MetaClaw 如何让 Agent 在真实业务中持续进化?

MetaClaw 如何让 Agent 在真实业务中持续进化?

唐国梁Tommy
发布于 2026-06-25 21:34:07
发布于 2026-06-25 21:34:07
论文名称:MetaClaw: Just Talk -- An Agent That Meta-Learns and Evolves in the Wild
论文链接:https://arxiv.org/abs/2603.17187目前绝大多数部署在生产环境中的 LLM Agent 都面临一个根本性矛盾:模型权重和系统 Prompt 在上线那一刻就被冻结了,但用户的实际需求分布却在不断漂移。
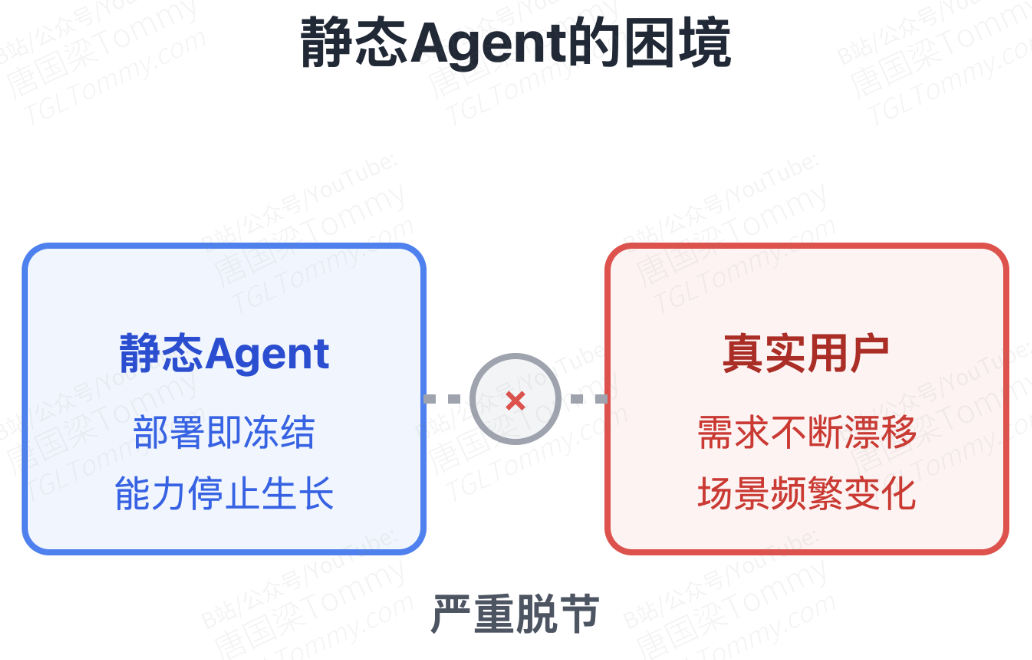
今天用户可能在频繁处理文件系统操作,下周可能就转向了多智能体通信流。面对这种 Non-stationary 的任务流,现有的优化手段都显得捉襟见肘:依赖长上下文的 Memory 机制容易导致信息冗余且无法提炼出泛化行为;维护静态的 Skill 库虽然有效,但它与底层模型的权重优化完全割裂;而传统的 RL(强化学习)微调又会带来难以忍受的线上服务宕机时间。

UNC、CMU 等机构提出的 MetaClaw,正是为了拆解这个“既要持续进化,又不能停机维护”的工程死局。

“快技能”掩护“慢更新”的双轨进化
MetaClaw 的核心设计是将 Agent 的进化拆分为两个天然互补的时间尺度。首先是秒级的“技能驱动快速适应”:当 Agent 在任务中碰壁时,系统会立刻调用一个 LLM Evolver 分析失败轨迹,并合成自然语言的行动指令(比如“修改文件前必须先备份”),这些指令作为新技能被即时注入到下一次的系统 Prompt 中,实现零宕机起效。

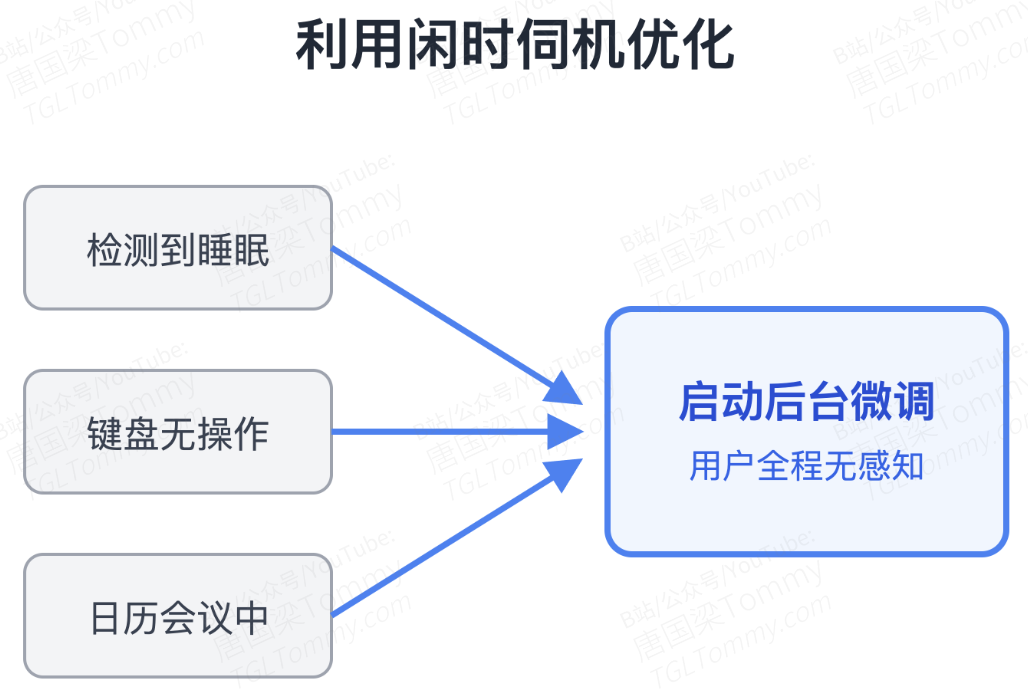
其次是小时到天级别的“伺机策略优化(Opportunistic Policy Optimization)”:系统会在后台积累这些使用新技能的成功轨迹,并通过一个 OMLS 调度器监控用户的系统闲置状态(如睡眠时间、键盘无操作或 Google Calendar 处于会议中),在不打扰用户的前提下,悄悄把这些经验通过 Cloud LoRA + PRM(过程奖励模型)蒸馏到模型权重里。Prompt 负责止血和探索,RL 负责将肌肉记忆刻进参数。
拒绝被“过期经验”带偏的梯度
我认为这篇论文在方法论上最精妙的一笔,是解决了在线 RL 中的“奖励污染”问题。
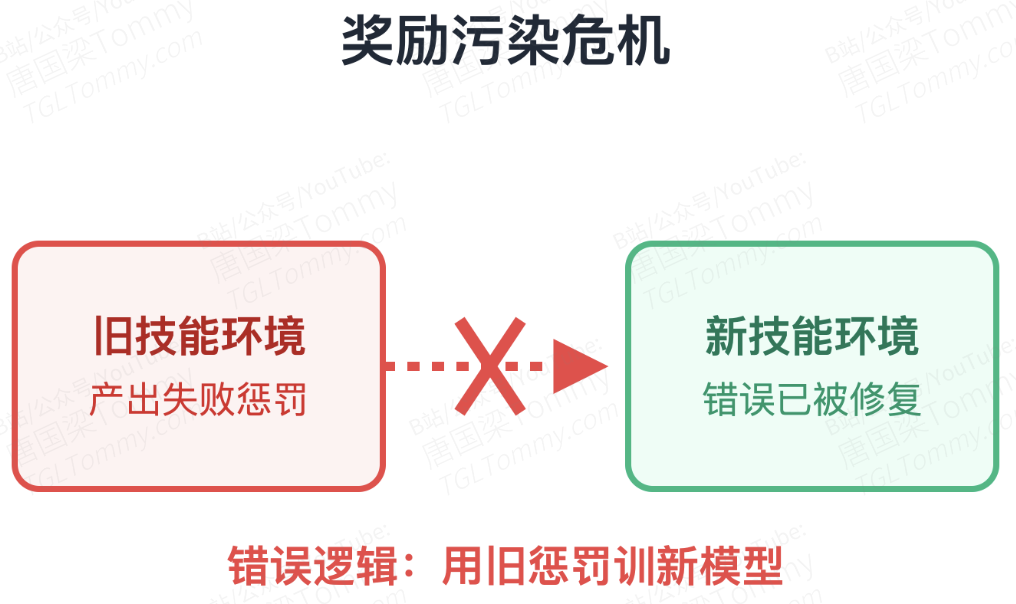
在传统的持续学习中,历史数据经常被直接扔进经验回放池。但在 MetaClaw 的框架里,一旦技能库更新了,旧技能环境下的轨迹(Support Data)所带有的奖励信号就“过期”了——如果用这些数据去计算梯度,等于在惩罚模型犯一个已经被新 Prompt 技能解决的错误。为此,MetaClaw 引入了严格的“技能代际版本控制”。它将失败的 Support Data 仅用于提炼技能后便丢弃,只允许在最新技能加持下收集的 Query Data 进入 RL 训练缓冲区。这种严格的读写分离,确保了策略优化始终在朝着“如何更好地利用现有技能”的元学习目标前进。
弱模型靠“后天努力”完成跨代逆袭
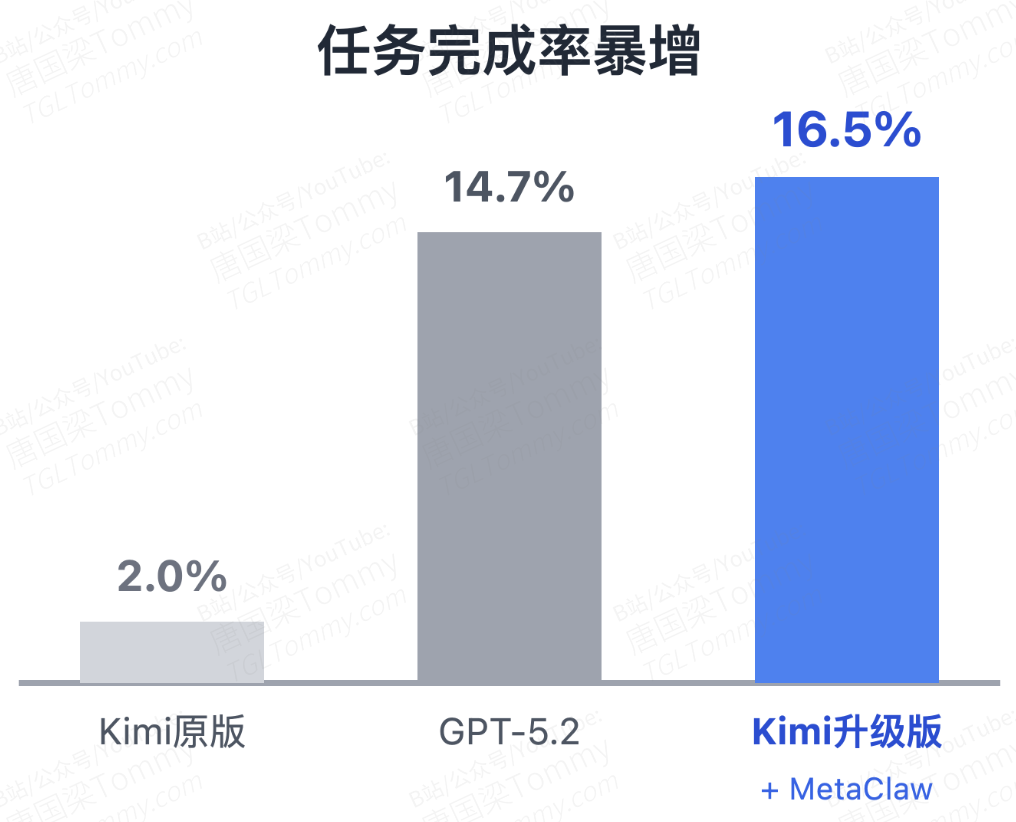
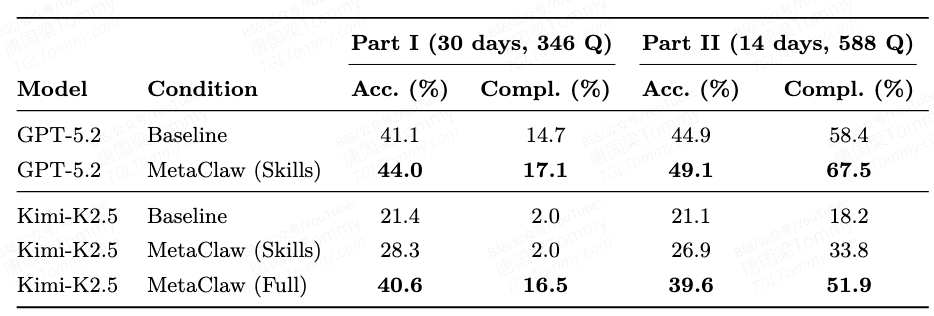
在 MetaClaw-Bench(包含 44 个模拟工作日、非平稳难度递增的评测基准)的实验中,数据的表现非常具有说服力。对于像 Kimi-K2.5 这样初始能力稍弱的基座模型,单纯的技能注入能提升选择题准确率,但无法解决复杂的文件执行任务。而一旦开启完整的 MetaClaw 飞轮,Kimi-K2.5 的端到端任务完成率暴增了 8.25 倍(从 2.0% 飙升至 16.5%),综合准确率达到 40.6%,几乎追平了未经适应的 GPT-5.2 基线(41.1%)。
这揭示了一个对工业界极具吸引力的事实:即使你因为成本或合规限制只能部署一个二线开源模型,只要赋予它良好的持续进化机制,它完全能在垂直场景的日常交互中“长”成一个专家。
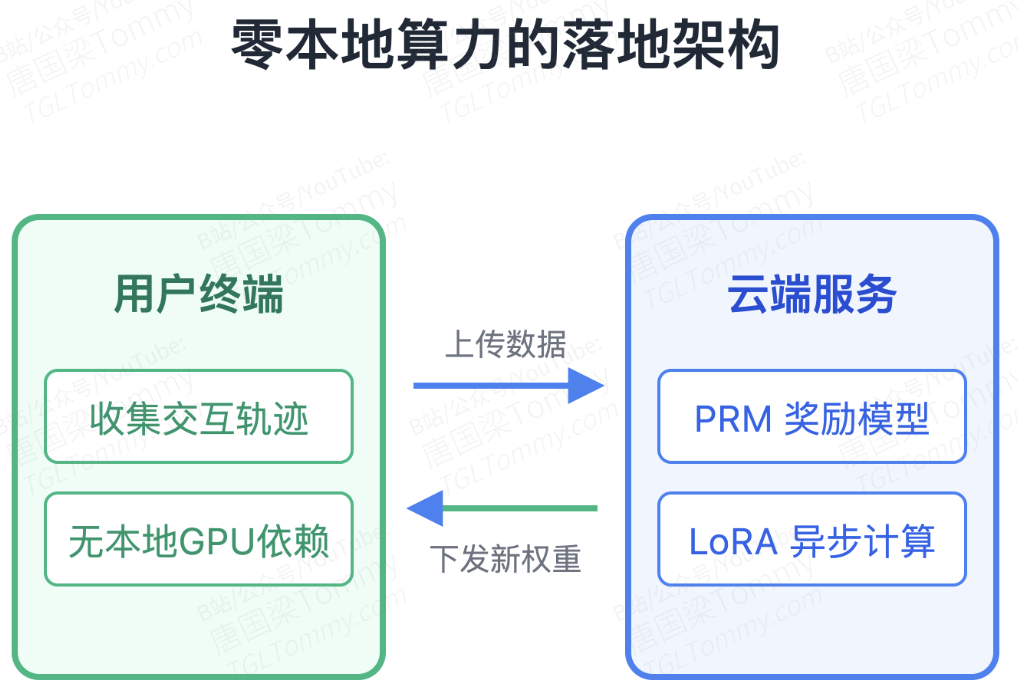
Agent-as-a-Service 的理想架构与潜在隐患
MetaClaw 给出了一套极其务实的 Agent 落地架构,它无需本地 GPU,通过代理服务和 Cloud LoRA 就实现了闭环。对于正在做 AI 助理或数字员工的从业者来说,这种“闲时异步 RL + 实时 Prompt 迭代”的设计思路非常值得借鉴。
然而,值得注意的是它的适用边界。MetaClaw 的慢更新飞轮高度依赖一个强大且准确的过程奖励模型(PRM)。在 CLI 命令、代码生成这类有明确对错的结构化场景中,PRM 很容易通过自动化脚本或规则构建;但如果面对的是主观性极强的开放域任务(如文案撰写、创意设计),如何获取高质量的奖励信号将成为瓶颈。此外,如果用户任务分布的漂移速度过快,RL 缓冲区可能永远攒不够同一技能版本下的高质量 Query 数据,导致权重更新跟不上场景的变化。这也是后续持续学习 Agent 亟待解决的下一个痛点。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号