如何快速部署DeepSeek| 腾讯云TI部署指南
原创如何快速部署DeepSeek| 腾讯云TI部署指南
原创
一、为什么要使用DeepSeek + 腾讯云HAI
近年来,随着大模型与多场景应用的蓬勃发展,AI工程师越来越需要快速、高效且低成本地部署和管理模型服务。腾讯云HAI(High-performance AI)平台是一个面向高性能计算与深度学习的综合解决方案,提供了 GPU/CPU 资源调度、自动化部署以及运维监控等功能;而 DeepSeek 则是一个帮助开发者快速搭建数据处理、模型训练与推理的智能化框架。将两者结合后,你可以更轻松地进行 AI 任务的全流程管理,比如数据处理、模型训练、自动化推理,以及持续迭代升级。
二、基础概念&服务介绍

- DeepSeek
- 腾讯云TI平台
- 平台特点:提供高性能计算资源(GPU、CPU 等),结合腾讯云成熟的容器调度体系及运维管理能力,便于 AI 开发者快速上线并管理模型服务。
- 核心功能:容器化、自动扩缩容、可定制的任务调度,支持主流框架(TensorFlow、PyTorch、MXNet 等)的部署。
- 适用场景:训练数据量大、推理性能要求高、希望自动化部署管理多版本模型的场景。
三、快速部署流程
腾讯云TI平台
首次登录腾讯云TI平台时,需要创建服务角色,跟着流程指引完成授权之后,进入到TI平台的大模型广场。
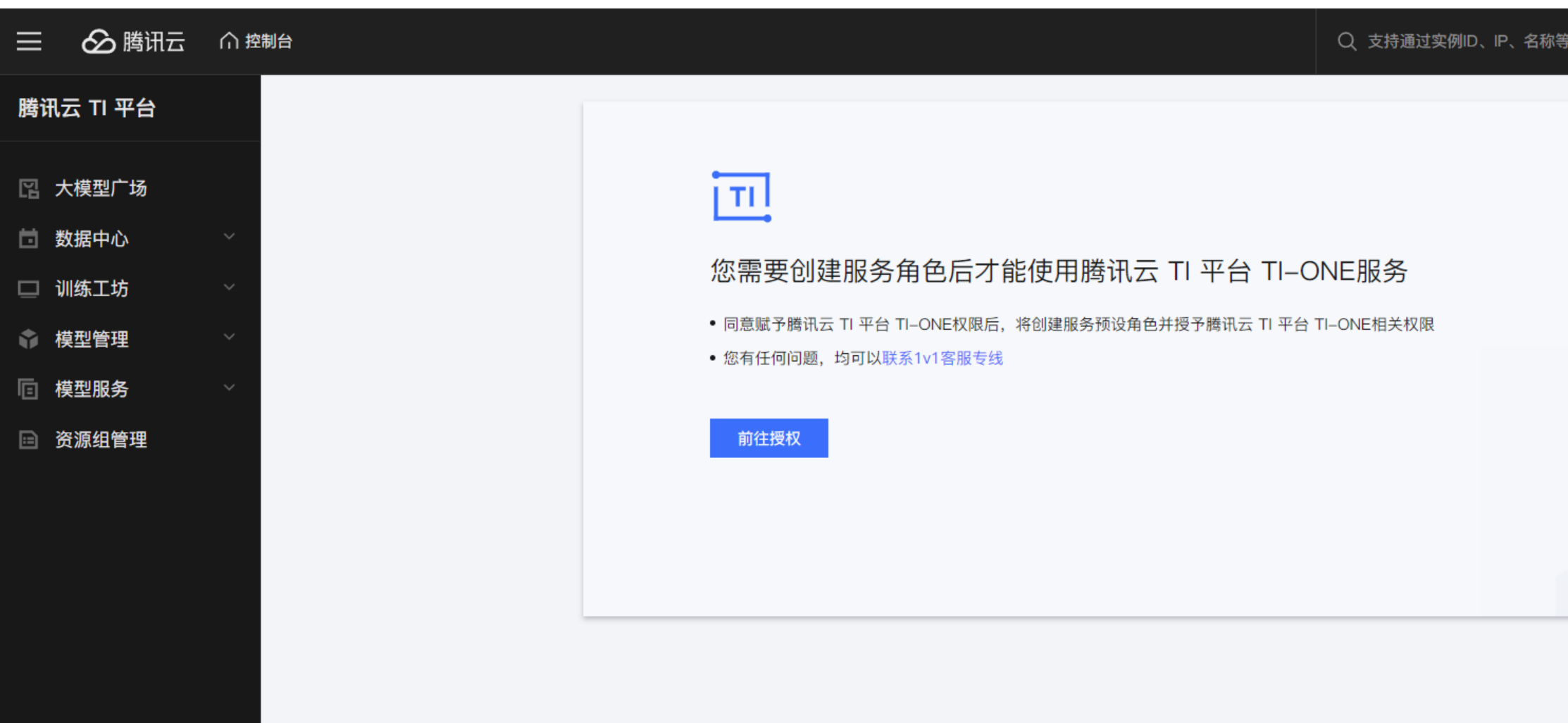
首先需要服务授权:
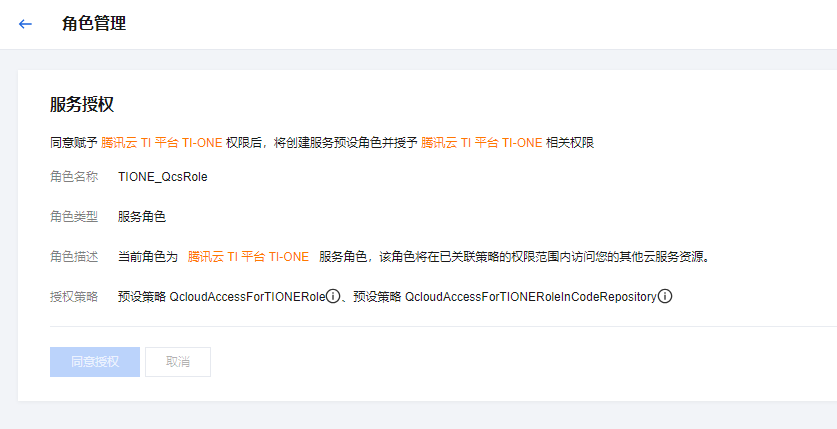
授权之后,那么我们就可以在大模型广场去找到我们想要的大模型资源了:

点击DeepSeek进入到详情页面,在详情页面可以看到模型介绍、模型体验。
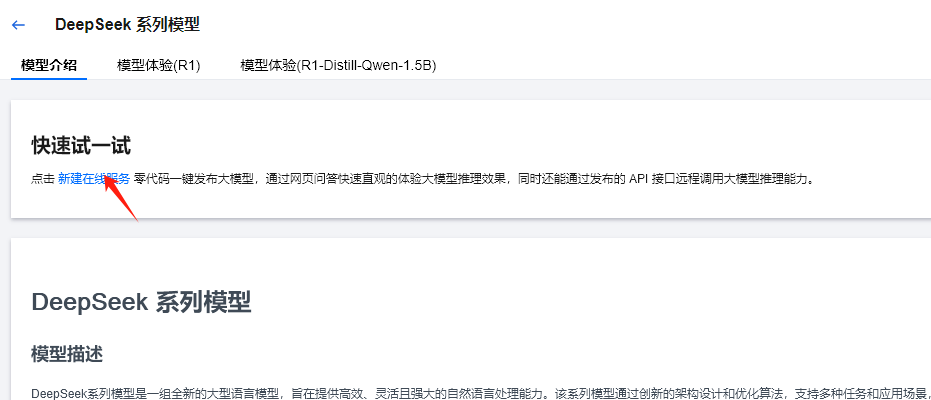
在模型体验中可以体验与DeepSeek模型的对话。

创建在线服务
在DeepSeek的模型页面,点击新建在线服务,进入到服务创建页面。填入服务名称之后,选择机器来源用来部署DeepSeek。
1. 选择主机资源
一种方式是从已有的腾讯云CVM中选择安装DeepSeek,这样DeepSeek模型运行和推理时,就会使用CVM云服务器的资源。另一种直接是通过TIONE平台购买资源(显卡、内存、CPU)完成部署。
定价模式
TI-ONE 的产品定价支持按量计费和包年包月两种模式,详细内容和具体费用可参考计费概述。
按量计费:定价包括 CVM 机器费用和 TI-ONE 软件费,按秒计费,按小时结算。多适用于快速体验各模块能力。
包年包月:定价不包括 CVM 机器费用,仅包括 TI-ONE 软件费,按月计费和结算。多适用于正式环境的训练和推理。
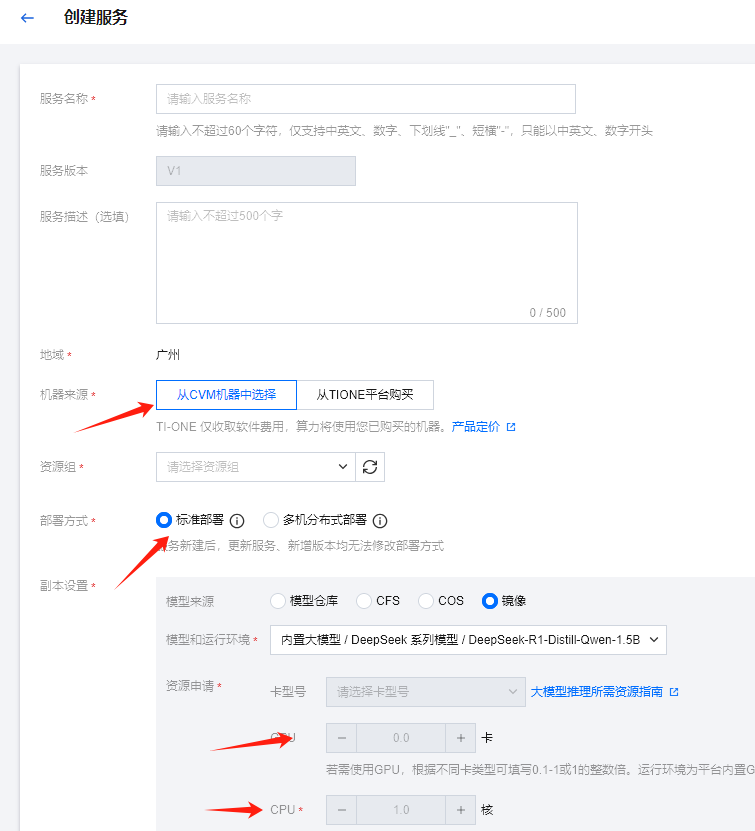
使用自有的CVM可能面临着资源不足的风险,通常带有显卡的CVM价格比较昂贵,而且当资源不足时也无法更改显卡内存或者内存的大小。而TIONE平台可以按量计费,可以实现快速的扩容和缩容。
2. 模型选择
接下来就是选择DeepSeek模型。

在内置大模型中,我们可以看到不同的名称的DeepSeek大模型,对于不同模型的区别如下所示:
模型名称 | 基础模型 | 参数规模 | 特点 | 计算需求 |
|---|---|---|---|---|
DeepSeek-R1-Distill-Qwen-1.5B | Qwen | 1.5B | 轻量级,适合移动端和本地推理 | 低(PC 可运行) |
DeepSeek-R1-Distill-Qwen-7B | Qwen | 7B | 适合本地推理和轻量级服务器部署 | 中等(24GB+ VRAM) |
DeepSeek-R1-Distill-Llama-8B | LLaMA | 8B | LLaMA 版本,英文能力更强 | 中等 |
DeepSeek-R1-Distill-Qwen-14B | Qwen | 14B | 中文能力更强,适用于专业应用 | 较高(A100 级别 GPU) |
DeepSeek-R1-Distill-Qwen-32B | Qwen | 32B | 适用于企业级 AI 任务 | 高(多 GPU / 云端) |
DeepSeek-R1-Distill-Llama-70B | LLaMA | 70B | 强大推理能力,适合高端 AI 计算 | 极高(H100 / TPU 级别) |
DeepSeek-V3-671B | 自研 | 671B | DeepSeek 最高参数量模型,超大规模通用 AI | 超高(云端 A100 集群) |
DeepSeek-R1-671B | 自研 | 671B | DeepSeek-R1 的完整超大模型 | 超高(企业级/科研级) |
- Qwen 系列(通义千问):基于阿里巴巴的 Qwen(通义千问)系列,适合中文任务,拥有较强的知识推理能力和上下文理解能力。
- LLaMA 系列:基于 Meta 的 LLaMA(LLaMA 2/3),更加通用,适合多语言任务,在英文任务上表现较好。
- DeepSeek 自研模型(R1/V3):DeepSeek 自主训练的大规模 Transformer 模型,R1 主要用于推理,而 V3 可能结合更多创新结构。
3. 选择算力规格
选择的按量计费的话,则选择从TIONE平台购买:
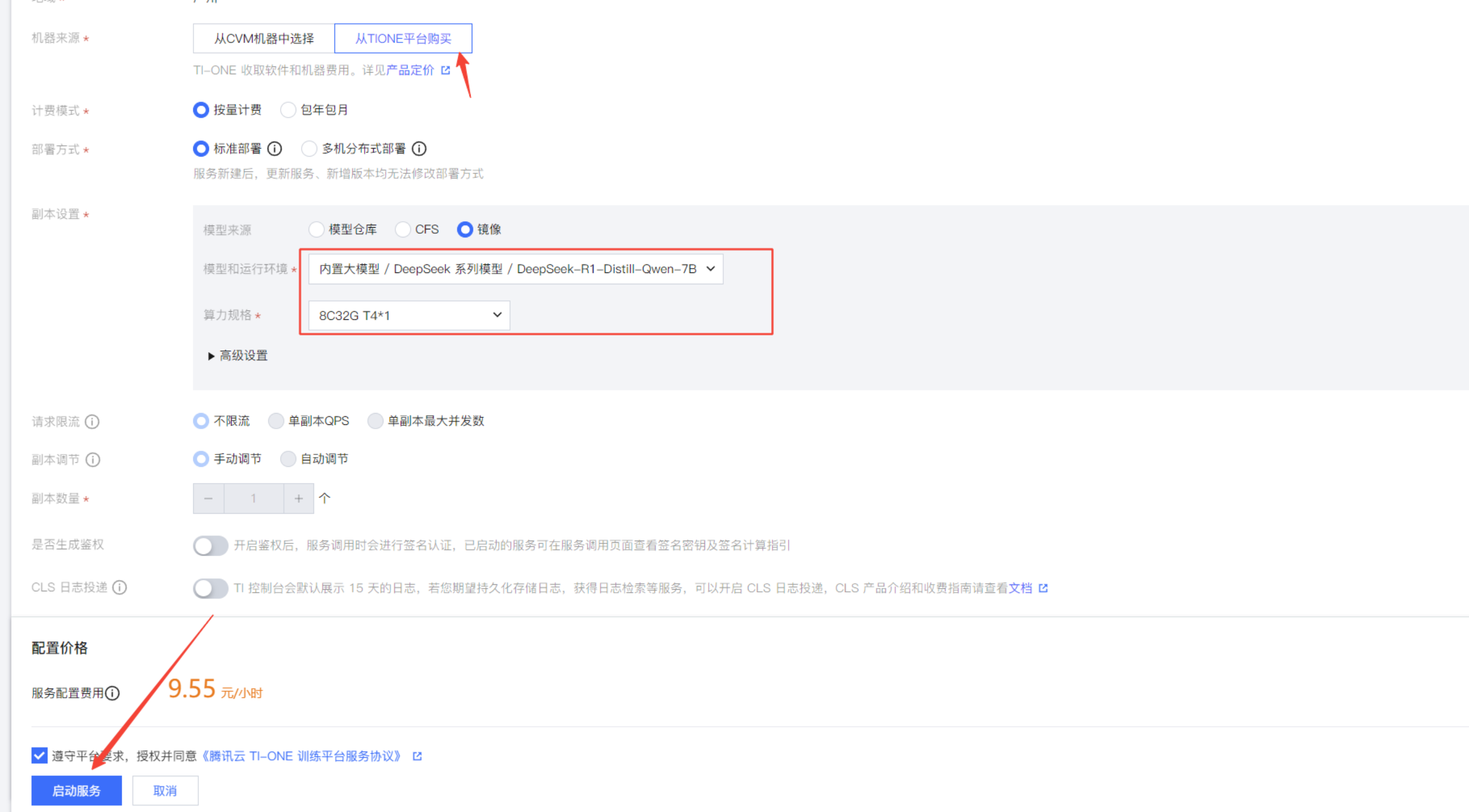
根据选择的DeepSeek模型,选择相对应的算力规格,点击启动服务。
4. 启动服务
启动之后进入在线服务列表。
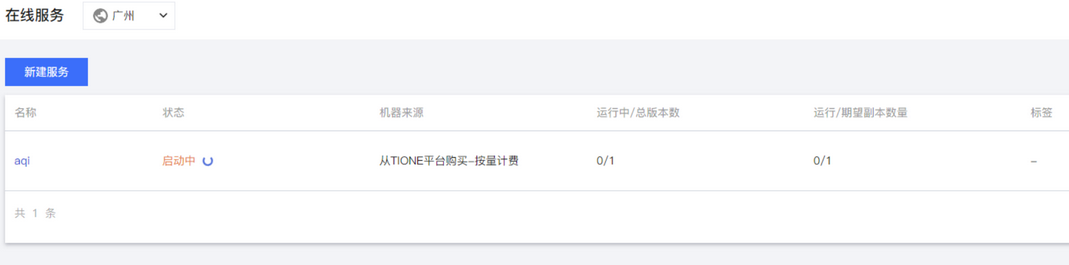
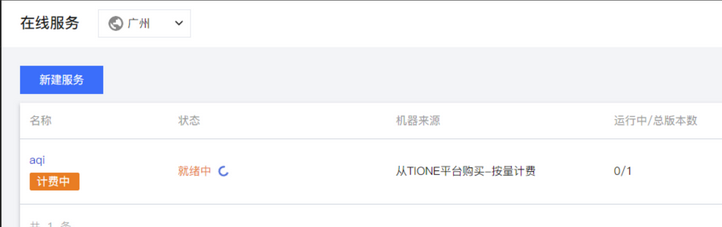
在等待服务就绪之后,我们就可以点击服务查看详情。
点击调用API,可以查看DeepSeek的服务调用地址。

同时可以点击实例进入详情页面,我们可以看到安装了DeepSeek大模型实例的信息。
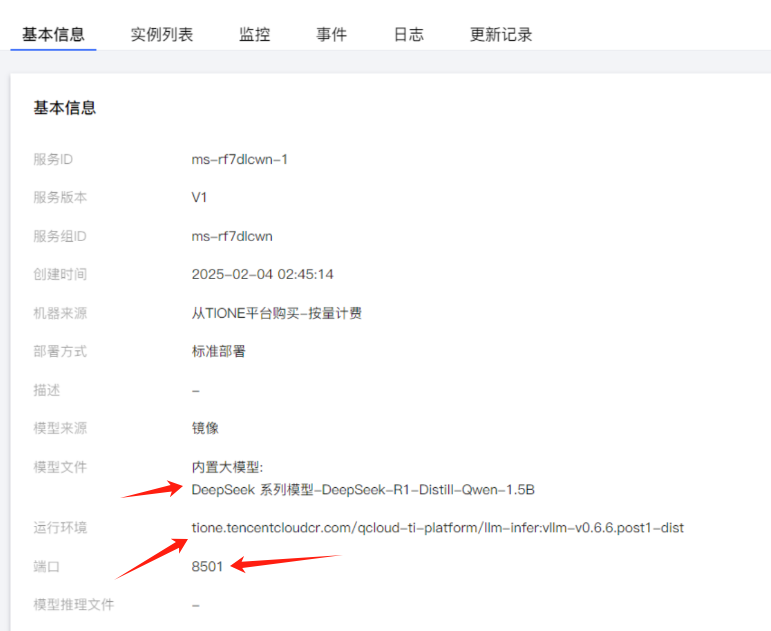
这样,我们就完成了DeepSeek在腾讯云TI平台的部署。
有任何问题或意见,欢迎在相关社区或官方文档中查阅更多信息,也可以向腾讯云和DeepSeek官方团队寻求支持。祝你一切部署顺利,玩得开心!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
