从"能用"到"敢改",中间差了多少工程能力?

从"能用"到"敢改",中间差了多少工程能力?

AI智享空间
发布于 2026-02-27 12:04:33
发布于 2026-02-27 12:04:33
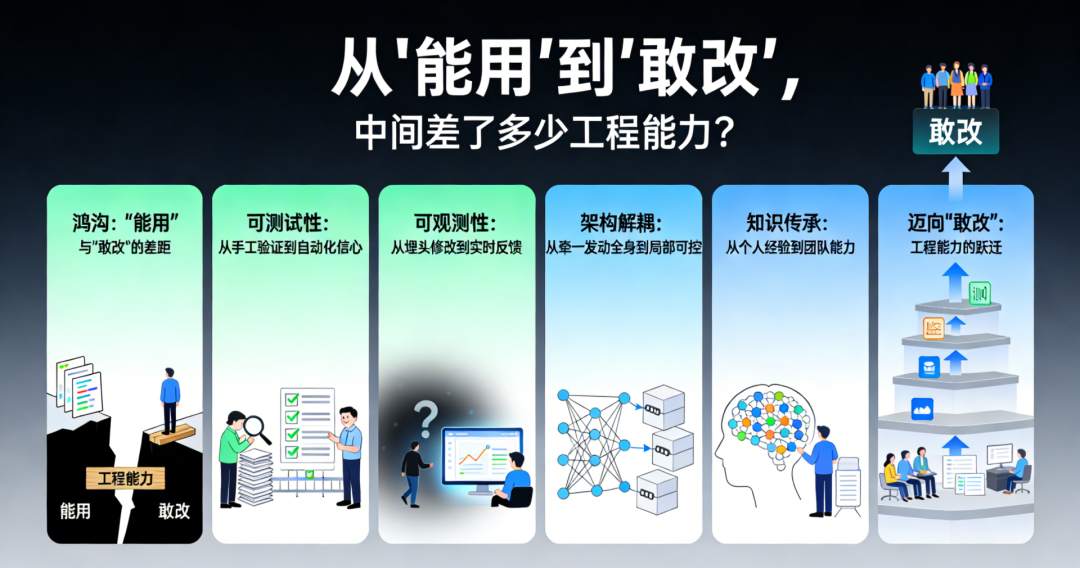
在技术团队中,我们都见过这样的场景:系统运行良好,业务稳定增长,但当需要重构某个核心模块时,所有人都面露难色。不是因为技术难度太高,而是因为没人敢动——担心改了之后引发连锁反应,担心上线后出现未知问题,担心背上“把系统搞崩”的责任。
这揭示了一个残酷的真相:“能用”和“敢改”之间存在着巨大的鸿沟。前者只需要代码能跑通、功能能实现;后者则需要系统具备可演进性,团队具备改造信心。这不仅是技术能力的差距,更是工程文化和系统设计哲学的分野。
“能用”的系统往往建立在脆弱的平衡上,依赖个别核心开发者的经验和记忆;而“敢改”的系统则建立在工程能力的积累上,让任何合格的工程师都能放心地进行演进。这两者之间的距离,决定了团队的发展上限和组织的技术债务累积速度。
本文将从以下几个维度剖析这一差距
- 可测试性:从“手工验证”到“自动化信心”
- 可观测性:从“埋头修改”到“实时反馈”
- 架构解耦:从“牵一发动全身”到“局部可控”
- 知识传承:从“个人经验”到“团队能力”
一、可测试性:从“手工验证”到“自动化信心”
“能用”阶段的测试困境
许多系统在初期能够快速上线,靠的是核心开发者的经验判断和手工验证。这个阶段的典型特征是:每次发布前,团队都要花费大量时间进行人工回归测试,核对各种业务场景,生怕遗漏某个关键路径。
我见过一个电商团队,每次修改促销引擎的代码,都需要三个资深工程师花两天时间手动测试各种优惠组合。他们清楚地知道哪些场景容易出错,但这些知识只存在于大脑中,没有沉淀为可执行的测试用例。结果是:系统“能用”,但没人敢轻易修改,因为改动的影响范围完全依赖人的记忆和经验。
“敢改”阶段的自动化护航
相比之下,具备良好可测试性的系统会建立多层次的自动化防护网。不是简单地追求测试覆盖率,而是将关键业务逻辑和边界条件固化为可重复执行的测试用例。
某支付团队的做法值得借鉴:他们为每一次生产事故都补充对应的测试用例,确保同样的问题不会再次出现。更重要的是,他们将测试用例按影响半径分级——核心支付链路的测试必须100%通过才能发布,而边缘功能的测试失败可以降级处理。这种分级策略让团队在保证质量的同时,也保持了足够的迭代速度。
当测试成为信心的来源而非负担,工程师才敢于重构。因为他们知道,即使改错了,测试会在几分钟内给出反馈,而不是等到用户投诉才发现。
二、可观测性:从“埋头修改”到“实时反馈”
“能用”阶段的黑盒困境
在缺乏可观测性的系统中,修改代码就像在黑暗中行走。开发者只能依靠本地调试和想象力来推测代码在生产环境中的表现,发布后也只能通过用户反馈来判断是否成功。
一个典型场景:某团队优化了数据库查询逻辑,本地测试性能提升明显,但上线后系统响应时间反而变慢。问题在于他们的优化基于理想数据分布,而生产环境的数据存在严重倾斜。由于缺乏实时监控指标,团队在用户抱怨一个小时后才意识到问题,又花了两个小时才定位到根因。
“敢改”阶段的全链路透明
真正敢改的系统,会在每一个关键节点埋入可观测的锚点。不仅记录错误日志,更要记录正常流量的关键指标——请求耗时分布、数据库慢查询、缓存命中率、第三方服务调用延迟等。
更进一步的做法是建立对比实验平台。某互联网公司在重构推荐算法时,采用了影子流量机制:新旧算法同时运行,但只有旧算法的结果返回给用户。通过对比两者的性能指标、资源消耗和推荐质量,团队能够在真实流量下验证改动的效果,发现问题时也能秒级回滚。
可观测性带来的不仅是问题的快速定位,更是改动的即时验证。当你能在发布后5分钟内看到所有核心指标的变化曲线,自然就敢于尝试更大胆的优化。
三、架构解耦:从“牵一发动全身”到“局部可控”
“能用”阶段的耦合泥潭
许多系统在初期为了快速上线,采用了高度耦合的架构。各个模块之间直接调用,数据库表之间存在复杂的外键关系,业务逻辑散落在多个层次中。这种设计在功能稳定时没有问题,但一旦需要改动,就会陷入困境。
我观察过一个CRM系统,客户信息模块、订单模块和财务模块紧密耦合。当团队尝试升级客户信息的字段结构时,发现需要同步修改另外两个模块的十几处代码,以及数据库的多张表。最终这个“简单”的需求花费了三周时间,期间还引发了两次线上问题。团队从此对架构调整心存恐惧。
“敢改”阶段的边界清晰
相比之下,架构解耦良好的系统会通过明确的接口契约和领域边界来隔离变化的影响范围。每个模块对外暴露稳定的API,内部实现可以自由演进,只要不破坏契约即可。
某电商平台在从单体架构向微服务演进时,采用了渐进式改造策略。他们首先识别出系统中变化频率最高的模块,比如促销规则引擎,将其抽取为独立服务。关键在于他们建立了防腐层:老系统继续通过原有方式调用,但底层实现已经切换到新服务。这种方式让团队能够在不影响整体稳定性的前提下,逐步完成架构升级。
架构解耦的本质是将复杂度封装在模块内部,将稳定性暴露在接口层面。当改动的影响范围可控,工程师自然就敢于动手。
四、知识传承:从“个人经验”到“团队能力”
“能用”阶段的依赖困局
在知识传承不足的团队中,系统的稳定运行往往依赖于少数核心开发者。他们记得每一个历史包袱的来龙去脉,知道哪些代码不能碰,哪些配置有特殊用途。这种“人肉文档”看似高效,实则脆弱。
一个真实的案例:某金融团队的核心清算系统,只有两个工程师完全理解其运作机制。当其中一人离职时,团队陷入恐慌。新人花了三个月才敢进行小幅度修改,期间积压了大量优化需求。系统虽然“能用”,但团队的迭代能力被严重削弱。
“敢改”阶段的能力沉淀
真正敢改的团队会将知识系统化地沉淀为可执行的代码、文档和实践。这不是简单的写文档,而是建立一套让新人也能快速建立信心的机制。
某互联网公司的做法值得借鉴:
- 架构决策记录(ADR):每一个重要的技术决策都会记录背景、选项、决策和后果,让后来者理解为什么代码会这样写
- 回归测试即文档:测试用例本身就是最好的业务场景说明,新人通过阅读测试就能理解系统行为
- 定期轮岗:要求高级工程师定期带新人进行代码改造,在实践中传递经验和信心
当团队的知识不再依赖个人记忆,而是沉淀为可传承的资产,每个合格的工程师都能放心地进行改造。这才是真正的工程能力。
结语
从“能用”到“敢改”,不是技术栈的升级,而是工程能力的跃迁。这个过程没有捷径,需要团队在可测试性、可观测性、架构解耦和知识传承等多个维度持续投入。
几点建议供参考:
- 建立最小可信改造单元:识别系统中哪些模块已经具备“敢改”的条件,从这里开始积累经验和信心
- 投资工程基础设施:自动化测试、监控告警、灰度发布等基础能力的投入,短期看是成本,长期看是团队迭代速度的保障
- 将事故转化为能力:每一次线上问题都是建立防护网的机会,补充测试、完善监控、优化架构,让同样的问题不再发生
- 培养改造文化:鼓励工程师进行小步快跑的重构,在实践中积累信心,而不是等到技术债务不可收拾时才着手处理
最终,我们要明白:系统的价值不在于此刻能否运行,而在于未来能否持续演进。当团队从“祈祷代码别出问题”转变为“相信改动在掌控之中”,这才是真正的工程成熟度。
这条路很长,但每一次对工程能力的投资,都是在为团队的未来争取更大的可能性。敢改,才敢赢。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号