Python地铁站点客流量预测:随机森林极限梯度提升回归器XGBoost|数据分享

Python地铁站点客流量预测:随机森林极限梯度提升回归器XGBoost|数据分享

拓端
发布于 2024-08-12 15:45:52
发布于 2024-08-12 15:45:52
本文将通过展示地铁站点客流量预测,并结合一个Python随机森林极限梯度提升回归器XGB实例的代码数据,为读者提供一套完整的实践数据分析流程。 然而,由于地铁系统复杂性以及乘客行为的不确定性,地铁客流量预测一直是一个挑战性的问题。 存在的问题:
- 地铁流量数据量巨大,获取较慢
- 在原始数据提取过程中,存在大量的缺失值和异常值的情况,会影响数据的预测的准确性和可靠性。
解决方案
我们采用了分层读取数据并采用二分法进行数据的筛选,处理缺失值和异常值的方法有很多种,这里我们采用删除法进行处理和分析。
任务/目标
主要是通过客户提供的郑州市数据,分别提取出每个月各个站点的进站和出站的日客流量,有选择性地从原始数据中抽取地点、日期和交易类型数据,进而根据交易类型统计各个站点进站和出站的日客流量并进行数据汇总。对提取的数据进行可视化分析,目的是分析周末和节假日是否能成为影响日客流量的影响因素,然后对数据进行汇总,采用神经网络回归模型进行预测12月1日-7日客流量的数据
数据源准备
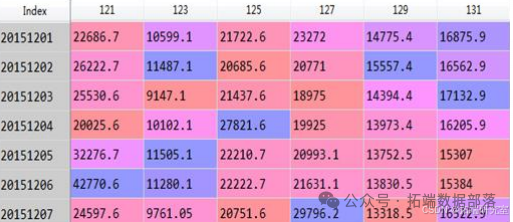
准备从8月到11月的地铁人流量数据(四个csv文件)样本如下:
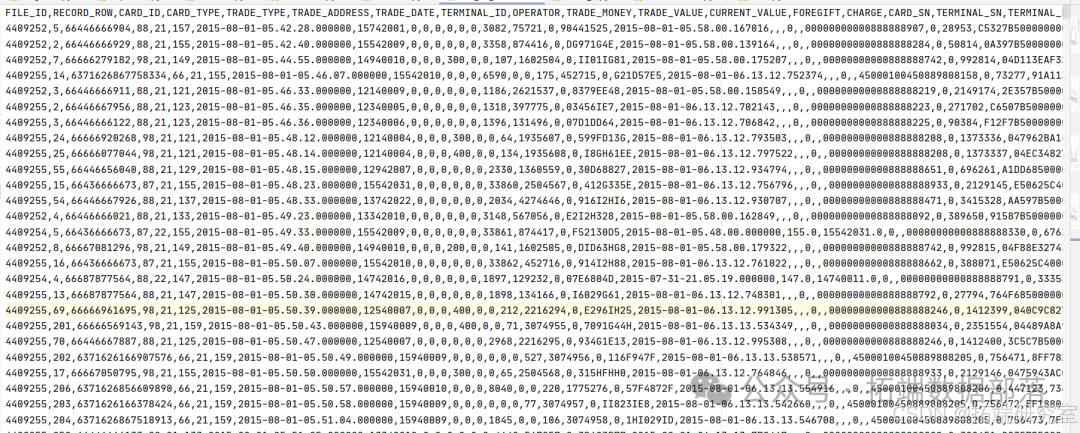
特征转换: 日期。就时间属性本身来说,对模型来说不具有任何意义,需要把日期转变成到年份,月份,日,周伪变量。 数据处理结果预览: 通过用分层读取法并用二分法获取数据,并对异常值处理之后获取到目表数据如下:(只列举部分特征)。分别处理四个月的地铁人流量数据获取如下数据
神经网络预测模型
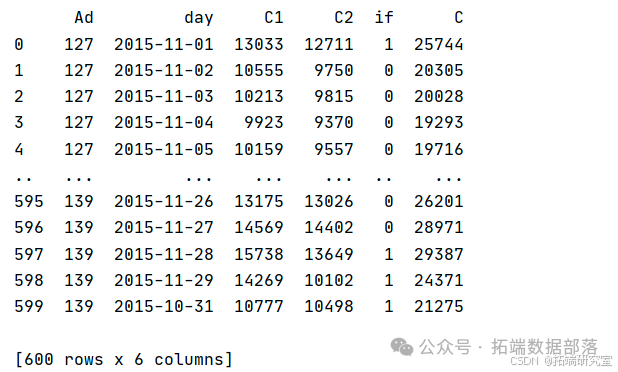
训练样本的特征输入变量用x表示,输出变量用y表示,测试样本共有5个特征数据,共2440条训练样本。

(1)训练样本构建示例代码如下:
import pandas as pd
data=pd.read_excel(‘总数据预测.xlsx’)
x=data.iloc[:,:5] #提取前四列数据
y=data.iloc[:,5] # 人流量数据import numpy as py
x11=np.array([121,14967,12260,20151201,0])
…
x207=np.array([159,14132,14167,20151207,0])
x11=x11.reshape(1,5)
…
X207=x207.reshape(1,5)其中预测样本的输入特征变量 用x11,x12…x207表示。 (3)神经网络回归模型构建示例代码如下:
#导入神经网络回归模块MLPRegressor。
from sklearn.neural_network import MLPRegressor
#利用MLPRegressor创建神经网络回归对象clf
Clf=MLPRegressor(solver=’lbfgs’,alpha=1e-5,hidden_layer_sizes=8,random_state=1)
#参数说明:
#solver:神经网络优化求解算法
#alpha:模型训练误差,默认为0.00001
#hidden_layer_sizes:隐含层神经元个数
#random_state:默认设置为1 #用clf对象中的fit()方法进行网络训练
clf.fit(x,y) #调用clf对象中的score()方法,获得神经网络回归的拟合优度(判决系数)
rv=clf.score(x,y) #调用clf对象中的predict()可以对测试样本进行预测,获得其测试结果
R11=clf.predict(x11)
R207=clf. predict (x207)1.编写预测方法: 先获取部分预测结果表:
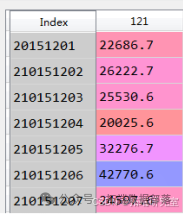
得到方法可行,预测全部站点人流量。
数据可视化结果:
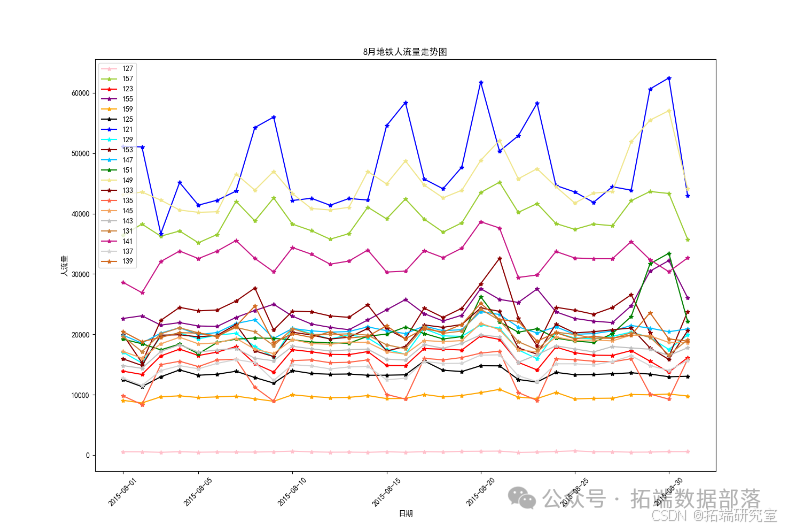
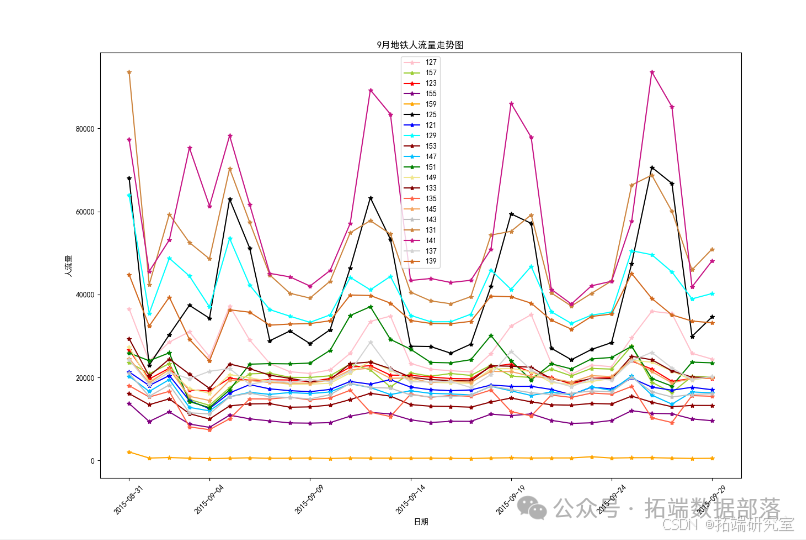
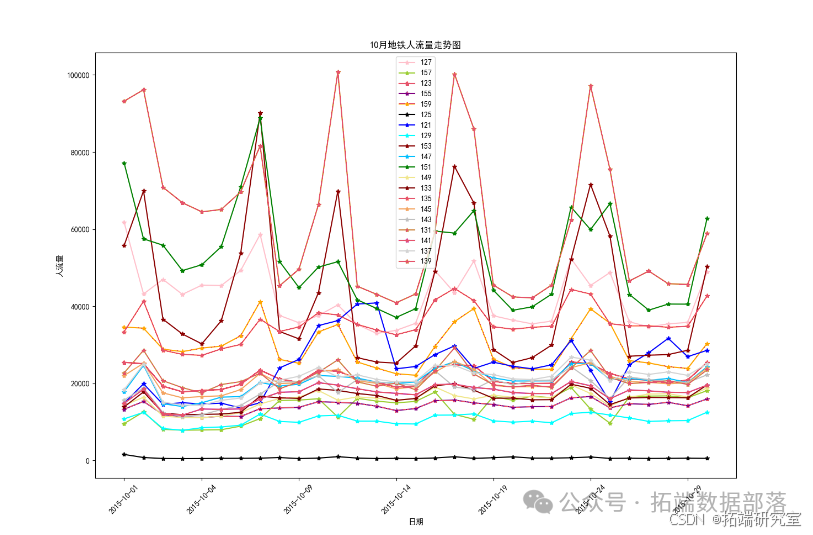
12月1日-12月7日地铁站点日客流量预测结果:
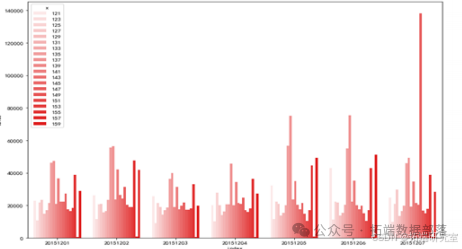
由十二月份一号到七号的预测数据画出的图表观察得出,站点135与137的客流量普遍较高,地铁工作人员应该在人流量多的站点多安排值班人员进行巡逻,维护站点的现场秩序,以免发生人员拥挤和安全事故的发生。特别的,图中12月7号147站点出现不同寻常的高峰客流量,考虑意外因素等情况造成的客流量增多,这一天我们可以提前预警并采取相应的安保措施,保证当天地铁站点的秩序。预测结果仅作为参考一个权重值,还需要专家意见,按照一定的权重来计算。
点击标题查阅往期内容

01
02
03
04

随机森林和极限梯度提升回归器XGB地铁交通流量预测
在本研究中,我们旨在通过自动化机器学习(AutoML)技术优化交通流量预测模型。为此,我们采用了TPOT(Tree-based Pipeline Optimization Tool),这是一个高效的AutoML工具,能够自动设计和优化机器学习管道。
首先,我将加载并查看提供的CSV文件以了解其结构和内容。然后,我将使用折线图来展示24小时的地铁交通流量变化趋势(查看文末了解数据免费获取方式)。让我们开始吧。
python复制import pandas as pd
# 加载CSV文件
df = pd.read_csv(file_path)
# 显示前几行数据以了解其结构
df.head()数据集包含多个字段,其中date_time和traffic_volume是我们关注的主要字段。date_time字段表示日期和时间,而traffic_volume字段表示交通流量。
接下来,我将使用折线图来展示24小时内的交通流量变化趋势。
python复制import matplotlib.pyplot as plt
# 将date_time列转换为datetime类型
df['date_time'] = pd.to_datetime(df['date_time'])
# 对数据进行排序以确保时间顺序
df = df.sort_values('date_time')
# 绘制折线图
plt.figure(figsize=(15, 6))
plt.plot(df['date_time'], df['traffic_volume'], marker='o', linestyle='-')
plt.title('24小时内交通流量变化趋势')
plt.xlabel('时间')
plt.ylabel('交通流量')
plt.grid(True)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()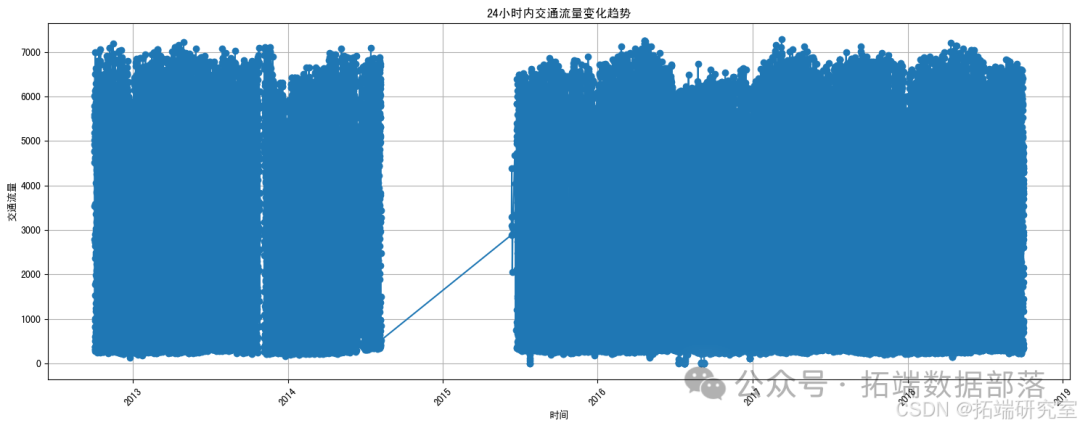
这是一个展示24小时内交通流量变化趋势的折线图。从图中可以看出,交通流量在不同时间段内有所波动。 为了更准确地展示24小时内的交通流量变化趋势,我需要先筛选出特定日期的数据。然后,我将再次绘制折线图。
python复制# 筛选出特定日期的数据(例如最早的日期)
specific_date = df['date_time'].dt.date.iloc[0]
df_specific_date = df[df['date_time'].dt.date == specific_date]
# 对数据进行排序以确保时间顺序
df_specific_date = df_specific_date.sort_values('date_time')
# 绘制折线图
plt.figure(figsize=(15, 6))
plt.plot(df_specific_date['date_time'], df_specific_date['traffic_volume'], marker='o', linestyle='-')
plt.title(f'{specific_date} 交通流量变化趋势')
plt.xlabel('时间')
plt.ylabel('交通流量')
plt.grid(True)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()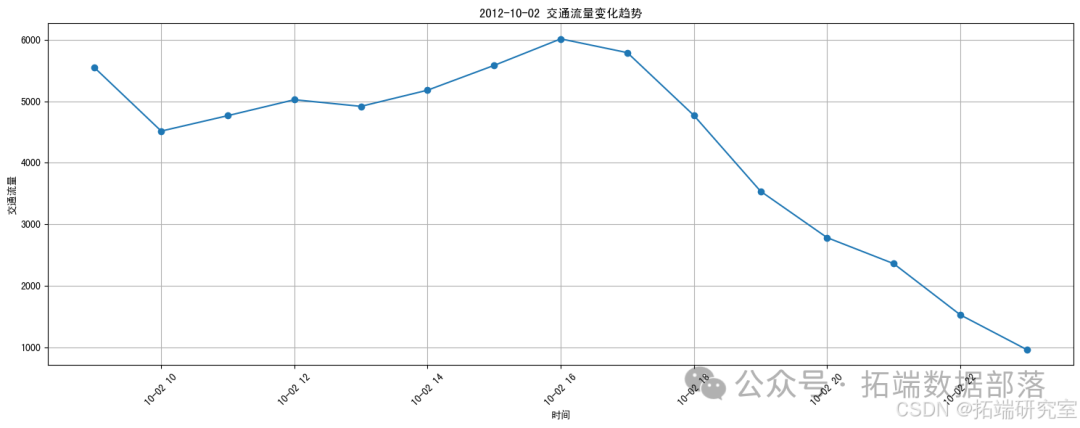
这是一个展示特定日期(最早的日期)内24小时交通流量变化趋势的折线图。从图中可以看出,交通流量在不同时间段内有所波动。 我将按照以下步骤进行操作:
- 使用散点图矩阵来探索
traffic_volume与weather_main、temp、rain_1h、snow_1h和clouds_all等变量之间的关系。 - 使用柱状图或箱线图来比较
holiday为“None”与特定假日(如Columbus Day, Veterans Day, Thanksgiving Day)的traffic_volume差异。
首先,我将进行第一步的分析。
python复制import seaborn as sns
# 选择相关的列
columns_to_explore = ['traffic_volume', 'weather_main', 'temp', 'rain_1h', 'snow_1h', 'clouds_all']
# 由于weather_main是分类变量,我们需要将其转换为数值编码
df['weather_main_code'] = df['weather_main'].astype('category').cat.codes
# 创建散点图矩阵
sns.pairplot(df[columns_to_explore], diag_kind='kde', markers=["o", "s", "D", "v", "<", ">"])
plt.suptitle('交通流量与天气条件的关系', y=1.02)
plt.show()
这是一个散点图矩阵,用于探索traffic_volume与weather_main、temp、rain_1h、snow_1h和clouds_all等变量之间的关系。
接下来,我将进行第二步的分析,即比较holiday为“None”与特定假日(如Columbus Day, Veterans Day, Thanksgiving Day)的traffic_volume差异。
python复制# 筛选出特定的假日
specific_holidays = ['Columbus Day', 'Veterans Day', 'Thanksgiving Day']
df_holidays = df[df['holiday'].isin(specific_holidays) | (df['holiday'] == 'None')]
# 创建箱线图
plt.figure(figsize=(12, 6))
sns.boxplot(x='holiday', y='traffic_volume', data=df_holidays, palette=["rgb(202,206,210, max =255)", "rgb(230,232,234, max =255)"])
plt.title('假日与非假日交通流量对比')
plt.xlabel('假日类型')
plt.ylabel('交通流量')
plt.show()
python复制# 修正颜色格式并重新创建箱线图
plt.figure(figsize=(12, 6))
sns.boxplot(x='holiday', y='traffic_volume', data=df_holidays, palette=["#C0C4C8", "#E6E8EA"])
plt.title('假日与非假日交通流量对比')
plt.xlabel('假日类型')
plt.ylabel('交通流量')
plt.show()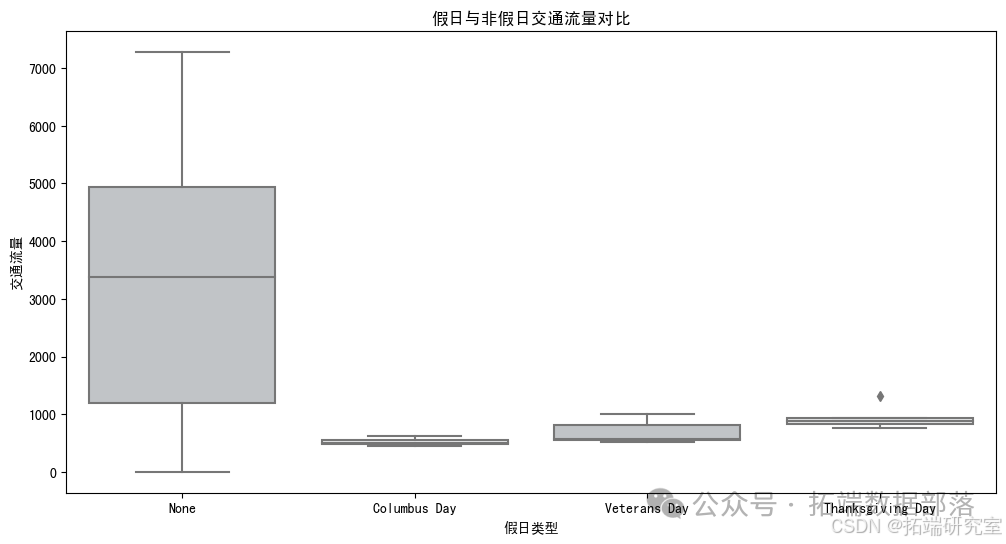
这是一个箱线图,用于比较holiday为“None”与特定假日(如Columbus Day, Veterans Day, Thanksgiving Day)的traffic_volume差异。
从图中可以看出,不同类型的假日和非假日的交通流量有所不同。
以下是我们实验过程的详细描述:
首先,我们对特征集`X`和目标变量`y`进行了训练集和测试集的划分,其中测试集占比为25%,并确保了数据的随机性,以避免任何潜在的偏差。具体实现如下: y,
test_size=0.25,
shuffle=True,
random_state=42) verbosity=2,
n_jobs=-1)
`接着,我们初始化并训练了一个TPOTRegressor模型,设置最大运行时间为60分钟,以确保模型有足够的时间探索可能的解决方案。此外,我们将verbosity设置为2,以便在训练过程中获得详细的输出,并将n_jobs设置为-1,以利用所有可用的处理器核心。
y_predictions = tpot.predict(X_test)
r2 = sklearn.metrics.r2_score(y_test, y_predictions)
mae = sklearn.metrics.mean_absolute_error(y_test, y_predictions)
mse = sklearn.metrics.mean_squared_error(y_test, y_predictions)
rmse = np.sqrt(mse)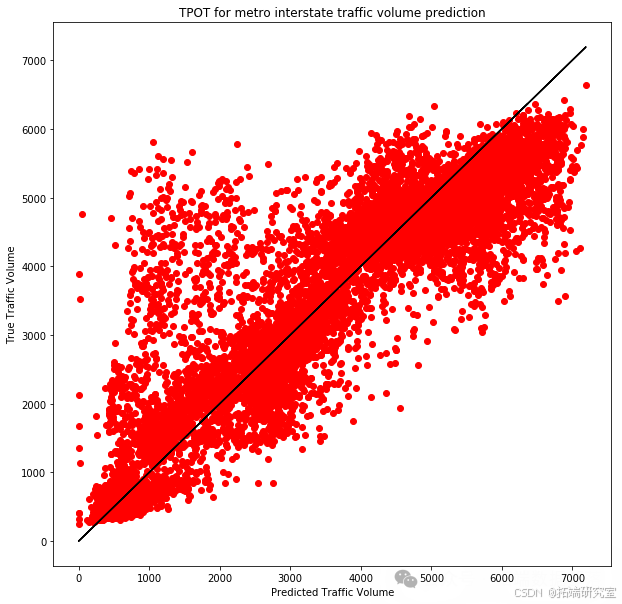
此外,我们还尝试了其他几种机器学习模型,包括随机森林回归器和极限梯度提升回归器(XGBRegressor),并对其进行了参数调优以优化性能。以下是随机森林回归器的一个示例:
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['traffic_volume'].values, random_state=None)
exported_pipeline = make_pipeline(
StandardScaler(),
RandomForestRegressor(bootstrap=False, max_features=0.45, min_samples_leaf=2, min_samples_split=2, n_estimators=100)
)
exported_pipeline = RandomForestRegressor(bootstrap=True, max_features=0.9000000000000001, min_samples_leaf=9, min_samples_split=19, n_estimators=100)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)features = tpot_data.drop('traffic_volume', axis=1).values
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['traffic_volume'].values, random_state=None)
exported_pipeline = ExtraTreesRegressor(bootstrap=False, max_features=0.8, min_samples_leaf=8, min_samples_split=18, n_estimators=100)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)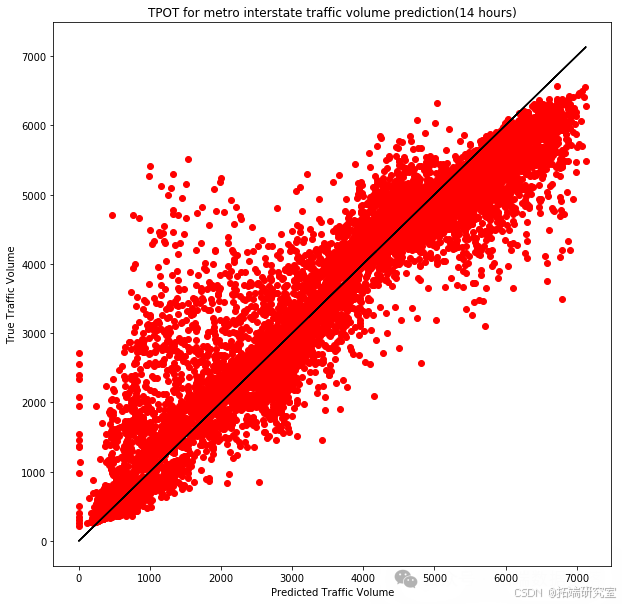
我们还尝试了极限梯度提升回归器,并对其进行了参数调整:
a=tpot_data['traffic_volume'].values
features = tpot_data.drop('traffic_volume', axis=1).values
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['traffic_volume'].values, random_state=None)
exported_pipeline = XGBRegressor(learning_rate=0.1, max_depth=3, min_child_weight=15, n_estimators=100, nthread=1, subsample=0.6000000000000001,objective = 'reg:squarederror')
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)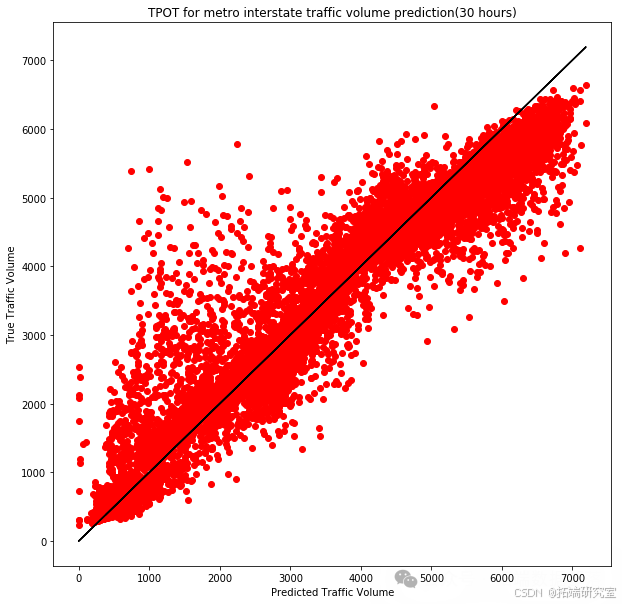
在每种情况下,我们都记录了模型在训练集上的平均交叉验证分数,并使用训练好的模型对测试集进行了预测。 通过这些实验,我们能够识别出最适合我们数据集的模型,并对其进行了详细的性能评估。这些结果为我们提供了有价值的见解,有助于进一步优化交通流量预测模型,并为城市规划和交通管理部门提供数据支持。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-08-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号