SIGGRAPH 2026|一张夜景,万种夜晚?LUCID:面向夜间摄影的可控去炫光与曝光调节框架

SIGGRAPH 2026|一张夜景,万种夜晚?LUCID:面向夜间摄影的可控去炫光与曝光调节框架

AI生成未来
发布于 2026-06-25 19:46:37
发布于 2026-06-25 19:46:37
作者:Tingyu Yang,Yuan Cheng,Xiaoyun Yuan
解读:AI生成未来

论文:LUCID: Learning Unified Control for Image Deflaring and Exposure Mastery in Nighttime Photography 论文地址:https://arxiv.org/pdf/2606.06901 作者:Tingyu Yang,Yuan Cheng,Xiaoyun Yuan 单位:上海交通大学 会议:SIGGRAPH Conference Papers 2026 关键词:夜景摄影、眩光去除、低光增强、可控生成、HDR、扩散模型 项目主页:xiaoyunyuan.net/index.html?project=lucid 模型权重:Hugging Face: Unswear/LUCID 代码仓库:GitHub: frakenation/LUCID
夜景摄影最迷人的地方,往往也正是它最难处理的地方。
城市灯牌、车灯、路灯、玻璃反射和镜头内部散射,会把夜晚变成一种极端复杂的光学现场。人眼可以在暗处和亮处之间迅速适应,但相机传感器没有这么幸运:暗部因为光子不足而塌进噪声,亮部因为动态范围有限而过曝,强光还会在镜头中形成光晕、鬼影和条纹,把本该存在的结构盖住。
更棘手的是,这些问题相互耦合。把照片简单拉亮,眩光也会被一起放大;把眩光强行抹掉,又可能把真实光源和高光纹理一起擦掉。夜景修复看起来像一个按钮问题,实际上是多个物理因素互相拉扯的平衡问题。
这正是 LUCID 想解决的核心矛盾:夜景照片不应该只能被“修复成一个固定答案”,而应该允许用户连续地控制曝光、眩光和光源保留方式。
LUCID 提出一个统一框架,将夜间图像中的低照度、镜头眩光和光源外观放到同一个可控生成过程中处理。它既能生成干净、清晰、自然的夜景结果,也能通过连续曝光控制生成一组“虚拟包围曝光”,进一步重建单图高动态范围图像。
亮点直击:这篇论文真正解决了什么?
如果用一句话概括 LUCID:
它把夜景增强从“自动修图”推进到“可控调光”。
传统夜景增强方法通常只回答一个问题:这张图该怎么变亮? 传统去眩光方法通常也只回答一个问题:这团眩光该怎么去掉?
但真实夜景里,这两个问题几乎从不单独出现。比如一张车灯直射的街景照片,暗处可能一片黑,车灯附近可能有大面积光晕,玻璃或镜片还可能产生鬼影。此时如果先去眩光再增强,前一步残留的光斑会在后一步被放大;如果先增强再去眩光,光斑结构会变得更强,去除难度更高。
LUCID 的出发点是:暗光和眩光属于同一个夜间成像问题,需要在统一框架中处理。
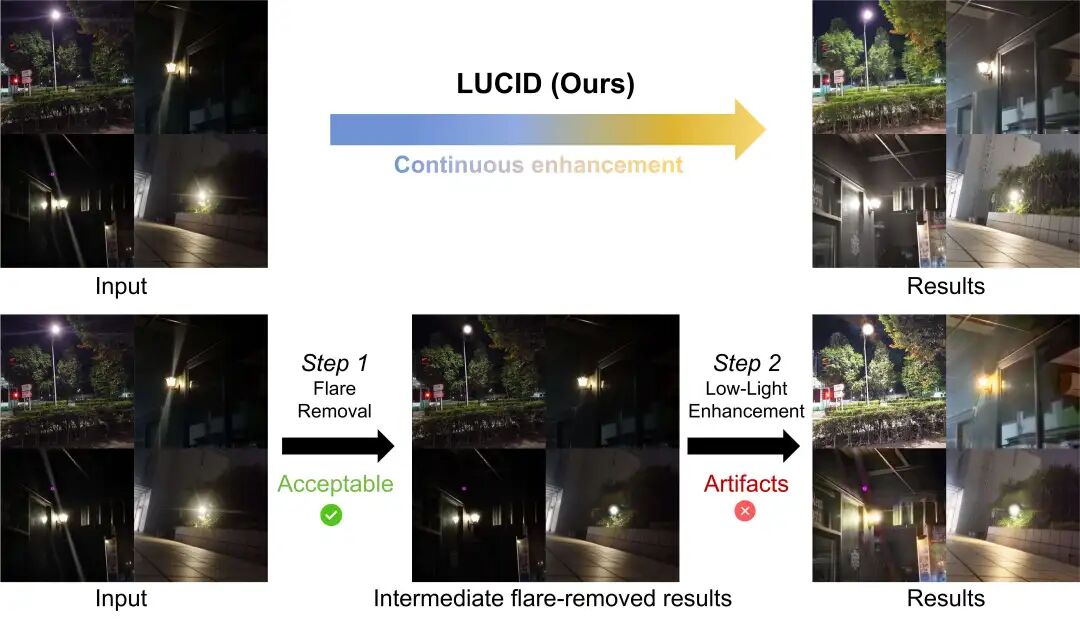
图中可以看到,分离式流程看似合理:先做去眩光,再做低光增强。但实际结果往往会出现错误累积。原本藏在暗处的残余眩光,在增强阶段被进一步放大,最后形成更明显的伪影。LUCID 则尝试在一个统一模型里同时理解背景、眩光和曝光变化,从源头减少这种“前一步的残差被后一步放大”的问题。
这篇工作的亮点主要有四个:
- 统一处理暗光增强和眩光去除 LUCID 避免把低光增强和眩光去除简单串联,先显式分解眩光和背景,再通过扩散模型联合恢复最终图像。
- 引入连续曝光控制 通过无分类器引导(classifier-free guidance,CFG),用户可以调节 $\beta),让结果从较暗、较保守的相对基准状态,平滑过渡到更明亮、更充分增强的正向恢复状态。
- 支持光源保留或移除 夜景里不是所有亮光都该被去掉。有时摄影师希望保留灯泡、车灯、霓虹灯本身,只去掉散射出来的脏光晕。LUCID 通过“光源”提示词和四模式训练,让模型学会在保留真实光源和去除光学伪影之间切换。
- 自然扩展到单图高动态范围重建 由于模型可以从一张输入生成不同曝光等级的结果,LUCID 可以把这些结果当作虚拟曝光序列,再融合成高动态范围图像,恢复更宽的亮度范围。
总结速览:LUCID 的核心思路
LUCID 的目标并非把所有夜景都处理成同一种“明亮清晰”的模板。它真正关心的是:给定一张夜间输入,用户能否决定想要怎样的光。
在这个框架中,一张输入图像会经历两个关键阶段。
第一阶段是眩光解耦(Flare Disentanglement)。模型先估计出两类信息:一类是背景图像,包含场景结构和原本的照明;另一类是眩光分量,包含光晕、散射和鬼影等加性光学伪影。这个阶段的作用很像把蒙在画面上的“光幕”先掀开。
第二阶段是混合状态扩散(Mixing-State Diffusion)。LUCID 使用基于SD-Turbo的扩散恢复模块,将主输入和参考输入编码到潜空间,并通过混合状态自注意力(mixing-state self-attention)让不同状态的信息相互交互。直观来说,模型会在“背景状态”“眩光状态”“原始输入状态”之间对照推理,判断哪些结构该保留,哪些亮斑该压制,哪些暗部该恢复。
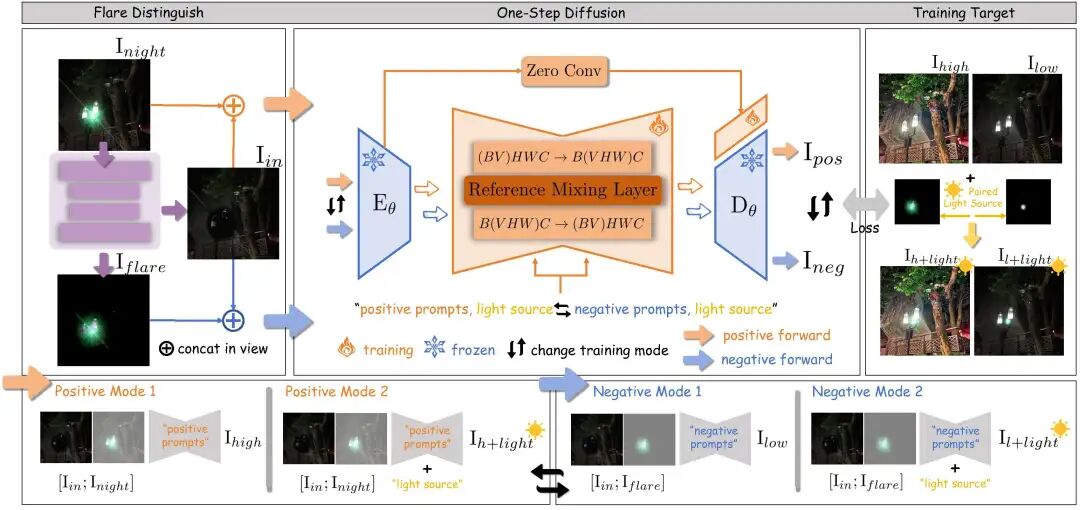
最关键的设计在训练方式上。LUCID 构造了四种训练模式,分别覆盖曝光增强、曝光抑制、光源保留、光源移除等状态。这样一来,模型在推理时可以摆脱固定输出,通过无分类器引导在相对基准状态和正向恢复状态之间连续移动。
可以把它理解为一个夜景调光台:
- 较低时,恢复更保守,曝光提升有限;
- 提高时,暗部逐步打开,画面亮度和可见性增强;
- 加入“光源”提示时,模型倾向于保留灯源本身;
- 不加入该提示时,模型可以更彻底地移除光源及相关眩光。
这种控制方式让 LUCID 更像一个面向夜景摄影的可控后期工具,而不只是常规图像增强模型。
方法:让分解与可控生成对齐
要理解 LUCID,关键不在于套用某个传统成像理论,而在于理解它为什么要把“先分解、再恢复”设计成一个耦合流程。
无分类器引导的关键,是沿着“相对基准状态 (\rightarrow) 正向恢复状态”的方向移动。 也就是说,模型需要同时知道两件事:相对基准状态是什么,正向恢复方向又是什么。用公式看,可以把方向写成 ( ),最终输出则由 () 得到。对应到夜景摄影里,相对基准状态可以是更保守、更暗、眩光信息更明显的一端;正向恢复状态则是更干净、更明亮、更符合目标曝光的一端。
如果没有前面的眩光解耦,模型很难稳定地定义这两个端点:暗部、真实光源、眩光残留会混在一起,后面的 就容易退化成粗暴调亮。LUCID 先分解背景和眩光,再让两个状态在扩散网络中耦合交互,正是为了让无分类器引导所代表的原生机制有清晰的“相对基准”和“正向方向”可调。
因此,LUCID 做的第一件事是显式拆分;做的第二件事,是让拆分后的状态重新在同一个扩散恢复过程中协同起来。
1. 眩光解耦:先把“光幕”分出来
LUCID 使用一个轻量 U-Net,包含共享编码器和两个并行解码器。两个解码器分别输出:
- 眩光分量:包含光晕、散射、鬼影等加性伪影;
- 背景分量:包含较完整的场景结构和照明信息。
为了让这两个分支真正学到不同东西,论文设计了两类约束。
第一类是重建约束:背景和眩光相加后,应该能重新组成原始输入。这保证分解不是凭空造图。
第二类是正交约束:在两个分支开始分化的特征层上,鼓励背景特征和眩光特征彼此独立。这样可以避免同一份信息同时进入两个分支,让模型更明确地区分“场景”和“光学伪影”。
其中, 和 分别表示背景分支与眩光分支在第 层的特征图, 表示逐元素相乘。结合分量监督后,眩光解耦网络的整体训练目标可以写成:
这里的 是对预测背景分量和眩光分量的监督项,用来保证分出来的两类结果不仅能相加还原输入,也分别对应到正确的背景和眩光目标。
这种分解的目的并非追求严格的物理变量拆分,而是更务实地服务于后续控制:背景图提供结构先验,眩光图提供需要抑制或调节的光学信息。只有先把这两类状态整理出来,后续的无分类器引导才能更稳定地调控“正向恢复相对于相对基准”的程度。
2. 混合状态扩散:让扩散模型在多种状态之间推理
单纯分出眩光还不够,因为最终图像不是简单的 输入 - 眩光。暗部要恢复,颜色要自然,高光要可信,缺失结构还可能需要生成式先验补全。
因此,LUCID 使用扩散模型作为恢复核心,并采用稳定扩散涡轮作为生成骨干。它把主输入和参考输入都编码到变分自编码器(VAE)的潜空间,然后在去噪网络的注意力层中引入混合状态自注意力。
普通自注意力只在单张图内部做信息交互。LUCID 的混合状态自注意力会把两个状态的潜空间特征拼在一起,让网络在注意力计算中同时看到主状态和参考状态。更具体地说,主输入和参考输入先被编码成 与 ,再沿状态维拼成 。在进入注意力层前,模型把状态维和空间维合并,把它重排为 的 token 序列;这样,来自主状态和参考状态的像素位置会进入同一个注意力池。注意力计算完成后,再把结果从 还原回 ,分别交还给两个状态继续去噪。这个“合并再拆回”的过程,让背景线索、眩光线索和原始输入线索可以在同一层注意力中互相对照,模型也就更容易学习到“这个区域属于背景结构”“这个区域更像眩光污染”“这个高亮应该保留为光源”的关系。
为了进一步约束恢复结果,LUCID 还复用了眩光解耦网络的编码器作为特征提取器,引入内在特征损失(intrinsic feature loss)。这里的重点不是泛泛地追求“高层特征相似”,而是让扩散恢复结果在眩光解耦网络学到的光照/结构表征上与目标保持一致:该保留的背景结构要对齐,该压制的眩光线索也要在特征层面被约束住。
其中,和 分别表示输出图像与目标图像在第 层提取到的特征, 是不同层的权重。最终的扩散训练损失综合了内在特征损失、L2 像素损失和感知损失:
这让结果既有可见性,也尽量保持自然纹理和感知质量。
3. 四模式训练:让模型学会“光可以被控制”
LUCID 最有意思的部分,是它把可控性设计进训练过程,而不是事后硬调参数。
论文构造了四种训练模式,围绕两个维度展开:
- 曝光控制:从欠曝状态到增强状态;
- 光源控制:保留光源或移除光源。
在曝光正向模式中,模型学习从背景状态和原始夜景参考中恢复出无眩光、曝光良好的图像。 在相对基准模式中,模型学习将眩光参考和欠曝目标对应起来,使其理解更保守的一端状态。 对于光源控制,训练中还会构造带有真实光源但不含散射眩光的伪光源图,并通过“光源”文本提示触发相应行为。
推理时,LUCID 使用无分类器引导在相对基准状态和正向恢复状态之间调节:
其中 表示相对基准状态, 表示正向恢复状态, 表示正向恢复相对于相对基准的调控程度。 越大,结果越靠近增强后的正向状态; 越小,结果越靠近保守状态。由于训练时已经通过前置分解和四模式训练建立了这些状态之间的关系, 调节可以带来结构更稳定、过渡更连续的曝光控制。
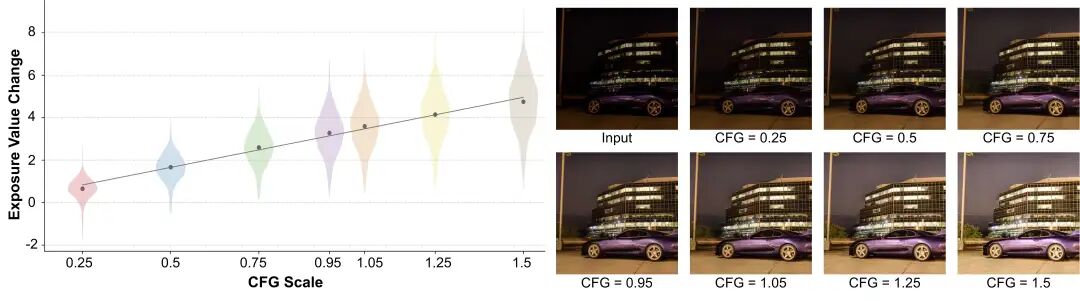
论文进一步分析了 与曝光值(Exposure Value, EV)的对应关系。这里不需要把它理解成一个复杂的计算过程,更重要的是它让模型控制和真实摄影经验对齐:摄影师熟悉“增加几档曝光”意味着什么,用户也更容易理解 从低到高时画面会怎样变化。当 时,输出会呈现接近逐档增亮的效果。换言之,会沿着 LUCID 学到的夜景恢复方向连续移动:暗部逐步打开,光源边界和场景结构仍尽量保持一致。

极端 结果
极端 结果
当 为负值时,结果会比输入更暗;当 过大时,画面会逐渐过曝。这说明 对照明强度具有直接、可解释的控制作用,但实际使用时仍需要选择合理范围。
4. 单图高动态范围:用模型生成“虚拟曝光包围”
高动态范围通常需要多张不同曝光的照片合成。但在很多真实夜景场景中,用户往往只有一张照片:可能是手机随手拍,也可能是视频里截出的一帧。
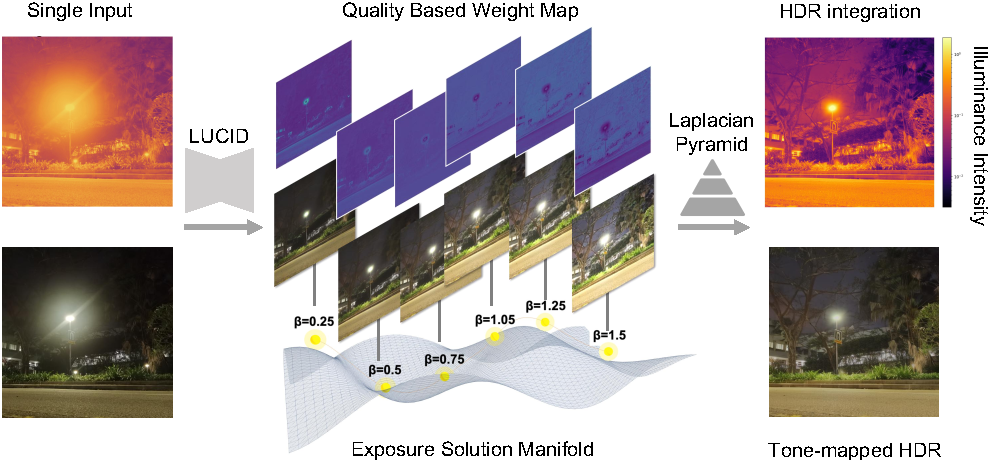
单图高动态范围重建思路
单图高动态范围重建思路
LUCID 的连续曝光控制给了一个新思路:既然模型可以从同一张输入生成不同曝光等级的结果,那么这些结果就可以被看作一组虚拟曝光序列。
论文进一步使用拉普拉斯金字塔融合和质量感知权重,将这些虚拟曝光结果合成为高动态范围表达。这样,模型既能保留暗部细节,也能处理高光区域,让单张夜景照片拥有更宽的可见动态范围。
实验:LUCID 在哪些场景里更强?
LUCID 的实验覆盖了三个核心任务:
- 通用夜景增强;
- 眩光去除;
- 单图高动态范围重建。
训练方面,论文使用 RELLISUR、LSRW、SICE 和 SID 等真实低光数据集,并结合 Flare7K 的物理眩光合成流程构造退化输入。模型在单张 NVIDIA A800 GPU 上训练,分辨率为 512 x 512,批量大小为 4。
评估方面,作者特别强调了真实夜景评测的复杂性。许多传统低光数据集通过固定曝光变化构造,但真实夜景没有唯一的“正确亮度”。同一张图可以被修成纪实风格,也可以被修成电影感夜景。因此,论文主要采用无参考图像质量指标,包括 CLIPIQA、MANIQA、MUSIQ、LIQE 和 NIMA,从感知质量角度衡量模型表现。
为了让真实夜景比较相对于基线方法更公平,论文没有直接使用 ExDark 的全部原始图像。原始 ExDark 面向检测和分类任务,里面包含运动模糊、压缩伪影、分辨率过低等样本,这些质量问题会干扰低层图像恢复评测。作者先剔除短边低于 512 像素的图像,再用拉普拉斯方差衡量清晰度、用 BRISQUE 衡量自然图像质量;最终形成 1,271 张图像的评测子集。这样筛选后的集合更聚焦夜间曝光、眩光和动态范围问题,也减少了无关图像质量缺陷对方法比较的影响。
1. 通用夜景增强:亮度、细节与氛围的平衡
在 ExDark 数据集上,LUCID 面对的是大量真实夜景图像,包含极暗环境、高对比光源、背光、颜色偏移等复杂情况。
从视觉对比中可以看到,真实夜景增强的难点远不止“变亮”。更理想的结果需要同时满足几件事:暗部细节被打开,光源附近不过曝,原本被眩光冲淡的结构重新可见,颜色也不能因为增强而明显漂移。LUCID 的结果整体更接近这种平衡:画面亮度提升的同时,局部高光、背景纹理和整体夜间氛围都保持得更稳定。

夜景增强视觉对比
夜景增强视觉对比
论文报告的无参考指标中,LUCID 在五项指标上均取得最佳结果:
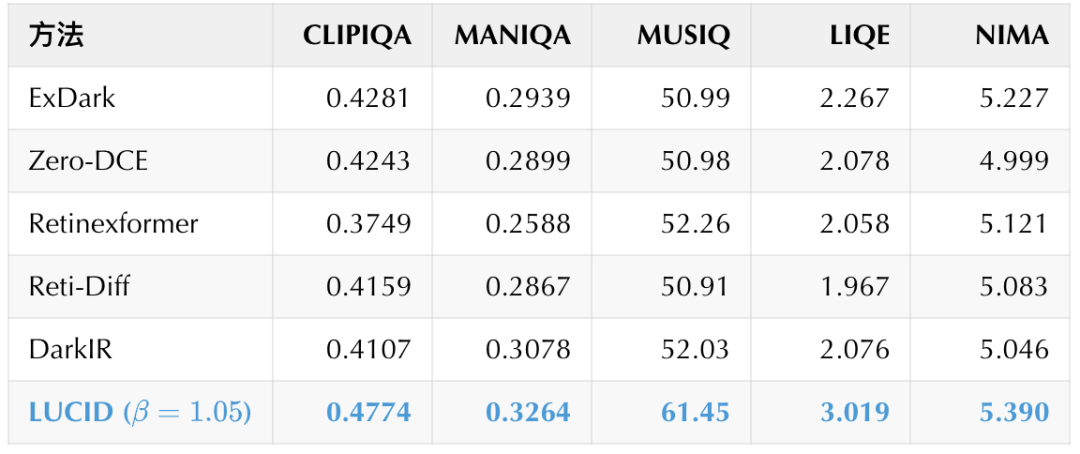
这组指标说明,LUCID 的提升不局限于亮度,在真实夜景分布上也更符合感知质量偏好。

更多真实夜景视觉效果
更多真实夜景视觉效果
补充材料还展示了更多真实场景,包括混合光照、强背光和复杂纹理。可以看到,LUCID 在不同街景、室内外夜景和高对比光照下都能保持较稳定的视觉风格:暗部被逐步打开,但不把整张图推成“白天感”;光源周围的眩光被压制,但场景本身的夜间气氛仍然保留。
2. 眩光去除:保留灯源,去掉脏光
在 Flare7K 数据集上,论文进一步评估了眩光去除能力。
这个实验关注的不只是光斑有没有消失,还包括光源附近是否自然。夜景里,车灯、路灯和霓虹招牌本来就是场景的一部分。如果算法把光源周围全部抹平,结果会看起来很假;如果只去掉一点点,残留眩光又会影响清晰度。
视觉结果显示,关键在于区分“真实光源”和“散射伪影”。对需要保留的真实光源,LUCID 可以维持自然光衰减;对光晕和鬼影,则倾向于压制其对背景结构的遮挡。

眩光去除视觉对比
眩光去除视觉对比

光源保留与光源移除
光源保留与光源移除
这组补充图更直观地展示了“光源”提示的作用:同一张输入可以得到保留光源的版本,也可以得到更彻底移除光源影响的版本。这种能力对于夜景摄影很重要,因为灯光既可能是瑕疵,也可能是画面氛围的一部分。
3. 单图高动态范围:从一张照片恢复更宽的亮度范围
在 SiHDR 数据集上,LUCID 进一步展示了单图高动态范围重建能力。
基于 控制合成的“虚拟曝光包围”,LUCID 可以自然扩展到单图高动态范围重建。原文中针对 SiHDR 的视觉对比指出,LUCID 在不同曝光层级下保持了更好的结构一致性和自然色彩平衡:暗部细节被逐步恢复,高光区域也不会被简单推向过曝。这样的结果带来了一种更灵活的审美空间,既可以得到接近真实摄影观感的恢复,也可以生成细节可见度更高的高动态范围版本。

单图高动态范围视觉对比
单图高动态范围视觉对比
4. 局限性
当然,LUCID 并不是没有边界。对于密集小光源、高反差场景和极端黑暗场景,输入本身可能已经缺失了大量有效信息。补充材料中的失败案例显示:模型可以给出视觉上合理的恢复,但在完全没有像素证据的区域,它不会凭空保证真实语义细节。这也是生成式恢复方法需要持续关注的问题。

LUCID 失败案例
LUCID 失败案例
总结:一个可控的夜景恢复框架
LUCID 主要解决的是夜景恢复中的联合处理问题:暗部增强、眩光抑制、光源保留和单图高动态范围重建往往同时出现,直接串联多个工具容易带来误差累积。论文的做法是先用眩光解耦模块整理背景与光学伪影,再用混合状态扩散统一恢复,最后通过四模式训练和无分类器引导提供 控制。
从应用角度看,LUCID 更适合处理真实夜景、强光源干扰、需要调节曝光强度的照片或视频帧。它的优势在于可控性:用户不必只接受一个固定输出,而是可以在更保守的恢复、更强的增强、光源保留和高动态范围效果之间做选择。
局限也比较明确。对于极端黑暗、高反差或信息已经严重丢失的区域,模型仍然需要依赖生成先验,结果不适合被理解为严格的真实还原。更合适的定位是:LUCID 是一个面向夜景摄影和视觉创作的可控恢复工具,而不是取代物理采集的万能 HDR 或取证级复原方法。
参考文献
[1] LUCID: Learning Unified Control for Image Deflaring and Exposure Mastery in Nighttime Photography
技术交流社区免费开放
这是一个高质量AIGC技术社群。
涉及 内容生成/理解(图像、视频、语音、文本、3D/4D等)、大模型、具身智能、自动驾驶、深度学习及传统视觉等多个不同方向。这个社群更加适合记录和积累,方便回溯和复盘。愿景是联结数十万AIGC开发者、研究者和爱好者,解决从理论到实战中遇到的具体问题。倡导深度讨论,确保每个提问都能得到认真对待。

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号