ICML 2024 | 时序异常检测应该如何设计有效的模型?

用机器学习做时间序列异常检测 (TAD) 受到有缺陷的评估指标、不一致的基准测试、缺乏模型选择适当性论证的困扰。
来自德国奔驰和卡尔斯鲁厄理工学院的研究者对 TAD 的现状进行了批判性分析,揭示了当前研究的误导性轨迹。研究者主张将重点从单纯追求新颖的模型设计转向改进基准实践,创建非琐碎数据集,并根据更简单的基线对复杂方法的有效性进行评估。
研究者的研究结果表明,需要探索和发展简单和可解释的 TAD 方法。在目前先进的基于深度学习的模型中,模型复杂性的增加几乎没有提供任何改进。

【论文标题】Position: Quo Vadis, Unsupervised Time Series Anomaly Detection?
【论文地址】https://arxiv.org/abs/2405.02678
【论文源码】https://github.com/ssarfraz/QuoVadisTAD
论文背景
时间序列异常检测在多个行业中都有广泛的应用。例如,车辆、制造工厂、机器人和患者监控系统等实际系统中,许多互联传感器会产生大量数据,这些数据可以用于检测异常行为。异常可以表现为单个不规则点或一组不规则点,其解释可能取决于系统的操作历史或子模块之间的互连性。
01、当前研究中的问题
- 评估指标的缺陷:当前的研究中普遍使用有缺陷的评估指标,这些指标可能会误导研究结果。
- 基准测试的不一致性:不同研究中使用的基准数据集和测试方法不一致,导致结果难以比较。
- 模型设计的合理性缺乏:许多新提出的基于深度学习的模型设计缺乏充分的理论或实验依据。
02、深度学习方法的应用
受自然语言处理和音频处理等领域成功的启发,许多最先进的深度学习架构被调整并应用于时间序列异常检测。这些方法旨在学习正常时间序列数据的潜在表示,并通过重建误差来检测异常。尽管这些方法初衷良好,但它们并未提供深度学习必要性的证据,且验证过程存在问题。
该论文指出,当前使用的评估协议(如点调整后的F1分数)存在严重缺陷,这些协议可能会偏向噪声预测,导致随机预测的性能优于最先进的方法。
研究者旨在通过严格的基准测试实践和研究模型的实用性来引导TAD社区朝着更有意义的进展方向前进。
- 提出了一些简单而有效的基线方法,并证明它们的性能与最先进的方法相当甚至更好,从而质疑增加模型复杂性是否真的有助于解决TAD问题。
- 通过这些背景信息,论文希望推动TAD领域的发展,强调改进评估协议和基准测试的重要性,以及探索和发展简单且可解释的TAD方法的必要性。
论文方法
该论文提出了几种简单而有效的基线方法,用于时间序列异常检测(TAD)。这些方法旨在挑战当前复杂深度学习模型的有效性,并提供更简单的替代方案。以下是论文中提出的主要方法:
01、有效的异常评估指标
传感器范围偏差(Sensor Range Deviation)
利用传感器在正常操作期间观察到的值范围来识别分布外(OOD)样本。如果测试数据点中的传感器值超出了正常范围,则可能表示存在异常。
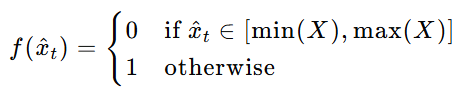
L2 范数(L2-Norm)
对于多变量时间序列数据,特定时间戳的向量大小可以作为检测OOD样本的相关统计量。通过计算向量的L2范数来作为异常分数。
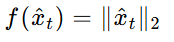
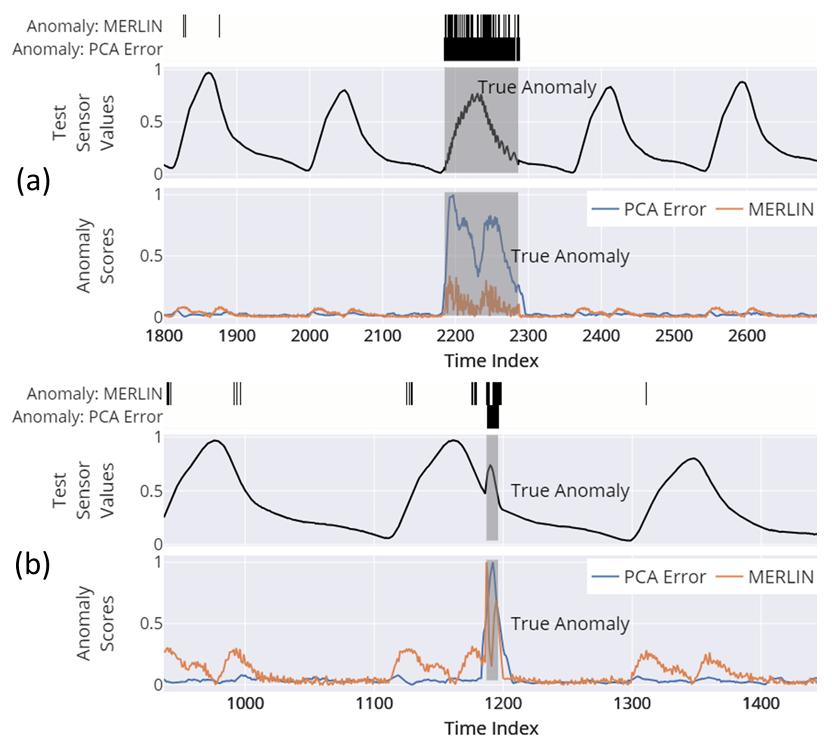
最近邻距离(NN-Distance)
异常样本应该与正常数据有较大的距离。因此,使用测试时间戳与训练数据之间的最近邻距离作为异常分数。
主成分分析重建误差(PCA Reconstruction Error)
使用PCA对训练数据进行降维,并计算测试数据的重建误差。重建误差可以作为异常分数。
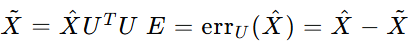
02、简单的神经网络基准
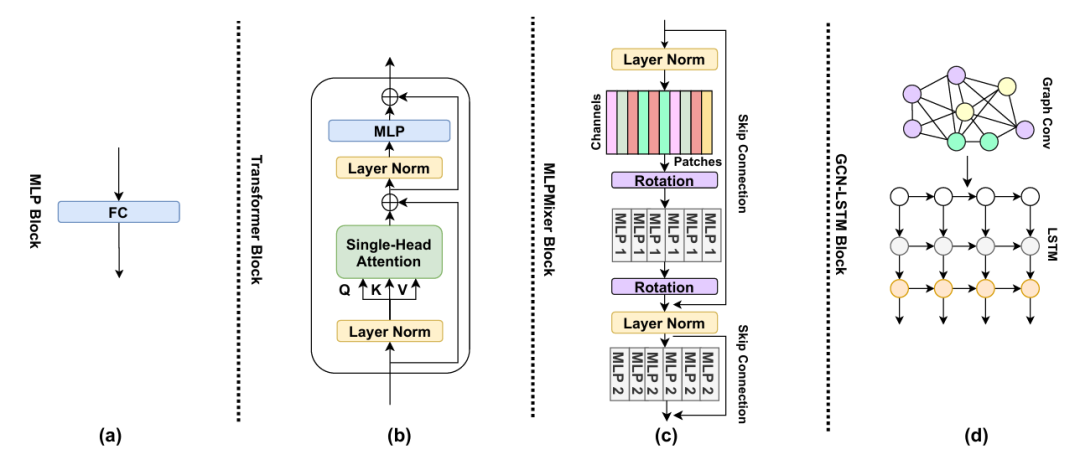
图:一个简单的神经网络基准
论文还提出了一些简单的神经网络基线模型,包括:
- 单层线性MLP作为自编码器(1-layer linear MLP as auto-encoder):使用没有激活函数的单层MLP作为自编码器。
- 单块MLP-Mixer(Single block MLP-Mixer):使用一个标准的MLP-Mixer块。
- 单块Transformer(Single Transformer block):使用一个单头注意力和一个全连接层作为基本的Transformer块。
- 单层GCN-LSTM块(1-layer GCN-LSTM block):使用一个GCN层和一个LSTM层来学习多变量时间序列数据的图结构和时间依赖性。
03、单变量时间序列表示
对于单变量时间序列数据,使用滑动窗口方法将每个时间戳表示为一个向量。通过这种方式,可以有效地发现异常。
04、评价指标
论文提出了一些简单有效的评估指标,包括:
- 标准F1分数(F1):用于评估单点检测的质量。
- 点调整后的F1分数(F1PA):调整预测以匹配真实异常区间。
- 时间序列范围F1分数(F1T):用于评估异常区间检测的质量。
这些方法通过简单有效的基线挑战了当前复杂深度学习模型的有效性,强调了在TAD领域中改进评估协议和基准测试的重要性。
实验结果
实验部分展示了提出的简单基线方法与当前最先进的深度学习模型在多个时间序列数据集上的性能对比。以下是实验结果的详细描述:
01、数据集
研究者使用了六个常用的基准数据集进行实验,包括三个多变量数据集(SWaT、WADI、SMD)和四个单变量数据集(UCR/Internal Bleeding)。每个数据集的统计信息如下:
- SWaT:51个传感器,训练集47520个时间戳,测试集44991个时间戳,4589个异常(占12.20%)。
- WADI-127:127个传感器,训练集118750个时间戳,测试集17280个时间戳,1633个异常(占9.45%)。
- WADI-112:112个传感器,训练集118750个时间戳,测试集17280个时间戳,918个异常(占5.31%)。
- SMD:38个传感器,训练集25300个时间戳,测试集25300个时间戳,1050个异常(占4.21%)。
- UCR/IB-16:1个传感器,训练集1200个时间戳,测试集6301个时间戳,12个异常(占0.19%)。
- UCR/IB-17:1个传感器,训练集1600个时间戳,测试集5900个时间戳,111个异常(占1.88%)。
- UCR/IB-18:1个传感器,训练集2300个时间戳,测试集5200个时间戳,102个异常(占1.96%)。
- UCR/IB-19:1个传感器,训练集3000个时间戳,测试集4500个时间戳,10个异常(占0.22%)。
02、实验设置
实验设置如下:
- 数据预处理:将特征缩放到[0, 1]区间,使用训练集的缩放参数对测试集进行缩放。
- 神经网络基线模型:在预测模式下训练,使用时间窗口大小为5,Adam优化器,学习率为0.001,批量大小为512。
- PCA重建误差:多变量数据使用前30个主成分,单变量数据使用前2个主成分,窗口大小为5。
03、实验结果
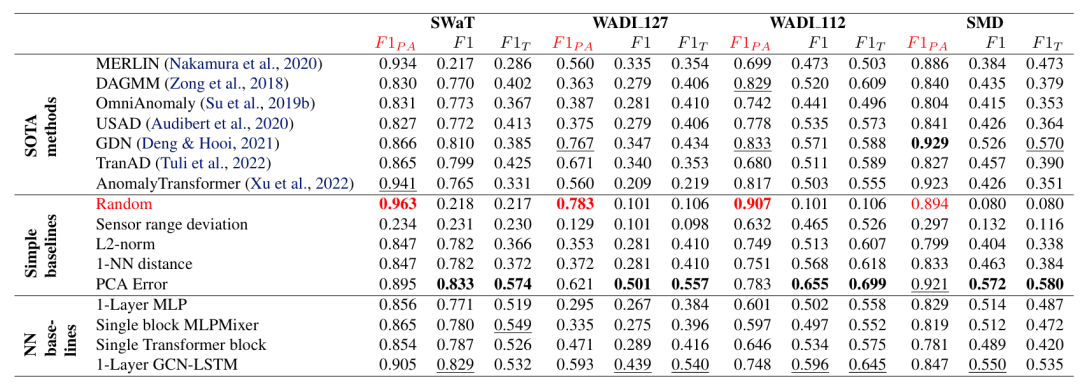
多变量数据集
下表格展示了在SWaT、WADI和SMD数据集上的实验结果,评估指标包括点调整后的F1分数(F1PA)、标准点F1分数(F1)和时间序列范围F1分数(F1T)。
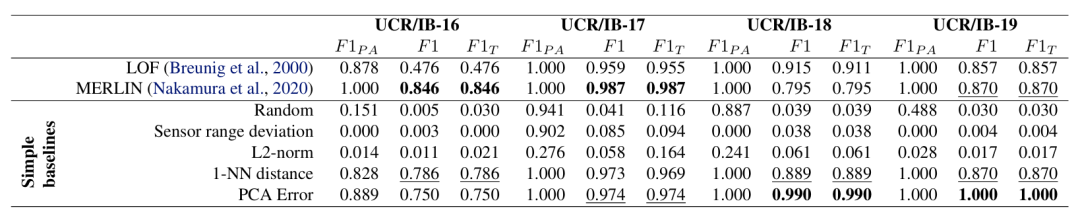
单变量数据集
下表格展示了在UCR/Internal Bleeding数据集上的实验结果,评估指标包括点调整后的F1分数(F1PA)、标准点F1分数(F1)和时间序列范围F1分数(F1T)。
总结
这篇论文表明,研究者提出的简单基线方法在多个数据集上表现优异,甚至在某些情况下超过了当前最先进的深度学习模型。这表明增加模型复杂性并不总是必要的,简单且可解释的方法在时间序列异常检测中同样具有重要价值。
腾讯云开发者
