梦想操控:赋予机器人通过想象力进行模仿学习的组合式世界模型

梦想操控:赋予机器人通过想象力进行模仿学习的组合式世界模型

编辑:陈萍萍的公主@一点人工一点智能

论文链接:arxiv.org/pdf/2412.14957
项目链接:https://dreamtomanipulate.github.io/

简介
本文提出了一种名为DreMA的组合式操控世界模型,旨在解决现有世界模型在真实机器人应用中存在的两大问题:动态预测不准确和数据需求量大。DreMA通过可学习的数字孪生(learnable digital twins)将真实环境的高斯溅射(Gaussian Splatting)重建与物理引擎(如PyBullet)相结合,使机器人能够在模拟环境中“想象”新场景,并生成多样化的训练数据。其核心贡献包括:
· 组合性建模:通过对象中心的高斯溅射表示,将场景分解为独立可控的物体资产(object assets),支持动态组合与交互。
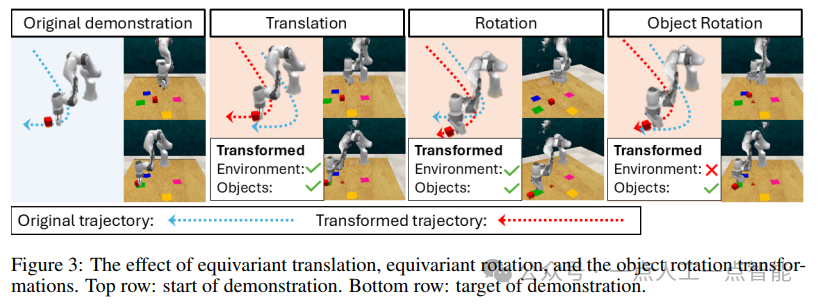
· 等变变换增强:利用几何变换(如平移、旋转)生成新的演示数据,显著降低模仿学习对原始数据的依赖。
· 真实机器人验证:在Franka Emika Panda机器人上实现了单样本策略学习(one-shot policy learning),展示了方法的实用性。
实验表明,DreMA在单任务和多任务设置中分别实现平均9.1%和13.1%的准确率提升,验证了其有效性和泛化能力。

问题背景
现有世界模型多基于隐式表示(如神经网络编码的潜在状态),虽能预测动作后果,但存在动态建模不精确和组合泛化能力不足的缺陷。例如,传统方法难以处理物体数量、位置和物理属性的变化,导致策略在真实环境中表现脆弱。作者提出三个关键需求:
· 组合性:模型需支持物体属性的动态重组(如位置、形状)。
· 对象中心化:以物体为基本单元建模,而非整体场景。
· 可操控性:通过显式控制物体状态实现精准交互。

DreMA的创新在于将高斯溅射的3D重建能力与物理引擎的动态仿真相结合,构建了一个既能生成高保真观测、又能预测物理交互结果的混合模型。例如,通过高斯溅射重建的物体可转换为物理引擎中的网格,进而模拟碰撞、重力等效果。这种显式建模方式避免了传统隐式模型的“幻觉”问题。

相关工作分析
作者从三方面梳理了相关研究:
· 世界模型:早期工作(如Ha和Schmidhuber的World Models)通过潜在状态预测未来帧,但局限于游戏或导航任务。近期研究(如Yang等人的UniSim)虽引入扩散模型生成未来帧,但动态预测仍不准确。
· 仿真重建:神经辐射场(NeRF)和动态高斯溅射(Dynamic Gaussian Splatting)在视觉重建上取得进展,但缺乏组合性与物理一致性。例如,PEGASUS结合高斯溅射与网格仿真提升6D姿态估计,但无法预测未来状态。
· 模仿学习:主流方法(如PerAct)依赖大量演示数据,而数据增强技术(如随机裁剪)难以生成物理合理的动作序列。DreMA通过等变变换同时调整观测与动作,解决了这一瓶颈。
与现有方法相比,DreMA的独特性在于显式组合建模与物理约束的结合,使其既能生成多样化数据,又能保证动作的有效性。
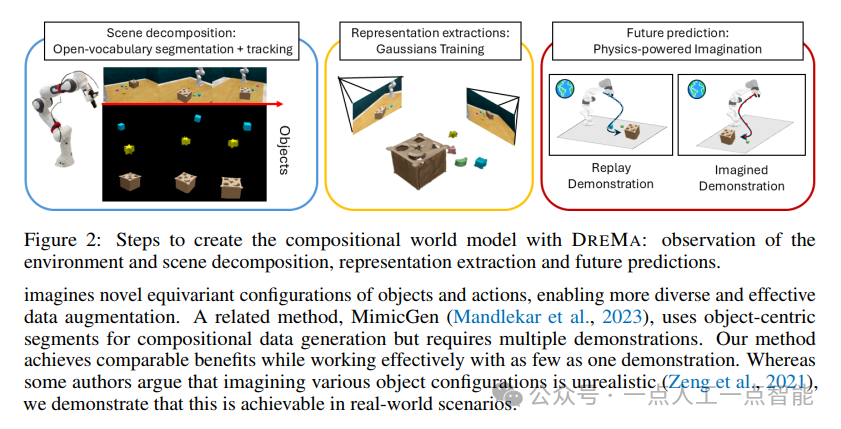

方法概述
4.1 对象中心的高斯溅射重建
高斯溅射通过优化3D空间中的高斯分布参数(位置p、旋转r、尺度s、颜色c、透明度α)实现场景重建。每个高斯单元可视为一个“粒子”,其渲染公式为:
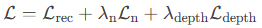
其中,Lrec为RGB重建损失,Ln约束表面法线一致性,Ldepth通过深度测量进一步优化几何精度。对象中心化通过分割掩码(segmentation masks)实现:对每个物体k,从视频帧中提取掩码Yk,并独立优化其高斯参数
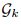
。例如,使用DEVA开放词汇跟踪模型自动分割物体,再通过掩码过滤背景信息。
4.2 物理引擎与动态建模
高斯溅射的几何表示需转换为物理引擎中的网格
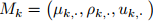
,其中μk为网格中心,ρk为朝向,uk为外观属性。物理引擎(PyBullet)根据牛顿力学更新物体状态:
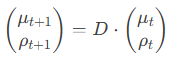
其中,D为动态算子,考虑机器人施加的力与物体间碰撞。高斯的位置和朝向同步更新为:
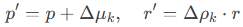
这种显式更新机制确保了物理一致性,避免隐式模型因累积误差导致的预测偏差。
4.3 等变变换与数据增强
模仿学习的关键挑战是生成物理有效的增强数据。DreMA通过对原始演示施加刚体变换(如平移Rκ、旋转R)生成新数据。例如,给定动作序列A=(a1,...,at),变换后的动作
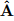
满足:
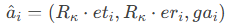
同时,物体的初始位姿也进行相同变换。为确保任务有效性,需验证变换后物体的最终位置
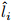
与目标位置的误差小于阈值τ:
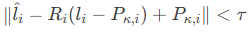
这种基于几何不变性的增强策略,显著提升了策略在未见场景中的泛化能力。

实验设计与结果分析
5.1 单任务与多任务学习
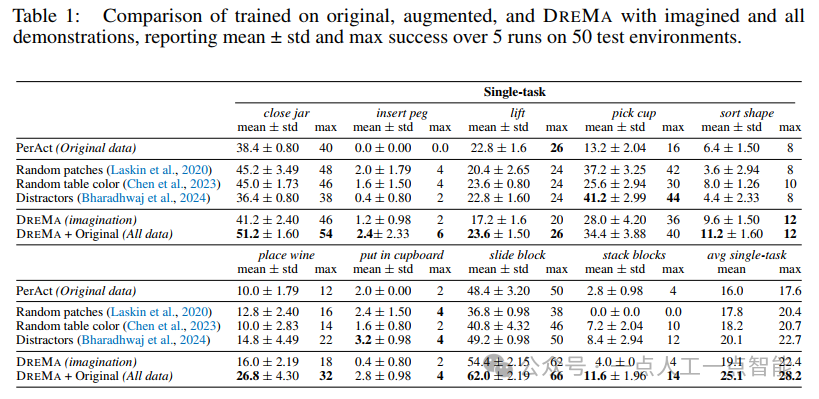
在RLBench模拟环境中,DreMA在9项任务(如关门、叠方块)中对比了三种训练方式:仅原始数据、仅增强数据、混合数据。结果显示,混合数据训练的PerAct模型在单任务中平均准确率达25.1%,较基线提升9.1%;多任务(关门、滑动积木、形状分类)中提升13.1%。关键发现包括:
· 数据效率:仅需1个原始演示即可生成800+有效增强样本。
· 泛化能力:增强数据覆盖更广的状态空间(图C.6),减少对初始位姿的敏感度。
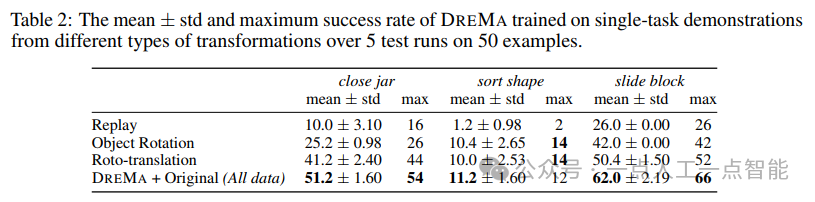
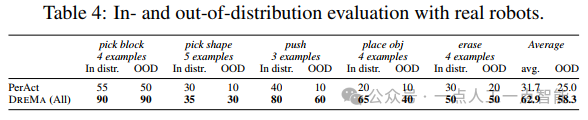
5.2 真实机器人验证
在Franka Emika Panda机器人上,DreMA在5项任务(如拾取方块、放置物体)中验证了方法的实用性。实验表明,增强数据使策略在分布外(OOD)场景中的成功率提升至62.9%,而仅用原始数据时仅为31.7%。局限性包括:
· 小物体处理:如“拾取形状”任务因物体尺寸小导致识别误差。
· 模型校准:物理参数(如摩擦系数)需进一步自适应优化。
5.3 消融实验
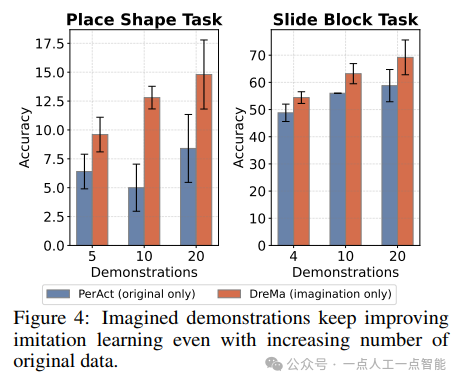
通过对比不同变换策略(如仅旋转、仅平移),发现复合变换(平移+旋转)效果最优,平均提升10.4%。此外,增加原始数据量(从4到20样本)持续改善性能,但增强数据的边际收益仍显著。

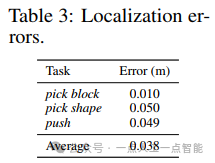

DREMA的扩展性与未来展望
尽管DREMA在仿真实验中展现出优异的性能,但其在真实世界任务中的扩展性仍然是一个重要议题。现实世界中的模仿学习和世界模型训练面临诸多复杂挑战,如动态环境变化、传感器噪声以及物理参数的不确定性。为此,研究团队采取了一系列工程手段来确保DREMA在实际应用中的可行性。首先,针对物理参数估计问题,研究团队采用了ASID(Memmel et al., 2024)和AdaptSim(Ren et al., 2023)等方法,简化了物理参数的选择过程。尽管如此,选择适当的物理参数依然是一个复杂的过程,研究团队在实验中选择了那些在验证集上表现良好的常量参数。
另一个关键挑战是如何确保仿真环境与真实世界的高度一致性。为了解决这个问题,研究团队引入了校准相机(Allegro et al., 2024),通过精确的视觉反馈来调整仿真环境,使其尽可能贴近实际情况。此外,研究团队还开发了2DGS Gaussian Splatting方法,解决了传统Gaussian Splatting在低分辨率条件下出现的行为异常问题,提升了深度信息的准确性。这些改进措施不仅增强了DREMA在实际应用中的可靠性,也为未来的扩展提供了坚实的基础。
尽管取得了初步成功,DREMA在真实世界中的广泛应用仍然面临一些挑战。例如,如何进一步提高世界模型的准确性,以更好地模拟复杂的真实环境;如何优化算法以降低计算资源消耗,使其更加适用于实时应用场景。此外,随着任务复杂性的增加,如何确保生成的想象数据依然能够有效指导机器人的行为也是一个值得深入探讨的问题。总体而言,DREMA为机器人模仿学习提供了一种全新的思路,其在现实世界中的扩展潜力巨大,有望在未来的研究和应用中发挥重要作用。通过不断的技术改进和优化,DREMA有望成为推动机器人智能化发展的关键技术之一。
腾讯云开发者
