Nat. Commun. | 人机协作医学文献挖掘基础模型

Nat. Commun. | 人机协作医学文献挖掘基础模型

DrugAI
发布于 2026-01-06 12:56:26
发布于 2026-01-06 12:56:26
DRUGONE
在循证医学中,系统性文献综述是核心环节,但人工执行往往耗时长、成本高。研究人员提出了一个名为 LEADS 的人工智能基础模型,利用21,335项系统综述、453,625篇临床试验文献和27,015条临床试验注册信息构建的63万余条指令数据进行训练。与多种前沿大语言模型相比,LEADS在六大医学文献挖掘任务(研究检索、文献筛选、数据提取等)中均表现更优。在一项涉及16名临床医生和研究人员的用户研究中,LEADS帮助提高了召回率并节省了20%以上的时间,同时提升了数据提取的准确性。这说明在医学文献挖掘中,结合高质量领域数据训练的专业模型能显著增强研究人员的效率与成果可靠性。

医学文献挖掘(如系统综述与Meta分析)已成为医学研究和指南修订的重要途径,但这一过程极为耗时,平均完成一个系统综述需要超过一年,并且单个机构的年均成本可达千万美元。同时,医学文献数量庞大且增长迅速,PubMed已收录超过3500万条文献,每年新增百万篇以上,其中不少元数据质量欠佳,进一步增加了检索和筛选的难度。
尽管人工智能近年来在医学文献挖掘中展现出潜力,例如用于关键词生成、研究筛选与信息抽取,但现有方法往往局限于单一任务或小规模数据集,缺乏全面性和可扩展性。更重要的是,许多模型强调自动化,却忽视了在人机协作中确保准确性与可信度的需求。因此,开发能支持多任务、灵活输入,并与专家高效协作的基础模型,成为亟待解决的问题。
方法
研究人员提出的 LEADS(Large language model for human-AI collaboration in literature mining)模型,基于通用LLM构建并通过 LEADSInstruct 数据集进行微调。该数据集覆盖六个核心子任务:
- 检索查询生成:根据研究问题自动生成优化检索式;
- 研究纳入评估:结合PICO元素,预测候选文献的纳入资格;
- 研究特征提取;
- 研究组设计提取;
- 受试者统计信息提取;
- 试验结果提取。
训练集来源于大规模系统综述、临床试验登记与相关文献的链接信息,最终形成63万余条高质量指令数据。LEADS在Mistral-7B模型基础上完成微调,具备长文本处理能力,可在无需额外训练的情况下跨疾病领域执行多任务。
结果
LEADS与LEADSInstruct总体表现
LEADS在六类任务上均显著优于GPT-4o、GPT-3.5、Claude-Haiku等通用LLM,以及部分医学专用LLM。在覆盖数千系统综述与数十万文献的测试集上,LEADS展现出更强的通用性与稳定性。
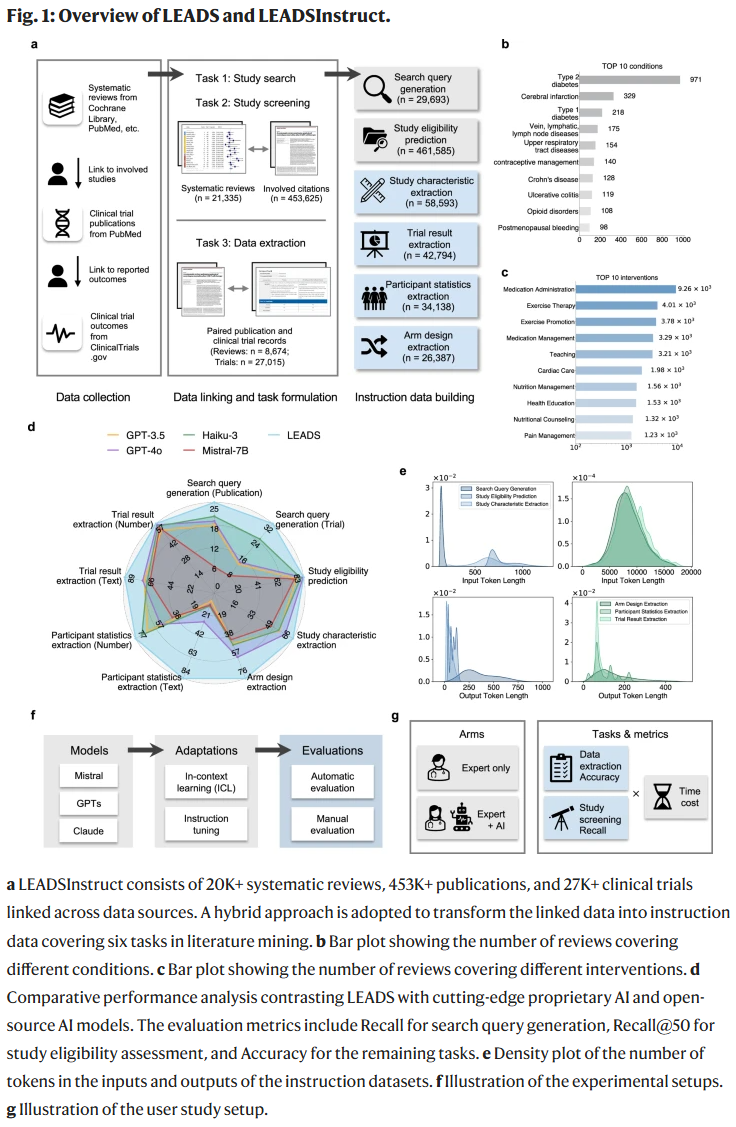
文献检索
在超过1万项系统综述的测试中,LEADS在PubMed与ClinicalTrials.gov的检索召回率显著优于基线模型,提升幅度最高可达7%以上。尤其在试验检索中,LEADS召回率几乎是GPT-4o的两倍。采用多次生成并集成(LEADS+Ensemble)策略后,检索召回率进一步提升至70%以上。
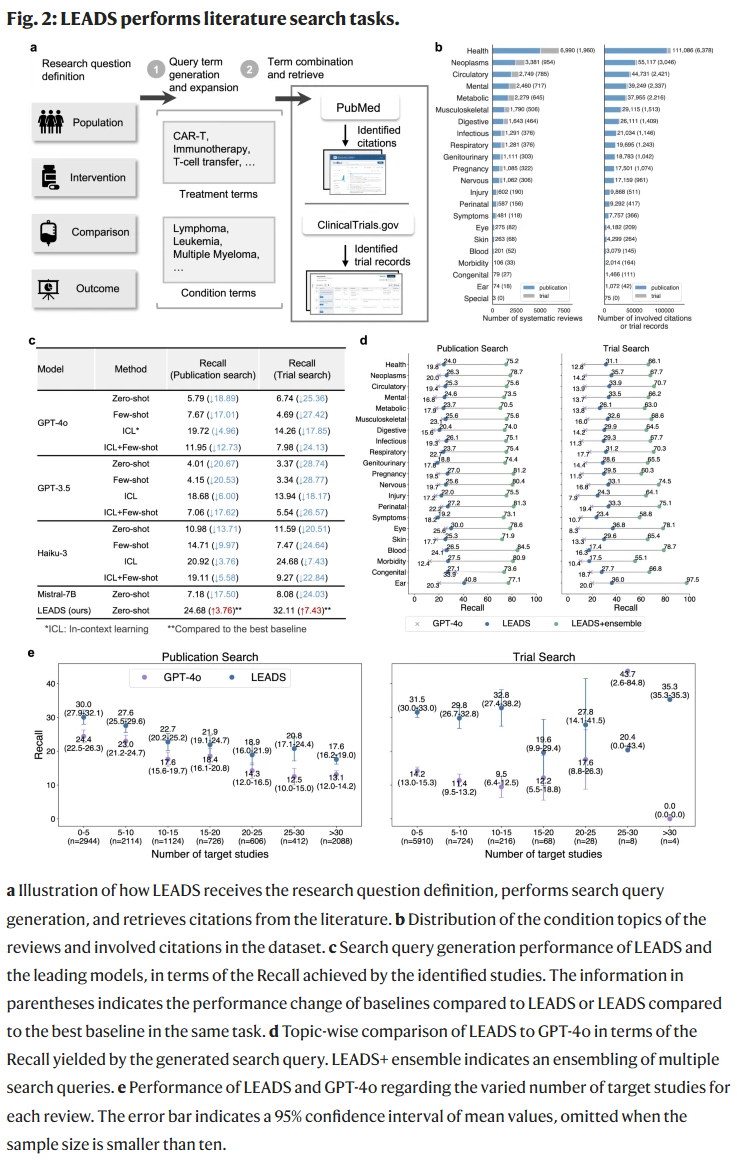
文献纳入评估
在40万条“综述-候选文献”对的数据集上,LEADS在Recall@50指标上与GPT-4o相当,并在大多数主题领域表现更佳。其在候选文献数量增多时依然保持稳定,而基线方法性能明显下降,显示出较强的鲁棒性。
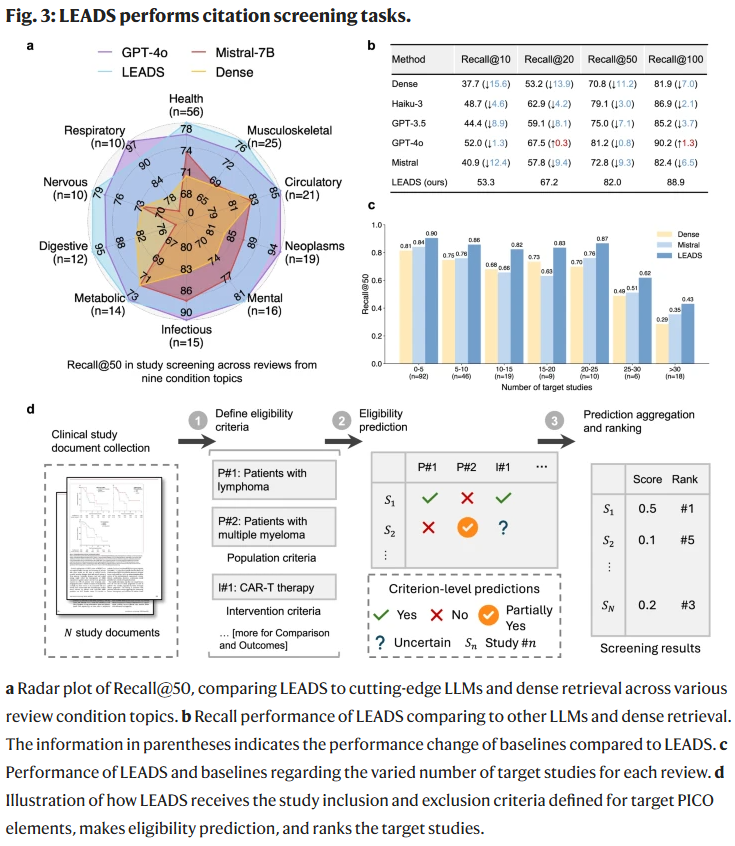
数据提取
LEADS在四类数据提取任务(研究特征、研究组设计、受试者统计、试验结果)中全面超越基线。尤其在受试者统计提取中,准确率显著高于GPT-4o。人工校验也证实,LEADS在多个任务上比其他模型提高了10%以上的准确度,同时在长文本输入下依然保持性能。

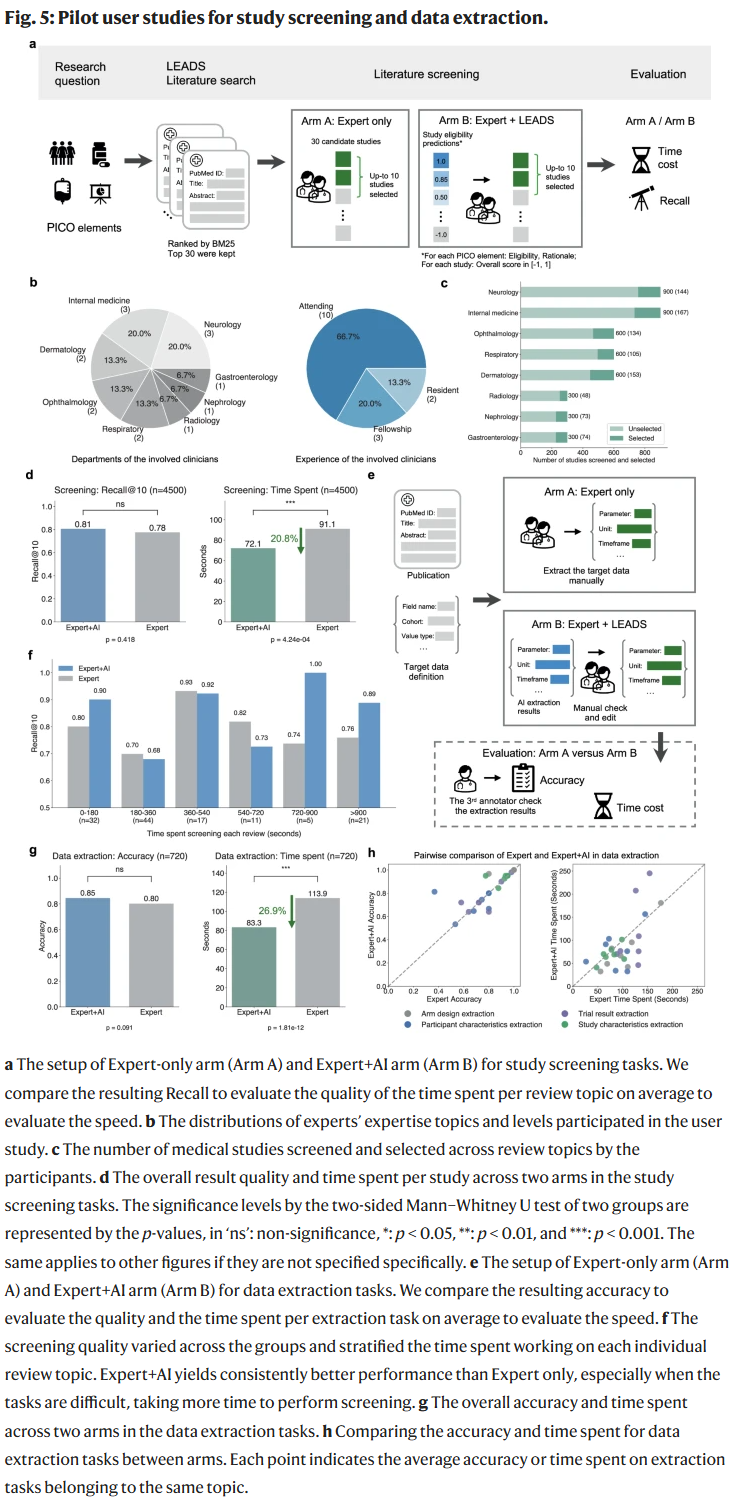
用户研究
在一项涉及15名临床医生和2名研究人员的试点研究中,LEADS展现了明显优势:
- 文献筛选:专家+AI组的召回率达到0.81,高于专家独立完成的0.78,同时节省20.8%的时间。
- 数据提取:专家+AI组的准确率为0.85,高于专家独立完成的0.80,时间缩短26.9%。
参与者反馈表明,LEADS的预测结果与解释能够帮助快速定位关键信息,提升整体效率。
讨论
系统性综述对循证医学至关重要,但其高时间与经济成本构成了重大挑战。LEADS的提出为这一问题提供了切实可行的解决方案。通过利用大规模、高质量的医学文献和临床试验数据构建训练集,研究人员证明:专门化的小模型在特定领域可优于通用大模型。LEADS不仅提升了检索、筛选与提取效率,还能在专家工作流中无缝集成,显著节省时间和人力。
然而,该研究也存在局限性:训练数据仍可能包含偏倚或错误;用户研究的规模有限,尚需更大样本与更接近真实环境的验证;此外,LEADS运行需要较高算力支持,限制了部分用户的使用场景。
总体而言,LEADS展示了在人机协作框架下,基础模型在医学文献挖掘中的巨大潜力。未来,随着数据与方法的不断优化,此类模型有望进一步推动循证医学与药物研发的发展。
整理 | DrugOne团队
参考资料
Wang, Z., Cao, L., Jin, Q. et al. A foundation model for human-AI collaboration in medical literature mining. Nat Commun 16, 8361 (2025).
https://doi.org/10.1038/s41467-025-62058-5
内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号