CogACT:一种新的VLA模型架构


编辑:陈萍萍的公主@一点人工一点智能

论文地址:https://cogact.github.io/CogACT_paper.pdf
项目地址:https://cogact.github.io/
本文介绍了一种名为CogACT的先进视觉语言行动模型,用于协同认知和行动在机器人操作中的应用。该模型基于大型视觉语言模型(VLM)进行设计,并采用组件化架构,具有专门的动作模块以根据VLM输出执行动作预测。实验结果表明,CogACT模型不仅显著提高了任务性能,而且能够适应新的机器人并泛化到未见过的对象和背景中。与现有的VLAs相比,CogACT模型在模拟评估和真实机器人实验中的成功率分别超过OpenVLA和RT-2-X模型。

论文方法
1.1 方法描述
该研究旨在开发一种视觉语言模型(VLA),使不同的机器人能够根据视觉观察和语言指令执行各种任务。为此,他们将模型分为三个部分:视觉模块、语言模块和动作模块。视觉模块通过强大的视觉变换器处理原始图像输入,并将其转换为一组感知令牌。语言模块使用LLAMA-2模型将语言指令转换为一组语言令牌,并与视觉令牌和一个可学习的认知令牌一起传递给模型以进行认知推理。动作模块接收认知特征作为输入条件来生成一系列连续的动作序列。
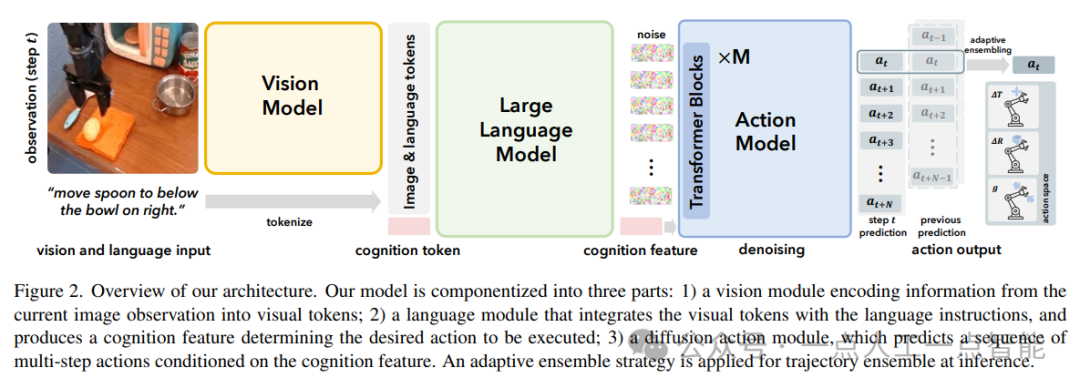
1.2 方法改进
该研究提出了以下几个改进:
1)使用预训练的DINOv2和SigLIP模型来捕捉丰富的视觉特征和全面的语义理解。
2)将LLAMA-2模型应用于语言模块以进行认知推理。
3)使用扩散Transformer(DiT)作为动作解码过程的强大后背来预测连续和多模态的真实世界物理行动。
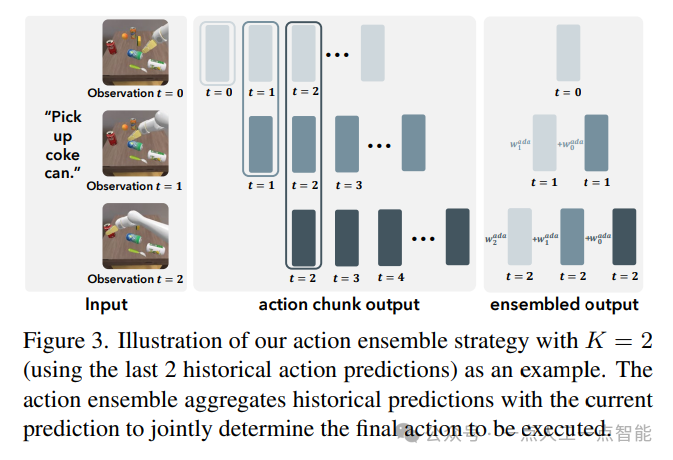
4)在推理过程中采用了自适应动作集成策略,考虑了不同时间步长上的动作之间的相似性,从而提高了任务执行的成功率。
1.3 解决的问题
该研究的主要目标是开发一种视觉语言模型,使不同的机器人能够根据视觉观察和语言指令执行各种任务。具体来说,该模型解决了以下问题:
1)如何有效地处理复杂的视觉观察和语言指令?
2)如何将视觉信息和语言指令整合起来并进行认知推理?
3)如何在真实世界的连续和多模态的物理行动中进行有效的预测和控制?
通过以上改进和解决方案,该研究提出的视觉语言模型可以更准确地预测和控制机器人的行为,从而提高任务执行的成功率。

论文实验
本文主要介绍了在机器人视觉与语言(VL)学习领域的一个研究项目,该项目旨在通过使用预训练的图像和文本模型来提高机器人的控制性能。该研究进行了多个对比实验,包括模拟环境下的评估和真实世界中的测试,并与其他现有的VL模型进行了比较。
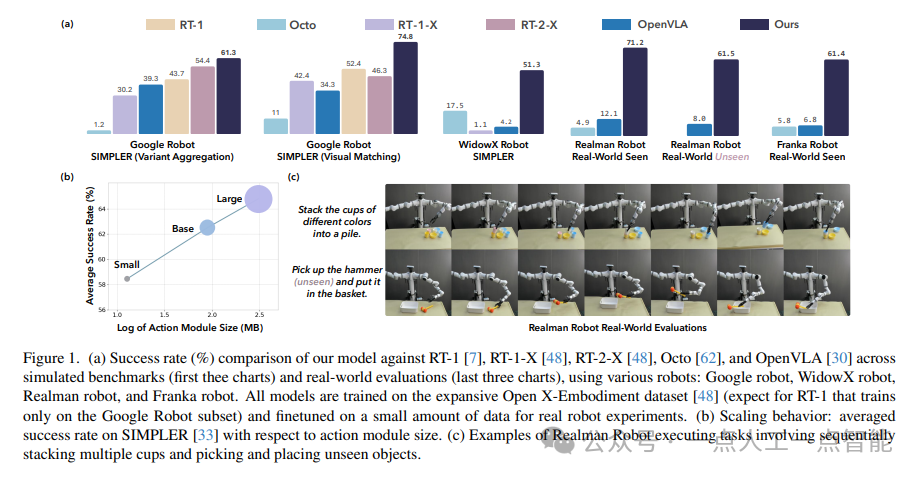
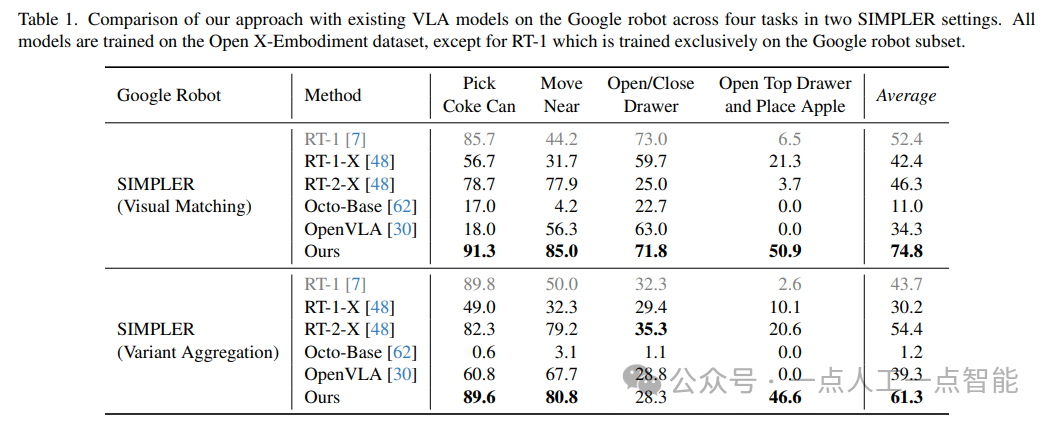
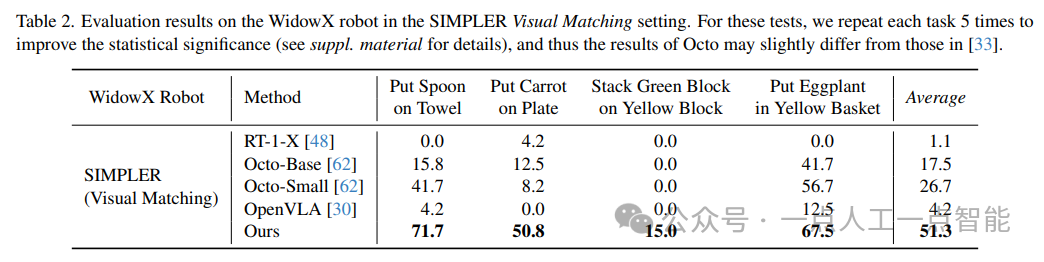
首先,在模拟环境中,作者使用了SIMPLER平台对Google机器人和WidowX机器人进行了评估。他们使用了两个不同的设置:Visual Matching和Variant Aggregations。在每个设置中,他们都评估了四个任务的成功率,并将结果与现有的VL模型进行了比较。实验结果表明,他们的模型在所有任务和设置中都表现最好,甚至比专门为特定机器人设计的模型表现更好。
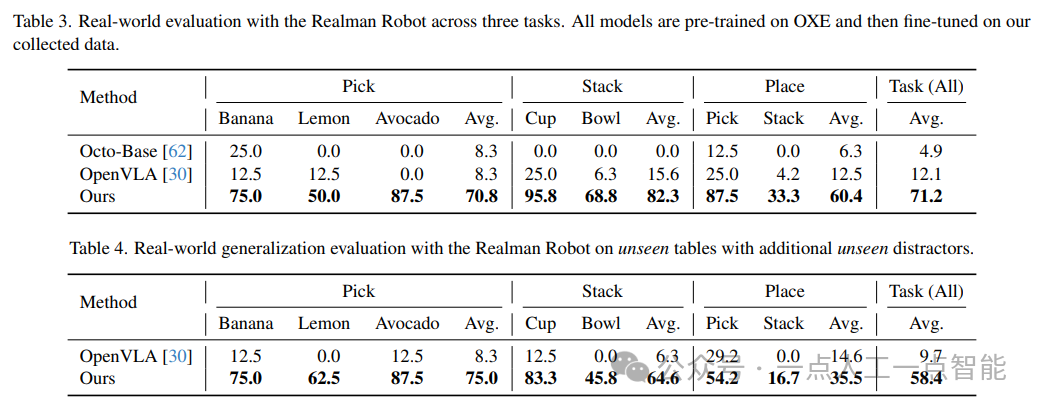
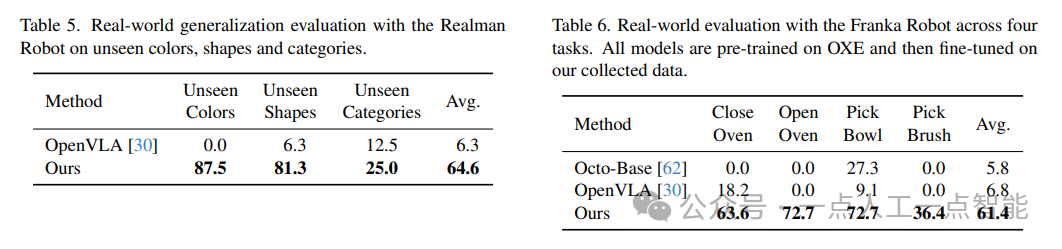
其次,在真实世界中,作者使用了Realman Arm4和Franka Arm5机器人进行了测试。他们定义了三个任务:Pick、Stack和Place,并手动收集了一些演示数据用于微调模型。然后,他们在每个任务上进行了多次试验,并将结果与Octo-Base和OpenVLA等现有模型进行了比较。实验结果表明,他们的模型在所有任务中都表现出色,并且具有很强的泛化能力,可以处理未见过的颜色、形状和类别。
最后,作者还进行了一些Ablation Study,以进一步验证他们的方法的有效性。他们比较了不同类型的动作模型架构、多步预测策略以及动作集成策略的效果,并得出了有益的结论。
总的来说,这项研究表明,使用预训练的图像和文本模型可以显著提高机器人的控制性能,并且可以在真实世界中实现良好的效果。此外,他们的实验还提供了一些有用的指导原则,可以帮助改进未来的VL学习算法。

方法创新点
该论文的主要贡献在于提出了一种全新的VLA模型架构——CogACT,通过将认知信息提取出来并作为条件引导动作预测过程,从而解决了现有VLAs在处理连续、多模态、时间相关且需要高精度的动作信号时存在的问题。此外,论文还引入了一个简单的自适应动作集成算法,进一步提高了模型性能。

未来展望
未来的研究可以探索更复杂的动作信号处理方法,例如结合多种传感器数据来提高动作预测的准确性和鲁棒性。同时,也可以考虑如何将这种方法应用于实际场景中的机器人控制中,以实现更加智能和高效的机器人操作。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-01-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号