告别RL探索困境:「强化学习教师」重塑大模型推理(Reasoning)训练

告别RL探索困境:「强化学习教师」重塑大模型推理(Reasoning)训练

唐国梁Tommy
发布于 2026-06-25 20:35:22
发布于 2026-06-25 20:35:22
近期,将强化学习(RL)应用于语言模型(LM)以提升其复杂推理能力,已经成为AI领域最前沿、最激动人心的方向之一。从DeepMind的AlphaCode到DeepSeek-AI的DeepSeek-R1系列,我们见证了通过RL“试错”和“反思”来攻克竞赛级数学和编程难题的惊人成果。这些模型不再仅仅是语言的模仿者,更像是具备初步推理和解决问题能力的“思考者”。
然而,在这条看似光明的道路上,一个巨大的阴影始终挥之不去——探索困境。传统的RL推理框架依赖于一个非常稀疏的奖励信号:答案正确,奖励为1;答案错误,奖励为0。这种机制要求模型在训练初期就必须具备一定的“运气”或“天赋”,能够碰巧蒙对几个难题。如果模型一开始就完全摸不着头脑,它将永远无法获得正向反馈,训练也就无从谈起。

这导致了一个现实问题:目前成功的RL推理应用,几乎都建立在那些本就极其强大的超大模型(如数百B参数)之上,因为只有它们才有足够的初始能力去“探索”到正确的解法。这不仅意味着巨大的算力成本,也限制了这项技术的普及。
更深层次地,我们发现了一个有趣的“角色错配”:我们训练这些大模型,是为了让它们成为解决未知难题的“终极解题者”(Solver)。但在实际应用中,它们一个更重要的角色是充当“教师”(Teacher),生成高质量的推理过程(reasoning traces),然后通过蒸馏的方式,将这些宝贵的“思维链”传授给更小、更高效的学生模型。
那么问题来了:一个擅长“蒙题”和“解题”的模型,就一定是个好“老师”吗?Sakana AI的这篇论文给出了一个否定回答,并提出了一种颠覆性的新框架——强化学习教师(Reinforcement-Learned Teachers, RLTs)。
一、核心思想:从“解题者”到“教学专家”的转变
RLT框架的出发点非常直观,甚至可以说是常识性的:评价一个人类教师的水平,我们看的不是他能否从零开始独立发现微积分,而是看他能否在拿到教科书(已知答案和理论)后,为学生讲授一堂清晰、易懂、富有启发性的课程。
传统RL推理框架要求模型扮演的是“牛顿”的角色,从零开始探索。而RLT框架则让模型扮演“金牌教师”的角色。具体来说,任务发生了根本性的转变:
- 传统RL模式:输入是“问题”,模型需要输出“思考过程 + 答案”。
- RLT模式:输入是“问题 + 标准答案”,模型的核心任务是输出一段详尽、清晰、有逻辑的“解题思路”。
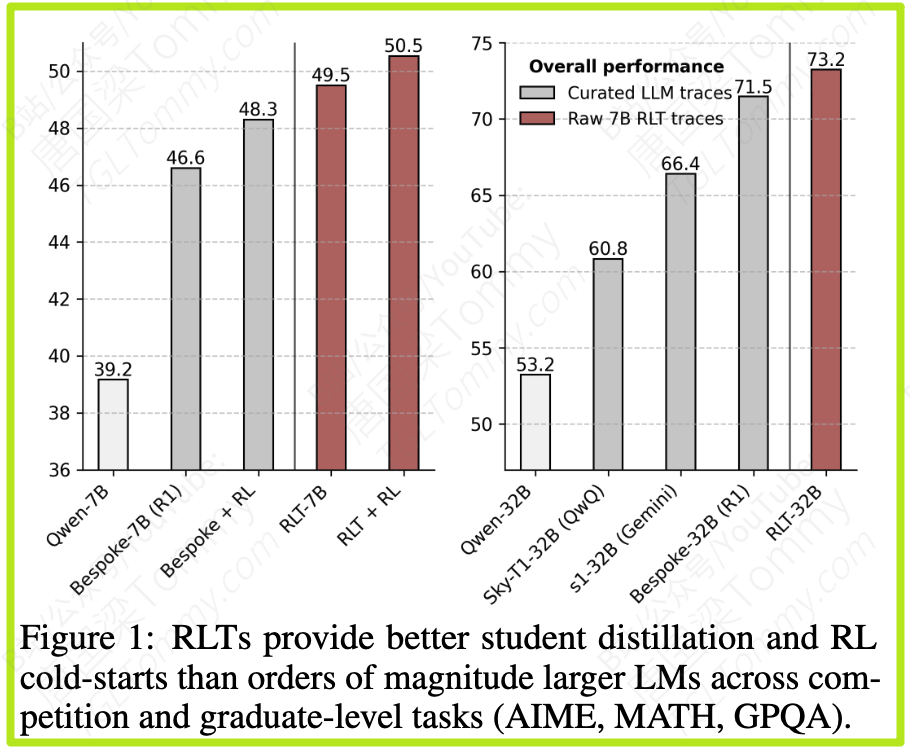
图1:论文中展示的两种模式对比。左侧是传统的RL推理格式,要求模型自己思考并解决问题。右侧是RLT的教学格式,模型被给予了最终答案,任务是“承前启后”,生成高质量的解释。
这个看似简单的改动,却带来了革命性的变化:
(1) 彻底规避探索难题:由于模型在训练时已经知道了答案,它不再需要在巨大的解空间中盲目探索。学习信号不再是稀疏的“0或1”,而是可以根据解释的质量给出稠密、连续的反馈。
(2) 目标与应用高度对齐:RLT的训练目标直接就是“生成最有效的教学材料(推理过程)”,这与它作为“教师模型”进行知识蒸馏的最终应用场景完全一致,解决了前文提到的“角色错配”问题。
现在,最关键的问题来了:我们如何用算法来量化一段解释是“好”还是“坏”呢?
二、方法解析:如何量化“好”的解释?
RLT框架的精髓在于其精心设计的稠密奖励函数。这个奖励函数不再关心答案的对错(因为答案是已知的),而是从两个维度来评估教师模型(RLT)生成的“解释”的质量:有用性和清晰度。
为了评估,框架引入了一个“学生模型”(student model),它通常是一个规模较小、未经特殊训练的普通语言模型。整个评估过程就像一场模拟教学:
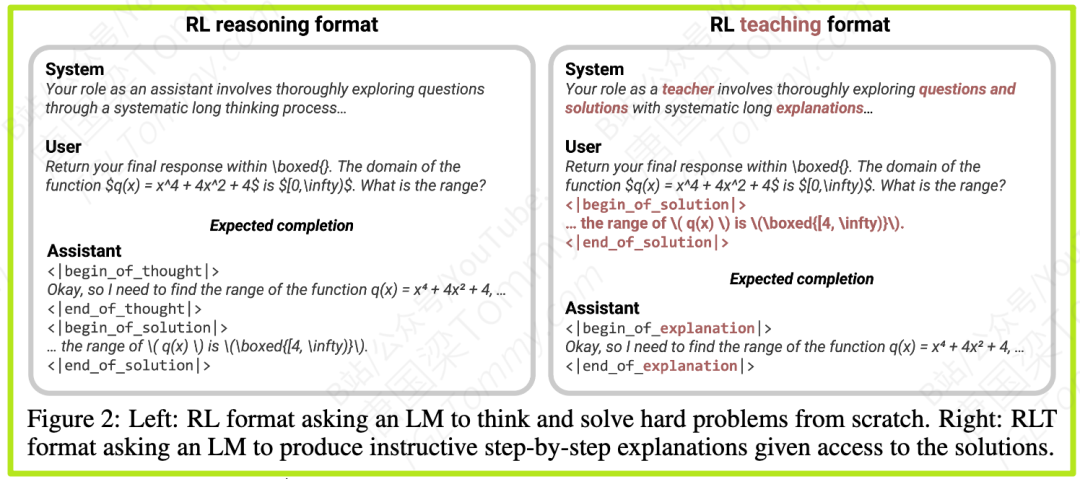
图2:RLT奖励机制示意图。教师(RLT)的解释被用来评估学生模型的理解程度,从而产生奖励信号。
2.1 奖励项一:解释的有用性
这个奖励项回答的问题是:“学生在听完老师你的这段解释后,是否能更好地理解并独立得出正确答案?”
具体计算方式如下:
- 将教师RLT生成的解释
to和原始问题qi拼接起来,作为学生模型的输入。 - 测量学生模型在此基础上,生成正确答案
si的对数概率(log probabilities)。 - 这个概率越高,说明教师的解释越“有用”,因为它有效引导了学生。
- 论文还巧妙地结合了平均概率(
avg)和最低概率(min),确保解释中的每个词都在为最终答案服务,避免出现部分有用、部分无效的解释。
数学上可以表示为:

2.2 奖励项二:解释的清晰度/自然性
光有用还不够,解释本身必须是合乎逻辑、易于理解的。这个奖励项回答的问题是:“老师你的这段解释,对于一个只知道问题、不知道答案的学生来说,听起来是否‘自然’、‘顺理成章’?”
如果一段解释充满了只有知道答案才能理解的“神来之笔”或逻辑跳跃,那它对学生的学习就没有泛化价值。为了量化这一点,论文引入了KL散度:
- 计算在解释的每一步(每个token),“知晓答案的教师模型”的思路(概率分布)与“一无所知的学生模型”的思路(概率分布)之间的差异。
- 这个差异(KL散度)越小,说明教师的解释越贴近学生的认知,越“自然”,没有开“上帝视角”。
- 同样,通过结合平均KL散度(
avg)和最大KL散度(max),确保解释的每一步都是平滑、易于跟随的,惩罚任何突兀的逻辑跳跃。
数学上可以表示为:
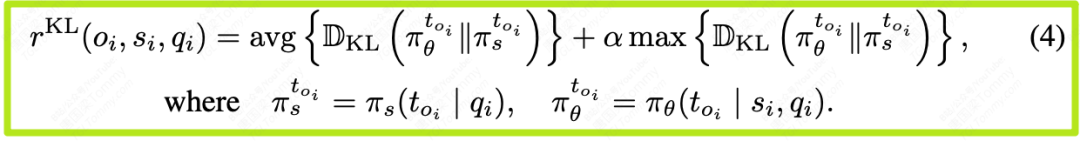
最终的总奖励是这两项的加权组合:
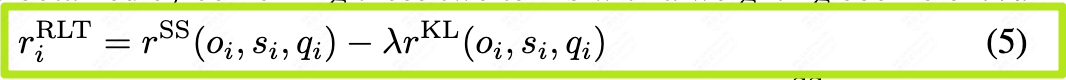
通过最大化这个奖励,RLT被激励去生成既能有效引出答案、又符合学生认知逻辑的完美解释。
有了这个稠密的奖励信号,Sakana AI使用与DeepSeek-R1类似的GRPO算法进行强化学习训练,但整个过程变得前所未有的稳定和高效。
三、实验结果:RLT的惊人效果
理论再完美,也要靠实验结果说话。RLT的表现可以说是相当惊艳,论文从多个角度验证了其有效性。
3.1 蒸馏效果:小教师“吊打”大教师
这是最核心的对比。研究者使用一个7B参数的RLT模型生成推理轨迹,然后用这些轨迹来微调(蒸馏)学生模型(包括7B和32B两种尺寸)。其效果与使用那些通过传统RL训练的、数百B参数的庞大模型(如DeepSeek-R1 671B)经过复杂后处理和筛选得到的推理轨迹进行对比。
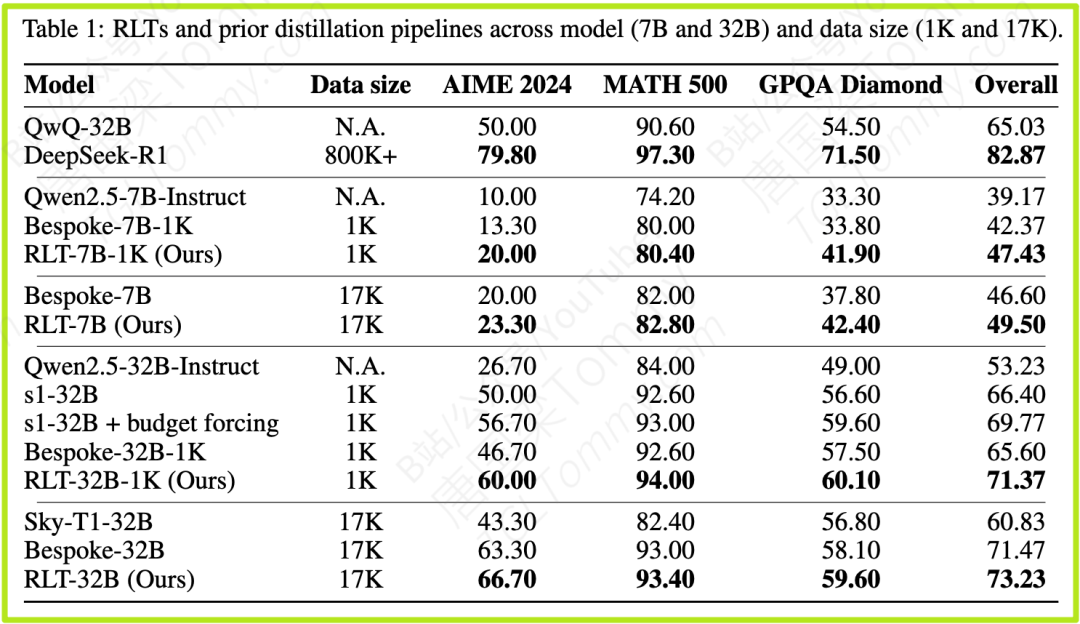
结果如上图所示,在AIME、MATH、GPQA等高难度推理基准上:
- 7B RLT的原始(raw)输出,在蒸馏学生模型时,其效果全面超越了由参数量大上百倍的模型精心策划和后处理的推理轨迹。
- 无论是训练7B的小学生,还是训练32B的大学生,7B RLT这位“小老师”的教学效果都更胜一筹。
这充分证明,训练一个专门的“教师”远比训练一个“解题者”然后逼它去教学要高效得多。
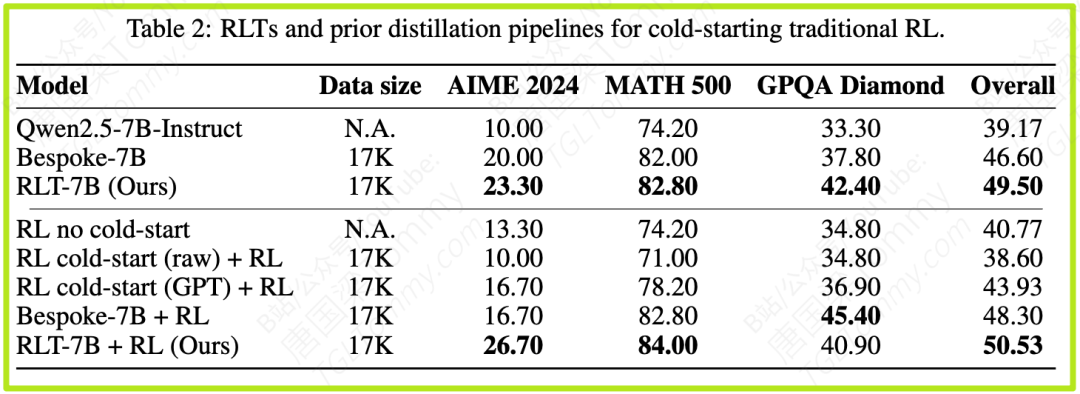
3.2 RL冷启动:提供更好的“课前预习”
传统RL训练非常依赖于一个好的初始模型(冷启动)。实验表明,先用RLT生成的教学数据对模型进行一轮微调,再进行传统的、以解题为目标的RL训练,最终达到的性能远高于其他冷启动方法,甚至优于那些使用GPT-4进行数据后处理的方案。RLT提供的高质量“预习材料”,让模型在面对真正的RL挑战时,起点更高,后劲更足。
3.3 零样本跨领域迁移:真正的“教学”是通用技能
这是最令人印象深刻的实验之一。研究者将在数学和编程问题上训练好的RLT,直接用于一个全新的、它从未见过的领域——倒计时(Countdown)游戏(一个数字组合游戏)。
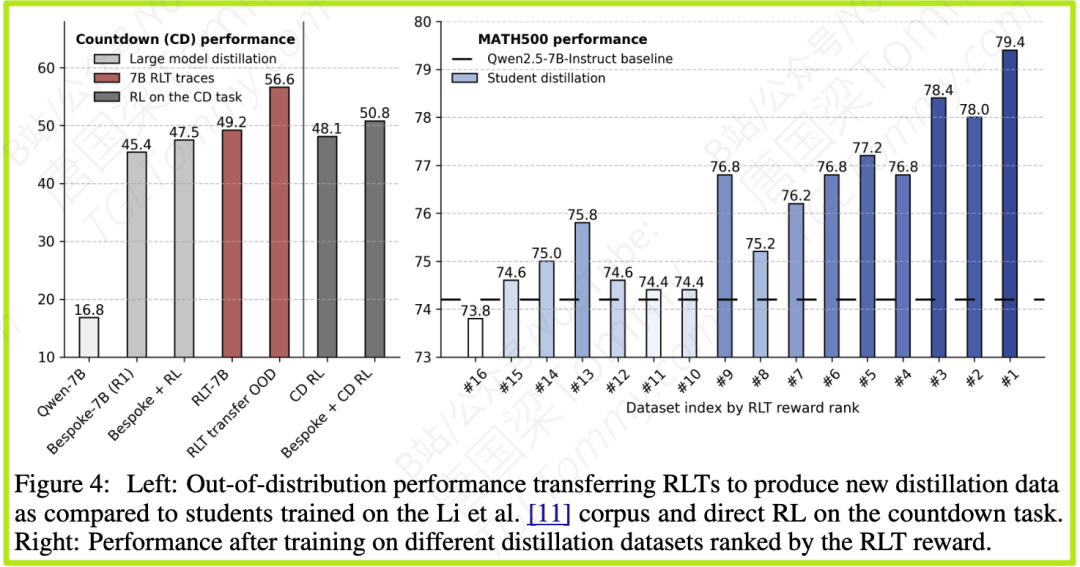
图4:RLT在倒计时任务上的零样本迁移效果(左侧图)。RLT transfer OOD(红色)表现最佳。
结果令人震惊:
- 未经任何重新训练,7B RLT直接在新任务上生成的解释,其蒸馏效果竟然超过了在该任务上从零开始进行专门RL训练的模型!
- 这表明,“如何解释一个解法”这项技能具有很强的通用性。一个好的数学老师,即使面对一个新领域的逻辑问题,也能凭借其教学本能,给出一个比该领域专家(但教学能力一般)更清晰的讲解。
四、启示与未来
Sakana AI的这项工作为我们揭示了一个简单而深刻的道理:与其强求模型成为无所不能的“全能解题者”,不如让其专注于成为一个优秀的“教学家”。 RLT框架通过巧妙地重构任务,不仅解决了RL在推理领域的探索难题,还极大地提升了训练效率和知识蒸馏的效果,为我们提供了一条更加民主化、低成本的推理能力提升路径。

这项研究也开启了许多令人兴奋的未来方向:
- 师生协同进化:能否让教师RLT和学生模型同时进行训练?教师根据学生的实时学习动态调整其解释策略,实现真正的个性化教学。
- 角色统一与自省:同一个模型能否同时扮演教师和学生的角色?在RLT框架下,模型首先学习“如何解释”,然后通过自我蒸馏,反思自己的解释,从而学会“如何解决”,统一了RL的开放性和监督学习的稳定性。
- 数据源的扩展:利用小型高效的RLT,我们可以为海量“问题-答案”对廉价地生成高质量的推理过程,从而构建规模和质量都堪比闭源SOTA模型所用的训练数据集,进一步推动开源社区的发展。
总而言之,RLT不仅是一个聪明的技术方案,更是一种思维方式的转变。它提醒我们,在通往通用人工智能的道路上,有时候最直接的路径,恰恰是那条最符合我们人类学习和传授知识直觉的道路。这无疑是近期AI领域最值得我们深入思考和学习的工作之一。
参考文献
论文名称: Reinforcement Learning Teachers of Test Time Scaling
第一作者: Sakana AI
论文链接: https://arxiv.org/abs/2506.08388v2
发表日期: 2025年6月22日
GitHub:https://github.com/SakanaAI/RLT.git
你好,我是唐国梁Tommy,专注于分享AI前沿技术。
#强化学习 #大模型LLM #大模型训练 #唐国梁Tommy #RL强化学习 #RLT强化学习 #强化学习教师 #AI前沿技术 #AIGC #AI论文解读
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号