AI论文速读 | TPLLM:基于预训练语言模型的交通预测框架

AI论文速读 | TPLLM:基于预训练语言模型的交通预测框架

时空探索之旅
发布于 2024-11-19 16:16:33
发布于 2024-11-19 16:16:33
论文标题:TPLLM: A Traffic Prediction Framework Based on Pretrained Large Language Models
作者:Yilong Ren(任毅龙), Yue Chen, Shuai Liu, Boyue Wang(王博岳), Haiyang Yu(于海洋) Zhiyong Cui(崔志勇)
机构:北京航空航天大学交通科学与工程学院,北京工业大学
关键词:交通预测,预训练大语言模型,少样本学习,微调
TL, DR: 本文提出了TPLLM框架,一个基于预训练大型语言模型(LLMs)的交通预测系统,它通过结合序列和图嵌入层以及LoRA微调技术,能够在数据有限的情况下有效提高交通流量预测的准确性和泛化能力。
论文链接:https://arxiv.org/abs/2403.02221
Cool Paper:https://papers.cool/arxiv/2403.02221
点击文末阅读原文跳转本文arXiv链接。

标题和作者
摘要:交通预测是智能交通系统(ITS)范围内的一个关键方面,实现高精度预测对于有效的交通管理具有深远的意义。深度学习驱动流量预测模型的精度通常会随着训练数据量的增加而呈上升趋势。然而,获取全面的交通时空数据集通常充满挑战,主要源于与数据收集和保留相关的巨额成本。因此,开发一种能够在历史交通数据有限的地区实现准确预测和良好泛化能力的模型是一个具有挑战性的问题。值得注意的是,近年来快速发展的预训练大型语言模型(LLM)在跨模态知识迁移和小样本学习方面表现出了卓越的熟练程度。认识到流量数据的顺序性质(类似于语言),本文引入了 TPLLM,这是一种利用 LLM 的新型流量预测框架。在此框架中,构建了基于卷积神经网络(CNN)的序列嵌入层和基于图卷积网络(GCN)的图嵌入层,分别提取序列特征和空间特征。随后将这些内容整合起来,形成适合LLM的输入。TPLLM 采用LoRA微调方法,从而促进高效学习并最大限度地减少计算需求。在两个真实数据集上的实验表明,TPLLM在全样本和少样本预测场景中都表现出了优越的性能,有效支持了历史交通数据稀缺地区的ITS发展。
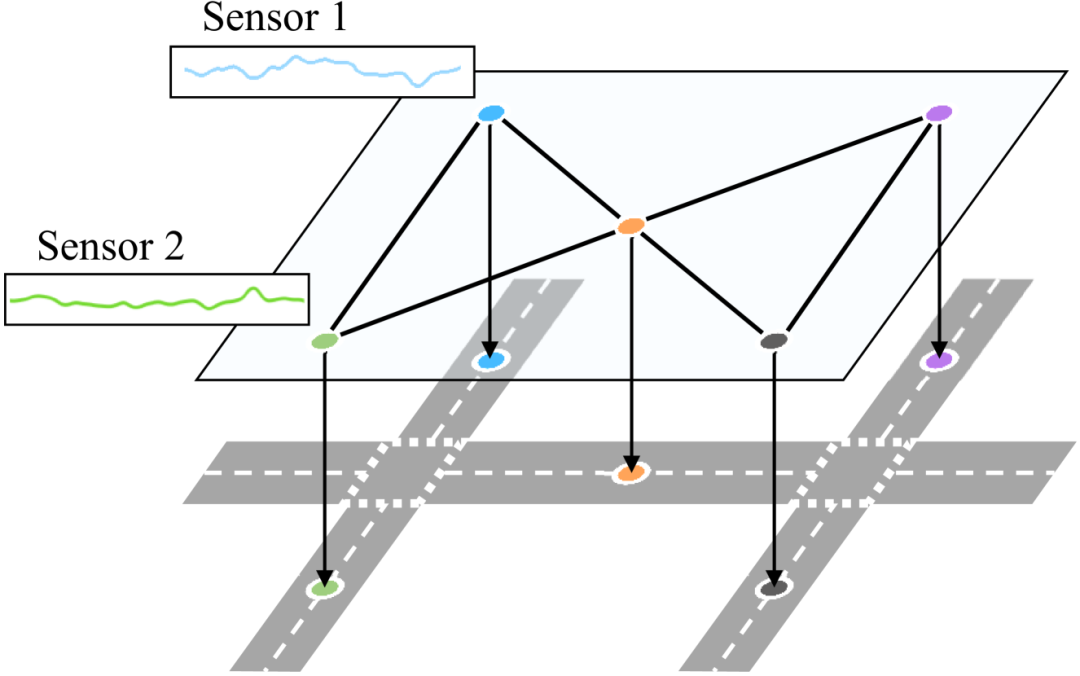
时间序列交通数据之间的相关性
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在有限的历史交通数据的情况下,实现高精度的交通预测。具体来说,论文提出了一个名为TPLLM(基于预训练大型语言模型的交通预测框架)的新型交通预测框架,旨在利用预训练的大型语言模型(LLMs)的强大能力和少量样本学习(few-shot learning)的特性,来提高交通预测的准确性和泛化能力。这个框架特别适用于那些难以获取大量历史交通数据的地区,从而支持智能交通系统(ITS)的发展。
Q: 有哪些相关研究?
A: 相关研究主要集中在以下几个方面:
- 交通预测:早期的交通预测研究通常依赖于统计方法或传统的机器学习方法,如ARIMA、SVM和KNN。这些方法将交通数据视为简单的时间序列,难以捕捉数据中的非线性时空特征,因此在预测精度上有局限性。近年来,深度学习方法,尤其是基于图的方法,被广泛应用于交通预测。例如,RNN及其变体LSTM和GRU用于提取交通数据的时间依赖性,而GCNs用于提取空间依赖性。此外,CNNs和注意力机制也被整合以识别显著信息。
- 预训练大型语言模型(LLMs):近年来,基于Transformer的预训练LLMs在自然语言处理任务中表现出色。这些模型通过在大规模高质量通用数据集上训练,捕获通用模式和信息。LLMs因其强大的少量样本学习能力和跨模态知识转移能力而受到关注。这些模型在多个领域都有应用,包括交通领域。
- LLMs在时间序列预测中的应用:由于LLMs的出色少量样本学习能力和跨模态知识转移能力,它们可以扩展到不同领域的多种场景。然而,将预训练的LLMs应用于交通预测的研究相对较少,主要集中在一般时间序列预测领域。一些研究提出了基于跨模态知识迁移的预训练LLMs的通用时间序列分析框架,包括预测、分类、插值和异常检测。
- 交通时间序列处理:在交通时间序列处理领域,预训练LLMs的应用还处于初步阶段。一些研究尝试使用预训练LLMs进行交通时空任务,例如通过图注意力机制识别空间依赖性,或者通过时空嵌入模块学习空间位置和全局时间表示。
这些相关研究为TPLLM框架的提出提供了理论和技术基础,特别是在如何利用预训练LLMs处理交通数据和提高预测性能方面。
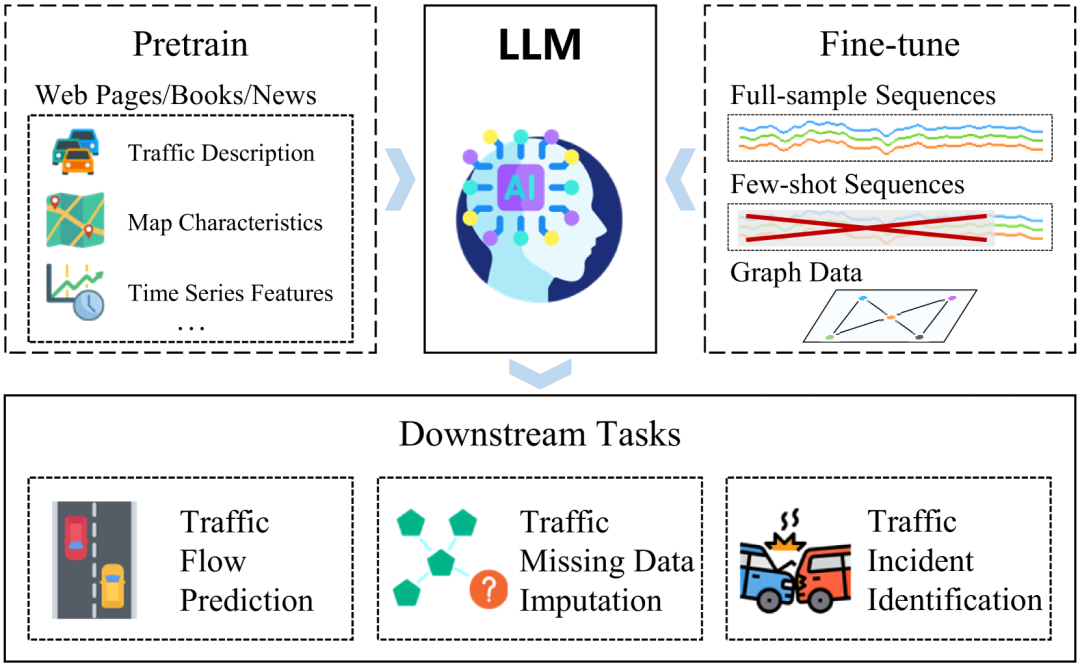
LLM在交通任务上的预训练任务
LLM的token embedding不是很适用于交通时序数据。但是多元时序数据和文本数据有显著的结构相似性,都可以表示为一致维数的向量集合。这种一致性有效地缩小了不同类型的数据之间的差距,为将LLM应用于交通数据分析提供了一种思路。
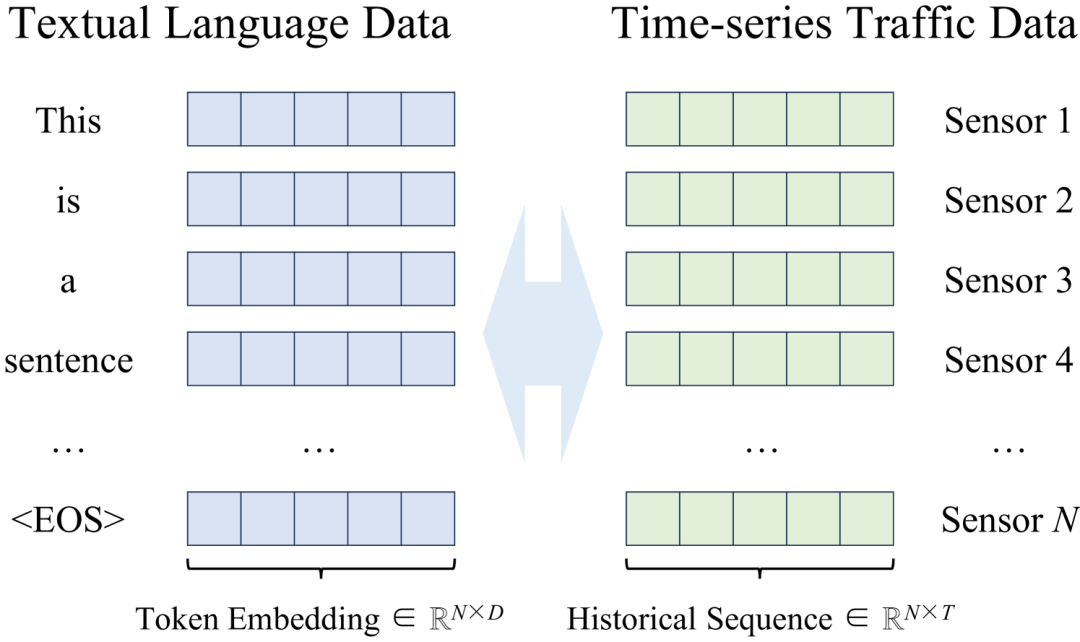
交通时序数据与自然语言的相似性
Q: 论文如何解决这个问题?
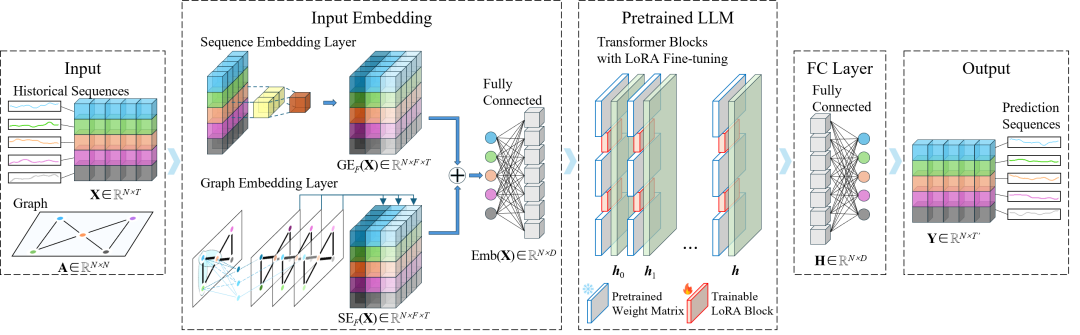
TPLLM
A: 论文通过提出TPLLM(Traffic Prediction based on Pretrained Large Language Models)框架来解决这个问题,具体方法如下:
- 利用预训练的大型语言模型(LLMs):论文认识到LLMs在跨模态知识转移和少量样本学习方面的能力,将其应用于交通预测任务。LLMs通过在大规模数据集上预训练,捕获通用模式和信息,这使得它们能够在有限的训练数据下快速适应新的下游任务。
- 设计两个输入嵌入模块:为了使预训练的LLMs能够处理交通数据,论文设计了一个输入嵌入模块,包括序列嵌入层和图嵌入层。
- 序列嵌入层:使用卷积神经网络(CNN)处理序列交通数据,提取时间依赖性和模式。
- 图嵌入层:使用图卷积网络(GCN)处理道路网络的邻接矩阵,提取空间依赖性和模式。
- 应用低秩适应(LoRA)微调方法:为了提高训练效率和微调效果,论文采用了一种参数高效的微调方法,即LoRA。这种方法在每个Transformer块中注入可训练的低秩分解矩阵,显著减少了可训练参数的数量,同时保持了模型性能。
- 实验验证:论文在两个真实世界的交通数据集上进行了实验,包括全样本预测和少量样本预测场景。实验结果表明,TPLLM在这两种场景下都表现出色,证明了预训练LLMs在交通预测任务中的有效性。
- 贡献总结:
- 提出了TPLLM框架,用于处理全样本和少量样本交通预测任务。
- 设计了基于CNN和GCN的嵌入模块,使LLMs能够理解时间序列数据并融合交通数据中的时空特征。
- 应用了成本效益高的微调方法LoRA,以在保持高微调质量的同时降低训练成本。
- 在具有充足和有限训练数据的场景中进行了实验,验证了预训练LLMs在交通预测中的有效性。
通过这些方法,论文成功地将预训练的LLMs应用于交通预测领域,并展示了其在处理有限历史交通数据情况下的潜力。
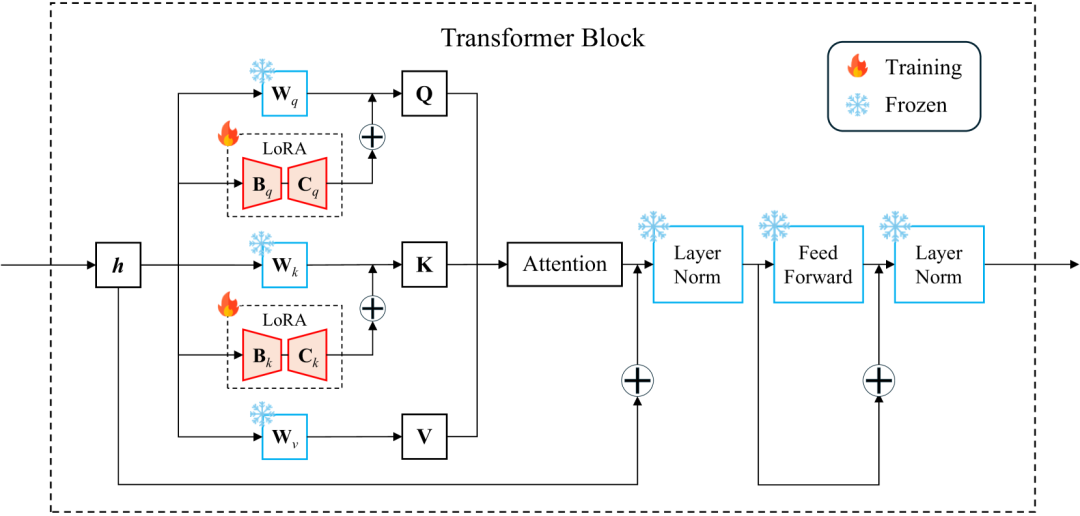
Transformer块的设计
Q: 论文做了哪些实验?
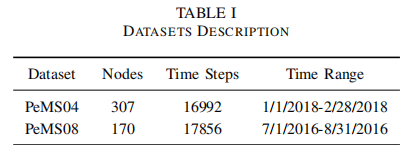
PEMS04,08实验数据集
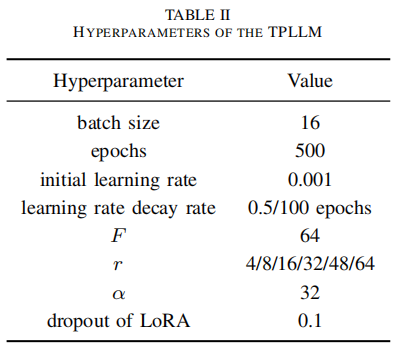
TPLLM超参设置
是LoRA秩数,
起着类似于针对LoRA学习速率的作用
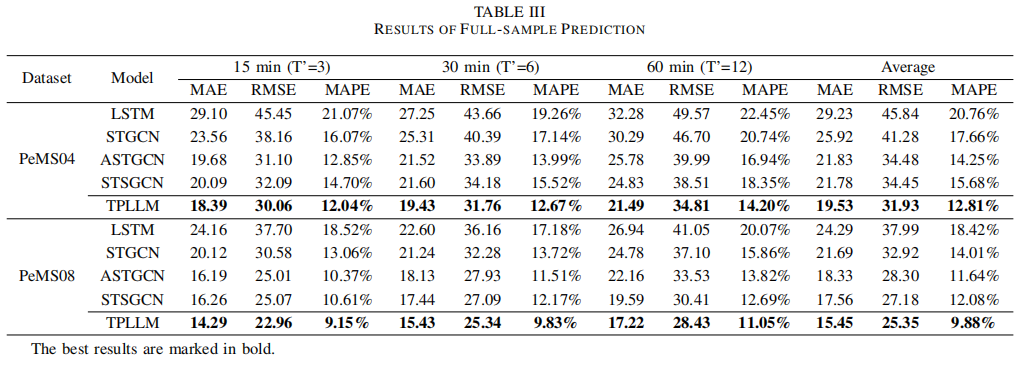
全样本实验
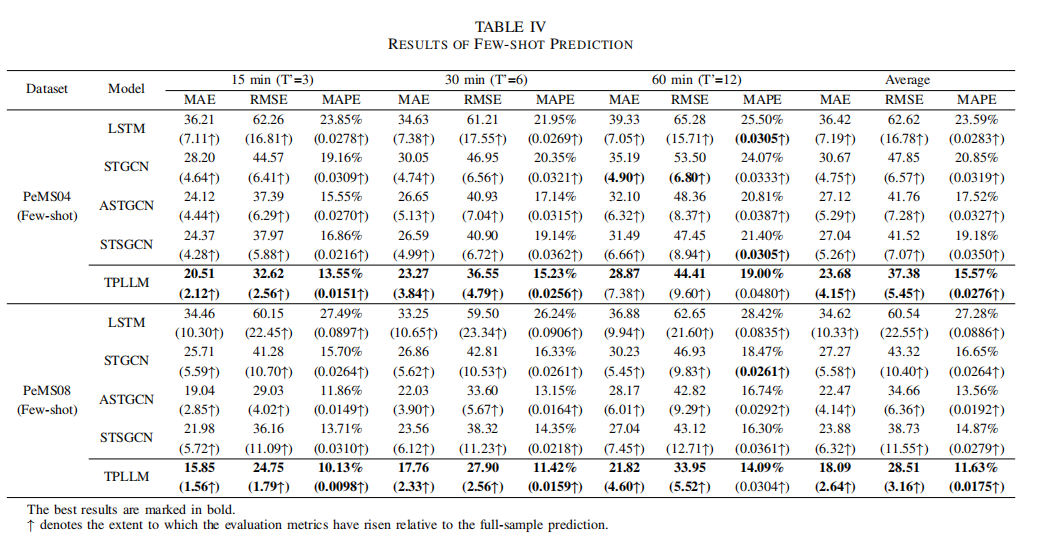
少样本预测
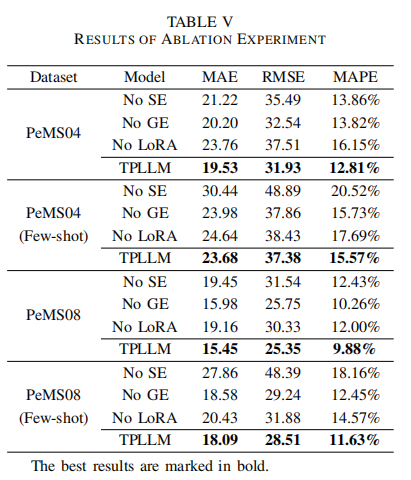
消融实验
A: 论文进行了一系列实验来验证TPLLM框架的有效性,主要包括以下几个方面:
- 全样本预测(Full-sample Prediction):
- 在两个真实世界的交通数据集(PeMS04和PeMS08)上进行实验。
- 使用1小时历史交通流量数据作为输入,预测未来15分钟、30分钟和1小时的交通流量。
- 将TPLLM与其他几个基线模型(LSTM、STGCN、ASTGCN、STSGCN)进行比较,使用MAE、RMSE和MAPE作为评估指标(大模型与常用的时空图预测模型作比较是否公平?)。
- 少样本预测(Few-shot Prediction):
- 在相同的数据集上进行实验,但训练集大小仅为全样本实验的**10%**。
- 评估指标与全样本预测相同,同时比较了少量样本预测与全样本预测的性能变化。
- 可视化预测结果(Visualization of Predictions):
- 随机选择了两个数据集中的单个节点和两个随机测试日(一个工作日和一个周末日)。
- 绘制了全样本预测和少量样本预测的可视化图表,以便更直观地观察结果。
- 消融研究(Ablation Study):
- 为了验证TPLLM中每个模块的有效性,分别移除了图嵌入层、序列嵌入层和LoRA。
- 在两个数据集上进行实验,保持其他超参数不变,并比较了原始框架与退化模型的性能。
- LoRA的秩(Rank of LoRA)敏感性分析:
- 研究了LoRA中秩(r)这一超参数对预测结果的影响。
- 使用不同的r值进行全样本和少量样本预测,并观察MAE的变化。
这些实验旨在全面评估TPLLM在不同数据条件下的性能,并与其他现有方法进行比较。通过这些实验,论文展示了TPLLM在交通预测任务中的优越性和稳健性。
Q: 有什么可以进一步探索的点?
A: 论文提出了几个可以进一步探索的点,包括:
- 改进嵌入设计:论文提到,未来的工作可以设计更复杂的嵌入来提高预测精度,这可能包括考虑更多影响交通的因素,如天气条件、特殊事件、节假日等。
- 探索更适用的PEFT技术:PEFT(Parameter-Efficient Fine-Tuning)技术在TPLLM中用于调整预训练的LLMs。未来的研究可以探索更多适用于时空预测任务的PEFT技术,以进一步提高模型的性能和效率。
- 寻找LLMs的可解释性知识学习模式:尽管LLMs在交通预测中表现出色,但它们的内部工作机制和知识学习模式仍然不够透明。未来的研究可以探索如何解释LLMs在交通预测中学习到的知识,以便更好地理解和利用这些模型。
- 跨领域知识转移:考虑到LLMs在自然语言处理中的成功,未来的研究可以探索如何将这些模型在其他领域的知识转移到交通预测任务中,以提高模型的泛化能力。
- 实时预测和动态调整:在实际应用中,交通状况是实时变化的。未来的研究可以探索如何使TPLLM能够实时更新和调整预测,以适应交通状况的动态变化。
- 大规模部署和优化:在实际的智能交通系统中部署TPLLM可能面临计算资源和实时性的要求。未来的研究可以关注如何优化模型以满足这些要求,例如通过模型压缩、硬件加速等技术。
- 多模态数据融合:交通预测可以受益于多模态数据的融合,例如结合交通传感器数据、卫星图像、社交媒体数据等。未来的研究可以探索如何有效地融合这些不同类型的数据来提高预测的准确性。
通过这些进一步的探索,研究者可以提高交通预测模型的性能,使其更加适应实际应用的需求,并为智能交通系统的发展提供更强大的支持。
Q: 总结一下论文的主要内容
A: 这篇论文提出了TPLLM(基于预训练大型语言模型的交通预测框架),旨在解决在有限历史交通数据条件下实现高精度交通预测的挑战。以下是论文的主要内容总结:
- 问题背景:交通预测对于智能交通系统(ITS)至关重要,但获取全面的时空数据集面临成本和数据收集的挑战。现有的深度学习模型通常需要大量数据进行训练,这限制了它们在数据有限区域的应用。
- 方法论:论文提出了TPLLM框架,该框架利用预训练的大型语言模型(LLMs)的跨模态知识转移和少量样本学习能力。为了使LLMs适应交通数据,设计了序列嵌入层和图嵌入层来提取时间序列和空间特征。
- 技术细节:
- 序列嵌入层:使用CNN处理时间序列数据,提取时间依赖性。
- 图嵌入层:使用GCN处理道路网络的图结构数据,提取空间依赖性。
- LoRA微调:采用低秩适应(LoRA)方法对模型进行微调,以提高训练效率并减少计算需求。
- 实验验证:在两个真实世界的交通数据集上进行了全样本和少量样本预测实验。实验结果表明,TPLLM在两种情况下都优于其他基线模型,证明了其在有限数据条件下的有效性。
- 贡献:
- 提出了一个能够处理全样本和少量样本交通预测任务的框架。
- 设计了能够理解交通数据时空特征的嵌入模块。
- 应用了LoRA微调方法,提高了模型的泛化能力和预测效率。
- 在不同数据条件下进行了实验,验证了预训练LLMs在交通预测中的应用潜力。
- 未来工作:论文提出了未来研究方向,包括改进嵌入设计、探索更适用的PEFT技术、寻找LLMs的可解释性知识学习模式等。
总的来说,这篇论文通过引入预训练的大型语言模型,为交通预测领域提供了一种新的解决方案,特别是在数据有限的情况下,展示了其在提高预测精度和泛化能力方面的潜力。
如果觉得有帮助还请分享,在看,点赞
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号