去噪扩散模型,根本不去噪?何恺明新论文回归「去噪」本质
原创
去噪扩散模型,根本不去噪?何恺明新论文回归「去噪」本质
原创
CoovallyAIHub
发布于 2025-11-20 09:49:53
发布于 2025-11-20 09:49:53
导读
高质量的图像生成如今几乎都由扩散模型实现。从艺术创作到商业设计,从人脸生成到自然场景合成,基于扩散的生成模型已经成为多模态领域的重要基石。
但有没有一种可能,「去噪扩散模型」实际上并没有做到「去噪」?
ResNet 之父、超70万引用的 AI 大神何恺明的新论文《Back to Basics: Let Denoising Generative Models Denoise》敏锐地捕捉了这一现象,并带领扩散模型回归其最初的本源。>>更多资讯可加入CV技术群获取了解哦
在如今的大模型时代,扩散模型(Diffusion Models)几乎统治了图像生成领域:从 Stable Diffusion、Flux 到各种 rectified flow,大多数方法都遵循一个“默认套路”——让神经网络预测 噪声(ε) 或 混合了噪声的数据(v)。
但 MIT 与何恺明(Kaiming He)给这一逻辑来了一个漂亮的反向质疑:
既然叫做“去噪模型”,为什么不真正让模型去预测“干净的图像”?
他们提出的答案就是——预测干净图像 x,才是扩散模型在高维空间中更自然、更有效的方式。
并由此带来了一个极简、却强大的新框架:
JiT:Just image Transformers 不预训练、不对齐、不用 VAE、不用额外损失,只靠一个纯粹的 Vision Transformer 在像素层面做扩散。
什么扩散模型这些年偏离了“去噪”?
传统扩散理论的核心思想很简单:
给图像加噪声,再学着把噪声去掉。
但在实践中,人们发现“预测噪声 ε”比预测干净图像 x 更容易,效果更强。
于是整个行业默认采用:
- ε-prediction
- v-prediction(流速度)
然而,这里隐藏着一个被忽视的问题——噪声不是“数据”。噪声是高维的、无结构的。
论文从“流形假设(Manifold Assumption)”出发提出:
- 真正的自然图像 位于一个低维流形上
- 但噪声 ε、速度 v 在整个高维空间中均匀分布
也就是说:
预测一个“结构化”的干净图像很容易
预测一个“高维噪声”非常难
尤其在像素级扩散模型中,这个问题变得格外明显,例如:
- 512×512 图像,一个 patch 就是 32×32×3 = 3072 维
- ViT 的 hidden size 往往才 768、1024、1280…
这意味着:
网络根本没有能力同时编码如此高维的噪声信息。
这就导致了:ε/v-prediction 在高维像素扩散中完全崩溃
而 MIT 和何恺明的实验验证了:只有 x-prediction(预测干净图像)能在高维条件下稳定工作。
让模型直接预测干净图像(x-prediction)
研究最大的贡献是 非常“朴素”但非常革命性的一点:
扩散模型本来应该做“去噪”,所以让它预测干净图像 x 才是自然的。
何恺明团队指出,预测干净数据与预测带噪量在本质上是不同的。这一洞见基于机器学习中的流形假设(Manifold Assumption)。
流形假设认为,自然图像在高维像素空间中位于一个低维流形上。干净图像 𝒙 可以建模为处于流形上(on-manifold),而噪声 ϵ 或流速度 𝒗(例如 𝒗 = 𝒙 − ϵ)则本质上处于流形之外(off-manifold)。

screenshot_2025-11-19_13-35-17.png
该图直观展示了干净图像位于低维流形上,而噪声和流速处于流形之外的本质差异
因此,让神经网络预测干净图像(即 𝒙-prediction)在本质上不同于让其预测噪声或带噪的量(即 ϵ/𝒗-prediction)。
这一差异在高维空间中尤为关键。当需要预测高维的噪声或带噪量时,网络需要足够的容量来保留所有相关信息;而预测干净图像时,即使容量有限的网络也能有效工作,因为它只需要保留低维流形上的信息。
他们的核心观点:
x 位于低维流形,Transformer 不需要建模高维噪声,只需要保留“图像结构”。
ε / v 是高维无结构分布,噪声包含 100% 的高维信息,网络必须“记住全部细节”,难度指数增长。
他们用一个很有说服力的玩具实验:
2 维真实数据被投影到 512 维空间,使用同一个小网络生成数据
screenshot_2025-11-19_13-48-39.png
结果发现:
x-prediction 在高维空间依然能恢复数据结构, ε 和 v-prediction 完全崩溃,这个现象和 ImageNet 像素扩散中的结果高度一致。
JiT:纯粹、极简,却非常强大的像素级扩散模型
基于 x-prediction,作者提出了 JiT(Just image Transformers):
JiT 使用普通的 Vision Transformer,直接在高维像素块上进行 𝒙-prediction,无需任何预训练、额外的损失函数或复杂的架构设计。这种方法在 ImageNet 256×256 和 512×512 分辨率上取得了有竞争力的结果,而在相同设置下,传统的 ϵ-prediction 和 𝒗-prediction 则会灾难性地失败。

screenshot_2025-11-19_13-42-56.png
简洁的ViT架构直接在像素块上进行𝒙-prediction,无需复杂设计
令人惊讶的是,研究还发现,在嵌入层引入瓶颈设计(降低维度)甚至能提高生成质量,这与经典流形学习的观察一致。

screenshot_2025-11-19_13-43-52.png
即使将768维的patch压缩到16维的小瓶颈,模型仍能有效工作,且适度瓶颈反而提升性能
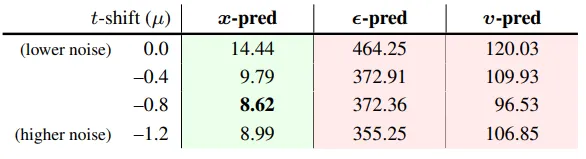
实验验证:𝒙-prediction 的显著优势
为了验证这一理论,研究团队进行了系统的实验对比:

screenshot_2025-11-19_13-46-20.png
在ImageNet 256×256数据集上,只有𝒙-prediction能够取得合理结果,而ϵ-prediction和𝒗-prediction都灾难性失败

screenshot_2025-11-19_13-47-15.png

screenshot_2025-11-19_13-47-22.png
JiT在不同分辨率下都保持良好性能,显示其强大的扩展能力和计算效率
对AI开发平台的启示
这一研究使去噪扩散模型回归本源,探索一种在原始自然数据上构建基于 Transformer 的扩散模型的自洽范式。它不仅对计算机视觉领域有重要意义,也为其他涉及原始高维自然数据的领域(如蛋白质、分子或气象数据)提供了启示。
Coovally操作动图.gif
!!点击下方链接,立即体验Coovally!!
平台链接:https://www.coovally.com
在Coovally这样的AI开发平台中,这种简洁而强大的方法尤为值得关注。 Coovally致力于简化AI开发流程,让开发者能够更高效地构建和部署模型。何恺明团队的研究方向与这一理念不谋而合——通过减少领域特定的设计,使「Diffusion + Transformer」的通用范式能够在更广泛的领域中应用。
总结
何恺明团队的这项工作提醒我们,有时最有效的解决方案往往是最直接的。在追求复杂架构和额外组件的同时,不妨回归基础,重新思考问题的本质。
「噪声与自然数据本质不同」,神经网络的能力不是无限的,它们应该更好地利用自身的容量来建模数据而非噪声。在这一视角下,𝒙-prediction 的优越性在 hindsight 看来是自然而然的结果。
随着越来越多像Coovally这样的平台将这类先进技术封装成易用的工具,我们可以期待,高质量的图像生成技术将被更广泛地应用,赋能更多领域的创新和发展。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者
