ICML 2026 | UniMedVL:统一医学多模态理解和生成

ICML 2026 | UniMedVL:统一医学多模态理解和生成

Amusi
发布于 2026-06-02 14:01:40
发布于 2026-06-02 14:01:40

论文标题:UniMedVL: Unifying Medical Multimodal Understanding and Generation through Observation-Knowledge-Analysis arXiv:https://arxiv.org/abs/2510.15710 代码与模型:https://github.com/uni-medical/UniMedVL 数据集:https://huggingface.co/datasets/General-Medical-AI/UniMedVL-5M
一、问题:医学 AI 为什么是"割裂"的?
临床诊断本质上是一个多模态进、多模态出的过程。一位放射科医生看疑似肺部病变时,会综合胸片、既往 CT、病史,然后产出多种互补结果:描述发现的文字报告、标注病灶位置的可视化、用于手术规划的对比影像。
但现有的医学 AI 系统把这条统一的链路拆开了:理解模型能看图回答问题、写报告,却画不出图;生成模型能合成影像,却给不出文字解释。作者把这种割裂归因于三个层面的瓶颈:
- 数据:医学数据集大多是单模态的,缺少天然的跨模态配对;
- 学习范式:现有医学多模态模型基本还是"继续预训练 + 指令微调"的两段式,缺乏能捕捉深层跨模态关系的渐进式学习设计;
- 能力收敛:通用领域已经走向统一架构,但医学领域仍缺真正的统一模型。即便是 HealthGPT,也需要按任务类型加载不同的模型权重,逼着医生手动切换 checkpoint。
于是核心问题变成:图像理解和图像生成能否共享同一个医学模型并互相增益,还是联合训练注定会牺牲某一边?
二、核心思路:从临床诊断抽象出的 OKA 范式
作者把"统一医学多模态建模"重新表述为一个三层对齐问题,对应上面三个瓶颈,称为观察–知识–分析(Observation-Knowledge-Analysis, OKA)范式:
- 观察层(Observation)——解决数据瓶颈。把分散的单模态医学数据重构成对齐的"多模态输入-输出对",构建 UniMedVL-5M:超过 560 万条样本,覆盖 8 种主要医学成像模态,同时支持理解、生成、交错(interleaved)任务。
- 知识层(Knowledge)——解决学习范式瓶颈。设计三阶段渐进式课程学习,让模型从基础对齐逐步走向理解与生成的紧耦合。
- 分析层(Analysis)——解决能力收敛瓶颈。引入 UniMedVL:用单一套参数同时完成医学理解与生成,无需切换权重。
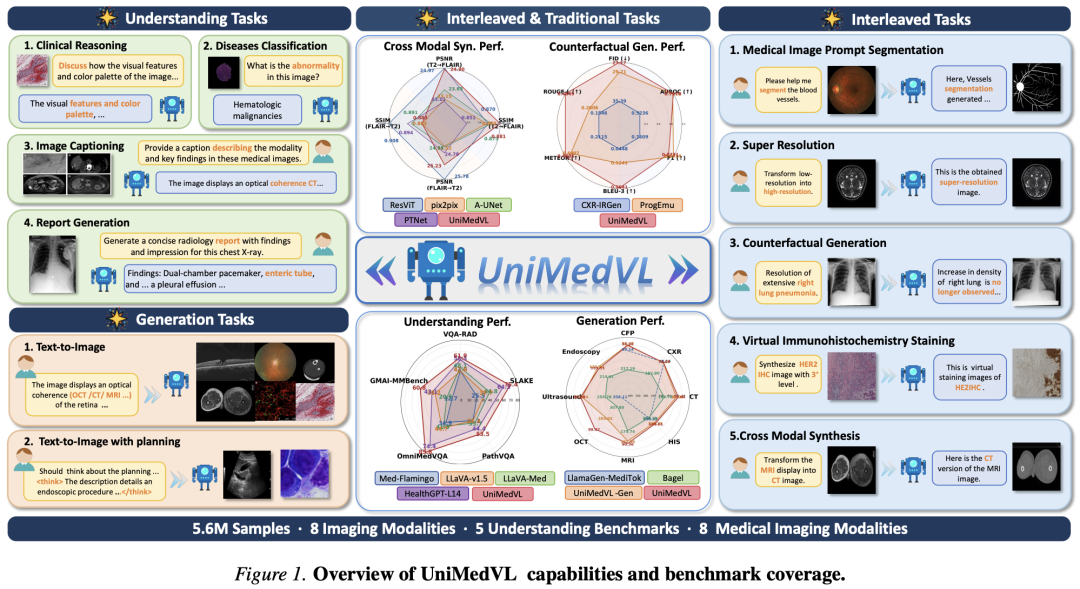
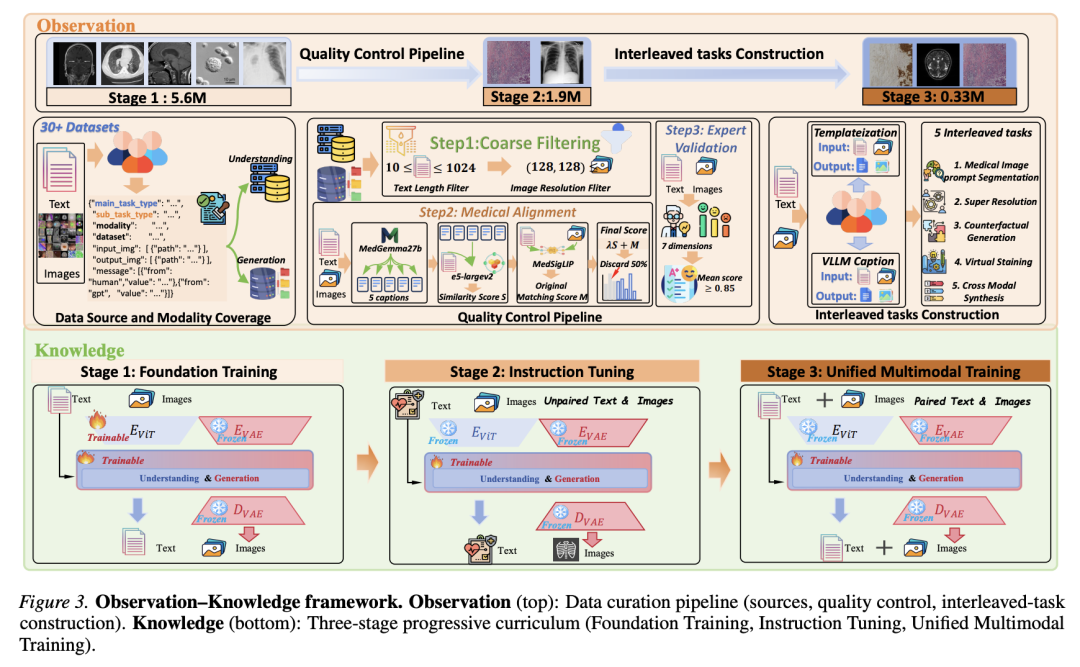
三、观察层:UniMedVL-5M 数据集是怎么造的
数据质量控制被形式化为一条串行过滤管线:
- 粗过滤:模态相关的标准预处理 + 轻量文本清洗,按图像最短边 ≥128、文本长度在 10–1024 字符之间筛选。
- 医学对齐:用 MedGemma-27B 为每张图生成 5 条候选 caption,结合 E5-large-v2 的语义相似度与 MedSigLIP 的医学专用匹配算出综合对齐分,保留排名前 50% 的高质量对。注意:MedGemma 只用于打分筛选,最终训练目标仍是来自人工验证开源数据集的原始图文对。
- 专家验证:5 位医学专家对分层抽样子集按 7 个医学维度打分,作为质量审计。
此外,作者还为 5 类交错任务(医学图像提示分割、超分、反事实生成、虚拟免疫组化染色、跨模态合成)做了"模板化 + MLLM 精炼"的两段式构造,把原本只有图像的数据集改造成结构化的多模态输入-输出对。
四、知识层:三阶段渐进式课程学习
阶段 | 目标 | 数据重点 |
|---|---|---|
Stage 1 基础训练 | 建立基础医学视觉-语言对齐 | 图生文为主(I2T 75%),辅以 T2I 25%、纯文本 5%;ViT + LLM 端到端训练,VAE 冻结 |
Stage 2 指令微调 | 强化复杂任务的指令遵循 | 引入高质量指令数据;理解任务用蒸馏思维链(DCOT)补充推理路径,生成任务用 Caption Augmented Generation(CAG)提升 caption 质量;ViT 冻结 |
Stage 3 统一多模态训练 | 建立交错多模态推理 | 把交错任务占比提到 25%,让模型在同一序列里同时产出视觉内容与解释性文字 |
设计要点:理解与生成先对齐、再强化、最后通过交错任务紧耦合——消融实验显示最大的生成增益恰恰出现在 Stage 3。
五、分析层:UniMedVL 的架构与训练目标
双编码器 + 共享骨干:理解用 ViT 编码器抽语义 token,生成用 VAE 编码器抽 latent;Transformer 骨干对理解/生成用专用 FFN 层,但共享自注意力层。ViT token、VAE token 与文本 token 拼成单一序列,预测下一文本 token 和 VAE latent 上的速度场。VAE 采用 FLUX 的通用预训练权重,未做医学微调(实验证明微调收益甚微)。
为什么联合训练更好? 作者给了一个信息论动机:联合建模输出分布相比"条件独立"训练,差距正好等于条件互信息
也就是说,只要理解与生成之间存在非平凡的依赖,统一模型永不劣于分离模型,且当两者共享互信息时严格更优。训练目标因此是「下一 token 预测损失 + 整流流匹配损失」的组合。
六、实验结果:理解与生成确实互相增益
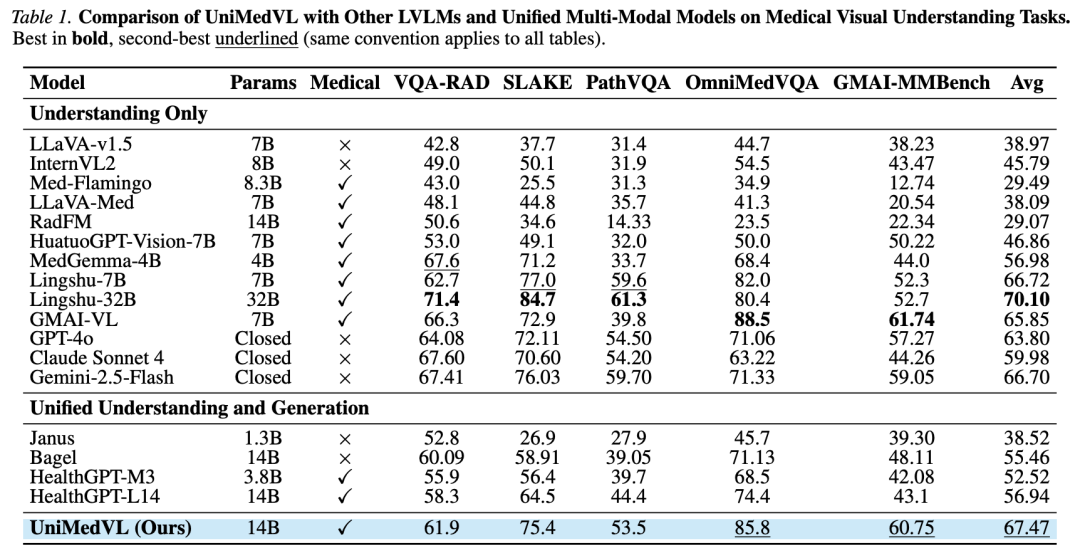
理解任务:在 VQA-RAD / SLAKE / PathVQA / OmniMedVQA / GMAI-MMBench 五个 benchmark 上平均 67.47,超过所有统一模型基线(HealthGPT-L14 为 56.94,Bagel 为 55.46),且无需切换权重。在 OmniMedVQA 上达到 85.8%,对比 HealthGPT-L14 的 74.4%。
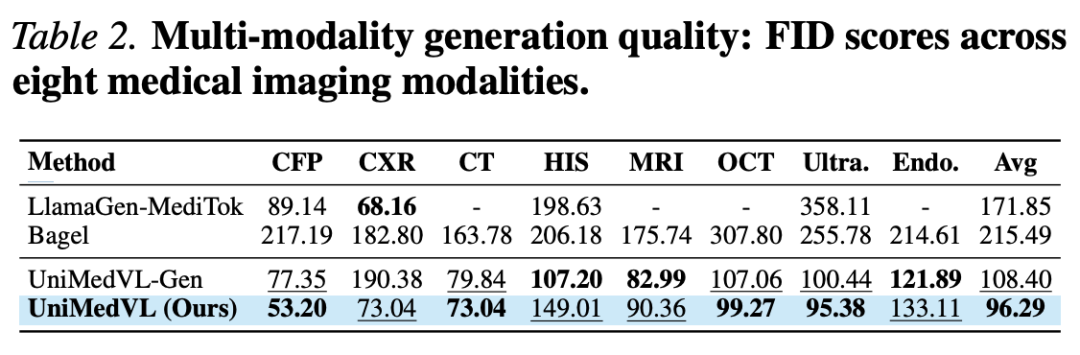
生成任务:8 种模态平均 gFID 96.29。关键对照——仅做生成训练的 UniMedVL-Gen 是 108.40,加入理解训练后降到 96.29,直接证明语义监督能提升生成保真度。在 held-out 外部数据集上同样取得最低平均 FID、最高 BioMedCLIP Score,说明增益能泛化到训练分布之外;甚至优于 4 个模态专用生成模型。
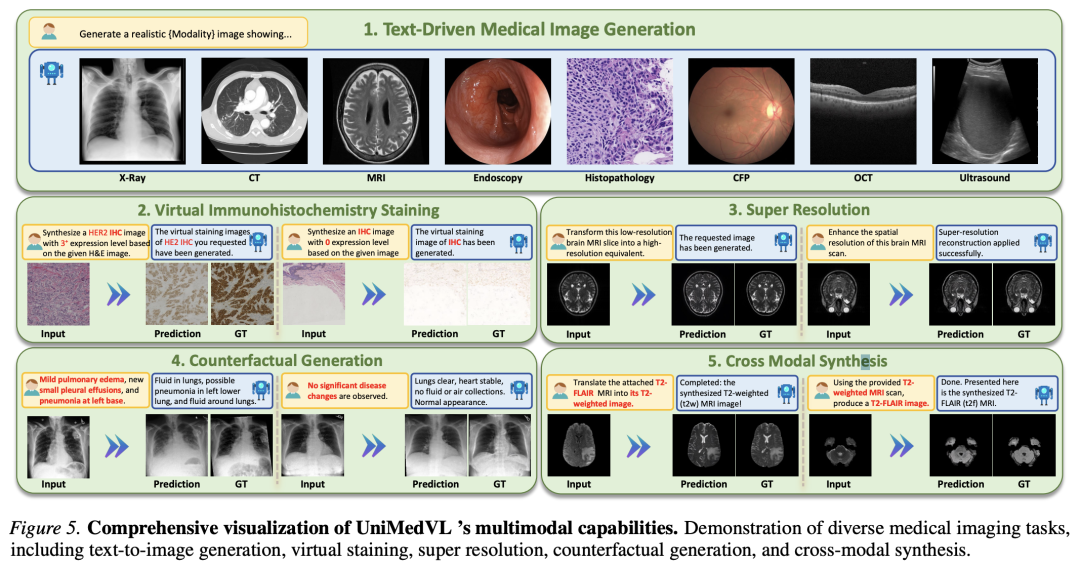
交错任务:H&E→IHC 虚拟染色 PSNR 20.27(超 HealthGPT-M3 约 28%);MRI 4× 超分 27.29 PSNR / 0.890 SSIM;T2↔FLAIR 跨模态合成平均 25.07 PSNR,逼近专用模型;反事实生成在影像质量与解释文本指标上均优于专用基线。
一句话结论:在医学场景里,理解与生成可以在单一模型内相互强化而非竞争,这挑战了"联合训练必然牺牲单任务性能"的传统假设。
七、局限与定位
作者很克制地把这项工作定位为"迈向统一医学多模态建模的一步,而非可部署的临床方案":
- 目前仅限 2D 医学影像,尚未扩展到 3D CT / MRI 体数据;
- 评估依赖自动指标,不能替代临床验证;
- 作为跨多任务的单一模型,在个别 benchmark 上仍不及最强的任务专用系统(如分割任务对比 Medical SAM3 仍有差距),缩小这一差距是后续方向。
失败案例分析也很诚实:生成时偶发幻觉文字/标注、交错编辑时编辑区域外的小结构(如导管)会轻微模糊偏移、以及计数和外科视频细粒度识别等"硬"任务上准确率偏低。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号