【Python技术】提取东方财富最新资讯通过大模型分析板块和个股机会

【Python技术】提取东方财富最新资讯通过大模型分析板块和个股机会

子晓聊技术
发布于 2026-04-23 14:02:58
发布于 2026-04-23 14:02:58
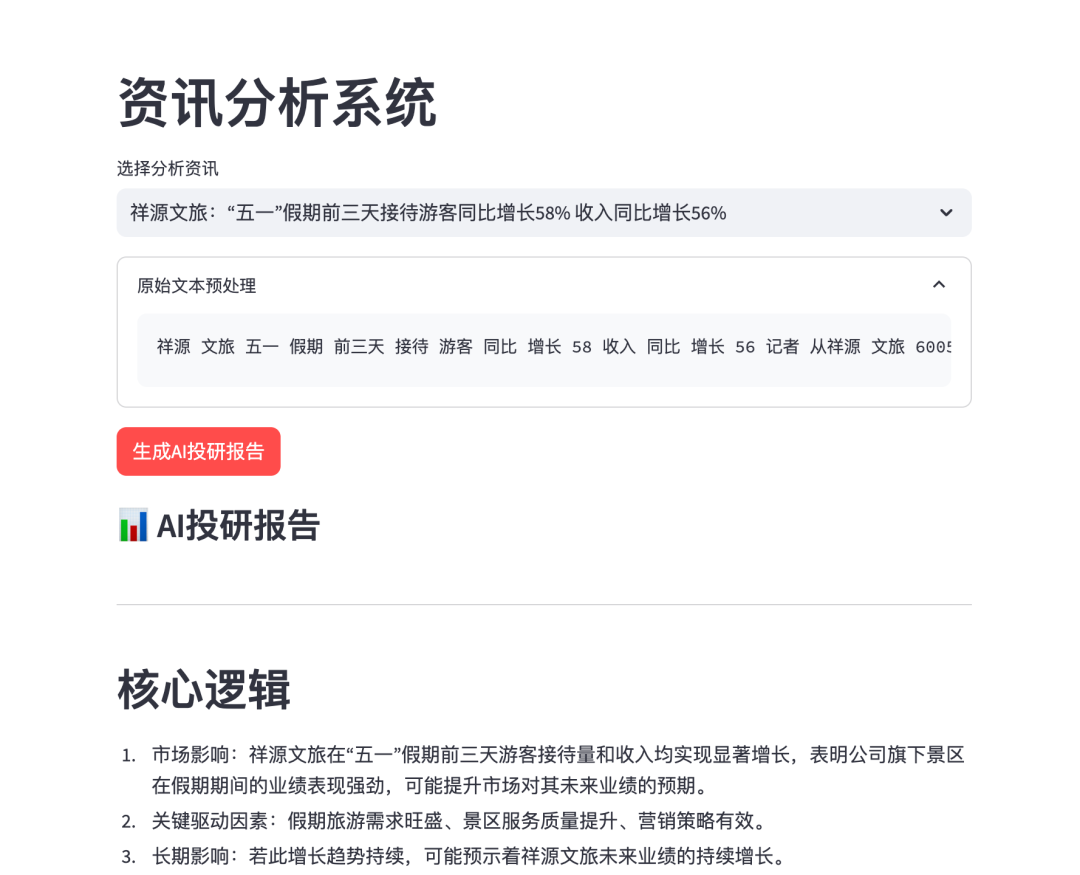

之前写了一篇关于提取新闻联播分析投资机会的文章, 五一休假期间,有同学问有没有其他的最新资讯源。 其实信息源很多, 我们这里以东方财富举例, 演示下 如何 获取最新资讯,分析资讯对应的板块个股机会。
这里还是以Streamlit框架构建,整合资讯数据获取、NLP预处理、大模型推理几个模块,形成简单的AI投研分析闭环。
1.1 数据获取层(Data Layer)
# 数据源配置
news_df = ak.stock_info_global_em()[['标题', '摘要', '发布时间']].dropna().head(20)
- AKShare数据引擎:通过金融数据接口获取全球实时资讯,支持股票、基金、期货等多维度数据抓取
- 数据清洗:采用智能过滤机制剔除无效数据,保留关键字段(标题/摘要/时间)
- 动态更新:内置定时任务模块实现分钟级数据刷新,确保信息时效性
1.2 NLP预处理层
defpreprocess_text(text):
# 正则去除非中文字符
text = re.sub(r'[^\w\s]', '', text)
# 结巴分词+停用词过滤
words = [word for word in jieba.cut(text)
if word notin STOP_WORDS andlen(word) > 1]
return" ".join(words)
- 文本清洗:通过正则表达式去除特殊符号和无效字符
- 智能分词:结巴分词引擎配合金融专业词典,精准切分行业术语
- 特征优化:定制化停用词表过滤冗余信息,保留核心语义要素
1.3 大模型推理层
# LangChain配置
prompt_template = """
作为专业金融分析师,请基于以下资讯摘要给出投资建议...
"""
chain = LLMChain(llm=llm, prompt=prompt)
- 大模型集成:对接前沿的大语言模型,支持金融文本深度理解
- 提示工程:采用结构化模板引导模型输出标准化分析报告
- 参数调优:平衡模型创造性与稳定性,确保专业建议的可靠性
1.4 交互展示层
# Streamlit界面组件
st.title("资讯分析系统")
selected_news = st.selectbox("选择分析资讯", news_df['标题'])
st.markdown(analysis.split("### 投资建议")[1])
- 可视化界面:构建交互式分析面板,支持多维度数据探索
- 动态渲染:实现分析报告的智能分段展示与高亮标记
- 响应式设计:自适应PC/移动端显示,优化用户体验
最后附上源代码,需要的自取。 备注:如果发现格式有多余的特殊字符,用普通浏览器打开复制应该没问题。
备注:程序中用的智谱api,你完全可以换成其他的大模型, 用它演示主要是由于免费。 key可以直接到https://open.bigmodel.cn/ 申请。
import akshare as ak
import streamlit as st
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain_openai import ChatOpenAI
import re
import jieba
# 智谱API配置
zhipu_api_key = "你的key"
llm = ChatOpenAI(
temperature=0.95,
model="glm-4-flash",
openai_api_key=zhipu_api_key,
openai_api_base="https://open.bigmodel.cn/api/paas/v4/",
max_tokens=2048
)
# 文本预处理配置
STOP_WORDS = {
'的', '了', '在', '是', '我', '有', '和', '就', '不', '人', '都', '而', '及', '可以',
'这', '一个', '为', '之', '与', '等', '也', '会', '要', '于', '中', '对', '并', '其',
'或', '后', '但', '被', '让', '说', '去', '又', '已', '向', '使', '该', '将', '到',
'应', '与', '了', '这', '我们', '他们', '自己', '这个', '这些', '这样', '因为', '所以'
}
# LangChain提示模板
prompt_template = """
作为专业金融分析师,请基于以下资讯摘要给出投资建议:
资讯标题:{news_title}
资讯摘要:{news_summary}
请按以下结构化输出:
### 核心逻辑
1. 市场影响:用不超过3句话说明资讯的核心影响
2. 关键驱动因素:列出3-5个关键驱动因素
### 板块机会
按受益程度列出前三大关联板块,每个板块包含:
- 板块名称
- 受益逻辑
- 受益强度评估(高/中/低)
### 投资建议
以表格形式推荐5只关联度最高的个股:
| 股票代码 | 股票名称 | 关联逻辑 | 操作建议 |
|---------|---------|--------|--------|
"""
prompt = PromptTemplate(
input_variables=["news_title", "news_summary"],
template=prompt_template
)
chain = LLMChain(llm=llm, prompt=prompt)
# 文本处理函数
def preprocess_text(text):
"""资讯文本预处理"""
text = re.sub(r'[^\w\s]', '', text)
words = [word for word in jieba.cut(text)
if word not in STOP_WORDS and len(word) > 1]
return " ".join(words)
# Streamlit界面
def app():
# 主界面
st.title("资讯分析系统")
try:
# 获取实时资讯
news_df = ak.stock_info_global_em()[['标题', '摘要', '发布时间']].dropna().head(20)
# 资讯选择器
selected_news = st.selectbox("选择分析资讯", news_df['标题'])
news_detail = news_df[news_df['标题'] == selected_news].iloc[0]
# 文本预处理
with st.expander("原始文本预处理", expanded=False):
cleaned_text = preprocess_text(news_detail['摘要'])
st.code(cleaned_text[:500] + "...", language='text')
# 生成分析报告
if st.button("生成AI投研报告", type="primary"):
with st.spinner('AI分析中...'):
analysis = chain.run({
"news_title": selected_news,
"news_summary": cleaned_text[:1000] # 摘要截取优化
})
# 结构化展示
st.subheader("📊 AI投研报告")
st.markdown("---")
try:
# 核心逻辑解析
core_logic = analysis.split("### 核心逻辑")[1].split("### 板块机会")[0]
st.markdown(f"## 核心逻辑\n{core_logic}")
# 板块机会展示
sectors = analysis.split("### 板块机会")[1].split("### 投资建议")[0]
st.markdown(f"## 板块机会\n{sectors}")
# 投资建议表格
st.markdown("## 投资建议")
st.markdown(analysis.split("### 投资建议")[1])
except Exception as e:
st.warning("结构解析异常,展示原始输出:")
st.code(analysis, language='markdown')
except Exception as e:
st.error(f"系统异常:{str(e)}")
if __name__ == "__main__":
app()本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号