cellchat细胞通讯中 prob 与 pval 的含义是什么?

cellchat细胞通讯中 prob 与 pval 的含义是什么?

细胞通讯就是分析任意两个单细胞亚群的受体和配体基因的共同高表达,比如文献:《CXCR6 orchestrates brain CD8+ T cell residency and limits mouse Alzheimer’s disease pathology》
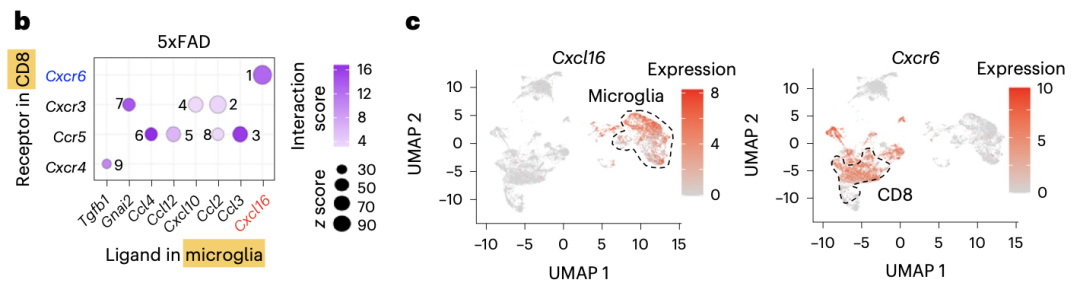
所以首先需要知道每个物种有哪些受体和配体基因,其次要对任意两个单细胞亚群进行组合分析,如果满足了a基因在A亚群并且b基因在B亚群同时高表达就是有通讯,当然了这个也是有统计学指标来量化所谓的同时高表达,不能是仅仅是靠肉眼看。比如cellchat这个算法做细胞通讯, 就有 prob 与 pval 这两个值!
CellChat v1版本于2021年发表在NC,并且在2024年进行了v2版本的一个更新,发在文章都很好,引用也是大几千上万了!
- Suoqin Jin et al., CellChat for systematic analysis of cell–cell communication from single-cell transcriptomics, Nature Protocols 2024 [CellChat v2] (Please kindly cite this paper when using CellChat version >= 1.5)
- Suoqin Jin et al., Inference and analysis of cell-cell communication using CellChat, Nature Communications 2021 [CellChat v1]
我们单细胞月更群里有一个学员提问:您好,哪位大佬能帮解释一下cellchat的通讯概率是什么意思吗?这个值越大说明通讯的概率越大呢?还是强度越大呢?如下结果,prob 与 pval 的含义是什么。

确实cellchat细胞通讯里面的两个指标很容易让人误解,这就让我们来一起看看cellchat的原理吧。
开发此算法的前提
- SingleCellSignalR, iTALK, 以及 NicheNet:这些方法通常只使用一对配体/受体基因,忽视了许多受体作为多亚基复合物的功能
- CellPhoneDB v2.0:考虑了 多亚基复合物 作为受体,策略为 细胞亚群中 多亚基对应基因平均值作为此受体的表达,但 没有考虑其他重要的信号共因子,包括可溶性激动剂、拮抗剂以及刺激性和抑制性膜结合共受体
- 其他局限性包括缺乏:
- (a) 系统整理的配体-受体对功能相关信号通路分类;
- (b) 对自分泌和旁分泌信号相互作用的直观可视化;
- (c) 分析复杂细胞间通信的系统方法;
- (d) 在细胞状态轨迹连续变化的情况下访问信号交叉作用的能力,考虑到细胞之间的生物学变异性可能是离散的或连续的.
看一下cellchat细胞通讯推断的步骤:
1、差异表达信号基因鉴定
Identification of over-expressed genes per cell group:基于细胞类型,鉴定显著上调的基因,统计方法为 Wilcoxon rank sum test, pvalue<0.05。
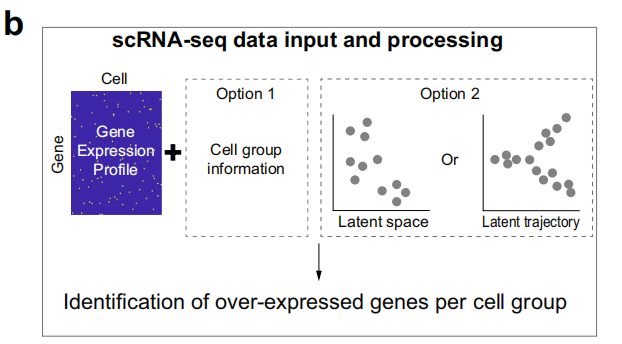
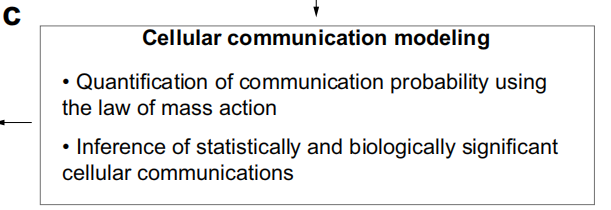
2、基于质量作用定律 (law of mass action) 计算通讯概率
probability 翻译为概率,但其实跟pvalue这种含义不一样,且看下面的解说。
1)获取信号基因表达均值:细胞通讯是基于细胞亚群的计算,因此需要用“均值”代表。但为了防止离群值对均值的影响,使用统计学稳健的算法(基于分位数):Q1, Q2, 和 Q3为信号基因在亚群中的第1/2/3分位数的表达。
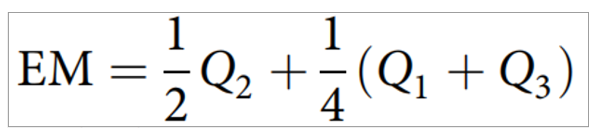
2)计算LR互作概率 probability
LR互作概率是 基于质量作用定律 (law of mass action)和希尔方程(Hill function)完成的。
其中,质量作用定律假设表达量可以替代浓度,希尔方程是 cellchat 算法思想的核心,主要通过希尔方程来考虑协同和拮抗作用。
在基于希尔方程推断LR互作之前,首先利用蛋白质互作网络对配体和受体进行过滤,过滤方法为 使用基于随机游走的网络传播技术(random walk based network propagation technique)将基因表达谱投射到来自 STRINGdb 的一个高可信度的实验验证的蛋白网络上。基于这些映射上的配体和受体,利用希尔方程来推断特定LR pair(k) 在细胞亚群 i 和 j 的通讯概率probability:
LR pairs通讯的概率通过以下元素相乘得到:1)基本通讯概率(红色);2)激动剂(蓝色)和拮抗剂(橙色);3)细胞水平随机互作的概率。
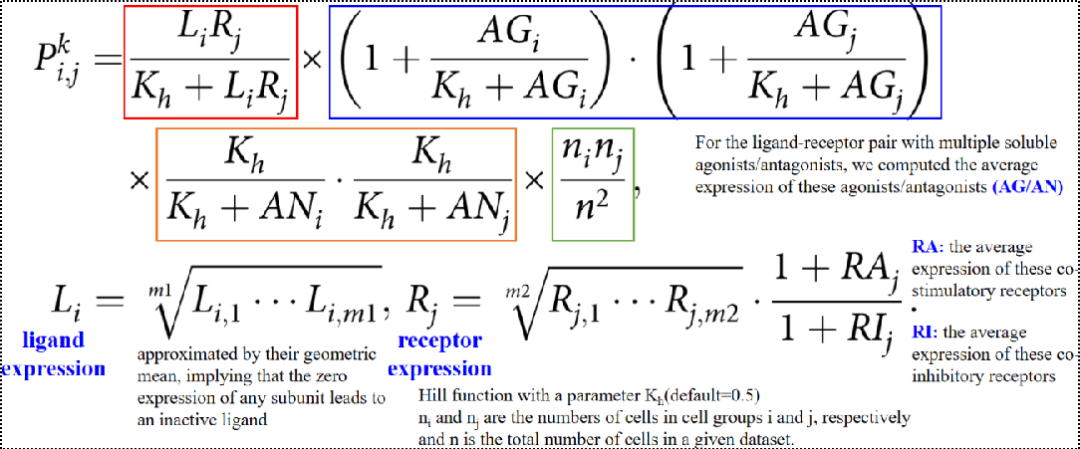
公式中的字母含义:
- i/j:细胞亚群i、j ;
- k:配体受体对
- Li:细胞亚群i中配体L的表达
- Rj:细胞亚群j中受体R的表达
- 复合体配体m1 subunits:m1个亚基的几何平均值,只要有一个表达为0,则为0
- 复合体受体m2 subunits:与上类似
- RA:对于配体受体对有多个共刺激受体:共刺激受体的均值RA
- RI:对于每个配体-受体对与多个共抑制受体
- parameter Kh:默认值0.5,as the input data has a normalized range from 0 to 1
- ni:细胞亚群i的细胞数;
- nj:细胞亚群j的细胞数;
- n:细胞总数
- AG:对于具有多个可溶性激动剂的配体-受体对,计算这些激动剂的平均表达量(用AG表示),然后使用Hill函数来模拟配体-受体相互作用的正向调节;
- AN:对于具有多个可溶性拮抗剂的配体-受体对,使用相同的方法来建模
3)细胞-LR-互作概率空间
所有配体-受体对的细胞亚群之间的通信概率probability由一个三维空间P (K, K, N)表示,其中K为细胞群的数量,N为配体-受体对或信号通路的数量。因此,两个细胞亚群通讯的概率probability就是把所有的LR-pairs加起来。
Note:这里的通信概率仅代表交互强度,并不是确切的概率pvalue。
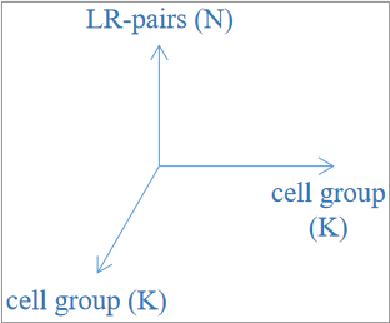
3、识别具有统计学意义的细胞间通信
两个细胞亚群间通讯的统计学显著性是基于随机扰动(permutation test)决定的,随机扰动细胞的类标签,然后重复上述过程从而获得随机分布,M默认为100次随机。
这样就得到了两个细胞亚群间发生通讯的具有统计学意义的指标pvalue,可以使用pvalue来过滤。
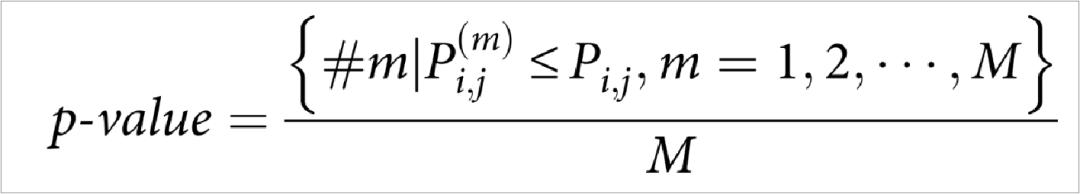
回答标题中的含义:
左图的边代表:线的粗细表示两个细胞亚群间通讯的显著的配受体对总数 Number of signifificant ligand-receptor pairs between any pair of two cell populations.
右图的边代表:communication probability的加和,该数据来源于cellchat@net$prob
Ref: https://github.com/sqjin/CellChat/issues/184

统计学确实是一个难啃的硬骨头,推荐大家抽空从基础开始补起来。 如果不学统计学,那么你就不可能看懂下面这图,生物信息学领域耳熟能详的生存分析,主成分分析,差异分析你都无法理解。
腾讯云开发者
