RLVR:通过精选的单个样本实现大型语言模型推理的显著提升

RLVR:通过精选的单个样本实现大型语言模型推理的显著提升

唐国梁Tommy
发布于 2026-06-25 20:26:51
发布于 2026-06-25 20:26:51
大语言模型(LLMs)在推理能力上取得了显著进展。从数学问题到逻辑推理,它们的表现越来越令人惊艳。我们看到了像OpenAI-o1、DeepSeek-R1 和 Kimi-1.5 这样在推理方面表现突出的模型。然而,要让这些模型掌握更复杂的推理技巧,尤其是通过强化学习(RL)进行微调时,往往需要大量的、高质量的训练数据。数据的收集、标注和训练成本都很高昂,这无疑是阻碍进一步发展的瓶颈之一。
那么问题来了:我们是否真的需要数千甚至数万个样本才能有效提升模型的推理能力?如果只需要极少量的样本,甚至只有一个,我们能做到吗?这篇论文就聚焦于此,探索了“单样本”或“少样本”强化学习(RLVR)在提升大模型推理能力上的潜力。研究人员发现,利用精心挑选的少量样本进行强化学习,其效果竟然可以媲美甚至超越使用包含成千上万样本的大型数据集进行训练。这无疑为数据高效的LLM推理能力提升打开了新的视角。
核心突破:少量样本,巨大能量
论文的核心发现令人振奋:只需利用区区几个,甚至单个样本进行强化学习,就能显著提升大语言模型在复杂数学推理任务上的表现。这种方法被称为RLVR,与传统的需要大规模数据集(如拥有7500个实例的MATH训练集 或1209个实例的DSR-sub数据集)的RLVR训练形成了鲜明对比。
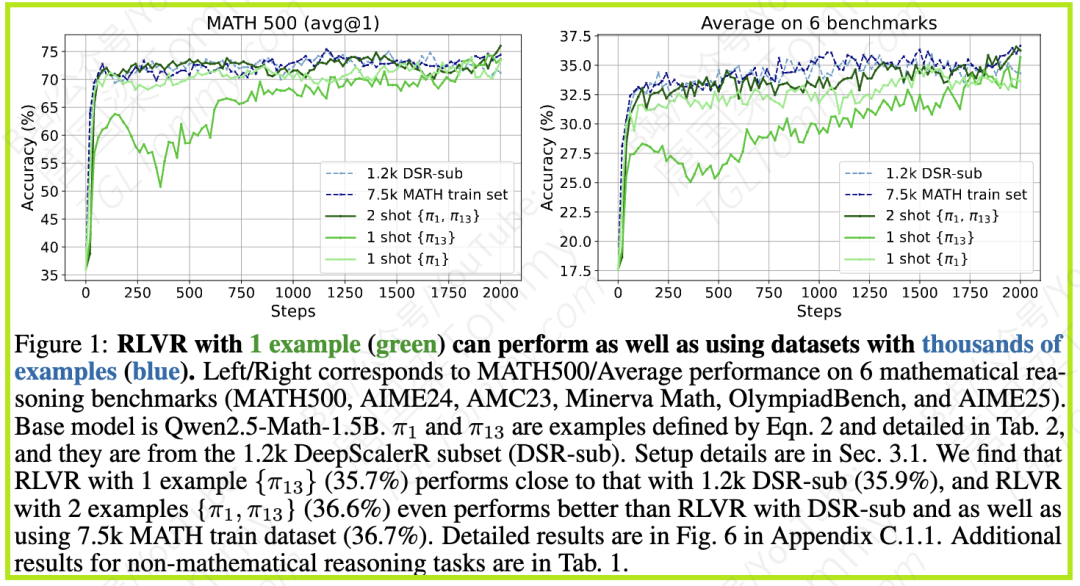
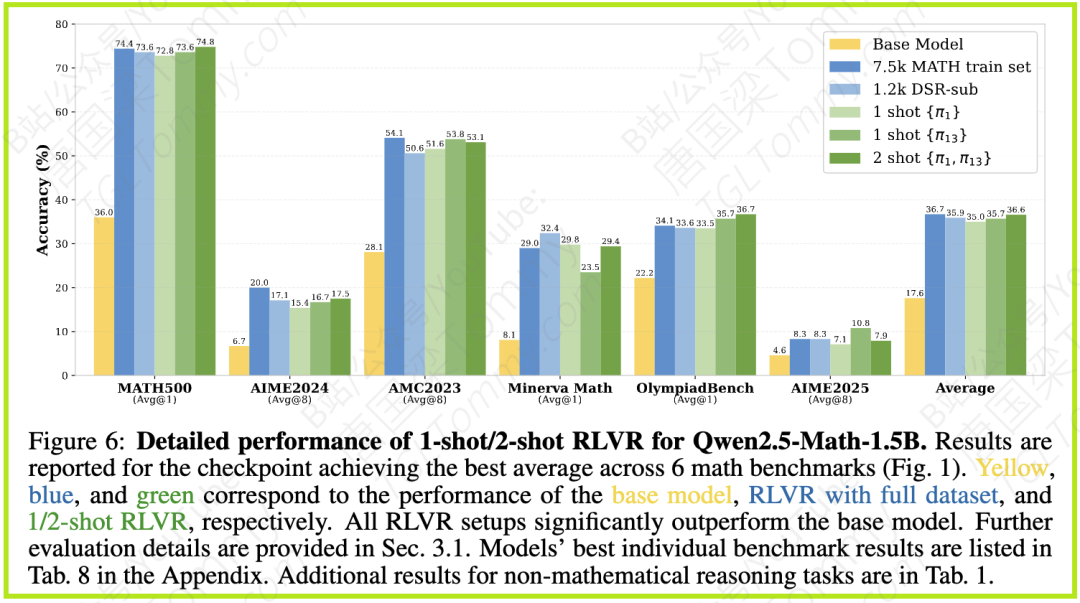
论文在Qwen2.5-Math-1.5B模型上进行的实验显示,采用1.2k大小的DSR-sub数据集进行RLVR训练,在6个数学推理基准测试(MATH500, AIME24, AMC23, Minerva Math, OlympiadBench, AIME25)上的平均准确率达到35.9%。而令人惊讶的是,仅使用1个精选样本(π13)进行RLVR训练,平均准确率就能达到35.7%,几乎与使用1.2k数据集持平。更进一步,使用2个样本(π1, π13)进行训练,平均准确率更是达到36.6%,超过了1.2k数据集的表现,并且与使用庞大的7.5k MATH训练集获得的36.7%准确率不相上下。
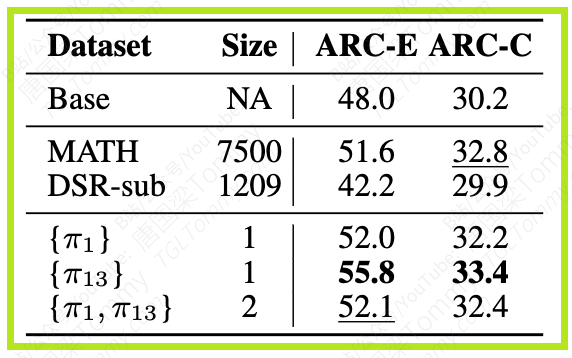
这一结果表明,对于某些推理任务,数据的“量”可能不如数据的“质”重要,或者说,少量的精心选择的样本能够非常高效地传递强化学习所需的关键信息。
更有趣的是,这种通过少量数学推理样本获得的提升,甚至迁移到了非数学推理任务上。在ARC-Easy和ARC-Challenge这两个非数学推理基准测试上,1-shot RLVR使用数学样本π1或π13,其表现甚至优于使用完整数据集进行RLVR训练的模型。这暗示了少量样本RLVR带来的能力提升可能具有一定的通用性。
方法解析:强化学习的“样本智慧”
论文中使用的强化学习算法默认是 GRPO。此外,研究也验证了 PPO 算法的可行性。
RLVR的训练目标是优化一个损失函数,该函数主要包含以下三个核心部分:
1. 策略梯度损失 (Policy Gradient Loss): 这是RL的核心,它根据模型的输出(response)获得的奖励信号,调整模型的策略(即生成下一个token的概率),以增加获得高奖励输出的概率,减少低奖励输出的概率。简单来说,就是让模型学习如何生成更好的推理过程和答案。
2. KL散度损失 (KL Divergence Loss): 用于衡量当前模型策略与参考模型(通常是微调前的初始模型)策略之间的差异。加入这个损失是为了防止模型在少量数据的训练中偏离原始能力太远,保持一定的稳定性。论文使用了KL散度的近似计算方法。
3. 熵损失 (Entropy Loss): 这个损失项旨在鼓励模型输出的多样性。研究发现,加入熵损失有助于提高模型在训练精度饱和后的泛化能力。直观理解,它可能是让模型在推理过程中更“敢于探索”不同的路径,避免过早收敛到次优解。
论文通过消融实验发现,策略梯度损失是带来模型性能提升的主要贡献者。而熵损失可以进一步增强模型在训练准确率饱和后的泛化能力。甚至,仅使用熵损失进行训练,也能带来超过25%的MATH500准确率提升,尽管仅靠熵损失模型的测试性能会迅速下降(可能导致随机输出)。这部分结果令人思考,纯粹的输出多样性鼓励是否本身就包含了一定程度的推理“探索”机制,或者与输出格式的改进有关。
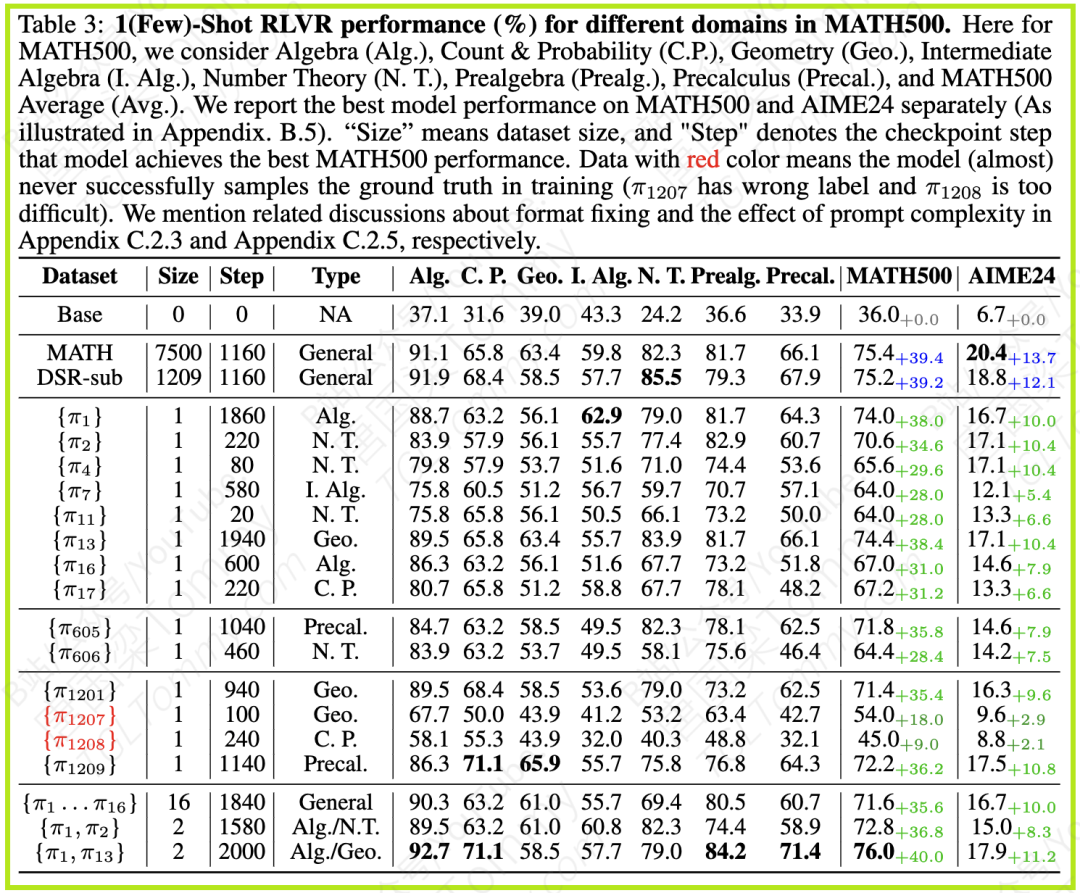
至于为什么少数样本能如此高效?论文通过分析训练数据发现,这些用于few-shot训练的样本是基于模型在初步训练后(例如对Qwen2.5-Math-1.5B训练500步后)的历史表现,通过计算历史方差得分来选取的。得分高的样本可能代表了模型表现不稳定、有较大提升空间的区域。这暗示了样本的选择并非随机,而是基于模型的内在特性和学习潜力。
在实际的少样本训练中,为了填满训练batch(例如batch size为128),研究人员简单地重复复制了选定的少量样本。这保证了强化学习算法能够在一个固定大小的批次上进行有效的梯度更新。
实验结果与分析:性能飞跃与内在机制探究
论文的实验非常详尽,不仅在主要模型Qwen2.5-Math-1.5B上验证了少样本RLVR的有效性,还进一步拓展到 Qwen2.5-Math-7B, Llama-3.2-3B-Instruct, DeepSeek-R1-Distill-Qwen-1.5B, Qwen2.5-1.5B, 和 Qwen2.5-Math-1.5B-Instruct 等不同规模和架构的模型上。结果表明,单样本/少样本RLVR对这些模型普遍有效。例如,在Qwen2.5-Math-7B上,2-shot {π1, π13} 的平均准确率(41.3%)甚至超过了1.2k DSR-sub(40.2%)。在Llama-3.2-3B-Instruct上,2-shot {π1, π13} 的平均准确率(21.0%)也显著高于Base模型(17.5%)和1.2k DSR-sub(19.8%)。即使对于DeepSeek-R1-Distill-Qwen-1.5B,尽管少样本与完整数据集的差距较大,但1-shot和4-shot RLVR仍带来了平均6.9%和9.4%的提升。
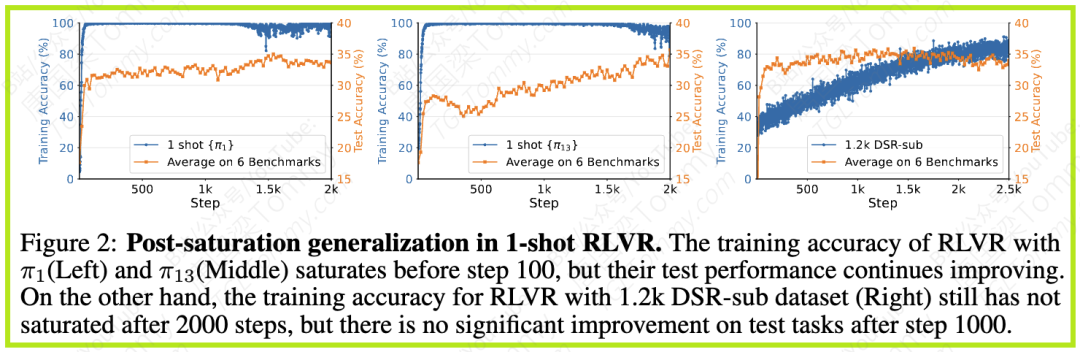
实验使用了包括 MATH500, AIME 2024/2025, AMC 2023, Minerva Math, OlympiadBench 在内的6个复杂数学推理基准,以及 ARC-Easy/Challenge 作为非数学任务评估。数学基准的评估主要使用pass@1或pass@8指标。
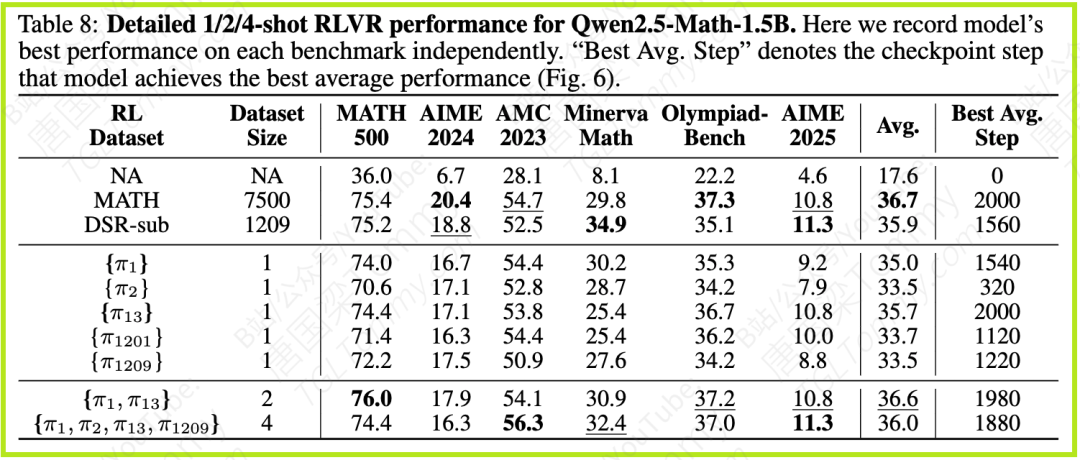
论文还深入探究了性能提升的内在原因。一个重要的观察是,模型输出的格式,特别是是否包含最终答案的标准格式(如使用\boxed{}标记)与推理准确率有很强的正相关性。通过少量样本RLVR训练后,模型生成包含\boxed{}格式的比例显著增加。这可能意味着一部分性能提升来自于模型学会了正确的输出格式。
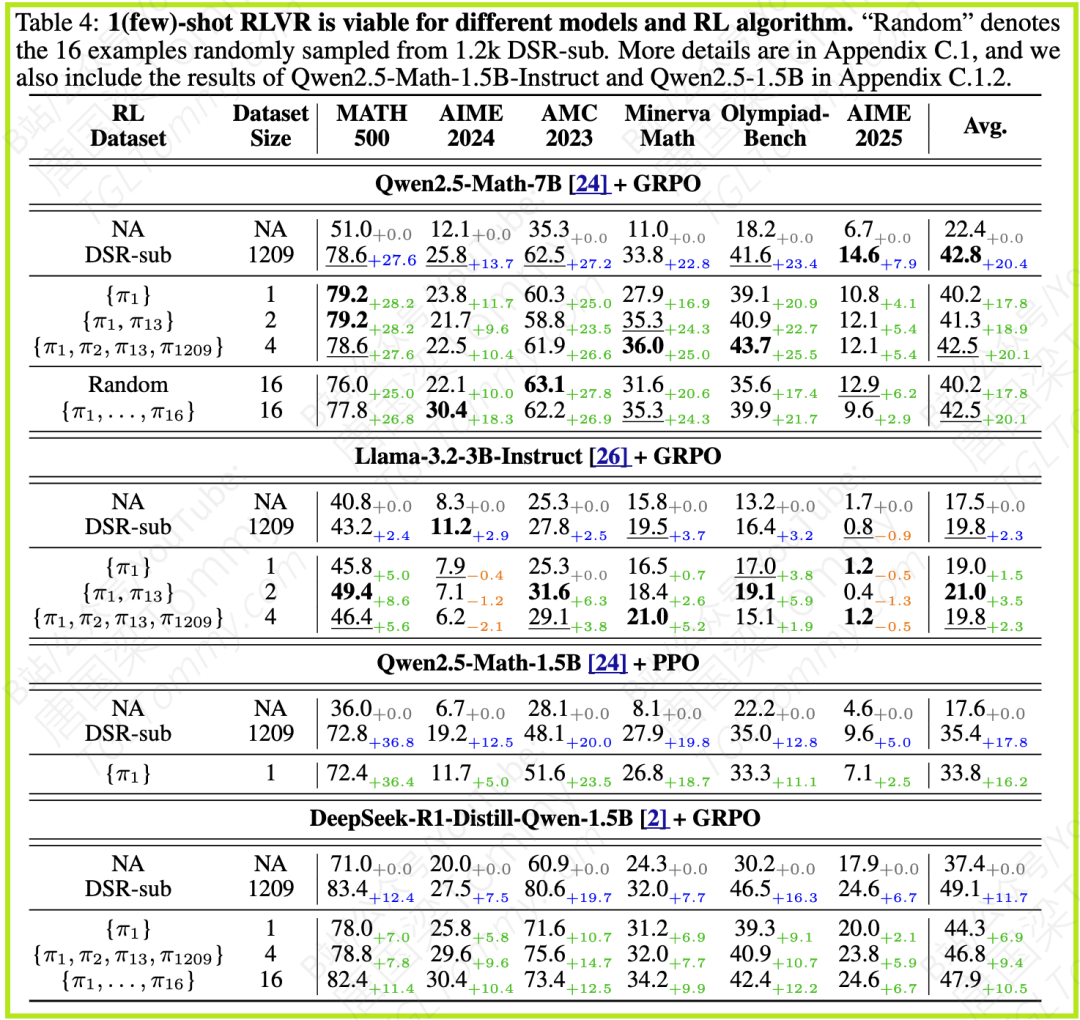
然而,研究人员进一步分析发现,性能提升不仅仅是学会了格式。他们区分了“结果奖励”(Outcome Reward,即答案是否正确)和“格式奖励”(Format Reward,即输出是否包含特定格式)。虽然仅使用格式奖励也能带来显著的性能提升,并且提高\boxed{}的使用比例,但使用结果奖励训练的模型通常能获得更高的准确率。更重要的是,他们观察到,在输出格式的比例达到平台期后,模型在某些基准(如MATH500, Minerva Math, OlympiadBench)上的准确率仍在持续提高。这强有力地支持了这样的结论:少样本RLVR不仅教会了模型正确的输出格式,还带来了独立的、真正的推理能力的提升。
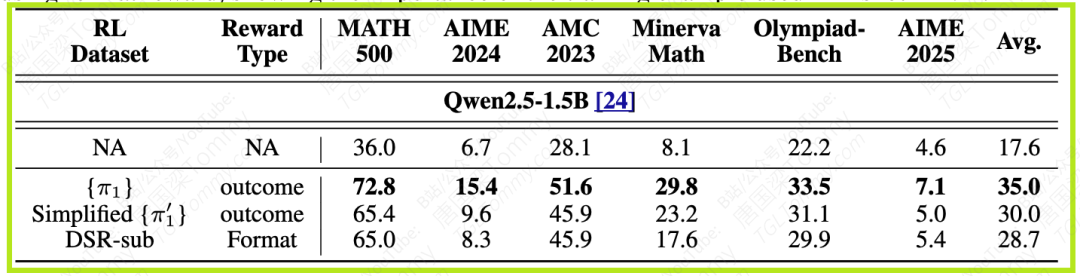
他们还用了一个例子(π1,解决P=kAV^3问题)及其简化的子问题(π'1,只计算 \sqrt{2048})进行对比,发现训练完整的π1样本比训练简化的π'1更能提升模型在 MATH500上的表现。这进一步证明了,选择一个包含完整推理链条的复杂问题作为少量训练样本,其效果优于仅包含其中一步的简化问题。
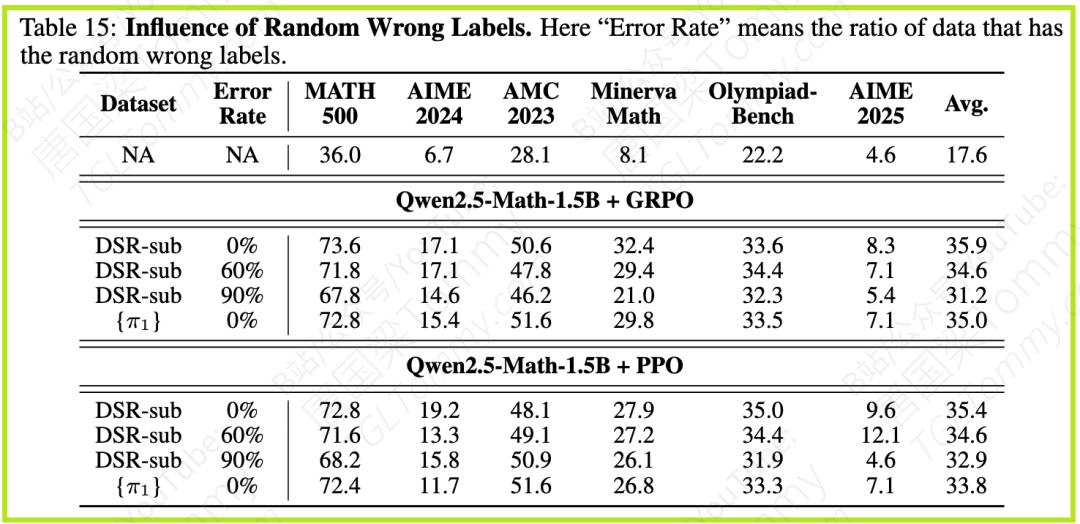
另外,实验也测试了随机引入错误标签的影响。不出所料,随着错误标签比例的增加,模型的表现会逐渐下降。这也说明,即使是少量样本,其质量和标签的正确性仍然是重要的。
启示与未来展望
这篇论文展示了少样本RLVR作为一种数据高效的训练方法,在提升LLM推理能力方面具有巨大潜力。它为那些难以获取大规模高质量标注数据的场景提供了可行的思路。
未来的研究可以进一步探索:
- 更智能的少量样本选择策略,除了基于历史方差,是否还有其他更优的方法来选取能够最大限度激发模型推理能力的样本。
- 深入理解从少量样本到大规模泛化的内在学习机制,特别是如何区分和促进格式修正之外的真正推理能力提升。
- 将少样本RLVR应用于更广泛的推理任务和领域。
总的来说,这项工作用坚实的实验证据告诉我们,在某些情况下,对于提升大模型的推理能力,“少即是多”是完全有可能的。这无疑是LLM训练领域一个非常值得关注和深入研究的方向。
参考文献
论文名称: Reinforcement Learning for Reasoning in Large Language Models with One Training Example
第一作者: 华盛顿大学
论文链接: https://arxiv.org/abs/2504.20571v2
发表日期: 2025年5月25日
GitHub:https://github.com/ypwang61/One-Shot-RLVR.git
你好,我是唐国梁Tommy,专注于分享AI前沿技术。
#AI前沿技术 #AIAgent #人工智能 #强化学习 #AI大模型 #CoT #思维链 #大模型 #LLM #唐国梁Tommy #计算机技术 #AIGC #大模型推理 #RL
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号