【深度学习入门篇 ⑤ 】PyTorch网络模型创建

大家好,我是小森( ﹡ˆoˆ﹡ ) ! 易编橙·终身成长社群创始团队嘉宾,橙似锦计划领衔成员、阿里云专家博主、腾讯云内容共创官、CSDN人工智能领域优质创作者 。
今天我们学习PyTorch的网络模型创建,全面概括该怎么创建模型!
神经网络的创建步骤
- 定义模型类,需要继承
nn.Module - 定义各种层,包括卷积层、池化层、全连接层、激活函数等等
- 编写前向传播,规定信号是如何传输的
可以用 torchsummary 查看网络结构,如果没有的话,使用pip命令进行安装
pip install torchsummaryModule: 神经网络的模板
所有的神经网络模块都应该继承该模块
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def _init__( self):
super()._init_()
self.conv1 = nn.Conv2d(1,20,5)
self.conv2 = nn.Conv2d( 20,20,5)
def forward( self, x):
x = F.relu( self.conv1(x))
return F.relu(self.conv2(x) )神经网络中常见的各种层
常见的层包括:卷积层,池化层,全连接层,正则化层,激活层
导入层有两种方法: 一种是将其看作一个类,在
torch.nn里面 另一种是将其看作一个函数,在torch.nn.functional里面可以调用
全连接层
全连接层又称为线性层,所以函数名叫 Linear,执行的操作是𝑦=𝑥𝐴𝑇+𝑏
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)- in_feature代表输入数
- out_features代表输出数,即神经元数量
import torch
import torch.nn as nn
m = nn.Linear(2,3)
input = torch.randn(5,2)
output = m( input)
print(output.size() )输出:
torch.Size([5, 3])先搭建个只有一层的网络,用 torchsummry 查看网络结构
import torch
import torch.nn as nn
from torchsummary import summary
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(10, 1, bias=False)
def forward(self, x):
x = self.fc(x)
return x
if __name__ == '__main__':
network = NeuralNetwork()
summary(network, (10,)) # 这里调用 torchsummary 来打印网络结构输出:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 1] 10
================================================================
Total params: 10
Trainable params: 10
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.00
Estimated Total Size (MB): 0.00
----------------------------------------------------------------
Process finished with exit code 0我们再自定义输入到网络中:
if __name__ == '__main__':
network = NeuralNetwork()
network.to('cuda')
input = torch.randn(10)
input = input.to('cuda')
print('input=', input)
output = network(input)
print('output=', output)
result = output.detach().cpu().numpy()
print('result=', result)-
detach()用于从计算图中分离出一个张量(Tensor),使其成为一个新的张量,这个新张量不再需要计算梯度(即不会参与反向传播)
打印结果:
input= tensor([ 0.5767, -1.2199, 0.4407, 0.6083, -0.1758, 0.2291, -0.8924, 1.1664,
0.3445, 0.7242], device='cuda:0')
output= tensor([-0.0183], device='cuda:0', grad_fn=<SqueezeBackward4>)
result= [-0.01834533]激活函数
常见的激活函数包括 sigmoid,relu,以及softmax,学会他们怎么用,就会用其他激活函数了
Sigmoid
sigmoid是早期的激活函数

函数的示意图:
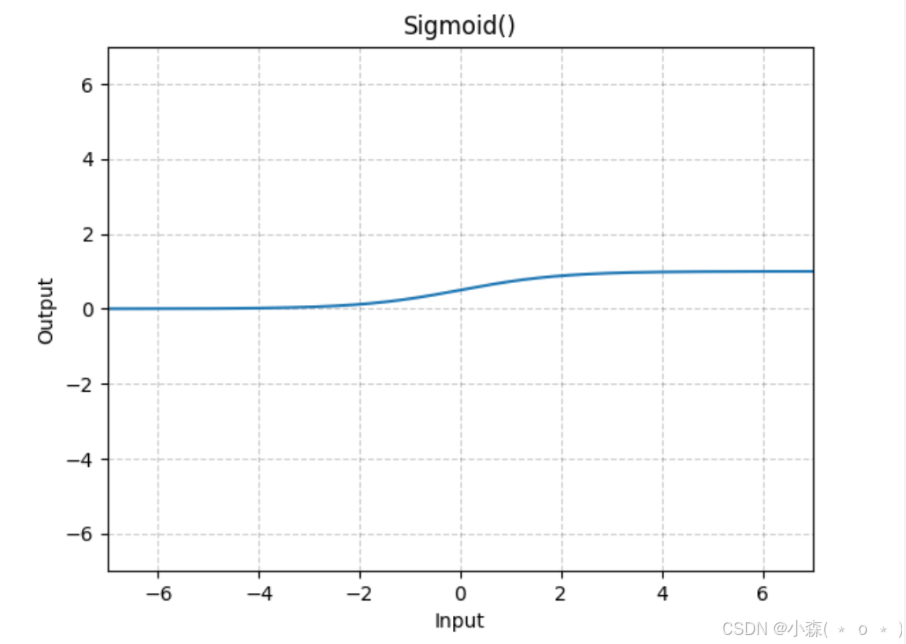
m = nn.Sigmoid()
input = torch.randn(5)
output = m(input)
print(input)
print(output)
# 输出
tensor([ 0.6759, -0.8753, -0.3187, 0.0088, 2.0625])
tensor([0.6628, 0.2942, 0.4210, 0.5022, 0.8872])ReLU
ReLU激活函数常放在全连接层、以及卷积层后面
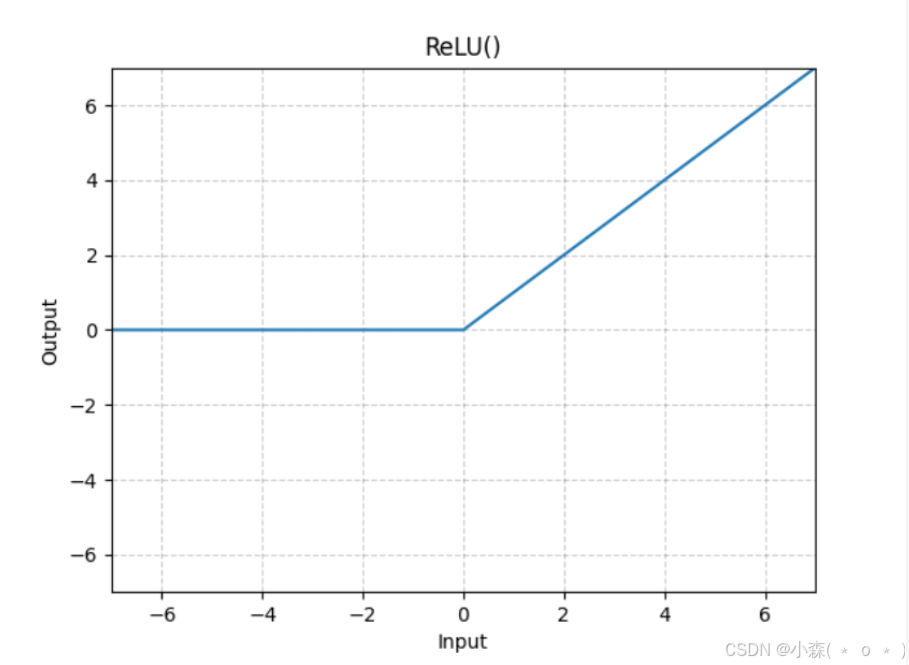
m = nn.ReLU() # 或m = F.ReLU()
input = torch.randn(5)
output = m(input)
print(input)
print(output)
# 输出
tensor([-2.8164, 0.8885, -0.9526, 0.3723, -0.2637])
tensor([0.0000, 0.8885, 0.0000, 0.3723, 0.0000])Softmax
softmax是在分类当中经常用到的激活函数,用来放在全连接网络的最后一层
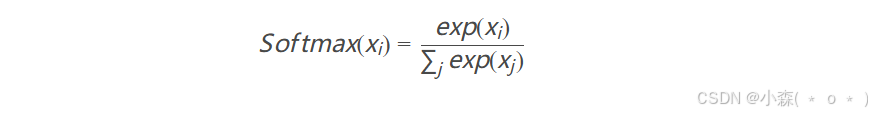
m = nn.Softmax(dim=1)
input = torch.randn(4,3)
output = m(input)
print(input)
print(output)
# 输出
tensor([[ 0.1096, 0.7095, 0.5996],
[-0.6431, -0.0555, 0.5332],
[-0.2367, -0.1851, 0.4029],
[-1.0242, 1.9747, 2.0828]])
tensor([[0.2245, 0.4090, 0.3665],
[0.1655, 0.2979, 0.5366],
[0.2532, 0.2667, 0.4801],
[0.0230, 0.4621, 0.5149]])随机失活Dropout
当 FC层过多,容易对其中某条路径产生依赖,从而使得某些参数未能训练起来
为了防止上述问题,在 FC层之间通常还会加入随机失活功能,也就是Dropout层
dropout的作用是随机失活的,通常加载FC层之间
m = nn.Dropout(p=0.5)
input = torch.randn(6,6)
output = m(input)
print(input)
print(output)输出:
tensor([[-2.1174, 0.1180, -1.2979, 0.3600, -1.0417, -1.3583],
[-0.2945, 1.0038, -0.9205, 2.5044, -1.2789, 0.4402],
[-0.4641, 1.3378, 0.1766, 0.1972, 1.6867, -1.7123],
[-1.1137, 1.1291, -0.1404, 0.6881, 0.3442, 0.7479],
[ 2.4966, -2.5837, 2.0277, -1.0195, 0.2140, -0.1453],
[-0.9259, 1.2443, -0.2939, 0.0304, -0.1057, -0.7959]])
tensor([[-4.2347, 0.0000, -0.0000, 0.0000, -0.0000, -2.7165],
[-0.5890, 2.0076, -0.0000, 0.0000, -2.5579, 0.0000],
[-0.0000, 0.0000, 0.3533, 0.3945, 3.3733, -3.4246],
[-0.0000, 2.2581, -0.0000, 1.3763, 0.0000, 0.0000],
[ 0.0000, -0.0000, 4.0554, -0.0000, 0.0000, -0.0000],
[-0.0000, 2.4887, -0.5878, 0.0608, -0.0000, -0.0000]])至此,一个全连接网络就可以构建了。
案例1:全连接网络处理一维信息
搭建以下的网络结构
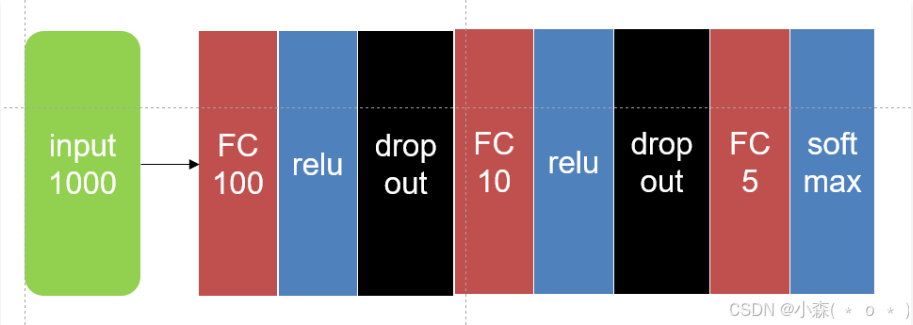
组合全连接层,dropout层,激活函数,我们就可以构建出一个完整的全连接网络结构,代码如下
import torch
import torch.nn as nn
from torchsummary import summary
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.relu = nn.ReLU()
self.softmax = nn.Softmax(dim=1)
self.dropout = nn.Dropout(p=0.5)
self.fc_1 = nn.Linear(1000, 100)
self.fc_2 = nn.Linear(100, 50)
self.fc_3 = nn.Linear(50, 10)
def forward(self,x):
x = x.view(-1, 1000) # 将输入的维度变成1000
x = self.dropout(self.relu(self.fc_1(x)))
x = self.dropout(self.relu(self.fc_2(x)))
x = self.softmax(self.fc_3(x))
return x
if __name__ == '__main__':
network = NeuralNetwork()
network.to('cuda')
input = torch.randn(10, 1000)
input = input.to('cuda')
output = network(input)
result = output.detach().cpu().numpy()
print('result=', result)
summary(network, (1000,))输出:
result= [[0.08132502 0.0739548 0.09398187 0.10661174 0.12098686 0.11598682
0.09127808 0.11483455 0.10602687 0.0950134 ]
[0.09192658 0.08138597 0.07189317 0.12415235 0.11198585 0.11625377
0.11482875 0.09960157 0.11294526 0.07502676]
[0.09182167 0.05779037 0.14180492 0.09080649 0.11460604 0.09648075
0.10017563 0.08380282 0.10664819 0.11606318]
[0.07540213 0.09515596 0.11200604 0.11029708 0.14663948 0.08727078
0.06854413 0.07956128 0.10746382 0.1176593 ]
[0.07536343 0.091349 0.1040979 0.08714981 0.11877389 0.14497975
0.08420233 0.08688229 0.11904272 0.08815894]
[0.08312867 0.05986795 0.12148032 0.10792468 0.10400964 0.1238383
0.11305461 0.08796311 0.11383145 0.08490121]
[0.07948367 0.09183787 0.08272586 0.11967309 0.12150185 0.10853862
0.09249827 0.10322765 0.102726 0.09778718]
[0.09022301 0.09465341 0.08689808 0.08957365 0.14267558 0.1025212
0.08516254 0.08472932 0.12696771 0.09659547]
[0.08116906 0.12094414 0.09831021 0.12145476 0.12512349 0.10931041
0.09090355 0.08238174 0.07898384 0.0914188 ]
[0.10484971 0.08653011 0.09862521 0.1086348 0.09272213 0.0991234
0.08527588 0.10124511 0.10974825 0.11324544]]
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 100] 100,100
ReLU-2 [-1, 100] 0
Dropout-3 [-1, 100] 0
Linear-4 [-1, 50] 5,050
ReLU-5 [-1, 50] 0
Dropout-6 [-1, 50] 0
Linear-7 [-1, 10] 510
Softmax-8 [-1, 10] 0
================================================================
Total params: 105,660
Trainable params: 105,660
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.40
Estimated Total Size (MB): 0.41
----------------------------------------------------------------案例2:全连接网络处理二维图像
搭建以下的网络结构
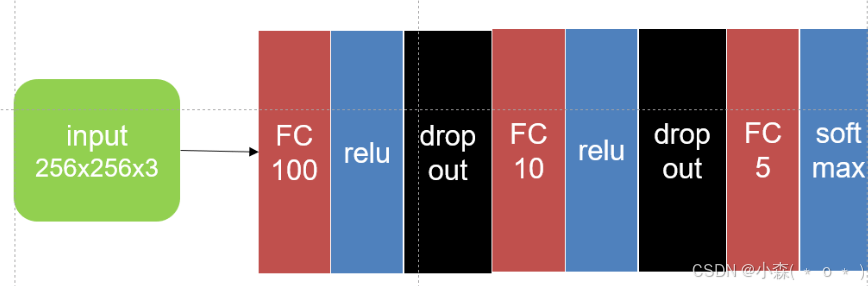
使用全连接网络处理二维图像信息,当二维特征(Feature Map)转为一维特征时,需要从高维压缩成一维
这时候可以用 tensor.view(),或者用nn.Flatten(start_dim=1)
import torch
import torch.nn as nn
from torchsummary import summary
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.relu = nn.ReLU()
self.softmax = nn.Softmax(dim=1)
self.dropout = nn.Dropout(p=0.5)
self.fc_1 = nn.Linear(3*256*256, 100)
self.fc_2 = nn.Linear(100, 10)
self.fc_3 = nn.Linear(10,5)
def forward(self,x):
x = x.view(-1, 3*256*256)
x = self.dropout(self.relu(self.fc_1(x)))
x = self.dropout(self.relu(self.fc_2(x)))
x = self.softmax(self.fc_3(x))
return x
if __name__ == '__main__':
network = NeuralNetwork()
network.to('cuda')
input = torch.randn((4,3,256,256)) # 4个样本,每个样本3通道,256*256像素
input = input.to('cuda')
output = network(input)
result = output.detach().cpu().numpy()
print('result=', result)
summary(network, (3, 256, 256))输出:
result= [[0.17621297 0.14625552 0.19215888 0.2527377 0.23263492]
[0.16786984 0.16124012 0.1907313 0.2352923 0.24486642]
[0.17400946 0.16431957 0.18192714 0.23585317 0.2438907 ]
[0.1535219 0.18567167 0.18704179 0.16786435 0.30590025]]
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 100] 19,660,900
ReLU-2 [-1, 100] 0
Dropout-3 [-1, 100] 0
Linear-4 [-1, 10] 1,010
ReLU-5 [-1, 10] 0
Dropout-6 [-1, 10] 0
Linear-7 [-1, 5] 55
Softmax-8 [-1, 5] 0
================================================================
Total params: 19,661,965
Trainable params: 19,661,965
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.75
Forward/backward pass size (MB): 0.00
Params size (MB): 75.00
Estimated Total Size (MB): 75.76
----------------------------------------------------------------腾讯云开发者
