又超越 CNN、Transformer ? CAF-MambaSegNet 探索无卷积和自注意力的图像分割新路径!
又超越 CNN、Transformer ? CAF-MambaSegNet 探索无卷积和自注意力的图像分割新路径!

卷积神经网络(CNNs)和基于Transformer的自注意力模型已成为医学图像分割的标准。本文证明,尽管卷积和自注意力被广泛使用,但它们并非分割的唯一有效方法。 打破传统,作者提出了一种基于Mamba的、无需卷积和自注意力的语义分割网络,名为CAF-MambaSegNet。具体来说,作者设计了一个基于Mamba的通道聚合器和空间聚合器,它们在每个编码器-解码器阶段独立应用。 通道聚合器跨不同通道提取信息,空间聚合器学习跨不同空间位置的特征。作者还提出了一个线性互联分解Mamba(LIFM)块,以减少Mamba的计算复杂度,并通过在两个分解Mamba块之间引入非线性来增强其决策函数。 作者的目标不是超越现有技术水平,而是展示这种创新的无卷积和自注意力方法如何激发除了已建立的CNNs和Transformers之外的研究,实现线性复杂度并减少参数数量。
Introduction
近期,Mamba在计算机视觉领域得到了重视,并将门控MLP []集成到H3 []的SSM中。读者可以参考以更全面地理解这一主题。在这里,作者将列出一些用于医学图像分割的相关Mamba架构。Mamba-UNet []将基于VMamba的[]编码器-解码器结构整合到UNet中。VMamba的Cross-Scan Module以四种方式扫描输入图像,以整合来自所有其他位置的特征元素的信息。Mamba-UNet在整个U型架构中使用这些VMamba块来捕捉强度图像的语义上下文。视觉Mamba UNet(VM-UNet)扩展了视觉Mamba ,使用名为Visual State Space的基础块。其非对称的编码器-解码器结构利用SSM捕获上下文信息,同时保持线性计算复杂性。
然而,这些混合方法解决了自注意力机制和卷积神经网络(CNN)所带来的挑战,并在密集预测任务(如分割)中利用了局部和全局特征。但是,无卷积方法近年来在计算机视觉中成为一种趋势,其中一些方法尝试仅利用基于自注意力的架构。例如,Kim等人[]提出了ReSTR用于指代图像分割,其中基于 Transformer 的编码器从每种模态(图像和文本)提取特征,然后通过由粗到精的分割解码器变换来从融合特征重建输出。Karimi等人[]提出了一个用于医学图像分割的无卷积3D网络。将3D图像块划分为个 Patch (k=3或k=5),并为每个 Patch 计算一个1D嵌入。他们的方法通过 Patch 嵌入之间的自注意力来预测块的中心 Patch 。MLP-Mixer []提出了一个仅基于多层感知机(MLPs)的图像分类任务的替代架构。通道混合和 Token 混合MLPs分别学习每个位置的特征和不同空间位置( Token )之间的特征。
尽管这些最新的模型试图克服CNN带来的挑战,但它们基于具有二次计算复杂度和高内存问题的自注意力。本文提出了一种无卷积方法,以减轻基于卷积架构的限制,以及一种无需自注意力的方法,它以线性复杂度带来了自注意力的好处,即全局感受野、动态权重机制和长距离依赖。
本文的贡献包括:
- 在作者了解的范围内,作者首次提出了一个基于Mamba的无卷积和无自注意力的分割网络,即CAF-MambaSegNet。
- 作者提出了线性互连分解Mamba(LIFM)块,以减少Mamba的可训练参数并增强其非线性,并为不同的扫描方向策略提出了一种权重共享策略,特别是针对视觉Mamba的两个扫描方向策略,进一步降低计算复杂度同时保持准确性。
- 作者引入了Mamba通道聚合(MCA)和Mamba空间聚合(MSA),并展示了它们如何分别沿着特征的通道和空间维度学习信息。
- 作者进行了广泛的消融研究,以展示每个组件的有效性。作者提出的基于Mamba的架构在心脏图像分割任务上与现有最先进的分割方法进行了比较,包括纯CNN、自注意力和混合自注意力方法,以及将原始基于Mamba的架构与CNN结合使用的方法。
Methodology
提出的卷积和无自注意力分割网络,CAF-MambaSegNet,如图1(a)所示。作者去除了Mamba块内的“局部卷积”以支持作者提出的无需卷积的方法,如图1(b)所示。所提出的架构完全由SSMs和线性层构建,在参数更少的情况下,性能与现有最先进的方法相当。本节将解释CAF-MambaSegNet的组成部分。
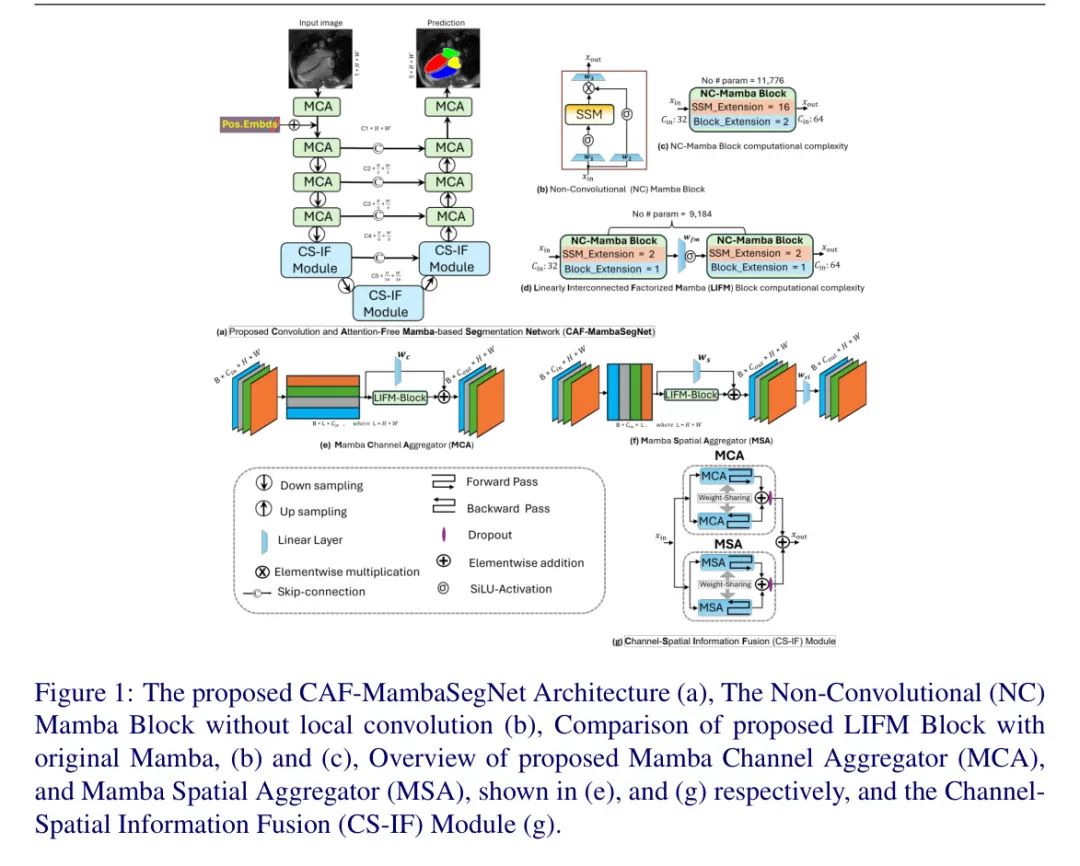
Factorized Mamba
受到深度CNNs[Ξ]的启发,其中堆叠的两个卷积滤波器具有的有效感受野,作者提出了分解Mamba的想法,这使得决策函数更具辨别性,同时也减少了参数数量。Mamba的“块扩展因子”_(E)和“SSM状态扩展因子”(D)控制Mamba的整体复杂性。更具体地说,使用具有学习权重和的线性层扩展Mamba块的维度,而在SSM内投射维度。作者用不同的和因子实现了Mamba块,并分析了它们的计算复杂性,如表1补充材料所示。在Mamba块中,大多数参数来自,的增加最小。大多数现有的基于Mamba的网络使用图1(c)中显示的默认SSM和Mamba块扩展,这在计算上代价高昂,一个单独的Mamba块带来了11,776个可训练参数(对于_c__in=32和_c__out_=64)。从数学上讲,它可以表示为,
其中,,是图1(b)中用于输入投影的可学习权重,表示逐元素乘法,是SiLU激活[Ξ]。
作者的分解Mamba块分离了SSM和Mamba的扩展参数,如图1(d)所示。作者在两个Mamba块之间添加了一个线性层,然后是SiLU激活[Ξ],以增加更多的非线性,并将其命名为线性互联分解Mamba(LIFM)块,用于作者提出的架构中。一个单独的分解Mamba块有4,608个参数(对于_c__in_=32和_c__out_=64),而提出的LIFM块只需要9,184个可训练参数。对于第一个分解Mamba块和线性层, = = 32,对于第二个分解Mamba块, = 64。从数学上讲,作者可以将LIFM块表示为,
最后,
其中,1 = 2 = 2,1 = 2 = 1,表示两个分解Mamba块之间的线性层。
从经验上讲,作者还发现一个大的Mamba块很容易过拟合数据并增加网络的总体计算负担。因此,作者在每个阶段分解了较大的Mamba块,并使用了两个连续的较小的块。这种分解方法减少了可训练参数的数量,并帮助网络增加其非线性,以便在数据中学习更复杂的模式和表示。
Mamba Channel Aggregator
曼巴通道聚合器(MCA)旨在学习跨通道信息,如图1(e)所示,学习不同通道的每个位置特征。类似于基于CNN的编码器-解码器结构,在每个编码器阶段通道数增加为,在每个解码器阶段减少为。对于通道聚合器,传入的特征被 Reshape 为,其中(B:批大小,C:通道数,H:高度,W:宽度),L = HW。然后,输入被分为两个分支,其中一个分支应用LIFM块,第二个分支作为残差连接,使用线性层,并通过元素逐加操作与第一个分支的特征相结合。从数学上讲,它可以表示为,
其中,表示 Reshape 函数,执行逆操作,是MCA的残差线性层,表示元素逐加操作。### 曼巴空间聚合器
如图1(f)所示,曼巴空间聚合器(MSA)旨在学习不同空间位置的信息,并使它们之间进行通信。空间聚合器的计算复杂度取决于特征的空间维度,因此它只用于U形网络的低维特征。更具体地说,它在瓶颈处、瓶颈前一个编码器阶段以及瓶颈后一个解码器阶段使用,如图1(a)所示。对于空间聚合器,传入的特征被 Reshape 为,其中L = HW。特征遵循与MCA相同的协议,最后使用线性层来扩展(在编码器中)或压缩(在解码器中)通道数。从数学上讲,它可以表示为,
这里,表示 Reshape 函数,执行逆操作,是MSA的残差线性层,是一个线性层,用于在MSA中增加或减少通道数,以与MCA相匹配。
Bidirectional Information Learning
受到视觉曼巴(Vision Mamba)[1]的启发,作者采用了双向扫描排列方案来实现MCA和MSA,如图1的补充材料所示。作者融入了双向SSMs,使网络具有空间感知能力。与视觉曼巴不同,作者发现为双向方案共享权重能带来更好的性能,同时降低计算复杂性,如表1的消融研究中所示。作者还尝试了多方向扫描排列,如四向[1]和八向方案[1]。然而,由于减少了复杂性和较小的数据集,采用所 Proposal 的权重共享策略增强的双向扫描方案是当前任务的最佳实践。
Channel-Spatial Information Fusion Module
通道-空间信息融合(CS-IF)模块包括MCA和MSA,并将沿通道和空间维度提取的信息进行合并,如图1(g)所示。输入特征传递给MCA和MSA,在那里,每个聚合体在前向传播和后向传播中都学习特征,并使用相应聚合体的同一实例,使得在利用权重时可以共享。通过元素 Level 的加法操作将两个传播的输出相加,为了避免过拟合,在每个聚合体的输出上应用了0.1的dropout。
Proposed CAF-MambaSegNet
提出的CAF-MambaSegNet结构,如图1(a)所示,在前四个编码阶段的卷积层中使用MCA从强度图像中提取特征。它还结合了正弦位置嵌入来编码空间上下文信息,使编码器能够理解图像内不同区域之间的相对位置。在每个编码阶段的特征也会通过一个2×2的平均池化层进行下采样。在接下来的编码阶段和瓶 Neck 分,作者实施了CS-IF模块,使模型能够在通道和空间维度上学习更丰富的特征。
在解码器方面,每阶段的特征通过一个2×2的双线性插值窗口进行上采样以匹配输出维度,瓶 Neck 分之后的第一阶段使用CS-IF模块,在所有其他解码器阶段使用MCA。在每个编码器-解码器阶段也实现了跳跃连接[]。最后,生成一个五类分割图(每个类别一个,左心房、右心房、左心室、右心室和背景),然后是sigmoid激活函数。
Experimental Validation
数据集详情: 作者使用了来自CMR×Recon MICCAI-2023挑战赛[]的分割数据。该数据集包含了300名受试者的多对比度、多视角、多切片和多线圈的心脏磁共振成像数据。挑战赛包括短轴(SAX)、双腔(2CH)、三腔(3CH)、四腔(4CH)长轴(LAX)视图以及T1映射和T2映射。作者使用了4CH-LAX电影图像及其相应的分割标签。一位专家放射科医生进行了手工标注,并为四个心腔提供了标注:左心房(标签=1),右心房(标签=2),左心室(标签=3)和右心室(标签=4)。
训练详情: 作者使用PyTorch实现了比较网络和所提出的框架,所有实验均使用配备40GB RAM的NVidia A100 GPUs进行。使用了AdamW[]优化器,, = [0.5,0.55];进行了500个训练周期的训练,使用Dice Loss[],初始学习率为0.0001,每100个周期减半。作为一个预处理步骤,每个输入强度图像通过其均值和标准差进行归一化。实施了各种强度和几何数据增强策略,包括高斯噪声、模糊、亮度对比、随机鬼影、旋转、缩放、随机翻转和随机仿射,以增强数据的多样性。为了公平比较,所有网络都使用相同的协议进行训练。实验使用了CMR×Recon MICCAI-2023挑战数据的五折交叉验证分割。
Ablation Studies
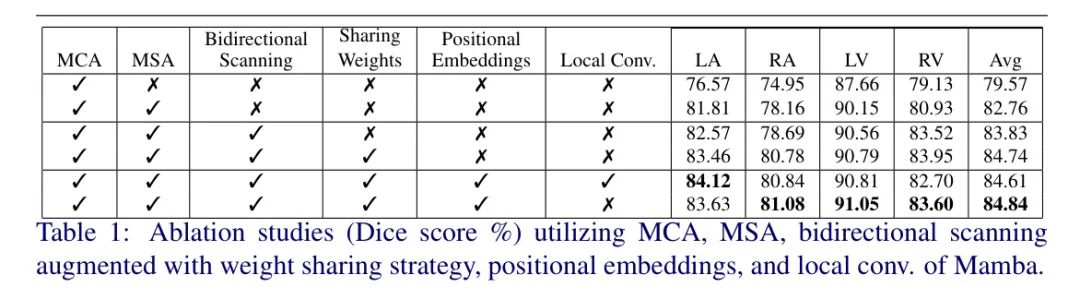
提出的CAF-MambaSegNet的有效性通过与不同消融版本的比较进行了评估,包括/不包括MCA/MSA、位置嵌入、双向扫描方案、权重共享策略以及Mamba局部卷积。
MCA和MSA: MSA促进了空间位置间的相互交流,并通过从CS-IF模块中移除它来评估其效率。由于MSA仅应用于网络中较低平面分辨率特征,因此作者仅在网络中使用了CA。表1的前两行列出了这一消融研究的定量结果,作者可以观察到使用MSA提高了所有评估指标,并在Dice评分上带来了平均超过3%的改进。
双向扫描和权重共享策略: 在每个编码器-解码器阶段引入的双向扫描方案提高了结果,如表1的第3行所示。然而,它为每次前向和后向扫描方案增加了额外的参数。所提出的双向扫描,通过共享策略减少参数并提高整体性能,如表1的第4行所示,平均Dice评分提高了约1%。
位置嵌入: CAF-MambaSegNet还利用正弦位置嵌入来编码输入图像序列中每个元素位置的空间信息[+(。这种差异在平均Dice和HD评分(分别为0.34和0.67)中表现出来,表明其鲁棒性和效率。值得注意的是,在比较方法中没有一种网络在精确分割所有四个解剖结构(左心房、右心房、左心室、右心室)方面普遍优于其他方法;相反,不同的方法在分割特定心腔方面表现出色。这突显了比较方法和提出方法之间性能的细微差异。
作者模型的参数利用效率值得注意。与参数数量从2513万到9585万的对手相比,作者的模型仅有2241万可训练参数。这种效率对于可能资源受限的实际部署至关重要。作者将作者模型的成功归因于一系列架构创新,包括将Mamba块分解的LIFM块;包括沿通道和空间维度捕捉信息的MCA和MSA的CS-IF模块;以及结合提出的权重共享策略的双向扫描方案。
图2:定性比较,(a,b,c)行展示了每个比较方法的成功案例,(d,e,f)行是一些失败案例的示例。
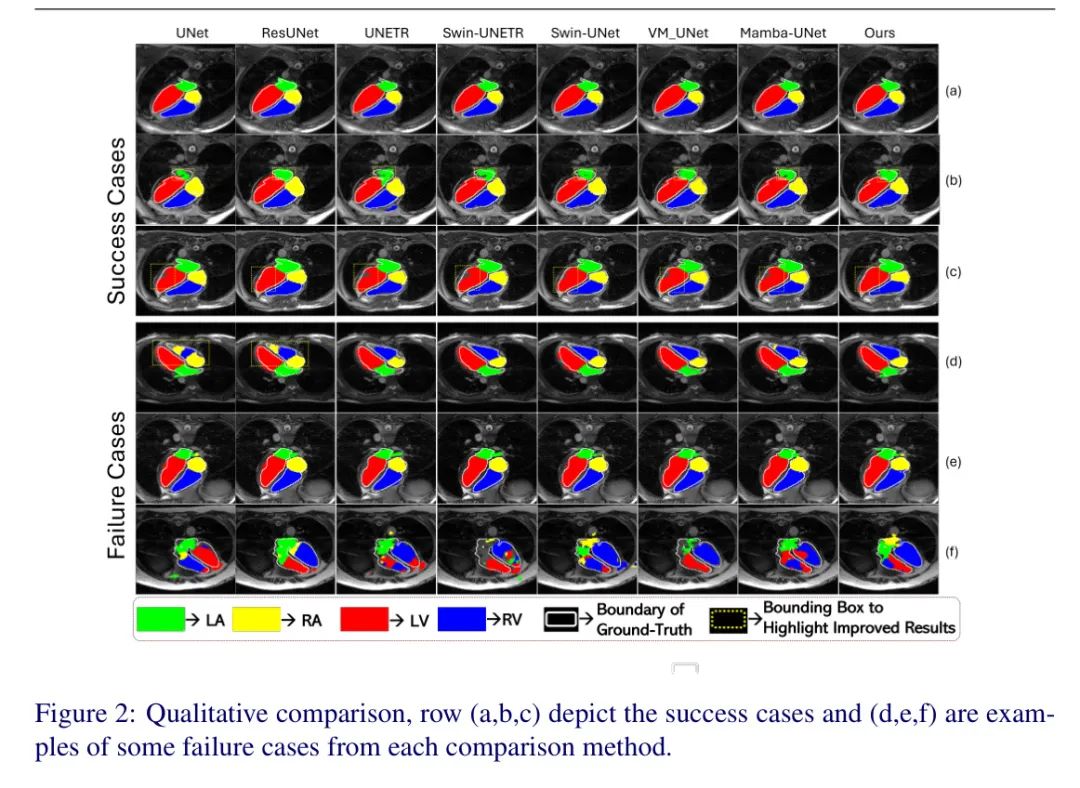
图2显示了视觉结果;为了公平比较,作者展示了每个比较网络的_成功_和_失败_结果。作者发现,残差连接和融合长距离依赖都有助于减轻失败案例。例如,在图2的(b,c)行中,提出的方法和带有残差连接的ResUNet比其他方法表现得更好。作者还通过移除所提方法中的残差连接来确认这种效果。从(d)行作者可以观察到,不使用自注意力或Mamba块的方法缺乏非局部推理,导致过度分割(右心室被分割成右心室和右心房)。(a)行描述了所有网络都获得准确分割结果的情况,而对于(f)行,所有评估方法的表现都不尽人意。这表明了图像特定特征的影响,并强调了更加强大和多样化的分割方法的重要性。
结论
作者是首个在没有卷积操作和自注意力机制的情况下提出基于Mamba的分割网络的团队,以展示基于SSM架构的力量。
作者为基于Mamba的方法引入了几个创新策略,以提高其性能并降低计算复杂性,包括线性互联分解Mamba(LIFM)块以减少可训练参数数量并增加决策函数,基于Mamba的空间和通道聚合器以学习不同空间位置的信息以及空间聚合器,以及双向权重共享策略方案。
参考
[1].Convolution and Attention-Free.
腾讯云开发者
