Patterns | 大语言模型赋能药物研发


DRUGONE
大语言模型(LLMs)在药物发现与开发领域的应用标志着一次重要的范式转变,为理解疾病机制、推动全新药物发现以及优化临床试验流程提供了新方法。本综述强调了LLMs在重塑药物研发各阶段中的作用。研究人员探讨了这些先进的计算模型如何揭示靶点与疾病的关联、解读复杂的生物医学数据、提升药物分子设计、预测药效与安全性,并推动临床试验的执行。本研究旨在为计算生物学、药理学及AI4Science领域的研究人员与实践者提供全面的概述,展现LLMs对药物发现与开发的潜在变革性影响。

“语言只是科学的工具,词语只是思想的符号。” ——塞缪尔·约翰逊
新药的研发是一项长期承诺,通常需要10–15年,耗资超过20亿美元,才能将一种新药带到患者手中。该过程传统上分为三个阶段:理解疾病并选择治疗靶点、开发靶向疗法,以及在临床试验中测试其有效性。由于生物系统的复杂性和所需的广泛验证,每个阶段都耗时且资源密集。虽然这些步骤对于最小化风险、确保只有安全且有效的疗法被引入至关重要,但冗长的周期也延迟了患者获得潜在疗法的机会。因此,通过提高效率和扩展当前实践的能力,可以带来巨大的收益。
更广阔的视角
药物开发是一个公认的漫长且昂贵的过程,往往需要十年以上,并耗费数十亿美元。如此冗长的时间线严重延迟了患者获取关键治疗手段的机会。人工智能,尤其是能够同时理解科学与人类语言的大型语言模型,为这一挑战提供了有前景的解决方案。尽管LLMs最初是为理解和生成自然语言而设计的,但它们正在被扩展,用于“理解”科学数据,包括DNA、蛋白质和化学结构的复杂语言。
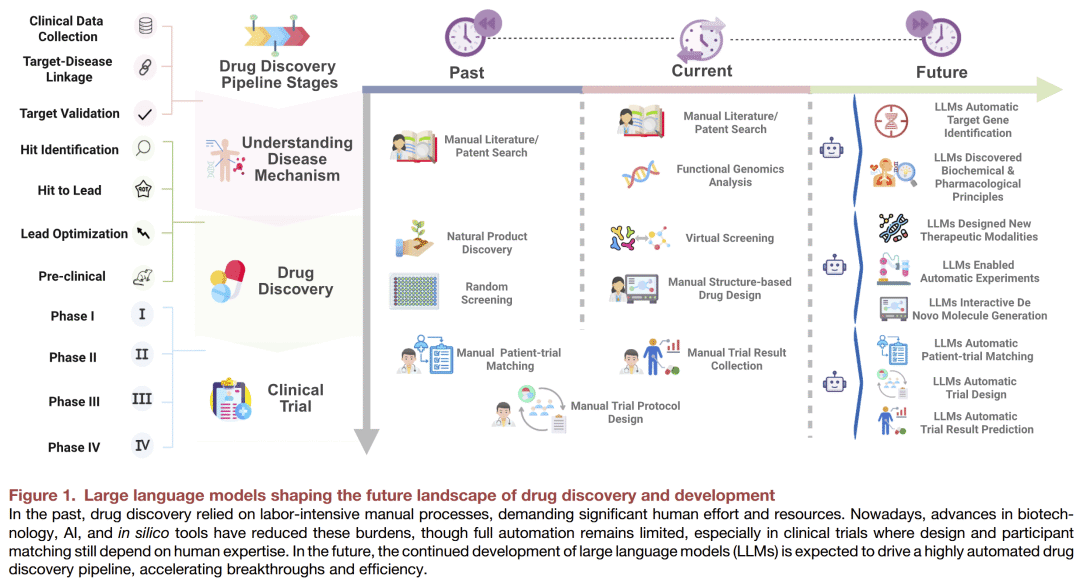
本文强调了LLMs如何成为药物开发各阶段的重要工具。例如,它们可以帮助研究人员快速定位疾病的生物学原因,甚至提出新的药物靶点。LLMs还能从零设计新的药物分子,在合成之前预测其有效性和安全性,并简化临床试验的复杂流程,使之更高效。通过自动化和加速这些关键步骤,LLMs有潜力显著降低新药上市的时间和成本,从而彻底改变未来疗法的发现与开发模式。
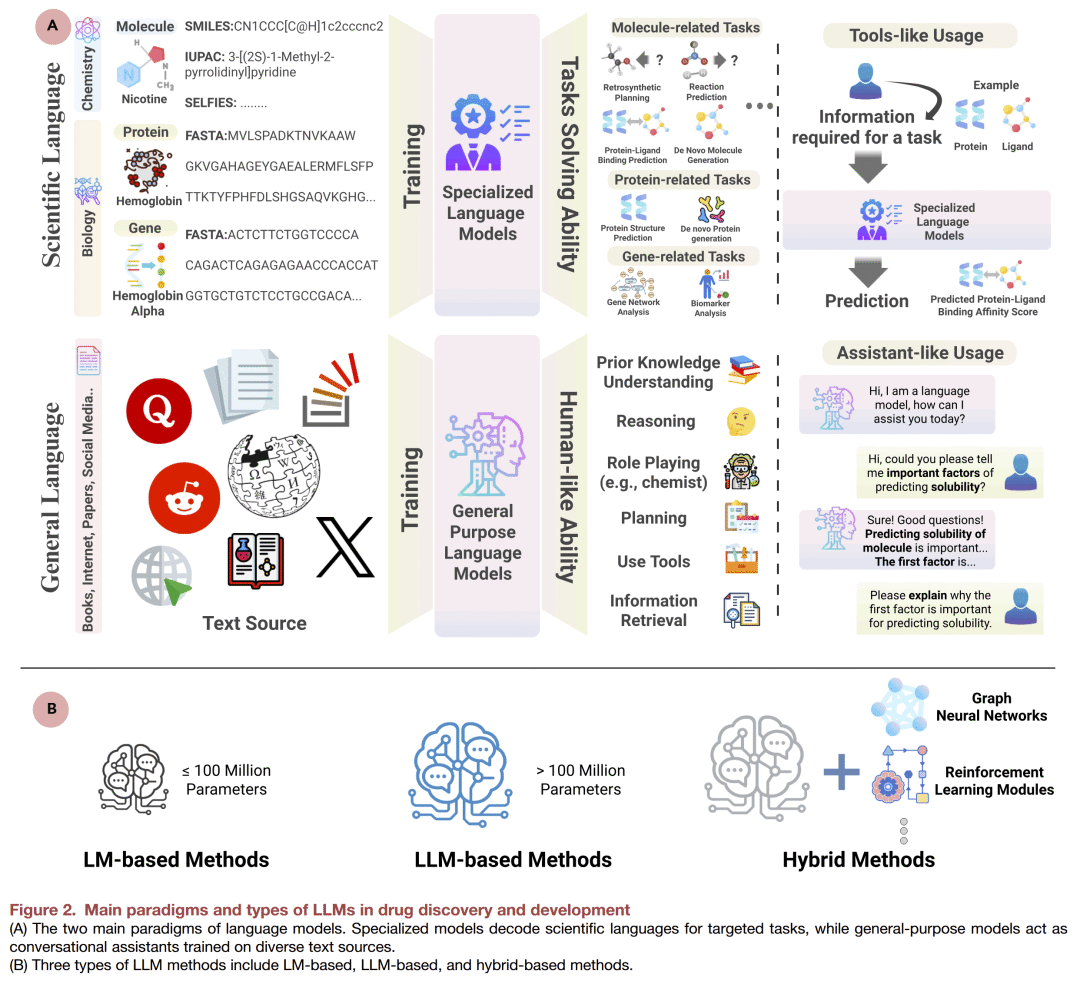
疾病机制研究
理解疾病机制是药物发现的首要步骤,其主要目标是识别适合的药物靶点。该过程通常包括三个主要阶段(图3):临床数据收集、靶点-疾病关联分析以及靶点验证。
- 临床数据收集:这一阶段包括患者数据的收集与亚群体划分,使得临床信息与多组学数据得以整合,从而帮助理解疾病差异以及不同患者群体中潜在的机制差异。
- 靶点-疾病关联:通过通路分析、基因表达谱以及实验手段(如CRISPR-Cas9和体内疾病建模)来建立潜在蛋白靶点与疾病之间的联系。
- 靶点验证:这是一个持续、迭代的过程,包括作用机制评估、治疗方式选择以及安全性和可行性分析,确保在进入研发后续阶段前靶点具备可靠性与可操作性。
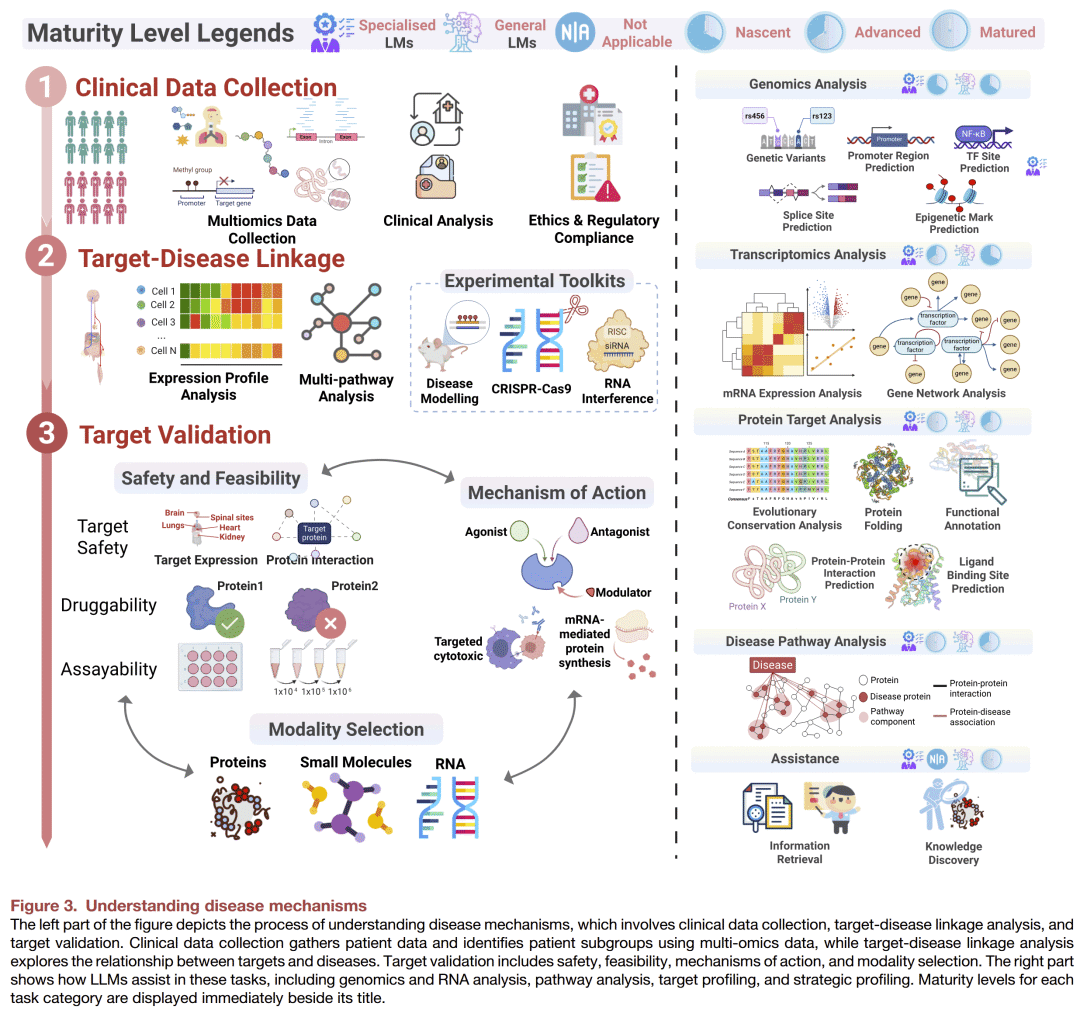
基因组学分析
基因组学分析为疾病机制研究的早期阶段提供基础,尤其在临床数据收集与靶点-疾病关联阶段。大规模全基因组关联研究(GWAS)已识别出与多种疾病相关的重要基因组区域,这为靶点发现与疾病理解提供了方向。整合遗传学关联信息能显著提高临床靶点的成功率。
近年来,DNA-BERT、Nucleotide Transformer 和 HyenaDNA 等核苷酸级LLMs的出现,使得基因组信息能够以类似语言的方式被解读。这些模型通过“掩码语言建模”等方法,能够识别功能相关的变异(如SNPs、插入或缺失),并优先预测可能驱动疾病的遗传变体。此外,这些模型还能预测调控元件(如启动子、转录因子结合位点、剪接位点)以及表观遗传标记的功能变化,从而为疾病亚型驱动因子的识别提供支持。
RNA领域的LLMs(如RNA-FM、RNAErnie、RiNALMo)则提升了RNA结构与表达调控的功能分析,尤其在亚型划分与机制建模方面。它们能够预测RNA二级结构、识别剪接位点并对未见过的RNA家族表现出良好泛化性。总体而言,这些模型为研究遗传变异如何驱动疾病表型奠定了基础。
转录组学分析
在疾病机制研究中,转录组数据是理解细胞类型特异性基因表达变化的重要来源。单细胞测序和高通量测序的进展,使得研究人员能够以前所未有的分辨率研究细胞行为。然而,罕见疾病或不可获取组织的数据仍然有限,限制了模型的训练与泛化能力。
为解决这一问题,专门的转录组LLMs被开发出来:
- Geneformer:通过“排序值编码”将单细胞转录组映射为基因序列,能够跨组织对比表达模式;并利用 in silico 基因敲除推断基因网络中的关键因子。
- scGPT、scMulan、scFoundation:在单细胞多组学分析中表现突出,能够零样本生成细胞类型聚类,捕捉复杂的基因网络关系。
- GeneCompass、scBERT、CellPLM:通过跨物种数据整合、批次效应校正和细胞-细胞互作建模,进一步提升了网络推断的精度。
这些模型支持患者分型、功能分析与靶点发现。例如,Geneformer能在仅884个细胞的条件下,识别出NOTCH1网络的关键因子,优于传统依赖3万细胞的分析方法。
蛋白靶点分析
蛋白质层面的分析是靶点验证的核心,用于评估候选靶点的结构、功能与可药性。LLMs在蛋白分析中主要涉及以下任务:
- 进化保守性分析:如ESM、Ankh、xTrimoPGLM等模型利用进化信号推断关键残基和功能位点。
- 蛋白质折叠预测:AlphaFold2/3、RosettaFold、RGN等模型能以接近实验精度预测三维结构,甚至扩展至蛋白-配体/核酸复合物。
- 功能注释:通过嵌入向量学习蛋白质功能,支持未表征蛋白的功能推断。
- 可药性评估:DockGPT、RosettaFold All-Atom等方法能预测结合位点、蛋白-配体相互作用以及突变对亲和力的影响。
这些能力大幅提升了靶点验证的效率。例如,AlphaFold3 能整合小分子、离子及修饰残基,提升蛋白-配体复合物预测的精度,为结构基础上的药物设计奠定基础。
通路分析
通路分析在靶点-疾病关联阶段至关重要,帮助研究人员将候选基因或变体与更广泛的生物功能和疾病路径联系起来。通用型LLMs凭借对科学文献和数据库的整合能力,能辅助组装基因调控网络、优先排序候选基因并生成新的假设。例如,GPT-4等模型已展示出自动生成基因网络代码、总结候选基因并进行文献验证的能力,体现了其在通路组装与假设生成中的潜力。
未来的模型需要实现动态、细胞类型特异的通路建模,支持因果推断,并将通路分析结果直接与临床疗法关联。
辅助作用
在整个疾病机制研究流程中,通用型LLMs作为跨学科助手发挥了关键作用。它们能够进行信息检索、跨模态结果综合、实时文献更新,并将复杂的技术内容转化为适合不同学科背景的解释。这种能力帮助研究人员在数据、解读和决策之间快速迭代,从而提升跨领域合作效率。
药物发现
药物发现过程包括若干关键步骤(图4):初始命中化合物识别(hit identification)、从命中到先导化合物的转化(hit to lead)、先导化合物优化(lead optimization)以及临床前开发(preclinical development)。
- 命中识别:确定具有潜在治疗效果的化合物。
- 从命中到先导:筛选并确认最具前景的候选物。
- 先导优化:提升先导化合物的效力、稳定性和安全性。
- 临床前开发:在动物模型中测试优化后的候选物,为进入人体试验做准备。
LLMs能够在这一流程中发挥重要作用,从化学设计到分子模拟,再到药物性质预测与优化。
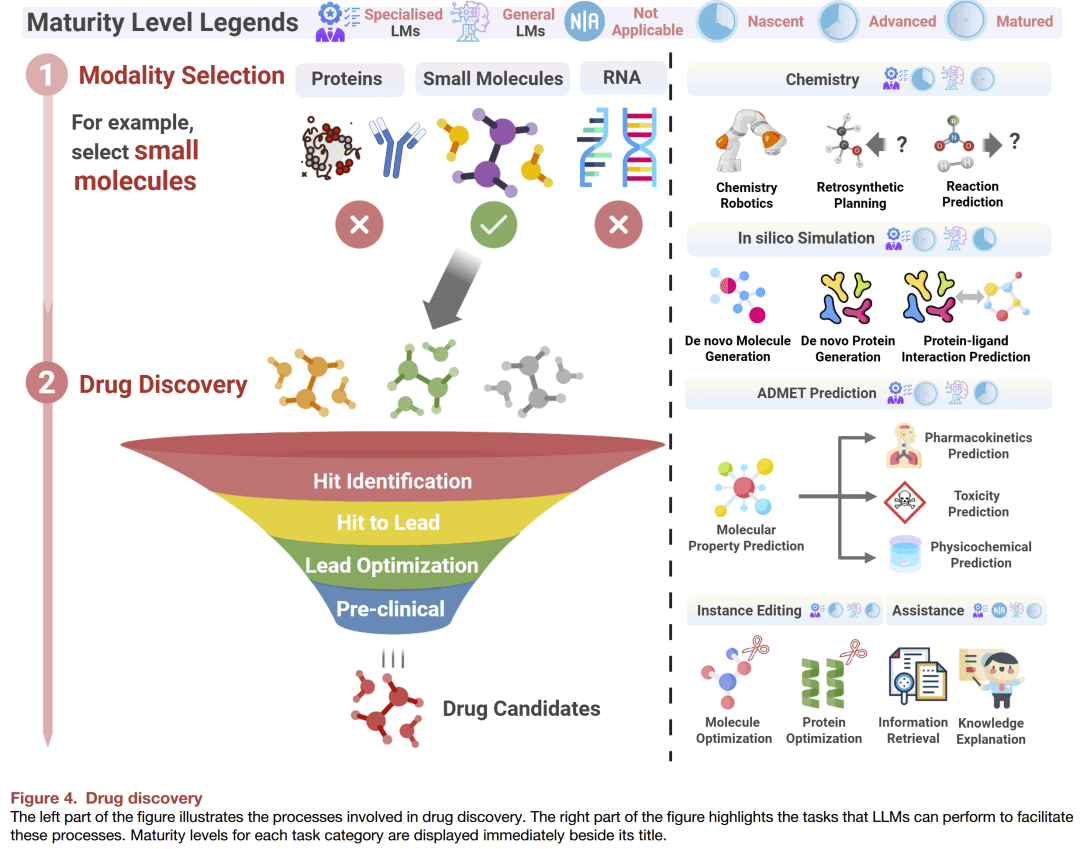
化学研究
药物发现的起点在于新化合物的设计与合成。随着自动化实验室的发展,传统的药物化学逐渐演变为结合机器人系统的高通量实验模式。LLMs作为研究人员与自动化平台之间的智能接口,能够:
- 将自然语言实验指令转化为机器可执行的协议;
- 推荐逆合成路径;
- 预测化学反应结果。
例如,GPT-4 等通用LLMs已被用于生成机器人执行代码,实现实验流程的自动化。此外,像 Coscientist、Chemcrow 这样的系统通过整合多种工具(如 SMILES 转换、专利检索、反应分类),能够完成复杂的化学实验规划。
未来,LLMs在化学实验中的应用将进一步扩展到实时反应优化、新催化剂与新骨架的提议,以及全自动的合成设计。
计算机模拟(In silico simulation)
计算机模拟是现代药物发现的核心环节,能够在合成之前对分子进行虚拟设计与评估,主要包括:
全新分子生成:设计新的小分子结构,可分为无约束生成(探索化学空间)和有约束生成(满足药物样性、ADMET等要求)。
- 专用模型如 MolGPT、Lingo3DMol 在结构生成上具有高精度;
- 通用模型如 MolT5、GIT-Mol 通过整合图、图像与文本,实现更广泛的分子生成。
全新蛋白生成:通过 LLMs设计蛋白质序列,既可探索蛋白质空间,也可针对特定功能进行约束生成。
- ProtGPT2、ProGen、PoET 等模型已能生成功能性蛋白;
- RFDiffusion、PocketGen 则利用结构信息进行高亲和力结合口袋设计。
蛋白-配体相互作用预测:这是药物研发的核心任务,LLMs能够基于序列信息推断结合位点、结合能及突变效应。
- 专用模型如 PSICHIC、STAMP-DPI 展示了超越传统结构方法的能力;
- 通用模型如 Galactica 能结合更广泛的知识背景进行预测。
这些能力能够显著加速先导化合物的优化和筛选。
ADMET 预测
ADMET(吸收、分布、代谢、排泄与毒性)预测在先导化合物优化阶段至关重要,能够帮助研究人员提前淘汰药代动力学或毒理学性质不佳的候选物。
- 专用模型(如 Molformer)在性质预测上设定了新基准;
- 通用模型(如 LLM4SD、Galactica)能够补充传统的机器学习工作流,提升预测精度。
通过更准确的 ADMET 预测,研发人员能够减少后期昂贵的失败风险,并优先考虑具备良好生物学特性的分子。
临床试验
临床试验是药物研发的最后阶段,通常包括四个阶段(I–IV),其核心目标是验证药物在人群中的安全性与有效性。由于设计复杂、成本高昂、周期冗长,临床试验是药物研发中最耗时的部分。
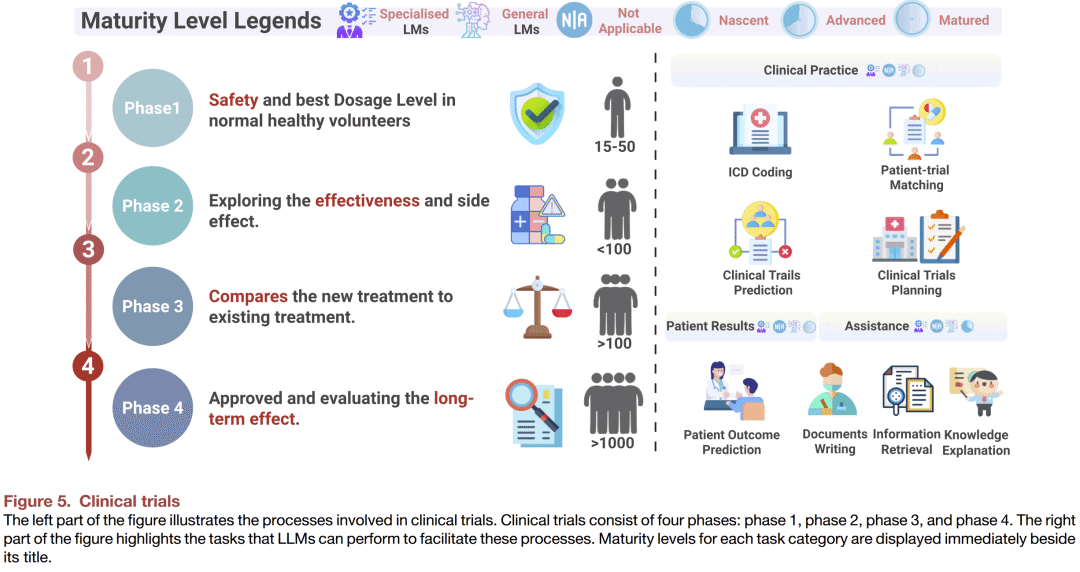
LLMs在临床试验中的潜在应用包括:
- 患者匹配:分析患者病历与试验需求,快速筛选合适人群。
- 试验设计:基于历史数据和临床需求优化试验方案。
- 试验结果预测:通过分析先前的临床试验数据,预测药物在特定人群中的表现。
- 文档与监管支持:自动化处理试验报告与监管文书,提高合规效率。
一些早期研究已经表明,LLMs能显著减轻临床试验中繁琐的任务,加快流程。
未来方向
尽管LLMs展现了巨大潜力,但其应用仍面临若干挑战与问题:
- 伦理问题:包括隐私保护、公平性与偏倚风险。由于LLMs逐渐被应用于敏感的健康数据和医疗决策,这些问题必须被严肃对待。
- 技术挑战:包括幻觉(hallucination)、可解释性不足等。缺乏可靠解释可能限制其在药物研发和临床中的应用。
- 跨模态整合:未来的LLMs需要同时处理基因组、蛋白质组、代谢组等多组学数据,并与空间、时间等维度结合。
- 可扩展性与可信度:只有当LLMs能在真实的实验和临床环境中展现稳定性与可重复性时,它们才可能成为可信赖的工具。
未来研究将聚焦于提升模型的透明度、稳定性与跨领域应用能力,使其真正成为药物研发中的“共创伙伴”。
结论
大型语言模型正在深刻改变药物发现与开发的格局。研究人员综述了其在疾病机制解析、分子生成与优化、临床试验加速等环节的应用,并提出了对未来发展的展望。总体来看:
- 在疾病机制研究中,LLMs通过基因组、转录组与蛋白质组分析,帮助识别靶点并揭示潜在病理机制。
- 在药物发现中,它们能自动化化学实验、进行分子与蛋白设计,并预测药物性质。
- 在临床试验中,它们为患者匹配、试验设计与结果预测提供了高效支持。
尽管仍存在挑战,但LLMs已成为推动药物研发提速与降本的重要引擎。研究人员认为,随着伦理与技术问题逐步解决,LLMs将在未来药物研发中扮演核心角色,加速创新疗法的诞生,最终惠及患者。
整理 | DrugOne团队
参考资料
Zheng et al., Large language models for drug discovery and development, Patterns (2025),
https://doi.org/10.1016/j.patter.2025.101346
内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号