调查。首先,为所审查的方法提出了一个分类体系,然后通过强调它们的优点和局限性,对这些方法进行了结构化的综述。此外还进行了实证研究,以研究不同的方法,并比较它们对下游任务的增强效果。最后,指出了多元时间序列插补未来研究中的开放问题。

【论文标题】Deep Learning for Multivariate Time Series Imputation: A Survey
【论文地址】https://arxiv.org/abs/2402.04059
【论文源码】https://github.com/WenjieDu/Awesome_Imputation
论文概述
在金融、医学和交通等各个领域的多元时间序列数据收集过程中,通常充满挑战和不确定性,例如传感器故障、系统环境不稳定、隐私顾虑或其他原因。这导致数据集通常包含大量缺失值,并可能对下游分析和决策制定的准确性和可靠性产生显著影响。因此,探索如何合理有效地填充多元时间序列数据中的缺失成分,是一项吸引人且至关重要的任务。
较早的统计插补方法历来被广泛用于处理缺失数据。这些方法用统计量(例如零值、平均值和最后一个观测值)或简单的统计模型(包括ARIMA、ARFIMA和SARIMA)来替代缺失值。此外,机器学习技术,如回归、K近邻、矩阵分解等,在文献中已逐渐崭露头角,用于解决多元时间序列中的缺失值问题。这些方法的关键实现包括 KNNI、TIDER、MICE 等。尽管统计和机器学习插补方法简单且高效,但它们难以捕捉时间序列数据中固有的复杂时间关系和变化模式,因此性能有限。
近年来,深度学习插补方法在缺失数据插补方面表现出了强大的建模能力。这些方法利用强大的深度学习模型,如 Transformer、变分自编码器(VAEs)、生成对抗网络(GANs)和扩散模型,来捕捉时间序列的内在属性和潜在复杂动态。通过这种方式,深度学习插补方法可以从观测数据中学习真实的基础数据分布,从而为缺失成分预测出更可靠和合理的值。鉴于多元时间序列插补是后续时间序列分析的关键数据预处理步骤,对深度多元时间序列插补方法进行全面系统的综述将极大地促进时间序列领域的发展。
该论文致力于弥补现有知识差距,对深度学习在多元时间序列插补(MTSI)方面的最新进展进行全面总结。首先,简要介绍了该主题,然后提出了一种新的分类方法,从插补不确定性和神经网络架构两个角度对方法进行分类。插补不确定性反映了对缺失数据插补值的信心,捕捉这种不确定性涉及随机生成样本并基于这些不同样本进行插补。因此,研究者将插补方法分为预测性方法和生成性方法。预测性方法提供固定估计值,而生成性方法则提供可能的值分布,以考虑插补不确定性。对于神经网络架构,研究者探讨了多种针对 MTSI 量身定制的深度学习模型,包括基于循环神经网络(RNN)的模型、基于图神经网络(GNN)的模型、基于卷积神经网络(CNN)的模型、基于注意力的模型、基于变分自编码器(VAE)的模型、基于生成对抗网络(GAN)的模型以及基于扩散的模型。
本文的贡献主要包括:
- 提出了一种新的深度多元时间序列插补方法分类法,综合考虑了插补不确定性和神经网络架构,并进行了全面的方法综述;
- 通过研究者开发的PyPOTS工具包对插补算法进行了深入的实证评估;
- 探讨了MTSI领域未来的研究机会。
插补方法分类
为了总结现有的多元时间序列插补方法,研究者从插补不确定性和神经网络架构两个角度提出一个分类体系,如图1所示,并在表1中更详细地概述了这些方法。
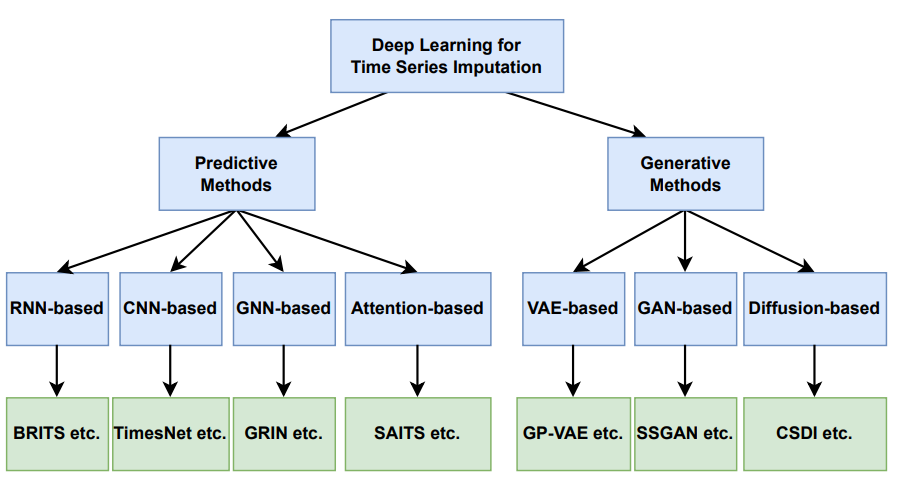
图1
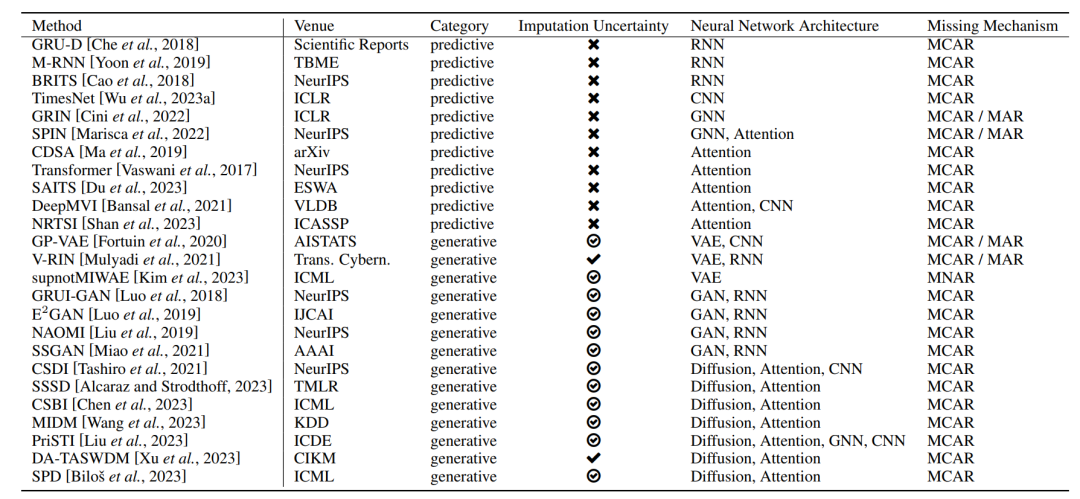
表1
在插补不确定性方面,研究者根据插补方法是否能够产生反映插补过程固有不确定性的多种插补结果,将其分为预测型和生成型两类。预测型方法通常提供单一的插补值,而不考虑插补过程中的不确定性。相比之下,生成型方法能够产生多个可能的插补结果,从而更全面地反映数据的不确定性。
在神经网络架构方面,研究者考察了专门为时间序列插补设计的深度学习模型。这些模型包括基于循环神经网络(RNN)的模型、基于卷积神经网络(CNN)的模型、基于图神经网络(GNN)的模型、基于注意力机制的模型、基于变分自编码器(VAE)的模型、基于生成对抗网络(GAN)的模型以及基于扩散模型的模型。
在接下来的两个部分中,将从这两个角度深入探讨现有的深度时间序列插补方法。通过对这些方法的分析和比较,我们可以更好地理解它们的特点、适用场景以及潜在的局限性,为未来的研究和实践提供有价值的参考。
预测型-插补方法分类
本节深入探讨预测型插补方法,主要讨论四种类型:基于循环神经网络(RNN)的模型、基于卷积神经网络(CNN)的模型、基于图神经网络(GNN)的模型以及基于注意力机制的模型。
01、基于RNN的模型
作为一种自然建模序列数据的方式,循环神经网络(RNNs)在高级时间序列分析的主题上得到了早期的发展,插补也不例外。GRU-D 是 GRU 的一个变种,旨在处理包含缺失值的时间序列。它通过一个时间衰减机制进行调节,该机制以时间滞后矩阵δi 作为输入,并建模由缺失值引起的时间不规则性。受名为 Hodgkin–Huxley 的生物神经模型启发,时间信念记忆(Temporal belief memory)被提出来处理缺失数据,它通过双向 RNN 计算每个特征最后观测值的信念,并根据其相应的信念对缺失值进行插补。M-RNN 是一种多方向工作的 RNN 变种。该模型通过双向 RNN 模型在数据流内部进行插值,并通过全连接网络在数据流之间进行插补。BRITS 使用双向 RNN 对不完整时间序列进行建模。它将缺失值作为 RNN 图的变量,并用 RNN 的隐藏状态填充缺失数据。除了插补外,BRITS 还能够同时处理时间序列分类任务。M-RNN 和 BRITS 都采用了来自 GRU-D 的时间衰减函数,以捕获有信息量的缺失性来提高性能。后续的工作,则将 RNN 与 GAN 结构相结合,以输出更高精度的插补结果。
02、基于CNN的模型
卷积神经网络(CNNs)是一种基础的深度学习架构,广泛应用于复杂的时间序列分析中。TimesNet 创新性地引入了快速傅里叶变换,将一维时间序列重构为二维格式,从而方便使用 CNNs 进行数据处理。同样在 GP-VAE 中,CNNs 在编码器和解码器中都扮演着骨干的角色。此外,在基于注意力的模型(如 DeepMVI )和基于扩散的模型(如CSDI )中,CNNs 作为关键的特征提取器,将输入数据映射到嵌入空间以供后续处理。
03、基于GNN的模型
基于 GNN 的模型将时间序列视为图序列,利用学习到的节点表示来重构缺失值。GRIN 是第一个用于 MTSI(多时间序列插补)的基于图的循环架构。GRIN 利用双向图循环神经网络有效地利用时间动态和空间相似性,从而在插补精度上取得了显著的提升。此外,还开发了 SPIN ,它在 GNN 框架中整合了一种独特的稀疏时空注意力机制。这种机制显著克服了 GRIN 中的误差传播问题,并增强了对高度缺失数据所呈现的数据稀疏性的鲁棒性。
04、基于注意力机制的模型
自提出 Transformer 以来,自注意力机制被广泛用于建模包括时间序列在内的序列数据。CDSA 被提出来通过联合学习时间、地点和测量值来插补带地理标签的时空数据。DeepMVI 将 Transformer 与卷积技术相结合,定制了关键的查询设计,以有效地解决缺失值的插补问题。对于每个时间序列,DeepMVI 利用注意力机制同时提取长期季节性、粒度局部和跨维度的嵌入,然后将它们拼接起来以预测最终输出。NRTSI 直接利用 Transformer 编码器进行建模,将时间序列数据作为一组时间戳和测量值元组来处理。作为一个排列模型,该模型必须遍历时间维度以处理时间序列。SAITS 采用了一种自监督训练方案来处理缺失数据,该方案整合了双重联合学习任务:一个掩码插补任务和一个观测重构任务。该方法采用两个对角掩码自注意力块和一个加权组合块,利用注意力权重和缺失指示器来提高插补精度。除了上述模型外,注意力机制还被广泛用于构建扩散模型中的去噪网络,如 CSDI、MIDM、PriSTI 等。
05、预测型插补模型优缺点
基于 RNN 的模型擅长捕捉序列信息,但由于其顺序处理特性和内存限制,它们在处理长序列时可能会遇到可扩展性问题。
虽然 CNN 已经发展了数十年,并且是捕捉邻域信息和局部连接性的有用特征提取器,但其内核大小和工作机制本质上限制了它们作为时间序列数据主干的性能。
由于注意力机制,基于注意力的模型通常在插补任务中优于基于 RNN 和 CNN 的方法,因为它们处理长距离依赖关系和并行处理的能力更出色。
基于 GNN 的方法为时空动态提供了更深入的理解,但它们通常伴随着计算复杂性的增加,这对于大规模或高维数据来说是一个挑战。
生成型-插补方法分类
生成式方法本质上建立在诸如 VAEs、GANs 和扩散模型等生成式模型的基础上。它们的特点是能够为缺失的观测值生成多样化的输出,从而能够量化插补的不确定性。通常,这些方法从观察到的数据中学习概率分布,然后为缺失的观测值生成与这些学习到的分布相一致的略有不同的值。
本节探讨生成式插补方法,主要包括三种主要类型:基于 VAE 的模型、基于 GAN 的模型和基于扩散的模型。
01、基于VAE的模型
VAE 采用编码器-解码器结构,通过最大化边缘似然的证据下界(ELBO)来逼近真实数据分布。这个 ELBO 强制形成一个高斯分布的潜在空间,解码器从中重构出多样化的数据点。
在[Fortuin et al., 2020]中,作者提出了首个基于 VAE 的插补方法 GP-VAE,其中在潜在空间中利用了高斯过程先验来捕捉时间动态。此外,GP-VAE 中的 ELBO 仅针对数据的观测特征进行评估。在[Mulyadi et al., 2021]中,作者设计了 V-RIN,以减轻缺失值插补中偏差估计的风险。V-RIN 通过在模型输出上容纳高斯分布来捕获不确定性,特别是将VAE模型重建数据的方差解释为不确定性度量。然后,它建模时间动态,并通过不确定性感知的 GRU 将这种不确定性无缝地集成到插补数据中。最近,[Kim et al., 2023]提出了 supnotMIWAE,并引入了一个额外的分类器。他们扩展了 GP-VAE 中的 ELBO,以建模观测数据、其掩码矩阵和标签的联合分布。通过这种方式,他们的 ELBO 有效地建模了插补不确定性,而额外的分类器则鼓励 VAE 模型产生更有利于下游分类任务的缺失值。
02、基于GAN的模型
GAN 通过两个组件之间的最小最大游戏促进对抗训练:一个生成器旨在模仿真实数据分布,而一个判别器则负责区分生成的数据和真实数据。这种动态促进了合成数据的逐步细化,使其越来越接近真实样本。
在[Luo et al., 2018]中,作者提出了一个两阶段的 GAN 插补方法(GRUI-GAN),这是首个基于 GAN 的时间序列数据插补方法。GRUI-GAN 首先通过标准的对抗训练方式学习观察到的多元时间序列数据的分布,然后优化生成器的输入噪声,以进一步最大化生成的和观察到的多元时间序列数据之间的相似性。然而,GRUI-GAN 的第二阶段需要大量时间来找到最佳匹配的输入向量,而且这个向量并不总是最佳的,特别是当“噪声”的初始值设置不当时。随后,进一步提出了一个端到端的 GAN 插补模型 E2GAN [Luo et al., 2019],其中生成器采用去噪自编码器模块,以避免 GRUI-GAN 中的“噪声”优化阶段。
同时,在[Liu et al., 2019]中,作者提出了一个非自回归多分辨率 GAN 模型(NAOMI),其中生成器由前向-后向编码器和多分辨率解码器组成。插补数据以非自回归的方式由多分辨率解码器递归生成,这缓解了高缺失率和长序列时间序列数据场景中误差累积的问题。另一方面,在[Miao et al., 2021]中,作者提出了 USGAN,它通过将判别器与时间提醒矩阵相结合来生成高质量的插补数据。这个矩阵增加了判别器训练的复杂性,进而提高了生成器的性能。
此外,他们通过将 USGAN 扩展为半监督模型 SSGAN,进一步引入了额外的分类器。通过这种方式,SSGAN 利用了标签信息,从而使生成器能够在观察到的成分和数据标签的同时估计缺失值。这种半监督的设置允许模型在有限标签数据的情况下进行更有效的学习,并可能提高插补的准确性。
03、基于扩散的模型
扩散模型作为一类新兴的且强大的生成模型,擅长通过一系列扩散步骤的马尔可夫链逐步添加然后反转噪声,来捕获复杂的数据分布。与 VAE 不同,这些模型采用固定的训练过程,并操作保留输入数据维度的高维潜在变量。
[Tashiro et al., 2021] 中介绍的 CSDI 是专门为 MTSI 设计的首个扩散模型。与传统的扩散模型不同,CSDI 采用了一种条件训练方法,其中观察到的数据子集被用作条件信息,以促进剩余部分观察数据的生成。然而,CSDI 中的去噪网络依赖于两个变换器,这导致关于变量数量和时间序列长度的二次复杂性。这种设计限制引起了关于内存约束的担忧,特别是在对大量多元时间序列进行建模时。
为了应对这一挑战,[Alcaraz and Strodthoff, 2023] 的后续工作引入了 SSSD,它通过用结构化状态空间模型[Gu et al., 2022]替换变换器,解决了二次复杂性问题。这种修改在处理长时间多元时间序列时证明是有利的,因为它降低了内存溢出的风险。
另一种方法 CSBI,由[Chen et al., 2023]提出,通过将扩散过程建模为薛定谔桥问题来提高效率,该问题可以转化为计算友好的随机微分方程。这种方法有可能进一步推动扩散模型在时间序列插补领域的应用,并优化其性能。通过利用薛定谔桥问题的数学特性,CSBI 可能能够更精确地控制数据的生成过程,并在处理复杂和大规模时间序列数据时展现出更高的效率。
此外,扩散模型的性能受到条件信息构建和利用的显著影响。MIDM [Wang et al., 2023] 提出在去噪过程中从观察到的数据表示的条件分布中采样噪声,从而能够显式地保留观察到的数据和缺失数据之间的内在相关性。PriSTI [Liu et al., 2023] 将时空依赖性作为条件信息引入,即为去噪网络提供由条件特征计算得出的时空注意力权重,以实现时空插补。此外,DA-TASWDM [Xu et al., 2023] 建议将动态时间关系(即变化的采样密度)纳入去噪网络,以进行医学时间序列插补。
与上述将时间序列视为离散时间步的扩散方法不同,SPD [Bilosˇ et al., 2023] 将时间序列视为底层连续函数的离散实现,并使用随机过程扩散来生成插补数据。通过这种方式,SPD 将连续噪声过程作为不规则时间序列的归纳偏置,以更好地捕获真实的生成过程,特别是考虑到数据固有的随机性。这种方法有望提供更准确和可靠的插补结果,特别是在处理具有复杂模式和不规则采样间隔的时间序列数据时。通过利用连续函数的特性,SPD 能够捕捉时间序列中的细微变化,并生成与原始数据分布一致的插补值。
04、生成型插补模型优缺点
基于 VAE 的模型擅长显式地建模概率,并为理解数据分布提供了理论基础。然而,它们的生成能力往往受到限制,这可能会限制它们在捕获复杂数据变异性方面的性能。
基于 GAN 的模型在数据生成方面表现出色,能够提供高质量的插补值,且对原始数据分布的保真度令人印象深刻。然而,它们以难以训练而闻名,存在诸如梯度消失等问题,这可能会阻碍模型的稳定性和收敛性。
基于扩散的模型作为强大的生成工具崭露头角,具有捕获复杂数据模式的强大能力。然而,它们的计算复杂度相当高,并且在处理缺失部分和观察部分之间的边界连贯性方面存在问题。
实验效果
论文实验使用了三个真实世界的数据集进行测试,分别是 Air、PhysioNet2012 和 ETTm1。这些数据集常用于时间序列分析领域,具有不同的样本数量、序列长度、特征数量和缺失率。
从数字上看,各种方法在不同数据集上的表现各不相同,本研究中没有明显的优胜者,需要进一步的工作来深入比较预测性和生成性插补方法。值得注意的是,在像 Air 和 ETTm1 这样的数据集中,数据是由传感器连续记录的,缺失率相对较低,非参数的 LOCF 方法表现出令人称赞的性能。相反,在 PhysioNet2012 数据集中,由于缺失率较高,深度学习插补方法明显优于统计方法。这一观察结果证实了深度学习方法能够有效捕捉复杂的时序动态并准确学习数据分布,特别是在高度稀疏、离散观测的场景中。
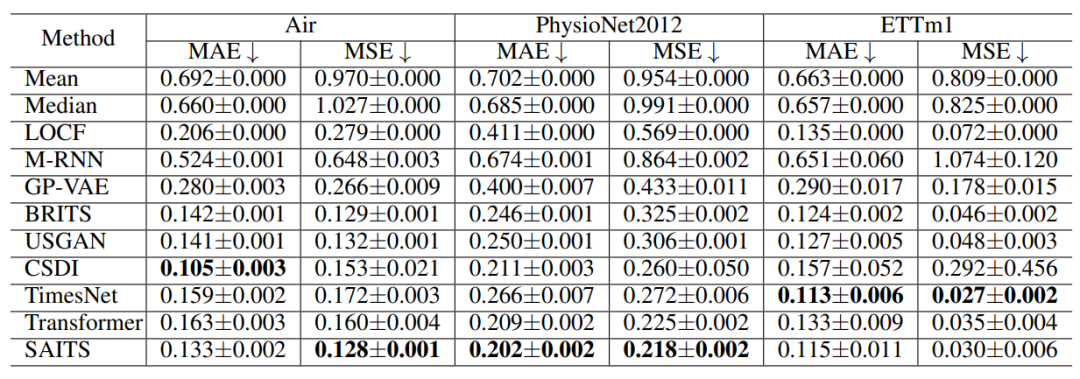
表2 Air、PhysioNet2012和ETTm1数据集上插补方法之间的MAE和MSE比较。所报告的值是五次运行的平均值±标准差
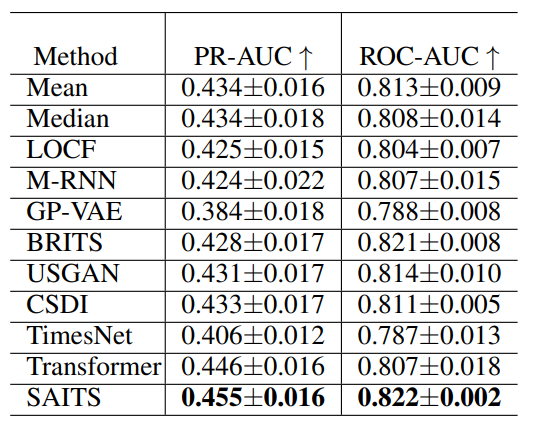
表3 五次运行中分类结果的平均值和标准差,这些数据有助于评估分类器在不同插补方法下的稳定性和一致性
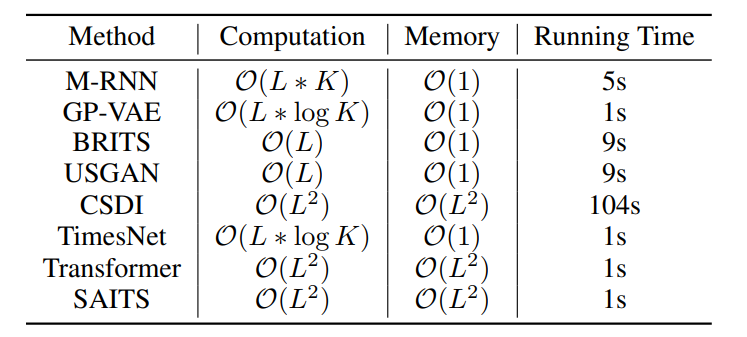
表4 插补模型的计算复杂度和空间复杂度,以及在PhysioNet2012测试集上的运行时间(秒)
总结
这篇论文系统地综述了近年来提出的深度学习插补方法。研究者提出了一种新的分类法来归类所评述的方法,并为每种方法提供了全面的介绍和实验比较。为了推动多变量时间序列插补(MTSI)领域的发展,论文指出以下几个方向进行探讨:
01、处理缺失数据的复杂模式
与 MCAR 和 MAR 不同,解决 MNAR 背景下的缺失数据问题需要创新性的方法,以实现更好的性能。这要求研究者不仅关注数据插补的技术细节,还需要深入理解缺失数据的生成机制,以便开发出更适应于复杂缺失模式的插补算法。
02、下游任务性能
尽管针对部分观测时间序列数据的最佳范式仍是未来研究的一个开放领域,但后一种端到端的方法看起来更有前景,尤其是在缺失模式中嵌入的信息对下游任务有帮助的情况下。这种端到端的方法通过同时优化插补和下游任务,有望更好地利用数据中的信息,提高整体性能。然而,这也带来了新的挑战,如如何设计有效的编码策略,以及如何平衡不同任务之间的损失函数等。因此,未来研究可以进一步探索这种端到端范式的设计和实现细节,以充分发挥其在处理缺失数据方面的潜力。
03、可扩展性
现有深度插补算法的高计算需求使得它们在大规模数据集上不太可行。因此,越来越需要利用并行和分布式计算技术的可扩展深度插补解决方案,以有效应对大规模缺失数据带来的挑战。
04、大模型在多元时间序列插补中的应用
LLMs 以其出色的泛化能力而闻名,即使在面对有限的数据集时也能展现出稳健的预测性能,这一特性在多元时间序列插补(MTSI)的背景下尤为宝贵。探索 LLMs 在 MTSI 中的集成代表了一个有前景的方向,有可能显著提高处理多元时间序列数据中缺失数据的效率和有效性。随着技术的不断发展和模型的改进,我们有理由期待 LLMs 在 MTSI 中发挥更大的作用,为解决现实世界中复杂的数据缺失问题提供新的途径。
腾讯云开发者
