双基准校准HP3458A八位半万用表(YUNSWJ 推导版)


今天这篇文章一台仪器的前导篇:

先卖个关子
先卖个关子
其实这个东西,在问题的图文里面已经小有端倪了:

就是在 7275 头上的
就是在 7275 头上的
小小的身材大大的能量,不过这次主角还不是它,也可以先看看内部:

之后的文章有详细的分析
之后的文章有详细的分析
关于校准
作者说使用了双 10 校准系统:
那知识点来了,什么是双 10?那就不得不追溯到:

这个文章的内容了
这个文章的内容了

具体是这篇
具体是这篇
在 09 年lymex 大佬就做了解读(我是后人了):
https://bbs.38hot.net/forum.php?mod=viewthread&tid=67
HP3458A最早的产品概念,是研究出一种手段,仅仅利用两个外部基准对其测试进行校准。这对传统方式设计的DMM是不可能的,因为都是逐档对满度增益和偏移校准的。

不知道这些大佬还在世吗?
不知道这些大佬还在世吗?
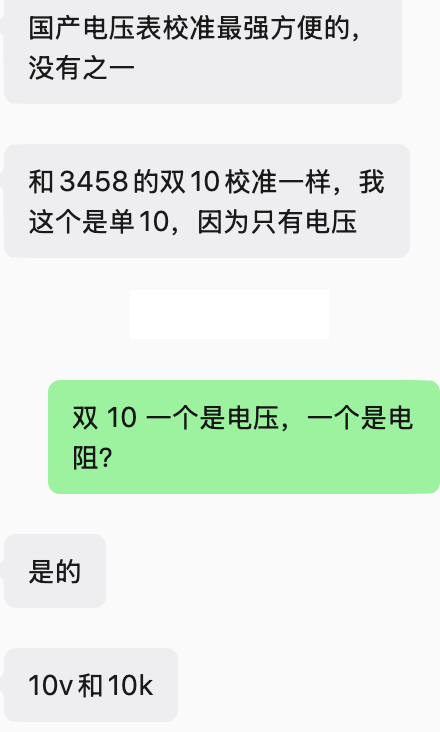
输入-输出曲线
输入-输出曲线
这个曲线就是输入-输出曲线,理想是一个通过原点、比例为1的直线(校准后);校准前曲线一方面有零点偏移误差,更主要的是有增益误差,即直线的角度不是45度。
自校准一般可以修正零点偏移误差,但增益误差必须通过外部校准来修正。很多万用表例如34401A不仅可以自己校准零点(不需要外部基准),而且可以在测量时通过短路方式先读数,然后再减去的方法,随时修正零点;另外,高位表尤其是这里的HP3458A,其ADC的线性度非常高,因此这两个“曲线”都是直线,不用考虑非线性校准。但还有一些万用表,ADC的线性不太好,表现在图中的线是弯曲的,这就要进行线性校准,使得校准更加复杂了。
校准原理
校准是一个利用外部基准输入,分别手动的或电子的调整每一档的增益和偏移,让误差最小,见图。增益和偏移值一般是通过精密比例转移测试一组尽可能少的追溯到国家标准(NIST)的工作基准来进行的。直流电压通常是来自1.018V的饱和电化学电池,也叫做惠斯顿标准电池。其输出被分压,或者用某种方式进行比例放大,来产生其它可追溯的电压值。
例如电池可以分压10.18倍来产生0.1V;总的来讲,比例转移过程对于每个校准值都是不同的,因此就容易引入随机误差和系统误差,并随校准过程不被注意的蔓延传播。这种校准不确定度或校验不确定度有时将产生“地板”误差,甚至比仪器本身的不确定度还要大。
双基准源校准的目标就是减少地板误差,并提供一个独立的方法来改善校准的不确定度。HP3458A使用高线性度的模数转换器(ADC)来测试其分压和外部基准之间的比例。这ADC承担了精密比例转移器的角色。
双基准校准 HP3458A 八位半万用表
文章核心思想是:不用传统那种每一档都单独拿外部标准去校增益/零点,而是只用两个外部标准,把整台表内部的电压、电阻、电流各量程都串起来校准。
文章开头先说了一个很关键的问题:传统 DMM 校准,往往是每个量程分别校偏移、校增益。例如 10 V 档、1 V 档、100 mV 档,各有各的增益误差和零点误差,需要靠外部标准一点点转移过去。这个过程一旦依赖外部分压、比例扩展、人工切换,就容易引入额外误差,形成所谓的“地板误差”。
HP3458A 的思路不一样。它利用自身 极高线性的 ADC 充当“内部比例比较器”,于是外部不再需要给每个量程提供大量标准值,而只需要很少几个外部基准,就能把整机的校准链建立起来。文中明确说,3458A 的目标是只靠两个外部基准完成校准:一个电压基准,一个电阻基准。
你好!来自1987年的ADI积分ADC模组-AD1175K(研究到自己都懵逼版)
把它理解成:外部标准只负责“定锚点”,内部高线性 ADC 负责“高精度比例转移”,内部基准和内部电阻网络负责“把锚点扩散到全量程体系”;这就是“双基准校准”的本质。
误差
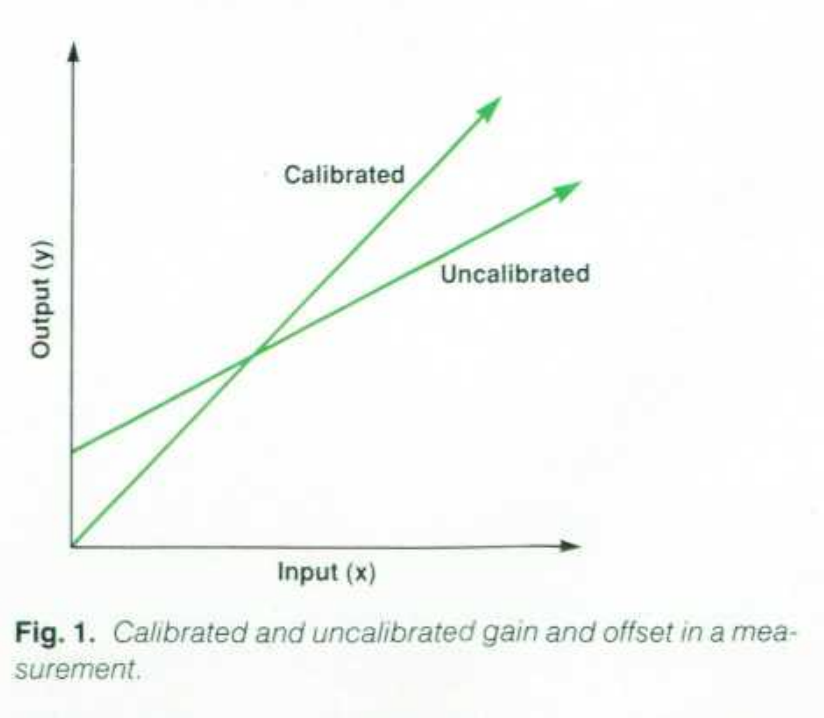
文章把比例测量误差分成两类:
微分误差 D
它是一个固定的、与输入大小无关的误差项;在直观上,可以把它看成偏移类误差、固定附加量、零点残余项。
积分误差 I
它是随输入变化的误差项,通常体现为比例误差、增益误差、线性偏离;文中给出一个以“满量程百分比”为基准的表达:
意思是:总误差 = 与输入成比例变化的项 + 一个固定项。
这其实非常像高精度仪器常见的规格写法:% of reading+% of range或者写成:读数项 + 量程项;只是文中换了一种更“误差传递”的抽象语言来讲。

为什么小读数更难测准
文中接着给了第二个表达式,它把误差改成“相对于读数本身”来表示:
这个式子非常重要,意思是说与读数成比例的那部分误差 ,无论测大测小,占比都差不多;但固定误差项 ,当读数 很小时,会被 放大
所以当我们在 10 V 档测 10 V,固定 1 mV 误差只占很小比例;但如果还在 10 V 档测 0.1 V,这 1 mV 就成了很大的相对误差;文章专门举了类似例子说明,强调量程选得过大时,小信号测量的相对误差会迅速恶化。
这和我平时做高分辨率采集时的经验完全一致:同样的偏置、热电势、开关残余、漏电流误差;对 10 V 信号可能几乎看不见;对 1 mV 或 100 µV 信号就是灾难。
固定误差项永远优先伤害小信号
HP3458A为什么能玩这个“内部比例传递”?
在于文章反复强调的一点:HP3458A 的 ADC 线性度极高,高到它不只是个“采样器”,还是一个精密比例转移器;普通 DMM 的 ADC,只能说“绝对测量还不错”;但 HP3458A 的 ADC 足够线性,于是它可以用来比较:外部 10 V 标准 与 内部 7 V 基准 的比例,内部 7 V 与 内部分压后的 1 V 的比例,已知电流流经内部标准电阻后得到的电压比例,不同欧姆档电流源之间的比例。
也就是说,它不一定每次都直接知道“绝对值”,但它能极其可靠地知道两个量之间的比值; 这就是“把 ADC 当成比例桥”的思想。
文中对 HP3458A 线性度的要求意味着什么?
文章写到,3458A 的设计目标,是让其内部比例传递误差不大于当时最好的商品分压器;并给出了一个很关键的量级:10:1 比例测试的总体线性要求大约是 0.5 ppm 输出值或者 0.05 ppm 输入值
这是什么意思?
假设用 10 V 档去做 10:1 比例转移,相当于把 10 V 的追溯性转到 1 V;如果内部比例误差控制在 0.05 ppm of input,那对 10 V 输入来说就是 0.5 µV 等级。
这已经是一个极其夸张的水平了;换句话说,3458A 之所以能用“少量外部基准 + 大量内部转移”而不崩,就是因为它的内部比例精度已经接近甚至优于很多外部转移器件。
一组线性测试
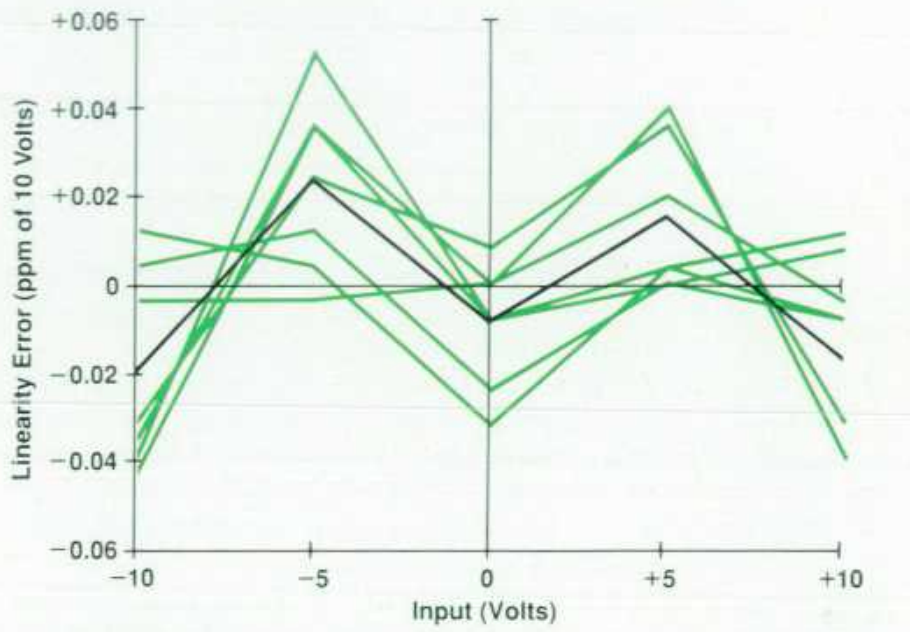
文章引用了用 JJA(超导约瑟夫森电压基准)对 HP3458A 做线性测试的结果。这个部分是全文最硬核的证据链。
积分线性
在 -10 V 到 +10 V 范围内,典型积分误差不超过 0.1 ppm 满量程;说明在整个输入输出关系极接近理想直线;即使跨越全量程,弯曲程度仍然极小,所以内部比例转移不会因“大范围非线性”而失控;对于 10 V 量程,0.1 ppm 对应 1 µV。
微分线性
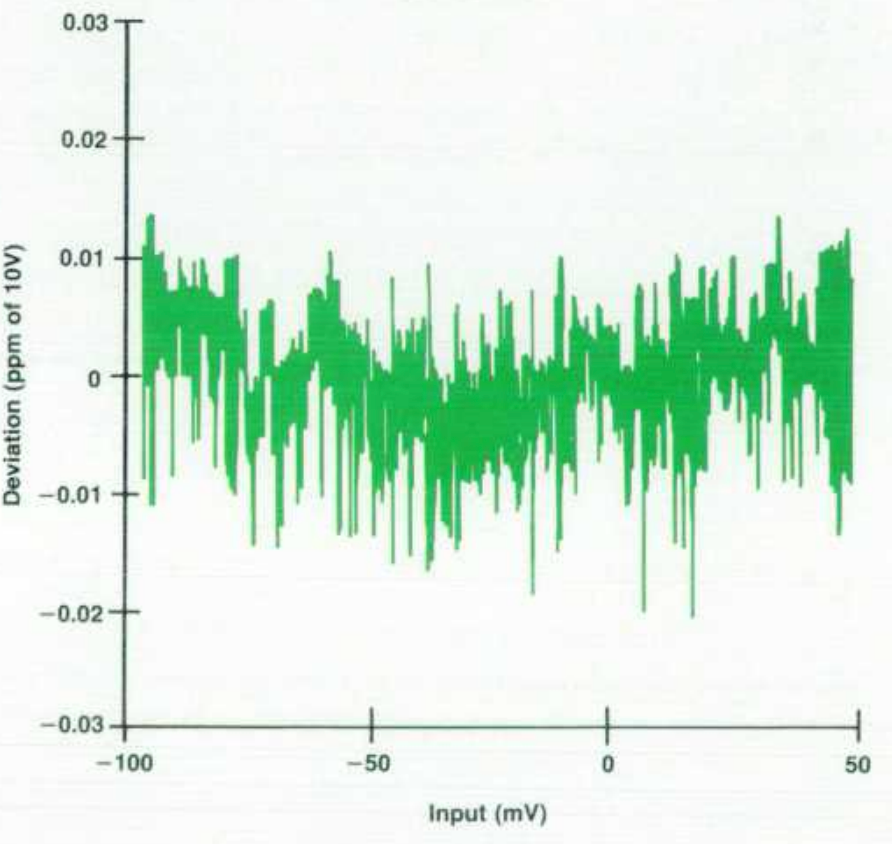
文中给出的典型微分线性在 0.02 ppm 以内,而且这是在零附近做的局部高分辨测试;小区间内的“局部比例斜率”也很稳定,ADC 不只是整体直,而且局部也很均匀
这个对于比例转移非常关键;因为如果局部微分线性差,即使整体拟合成一条直线,也会导致小比例比较时出现不可预测的细小误差。
10:1 内部转移误差

文章说 10:1 转移可以做到典型 0.01 ppm 输入值 或 0.1 ppm 输出值;指标的 3σ 转移值大于 0.3 ppm。;因为内部 10:1 比例转移足够准,所以 10 V 可以可靠地“生”出 1 V 的追溯性。
偏移误差是怎么被处理掉的?
文章后面进入偏移误差处理,给了一个简化直流测量电路图;它说明 HP3458A 在每次测量前,利用开关先采一个“零参考”,再采真实输入,然后相减。文章明确把这个过程称为 Autozero(自稳零)。
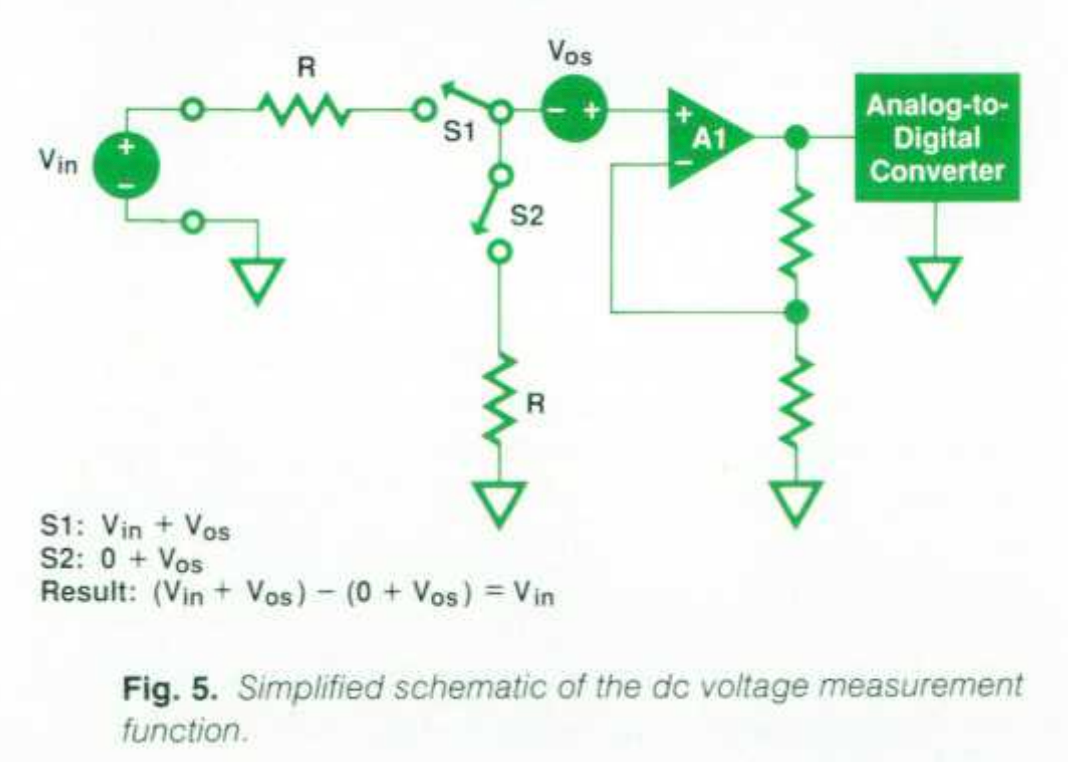
这个结构的本质是:先测内部零点路径;这一路包含了大量共同路径误差,比如运放失调+某些漏电流造成的压降+开关残余+后级 ADC 偏移。再测真实输入,两次结果相减,公共偏移项被抵消
所以 Autozero 并不是“让系统没有偏移”,而是:通过时间复用地测量偏移,再把它减掉。
文中也指出,它的代价是测量时间加倍;但对 HP3458A 这种本来就非常快的表来说,这个代价可以接受。并且如果追求更高速度,自稳零也可以关闭。
偏移误差为什么还不能完全靠 Autozero 解决?
文章说,自稳零能消掉大部分内部共同路径偏移,但连接部分、外部引线、热电势、非公共路径误差还需要额外处理。它提到可以通过外部短路器测一个残余偏移,并把它作为各量程校准常数保存下来。最终相当于对每个量程都保留一个 项,在输出中减掉。
这非常像仪器误差模型:
其中: 是增益校准, 是偏移校准
Autozero 更像是在实时消减一部分动态偏移;而存储的 offset calibration 更像是在校准层面消除量程固有残差。
真正厉害的地方:增益误差的“内部闭环传递”
文章最精彩的是“直流校准”这一段。它把 HP3458A 的电压校准链完整讲清楚了。
第一步:建立内部 7 V 基准的追溯性
外部拿来一个 10 V 标准,仪器依次测:外部 10 V+内部 7 V;通过 ADC 的高线性测出二者比例,得到“内部 7 V 实际值相对于外部 10 V 的关系”,并存到校准内存。
注意文中强调:这一步不要求 10 V 量程绝对增益已经完全准确,因为这里测的是比例,很多共同增益项会消掉,只要求测量期间稳定。
这一点特别妙,它不是“先把测量系统完全校准好,再去校基准”;而是先用高线性比例测量,把内部基准挂到外部标准上。
第二步:用内部 7 V 去校 10 V 档增益
有了“7 V 实际值”,再用 10 V 档测这个内部 7 V,反推出 10 V 档的增益校正系数。这个系数也存储起来;于是:外部 10 V 标准只出现过一次,之后 10 V 档的校准就能靠内部 7 V 重新建立
第三步:从 7 V 派生 1 V 档
文中说,对 1 V 增益的调整,是把内部可追溯的 7 V 分压到名义 1 V,再用已经校准好的 10 V 档去测它,大约是 1/10 满量程。这个测得的 1 V 值,再反过来校 1 V 档增益。
这里最关键的是文章的结论:
这个名义 1 V 是否绝对精确、长期是否稳定,并不重要;重要的是它在短暂的两次转移测量期间保持稳定。
这个思想很好:不是每个中间节点都必须是“完美标准”,只要它在传递过程中短时稳定,且比值测量足够准,它就可以作为“转移标准”。
其余电压量程也是同理;其它直流电压档都依赖内部 7 V + 内部比例转移来建立,所以所有电压档的“祖先”其实都是那一次外部 10 V 标准对内部 7 V 的追溯绑定。
电阻档和电流档是怎么串起来的?
这部分同样非常漂亮;文章说,欧姆和直流电流校准的外部标准是 10 kΩ 电阻标准,内部则有一个 40 kΩ 参考电阻。
先确立内部 40 kΩ 的追溯性
通过外部 10 kΩ 标准,把内部 40 kΩ 的实际值建立起来,并存储。
再确立欧姆测量电流
欧姆测量本质上是:
既然电压体系已经通过前面的电压校准建立了追溯性,现在只要再把“测欧姆用的电流源”校准出来,整个欧姆档就成立了。
文章举例:让 10 kΩ 档的名义 100 µA 电流流过已追溯的内部 40 kΩ 电阻,测出其电压,于是
这样这个 100 µA 电流就被精确确定并存储;然后这个已知电流再加到内部 5.2 kΩ 电阻上,通过测电压来得到其阻值;而这个电阻又是某个电流档的分流电阻,于是又能确定另一个电流档。
如此一级一级传递下去,直到所有电流源和分流电阻都被定出来。
文章最后下结论:所有直流电压、直流电流、电阻的增益误差,都可以只相对于外部 10 V 和 10 kΩ 两个基准完成调整。
苛刻的工程前提
这套方法成立,有几个极苛刻前提:ADC 必须极线性,如果内部 ADC 比例误差不够小,那做的不是“精度转移”,而是在传播误差;开关网络必须极稳定,每一次内部切换都会带来:热电势+漏电+接触电阻变化+电荷注入+介质吸收残余,这些在 8.5 位系统里全都不是小问题。
内部中间节点要短时极稳定;文章反复强调,中间产生的名义 1 V 未必长期完美,但必须在转移期间稳定,要求:电阻网络低温漂+放大器低漂移+参考低噪声低热滞+板级热设计非常讲究等。反正就是挺难的,这个算法也得写对,不然也不好传递在后面。
小结
可以看的出来“绝对准确”不如“比例准确”;很多时候不需要每一级都直接对国家标准;现实的方法是:抓住一两个高质量外部标准,让系统内部建立高精度比例关系,用短期稳定去完成转移。(那我之前这个对比法也不错)
在 DC 低频系统内;高线性比低噪声更稀缺,很多人只关注噪声,但这篇文章让我们看到:在“内部比例转移”系统里,线性度是基础设施, 没有线性,所有比例推导都站不住。
完美的工程实践需要优雅的数学推导
现在要建立一个统一的数学误差传递模型,目标是把这篇文章里的几件事统一起来:微分误差 +积分误差 +10:1 内部比例转移误差+自校准 / 双基准校准+中间节点的短期稳定度+测量噪声与重复性
先把一切都抽象成:
:真实输入量
:仪器输出读数
:整套测量链
但在高精度系统里, 不能只写成一个黑箱函数,因为它内部包含:偏移类误差,增益类误差,比例转移误差,中间参考的漂移,噪声,每次测量时的随机散布,所以我把它拆开。
单一量程的基本测量模型
对某一个量程 ,最基本可以写成:
:该量程的总增益
:该量程的总偏移
:噪声与时间相关随机项,这是最原始的表达。
如果进一步把增益写成理想值加误差:
则有:
这已经能对应常见的:读数误差项+固定误差项
对应文中的 和
文章里把误差拆成:微分误差 与输入无关的固定项+积分误差 与输入成比例变化的项
所以如果定义误差
那么:
于是可以直接对应成:
也就是说;文中的积分误差,本质上就是增益/比例误差,文中的微分误差,本质上就是固定附加误差/偏移误差
如果按“相对于满量程 ”来归一化,则:
这就对应文中的“以量程百分比表示”的误差图。
以读数为基准的误差表达
文章又给了另一种表达:以读数/输出值作为基准时,小读数下固定误差项会被放大;这在我们的模型里非常容易得到:
相对读数误差为
这就是高精度仪器规格常写成:
因为:
对应
对应
而当 时,
所以越接近零,固定误差越主导。
把 Autozero 放进模型
文章说明了 Autozero 的本质:先测零点路径,再测输入路径,相减以去掉共同偏移;设内部共有偏移项为 ,非共路径偏移项为 ,那么未经 AZ 的单次测量:
零点测量:
Autozero 后输出:
代入得:
所以可以看到:共同偏移项 被消掉,非共同路径偏移 还在;噪声会增加,因为是两次测量差分;如果两次噪声独立同分布,方差相同为 ,则 AZ 后噪声标准差变成:
这和直觉一致:AZ 提升零点准确性,但会牺牲一点速度和噪声。
把“校准”写成参数估计问题
对每个量程 ,校准的目标是得到两个参数:
让修正后输出为:
或者若增益误差很小,也可以写成近似一阶修正:
HP3458A 的特别之处在于它不是每个量程都直接拿外部标准去估计 ,而是先建立少数内部锚点,再通过内部比例转移去推导所有量程。
建立“比例转移”的统一数学表达
假设有两个量:源量 和目标量 ,仪器通过内部 ADC 测得它们的比例:
:比例转移的系统误差(线性误差、切换误差、路径增益残差)
:比例转移时的随机噪声
如果 已知,则 的估计值为:
因此:
即:
所以比例转移误差自然分成两部分:乘性系统误差+随机噪声项。
多级比例转移链的误差传播
假设一个目标量 不是直接由外部标准得到,而是经过多级内部转移:
每一级:
其中:
是理想比例,比如:7/10,1/7,10:1,4:1,电阻比,电流比
那么:
若误差很小,取一阶近似:
这条式子非常重要;表明了初始外部标准的不确定度会传到最终量,但每一级比例转移的系统误差近似线性叠加,每一级比例转移的随机项也会累加;级数越多,链越长,最终不确定度越大
所以设计高精度内部校准网络时,必须让:链尽量短,每一级转移尽量高精度,中间节点短时稳定,开关路径热 EMF 尽量小
把 HP3458A 的电压校准链写成方程
文章中电压链路可以抽象成:
外部 10V 标准确立内部 7V
设外部标准为 ,其不确定度为 ;通过 ADC 测得内部 7V 与外部 10V 的比例:
于是内部 7V 的估计值:
相对误差:
用内部 7V 去校 10V 档增益
如果 10V 档原始测量为:
AZ/偏移修正后,可近似用:
于是:
也就是说,10V 档增益校准的不确定度来自:测 7V 时的读数噪声/残余误差,以及内部 7V 自身追溯误差
从 7V 分压得到名义 1V,再校 1V 档
设内部分压比理想为 ,真实有误差:
则生成的名义 1V:
但这不是最终可信值,因为文章强调这个中间 1V 本身不必长期绝对准确,只要短时稳定,并且可以被已校准的 10V 档测出来。
因此真正被用来校准 1V 档的是:
它相当于:
再用 去定 1V 档增益 。
于是 1V 档最终不确定度包括:外部 10V 不确定度+7V 追溯误差+内部分压比误差+10V 档测这个 1V 节点时的测量误差+1V 档自身校准时的测量误差。
把“短期稳定度”显式放进去
这是文章非常强调、中间生成的名义 1V 不一定要长期完美,只要在两次转移测试期间足够稳定;所以对任意中间节点 ,我们要写成:
:长期漂移、温漂、老化
:在校准窗口内的短时波动
如果某个中间节点只在时间窗 内用于两次转移,那么真正影响这次转移的不是长期漂移,而是:
因此对于“转移标准”来说,更关键的是短期 Allan 偏差或者短时 RMS 波动,而不是一年漂移。
所以校准链中的中间节点,可以允许长期不完美,但必须在校准窗口内稳定,因而需要关注热时常、开关自热、参考恢复时间、介质吸收、机械应力松弛。
噪声如何叠加到比例转移里
假设一次比例测量由两次读数构成:
测 :得到
测 :得到
比例估计为:
设
则一阶展开:
所以比例测量的相对随机不确定度为:
如果两次读数还带有相关漂移项,比如公共增益抖动 ,那么它们会部分抵消,这也是比例法常常优于绝对法的原因。
电压 / 电阻 / 电流三条链的统一表达
文章说明了 HP3458A 最终是把所有 DCV、Ω、DCI 都追溯到两个外部标准:10V 和 10kΩ。
所以可以写成三条链:
电压链
各内部电压节点各电压量程增益
电阻链
已知电流内部其它参考电阻各欧姆量程
电流链
追溯追溯各电流源分流器各电流量程
统一公式都可写成:
其中 可以是 、、。
一个总的不确定度预算公式
如果最终某量程 的输出经校准后为 ,那么总相对不确定度可近似写成平方和形式:
:外部基准不确定度
:内部比例转移误差
:该量程求增益常数时的拟合误差
:偏移剩余项
:中间节点在转移窗口内的不稳定
:读数随机噪声
若按绝对误差写:
其中
这就是“读数项 + 固定项”的总版。
特别写出 10:1 转移的误差形式
我特别关心这个,单独抽出来;假设用 10V 档测 1V 节点,形成一个 10:1 转移。文章里给出的思路是:若积分误差和微分误差分别记为 ,则 10:1 转移误差会放大固定项,文中还给了类似 的估计思路。
把它写成统一形式,若 10V 档测量模型是:
对于 ,但量程是 10V,若把误差换算到“相对于 1V 读数”,则:
若固定项 是按 10V 满量程定义的 ppm,则它相对于 1V 读数就会乘上 10。
因此:
这正是文中那种表达背后的本质。所以:大比例缩小转移时,固定误差项会被放大,这就是为什么 10:1 转移对偏移、热电势、零点残余极其敏感,也是为什么 HP3458A 必须把微分误差压得极低。
传递的流程
层 1:原始测量层
层 2:AZ 层
层 3:内部参考层定义主参考 +主参考电阻
层 4:比例转移层
层 5:校准参数层
每个量程存:offset 常数 和 gain 常数
层 6:不确定度预算层
这样就可以把任何一个量程的精度追溯到:外部标准+内部转移链,以及当前温度与时间状态和本次噪声条件;如果把所有东西合成一个式子,一个量程 的最终修正输出可以写成:
:当前输入读数
:Autozero 零点读数
:该量程残余偏移校准常数
:该量程增益校准常数
而 本身不是独立获得的,而是:
也就是由整个内部比例追溯网络计算出来。
最终总误差可写成:
这已经几乎就是一个完整的“高精度量测系统总误差方程”了。
总结
我首先把乐老师的文章重新写了一遍,给出了工程的难点,也给出了(用两个外部标准建立两个内部追溯锚点,再借助极高线性的 ADC,把电压、电阻、电流各量程通过内部比例转移全部校准起来);接着使用数学建模的工具把所有误差分成乘性误差链和加性误差链;外部双基准只负责定义起点,内部高线性 ADC 负责比例传递,短期稳定度决定中间节点能不能当转移标准,最终每个量程都落到一个“增益常数 + 偏移常数 + 噪声项”的校正模型上。
压缩一点,就是:外部标准少,内部传递强,核心靠线性。(另外推荐使用电脑阅读,公式对手机不友好)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号