Agentic RAG:给传统 RAG 装个 "智能导航",专治各种 "超纲提问

Agentic RAG:给传统 RAG 装个 "智能导航",专治各种 "超纲提问

HELLO程序员
发布于 2026-06-26 21:13:52
发布于 2026-06-26 21:13:52
先来个灵魂类比
记得七年级英语考试那事儿不?有道题超纲了,全班都慌了。考完大家找老师求情,老师居然给这题算分了 —— 简直白捡分,爽翻!
但现实世界哪有这好事?做 RAG(检索增强生成)系统时,用户总会问些 "超纲题",也就是知识库压根没覆盖的内容。总不能堵着用户的嘴不让问吧?
这时候就得搞个 Agentic RAG 系统 —— 它能认出问题是不是超纲,还能自己去搜网页、查资料,给个靠谱答案。
啥是 RAG?先唠唠基础
检索增强生成(RAG)把信息检索和大模型的优点捏一块儿,直接颠覆了 AI 应用的玩法。
传统 RAG 里,模型不会把整个大数据集塞给 LLM,而是根据用户问题,从外部知识库或文档库里扒最相关的信息(上下文),再把这些内容给 LLM,让它生成有依据、贴上下文的回答。
RAG 好不好用,主要看两点:速度和准头。
这俩都受嵌入维度、索引方式、系统架构复杂度这些因素影响。
今儿咱就聊聊 Agentic RAG 这个新兴架构,跟传统(或者说 "原味")RAG 比比看,再用代码实操一把,看看差别在哪儿。
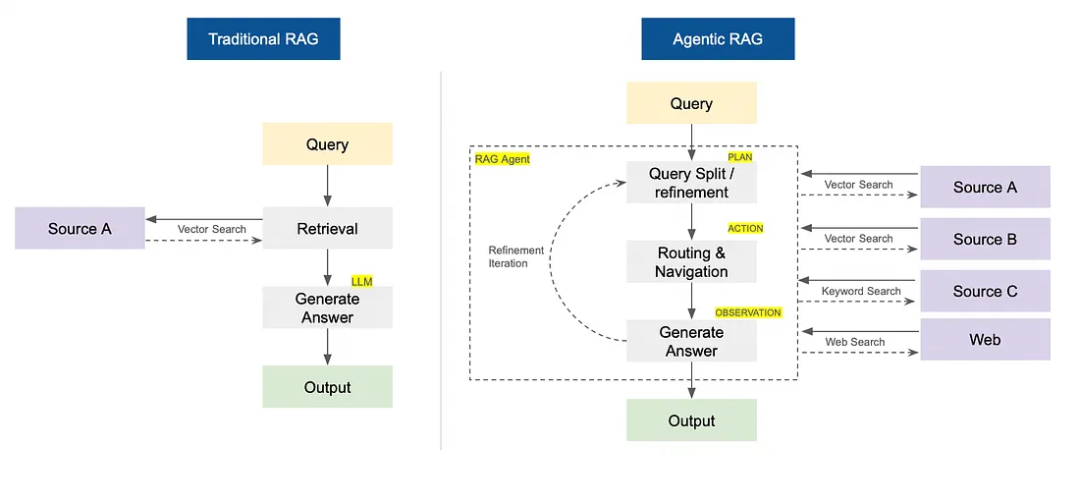
传统 RAG vs Agentic RAG:差在哪儿?
传统 RAG 就是固定的 "先检索再生成" 流程 —— 从指定源扒点信息就回答,一根筋到底。
Agentic RAG 则是让 AI 智能体自己做主:决定搜啥、咋搜、啥时候搜、从哪儿搜(比如网页、向量数据库)。它会规划多步搜索,实时调整查询方式,一步步迭代出更好的答案。
传统 RAG 啥时候掉链子?
传统 RAG 在需要灵活应变、跨多个知识库深度推理的场景里,直接歇菜。主要坑点在这儿:
- 单次检索定生死只搜一回,多步推理和深层上下文关联全漏了;
- 搜错信息 + 瞎编找着语义相似但上下文完全不对的内容,结果净是事实错误;
- 死板不会变通不会根据用户意图、反馈或变化的上下文动态调整检索策略;
- 扩展能力拉胯受限于上下文窗口,大规模数据聚合能力差,计算开销还贼高。
得了,咱现在就用 LangGraph、ChromaDB 和 SerperAPI(网页搜索)整一个 Agentic RAG 玩玩。
问题来了:咋解决?
需求:咋设计一个检索增强生成系统,能动态选最合适的知识库,验证搜来的信息靠不靠谱,还能在医疗、医疗器械这种高风险领域生成有依据、贴上下文的回答?
方案:整一个 Agentic RAG 流水线 —— 让轻量级的路由智能体从多个检索源(问答数据集、设备手册、网页搜索)里选,先检查搜来的上下文相关不相关,再用 LLM 生成答案。这招比传统 RAG 更准、更灵活、更靠谱。
技术栈
Python、LangGraph、LangChain、Chroma DB、SerperAPI(网页搜索)、OpenAI API(LLM)
先把要用的模块导进来
import pandas as pd
import numpy as np
import json
import re
from typing import List, Dict, Any, Tuple
import faiss
from sentence_transformers import SentenceTransformer
from openai import OpenAI
import time
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
import seaborn as sns
from dotenv import load_dotenv
import openai
import os
from langchain_community.utilities import GoogleSerperAPIWrapper
# ✅ 加载环境变量
load_dotenv()
openai_api_key = os.getenv("OPEN_AI_KEY")
SERPER_API_KEY = os.getenv("SERPER_API_KEY")加载数据
实验用了俩 CSV 数据集(都采样到 500 行,跑起来快):
医疗问答数据集
一个全乎的医疗问答数据集。咱采样 500 行,把每行拼成一个combined_text字段,格式是:问题:…… 答案:…… 类型:……。
## 数据1:读取医疗问答数据集
df_qa = pd.read_csv("medical_q_n_a.csv")
## 数据本来有16407行,咱采样500行做实验
df_qa = df_qa.sample(500, random_state=0).reset_index(drop=True)
print(df_qa.shape)
df_qa.head()
# 给向量数据库准备数据:把文本拼一块儿
df_qa['combined_text'] = (
"问题:" + df_qa['Question'].astype(str) + "。" +
"答案:" + df_qa['Answer'].astype(str) + "。" +
"类型:" + df_qa['qtype'].astype(str) + "。"
)
df_qa.head()
医疗器械手册数据集
里面是医疗器械手册和元数据。同样采样 500 行,拼成combined_text:设备名称:…… 型号:…… 厂商:…… 适用范围:…… 禁忌:……。
## 数据2:读取医疗器械手册数据集
df_medical_device = pd.read_csv("medical_device_manuals_dataset.csv")
print(df_medical_device.shape)
## 数据本来有2694行,采样500行做实验
df_medical_device = df_medical_device.sample(500, random_state=0).reset_index(drop=True)
print(df_medical_device.shape)
# 给向量数据库准备数据:把文本拼一块儿
df_medical_device['combined_text'] = (
"设备名称:" + df_medical_device['Device_Name'].astype(str) + "。" +
"型号:" + df_medical_device['Model_Number'].astype(str) + "。" +
"厂商:" + df_medical_device['Manufacturer'].astype(str) + "。" +
"适用范围:" + df_medical_device['Indications_for_Use'].astype(str) + "。" +
"禁忌:" + df_medical_device['Contraindications'].fillna('无').astype(str)
)
df_medical_device.head()
搭向量数据库(Chroma DB)
创建 ChromaDB 客户端
用 chromadb 库整个客户端:
import chromadb
# 配置ChromaDB
client = chromadb.PersistentClient(path="./chroma_db")创建集合
咱整俩集合,一个存设备手册数据集,一个存问答数据集。
你可以把集合想成数据库里的表,每个数据源对应一张表。
集合 1:医疗问答数据集
创建 "medical_q_n_a" 集合,把数据塞进去:
# 医疗问答数据集的集合
collection1 = client.get_or_create_collection(name="medical_q_n_a")
# 往集合里加数据
# 这里ChromaDB会用默认的嵌入模型(sentence transformers)
collection1.add(
documents=df_qa['combined_text'].tolist(),
metadatas=df_qa.to_dict(orient="records"),
ids=df_qa.index.astype(str).tolist(),
)
# 快速测试下
query = "川崎病的治疗方法有哪些?"
results = collection1.query(query_texts=[query],
n_results=3
)
print(results)输出:
{'ids': [['1', '393', '60']],
'embeddings': None,
'documents': [["问题:川崎病的治疗方法有哪些?。答案:这些资源介绍了川崎病的诊断或治疗: - 辛辛那提儿童医院医疗中心 - 基因检测登记处:急性发热性黏膜皮肤淋巴结综合征 - 美国国家心肺血液研究所:川崎病如何治疗? MedlinePlus的这些资源提供了各种健康状况的诊断和治疗信息: - 诊断测试 - 药物治疗 - 手术和康复 - 遗传咨询 - 姑息治疗。类型:治疗。 ",
'问题:克拉伯病的治疗方法有哪些?。答案:克拉伯病目前无法治愈。一项针对婴儿期克拉伯病儿童的小型临床试验结果显示,在症状出现前接受无关供体脐带血干细胞的儿童,神经损伤很小。骨髓移植可能对部分人有帮助。一般来说,这种疾病的治疗是对症和支持性的。物理治疗可能有助于维持或增加肌肉张力和血液循环。类型:治疗。 ',
'问题:早衰型埃勒斯-当洛斯综合征的治疗方法有哪些?。答案:早衰型埃勒斯-当洛斯综合征如何治疗?早衰型埃勒斯-当洛斯综合征患者可根据症状从多种治疗中获益。肌肉张力弱、发育迟缓的患病儿童可从物理治疗中获益,以提高肌肉力量和协调性。关节疼痛的患者可从抗炎药中获益。可能建议改变生活方式或在运动或剧烈体力活动时采取预防措施,以减少皮肤和骨骼受伤的机会。建议患者与医疗保健提供者讨论治疗方案。类型:治疗。 ']],
'uris': None,
'included': ['metadatas', 'documents', 'distances'],
'data': None,
'metadatas': [[{'qtype': 'treatment',
'combined_text': "问题:川崎病的治疗方法有哪些?。答案:这些资源介绍了川崎病的诊断或治疗: - 辛辛那提儿童医院医疗中心 - 基因检测登记处:急性发热性黏膜皮肤淋巴结综合征 - 美国国家心肺血液研究所:川崎病如何治疗? MedlinePlus的这些资源提供了各种健康状况的诊断和治疗信息: - 诊断测试 - 药物治疗 - 手术和康复 - 遗传咨询 - 姑息治疗。类型:治疗。 ",
'Answer': "这些资源介绍了川崎病的诊断或治疗: - 辛辛那提儿童医院医疗中心 - 基因检测登记处:急性发热性黏膜皮肤淋巴结综合征 - 美国国家心肺血液研究所:川崎病如何治疗? MedlinePlus的这些资源提供了各种健康状况的诊断和治疗信息: - 诊断测试 - 药物治疗 - 手术和康复 - 遗传咨询 - 姑息治疗",
'Question': '川崎病的治疗方法有哪些?'},
{'qtype': 'treatment',
'combined_text': '问题:克拉伯病的治疗方法有哪些?。答案:克拉伯病目前无法治愈。一项针对婴儿期克拉伯病儿童的小型临床试验结果显示,在症状出现前接受无关供体脐带血干细胞的儿童,神经损伤很小。骨髓移植可能对部分人有帮助。一般来说,这种疾病的治疗是对症和支持性的。物理治疗可能有助于维持或增加肌肉张力和血液循环。类型:治疗。 ',
'Answer': '克拉伯病目前无法治愈。一项针对婴儿期克拉伯病儿童的小型临床试验结果显示,在症状出现前接受无关供体脐带血干细胞的儿童,神经损伤很小。骨髓移植可能对部分人有帮助。一般来说,这种疾病的治疗是对症和支持性的。物理治疗可能有助于维持或增加肌肉张力和血液循环。',
'Question': '克拉伯病的治疗方法有哪些?'},
{'Question': '早衰型埃勒斯-当洛斯综合征的治疗方法有哪些?',
'qtype': 'treatment',
'Answer': '早衰型埃勒斯-当洛斯综合征如何治疗?早衰型埃勒斯-当洛斯综合征患者可根据症状从多种治疗中获益。肌肉张力弱、发育迟缓的患病儿童可从物理治疗中获益,以提高肌肉力量和协调性。关节疼痛的患者可从抗炎药中获益。可能建议改变生活方式或在运动或剧烈体力活动时采取预防措施,以减少皮肤和骨骼受伤的机会。建议患者与医疗保健提供者讨论治疗方案。',
'combined_text': '问题:早衰型埃勒斯-当洛斯综合征的治疗方法有哪些?。答案:早衰型埃勒斯-当洛斯综合征如何治疗?早衰型埃勒斯-当洛斯综合征患者可根据症状从多种治疗中获益。肌肉张力弱、发育迟缓的患病儿童可从物理治疗中获益,以提高肌肉力量和协调性。关节疼痛的患者可从抗炎药中获益。可能建议改变生活方式或在运动或剧烈体力活动时采取预防措施,以减少皮肤和骨骼受伤的机会。建议患者与医疗保健提供者讨论治疗方案。类型:治疗。 '}]],
'distances': [[0.4760013818740845, 0.9692587852478027, 1.0237324237823486]]}集合 2:医疗器械手册数据集
创建 "medical_device_manual" 集合,塞数据:
collection2 = client.get_or_create_collection(name="medical_device_manual")
# 往集合里加数据
# 这里ChromaDB会用默认的嵌入模型(sentence transformers)
collection2.add(
documents=df_medical_device['combined_text'].tolist(),
metadatas=df_medical_device.to_dict(orient="records"),
ids=df_medical_device.index.astype(str).tolist(),
)
# 快速测试下
query = "哪些设备适合新生儿患者使用?"
results = collection2.query(query_texts=[query],
n_results=5
)
print(results)输出:
{
"ids": [["218", "149", "235"]],
"embeddings": null,
"documents": [["设备名称:起搏器。型号:JOH663。厂商:强生。适用范围:专为新生儿重症监护环境中的导管插入术支持设计。禁忌:避免用于装有心脏设备或人工耳蜗的患者。不适用于化学暴露区域。",
"设备名称:输液泵。型号:Model 7800。厂商:直觉外科。适用范围:专为新生儿重症监护环境中的关节置换支持设计。禁忌:不建议用于老年患者或肝功能不全者。",
"设备名称:麻醉机。型号:STR623。厂商:史赛克。适用范围:专为新生儿重症监护环境中的组织活检支持设计。禁忌:不得与镇静剂或氧疗方式联合使用。"]],
"uris": null,
"included": ["metadatas", "documents", "distances"],
"data": null,
"metadatas": [[{"Manufacturer": "强生", "Number_of_Cautions": 10, "Model_Number": "JOH663", "combined_text": "设备名称:起搏器。型号:JOH663。厂商:强生。适用范围:专为新生儿重症监护环境中的导管插入术支持设计。禁忌:避免用于装有心脏设备或人工耳蜗的患者。不适用于化学暴露区域。", "Indications_for_Use": "专为新生儿重症监护环境中的导管插入术支持设计。", "Device_Name": "起搏器", "Manual_Version": "2021-01-A", "Device_Class": "II类", "Number_of_Warnings": 10, "Sterilization_Method": "不适用", "Device_Weight_kg": 0.06, "Publication_Date": "2023-09-27", "Regulatory_Approval_ID": "H148086", "Patient_Population": "成人(18-65岁)", "Contraindications": "避免用于装有心脏设备或人工耳蜗的患者。不适用于化学暴露区域。", "Max_Operating_Temperature_C": 39.0},
{"Device_Class": "IIb类", "Indications_for_Use": "专为新生儿重症监护环境中的关节置换支持设计。", "Device_Lifetime_Years": 12.0, "Device_Name": "输液泵", "Max_Operating_Temperature_C": 31.0, "Manual_Version": "2020-05-S", "Model_Number": "Model 7800", "Number_of_Warnings": 8, "Manufacturer": "直觉外科", "Sterilization_Method": "干热灭菌", "Contraindications": "不建议用于老年患者或肝功能不全者。", "Device_Weight_kg": 2.83, "Patient_Population": "成人和儿科", "Number_of_Cautions": 18, "combined_text": "设备名称:输液泵。型号:Model 7800。厂商:直觉外科。适用范围:专为新生儿重症监护环境中的关节置换支持设计。禁忌:不建议用于老年患者或肝功能不全者。", "Regulatory_Approval_ID": "PMDA-473669", "Publication_Date": "2024-01-21"},
{"Max_Operating_Temperature_C": 31.0, "combined_text": "设备名称:麻醉机。型号:STR623。厂商:史赛克。适用范围:专为新生儿重症监护环境中的组织活检支持设计。禁忌:不得与镇静剂或氧疗方式联合使用。", "Manual_Version": "Rev. 5.6", "Number_of_Cautions": 17, "Publication_Date": "2017-09-04", "Contraindications": "不得与镇静剂或氧疗方式联合使用。", "Regulatory_Approval_ID": "BLA811783", "Sterilization_Method": "不适用", "Patient_Population": "老年", "Number_of_Warnings": 16, "Device_Name": "麻醉机", "Device_Weight_kg": 51.65, "Device_Class": "I类", "Indications_for_Use": "专为新生儿重症监护环境中的组织活检支持设计。", "Manufacturer": "史赛克", "Model_Number": "STR623", "Device_Lifetime_Years": 14.0}]],
"distances": [[1.0503746271133423, 1.0830397605895996, 1.0891238451004028]]
}配置网页搜索 API
咱用 SerperAPI 做网页搜索(谷歌搜索),免费额度有 2500 次网页搜索 API 调用,1-2 秒就能返回谷歌搜索结果。
from langchain_community.utilities import GoogleSerperAPIWrapper
from dotenv import load_dotenv
load_dotenv()
SERPER_API_KEY = os.getenv("SERPER_API_KEY")
search = GoogleSerperAPIWrapper()
# 测试谷歌搜索API
search.run(query="COVID-19的各类疫苗有哪些")输出:
"不同类型的COVID-19疫苗:工作原理 · mRNA疫苗 · mRNA疫苗 · 信使RNA(mRNA)疫苗 · 病毒载体疫苗 · 病毒载体疫苗 ... 2020年12月首次推出的辉瑞和Moderna原始COVID mRNA疫苗对原始SARS-CoV-2病毒有保护作用 ... 目前,美国使用的COVID-19疫苗有两种类型:mRNA和蛋白亚单位疫苗。这些疫苗都不能 ... 本页面提供信息图表,解释不同类型的疫苗如何工作,包括辉瑞/BioNTech疫苗、Moderna疫苗和 ... COVID-19疫苗类型。美国推荐使用的COVID-19疫苗有两种类型:mRNA疫苗。Moderna COVID-19疫苗 ... COVID-19疫苗授权列表 · 目录 · 概述地图 · 牛津-阿斯利康 · 辉瑞-BioNTech · 强生 · Moderna · 国药集团北京生物制品研究所 · 卫星V。世卫组织建议大多数COVID-19疫苗采用简化的单剂基础免疫方案,这将提高接受度和接种率,并提供 ... 查找有关COVID-19疫苗的信息和问题答案,包括预约、儿童接种、加强针、额外剂量、记录等。加利福尼亚州公共卫生部致力于优化加利福尼亚人的健康和福祉。了解COVID-19疫苗的工作原理、需要多少剂、可能的副作用以及谁不应该接种疫苗。"配置 OpenAI API 客户端
咱这次实验用 Open AI API 的 gpt-5-nano 模型。
选这个模型是因为实验规模小、复杂度低,提示词也简单。实际场景里,你可能得用更高级的模型(gpt-5-mini /gpt-5)。
代码在这儿:
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
openai_api_key = os.getenv("OPEN_AI_KEY")
def get_llm_response(prompt: str) -> str:
"""获取LLM响应的函数"""
from openai import OpenAI
client_llm = OpenAI(api_key=openai_api_key)
response = client_llm.chat.completions.create(
model="gpt-5-nano",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
## 测试LLM响应
prompt = "用30个字简单解释相对论"
response = get_llm_response(prompt)
print(response)输出:
相对论认为物理定律对观察者适用,无优选参考系,光速不可超越。时空随运动和引力弯曲,质能本质等价。环境都配好了,咱开始整 RAG 吧。先基于第一个源(医疗问答)搞个传统 RAG,再升级到 Agentic RAG。
简单 RAG:代码实现
这个简单 RAG 的流程是:
查询 → 检索 → 构建提示词(增强) → 生成
用 LangGraph 的 StateGraph 实现,分三个节点(步骤):
- 检索器对medical_q_n_a集合做相似度查询,把最相关的文档拼成一个上下文字符串;
- 提示词构建器整一个简单的 RAG 提示词,把检索到的上下文和用户问题嵌进去,还加了长度限制;
- LLM调用get_llm_response(prompt),把模型输出存到工作流状态里。
from typing import Literal
from langgraph.graph import StateGraph,MessagesState, START, END
from openai import OpenAI
from typing_extensions import TypedDict
from typing import List
# === 定义工作流节点函数 ===
def retrieve_context(state):
"""根据查询从ChromaDB检索最相关的文档"""
print("---检索上下文---")
query = state["query"] # 最后一条用户消息
results = collection1.query(query_texts=[query], n_results=3)
context = "\n".join(results["documents"][0])
#state
["query"] = query
state["context"] = context
print(context)
# 把上下文存到状态里,供后续节点用
return state
def build_prompt(state):
"""构建RAG风格的提示词"""
print("---增强(构建提示词)---")
query = state["query"]
context = state["context"]
prompt = f"""
根据下面的上下文回答问题。
上下文:
{context}
问题:{query}
回答限制在50字以内。
"""
state["prompt"] = prompt
print(prompt)
return state
def call_llm(state):
"""调用现有的LLM函数"""
print("---生成(调用LLM)---")
prompt = state["prompt"]
answer = get_llm_response(prompt)
state["response"] = answer
return state
# === 构建工作流 ===
## 定义状态结构
class GraphState(TypedDict):
query : str
prompt : str
context : List[str]
response : str
workflow = StateGraph(GraphState)
# 添加节点
workflow.add_node("Retriever", retrieve_context)
workflow.add_node("Augment", build_prompt)
workflow.add_node("Generate", call_llm)
# 定义边
workflow.add_edge(START, "Retriever")
workflow.add_edge("Retriever", "Augment")
workflow.add_edge("Augment", "Generate")
workflow.add_edge("Generate", END)
# 编译智能体
rag_agent = workflow.compile()
# === 运行 ===
from IPython.display import Image, display
display(Image(rag_agent.get_graph().draw_mermaid_png()))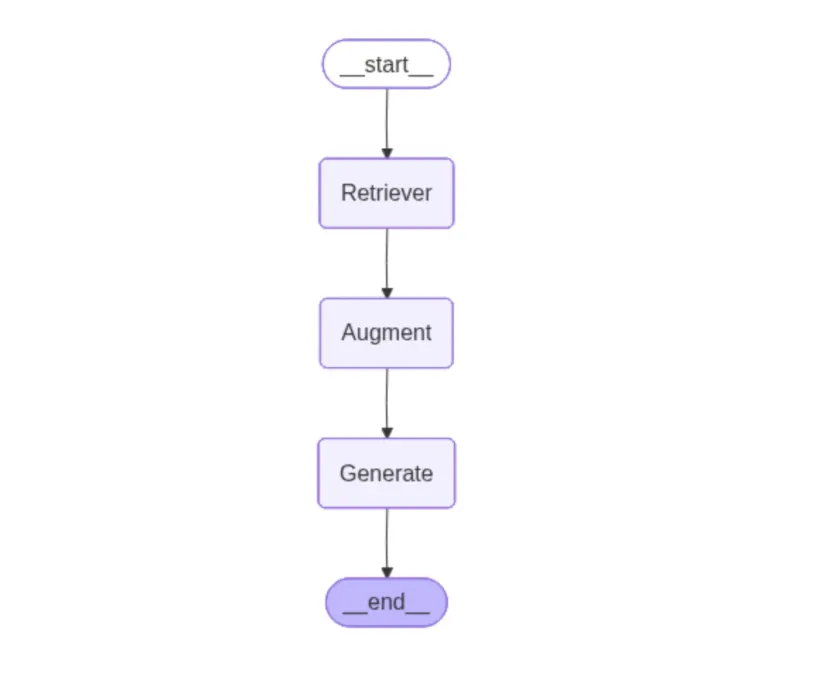
测试简单 RAG:
input_state = {"query": "川崎病的治疗方法有哪些?"}
from pprint import pprint
for step in rag_agent.stream(input_state):
for key, value in step.items():
pprint(f"完成运行:{key}:")
pprint(value["response"])输出:
---检索上下文---
问题:川崎病的治疗方法有哪些?。答案:这些资源介绍了川崎病的诊断或治疗: - 辛辛那提儿童医院医疗中心 - 基因检测登记处:急性发热性黏膜皮肤淋巴结综合征 - 美国国家心肺血液研究所:川崎病如何治疗? MedlinePlus的这些资源提供了各种健康状况的诊断和治疗信息: - 诊断测试 - 药物治疗 - 手术和康复 - 遗传咨询 - 姑息治疗。类型:治疗。
问题:克拉伯病的治疗方法有哪些?。答案:克拉伯病目前无法治愈。一项针对婴儿期克拉伯病儿童的小型临床试验结果显示,在症状出现前接受无关供体脐带血干细胞的儿童,神经损伤很小。骨髓移植可能对部分人有帮助。一般来说,这种疾病的治疗是对症和支持性的。物理治疗可能有助于维持或增加肌肉张力和血液循环。类型:治疗。
问题:早衰型埃勒斯-当洛斯综合征的治疗方法有哪些?。答案:早衰型埃勒斯-当洛斯综合征如何治疗?早衰型埃勒斯-当洛斯综合征患者可根据症状从多种治疗中获益。肌肉张力弱、发育迟缓的患病儿童可从物理治疗中获益,以提高肌肉力量和协调性。关节疼痛的患者可从抗炎药中获益。可能建议改变生活方式或在运动或剧烈体力活动时采取预防措施,以减少皮肤和骨骼受伤的机会。建议患者与医疗保健提供者讨论治疗方案。类型:治疗。
'完成运行:Retriever:'
---增强(构建提示词)---
根据下面的上下文回答问题。
上下文:
问题:川崎病的治疗方法有哪些?。答案:这些资源介绍了川崎病的诊断或治疗: - 辛辛那提儿童医院医疗中心 - 基因检测登记处:急性发热性黏膜皮肤淋巴结综合征 - 美国国家心肺血液研究所:川崎病如何治疗? MedlinePlus的这些资源提供了各种健康状况的诊断和治疗信息: - 诊断测试 - 药物治疗 - 手术和康复 - 遗传咨询 - 姑息治疗。类型:治疗。
问题:克拉伯病的治疗方法有哪些?。答案:克拉伯病目前无法治愈。一项针对婴儿期克拉伯病儿童的小型临床试验结果显示,在症状出现前接受无关供体脐带血干细胞的儿童,神经损伤很小。骨髓移植可能对部分人有帮助。一般来说,这种疾病的治疗是对症和支持性的。物理治疗可能有助于维持或增加肌肉张力和血液循环。类型:治疗。
问题:早衰型埃勒斯-当洛斯综合征的治疗方法有哪些?。答案:早衰型埃勒斯-当洛斯综合征如何治疗?早衰型埃勒斯-当洛斯综合征患者可根据症状从多种治疗中获益。肌肉张力弱、发育迟缓的患病儿童可从物理治疗中获益,以提高肌肉力量和协调性。关节疼痛的患者可从抗炎药中获益。可能建议改变生活方式或在运动或剧烈体力活动时采取预防措施,以减少皮肤和骨骼受伤的机会。建议患者与医疗保健提供者讨论治疗方案。类型:治疗。
问题:川崎病的治疗方法有哪些?
回答限制在50字以内。
'完成运行:Augment:'
---生成(调用LLM)---
'完成运行:Generate:'
('川崎病主要用静脉注射免疫球蛋白(IVIG)和大剂量阿司匹林治疗,以减轻炎症、预防冠状动脉瘤。若发热复发或IVIG耐药,可考虑重复IVIG、激素等;需定期超声心动图监测。')是不是简单又直接?但要是有人问超纲问题咋办?!
没错,这系统直接歇菜。
别急,咱有 Agentic RAG 当救星呢。
Agentic RAG:代码实现
核心思路:不再死磕同一个检索器,而是用轻量级的路由智能体,从多个检索选项里选,还能验证搜来的上下文相关不相关。
流程是这样的:
查询 → 路由器(选数据源) → 检索 → 相关性检查 → 相关:生成;不相关:网页搜索 → 结束
用 LangGraph 的 StateGraph 节点实现,条件判断用 "conditional_edge"。
关键节点在这儿:
- 路由器节点整一个简短的决策提示词,让 LLM 返回三个标签之一:Retrieve_QnA、Retrieve_Device或Web_Search;
- 检索器节点一个查问答 Chroma 集合,一个查设备手册 Chroma 集合,还有一个调用网页搜索 API。每个节点都返回上下文字符串,还会设个source标签;
- 相关性检查器让 LLM 判断搜来的上下文相关不相关(回答只能是Yes或No);
- 条件路由要是相关,就继续构建提示词、调用 LLM;要是不相关,就 fallback 到Web_Search,再检查一遍相关性;流程最多迭代 3 次。
Agentic 流程把这些节点拼成带条件边的 StateGraph。
from typing import Literal
from langgraph.graph import StateGraph,MessagesState, START, END
from openai import OpenAI
from typing_extensions import TypedDict
from typing import List
# === 定义工作流节点函数 ===
def retrieve_context_q_n_a(state):
"""从ChromaDB集合1(医疗问答数据)检索最相关的文档"""
print("---检索上下文---")
query = state["query"] # 最后一条用户消息
results = collection1.query(query_texts=[query], n_results=3)
context = "\n".join(results["documents"][0])
state["context"] = context
state["source"] = "医疗问答集合"
print(context)
# 把上下文存到状态里,供后续节点用
return state
# === 定义工作流节点函数 ===
def retrieve_context_medical_device(state):
"""从ChromaDB集合2(医疗器械手册数据)检索最相关的文档"""
print("---检索上下文---")
query = state["query"] # 最后一条用户消息
results = collection2.query(query_texts=[query], n_results=3)
context = "\n".join(results["documents"][0])
state["context"] = context
state["source"] = "医疗器械手册"
print(context)
# 把上下文存到状态里,供后续节点用
return state
def web_search(state):
"""用谷歌Serper API做网页搜索"""
print("---执行网页搜索---")
query = state["query"]
search_results = search.run(query=query)
state["context"] = search_results
state["source"] = "网页搜索"
print(search_results)
return state
def router(state: GraphState) -> Literal[
"Retrieve_QnA", "Retrieve_Device", "Web_Search"
]:
"""Agentic路由器:决定用哪种检索方式"""
query = state["query"]
# 轻量级决策LLM——你可以换成GPT-4o-mini之类的
decision_prompt = f"""
你是一个路由智能体。根据用户查询,决定去哪儿找信息。
选项:
- Retrieve_QnA:如果是关于一般医疗知识、症状或治疗的问题;
- Retrieve_Device:如果是关于医疗器械、手册或使用说明的问题;
- Web_Search:如果是关于近期新闻、品牌名称或外部数据的问题。
查询:"{query}"
只返回以下选项之一:Retrieve_QnA, Retrieve_Device, Web_Search
"""
router_decision = get_llm_response(decision_prompt).strip()
print(f"---路由器决策:{router_decision}---")
print(router_decision)
state["source"] = router_decision
return state
# 定义条件边的路由函数
def route_decision(state: GraphState) -> str:
return state["source"]
def build_prompt(state):
"""构建RAG风格的提示词"""
print("---增强(构建生成提示词)---")
query = state["query"]
context = state["context"]
prompt = f"""
根据下面的上下文回答问题。
上下文:
{context}
问题:{query}
回答限制在50字以内。
"""
state["prompt"] = prompt
print(prompt)
return state
def call_llm(state):
"""调用现有的LLM函数"""
print("---生成(调用LLM)---")
prompt = state["prompt"]
answer = get_llm_response(prompt)
state["response"] = answer
return state
def check_context_relevance(state):
"""判断检索到的上下文是否相关"""
print("---上下文相关性检查器---")
query = state["query"]
context = state["context"]
relevance_prompt = f"""
检查下面的上下文是否与用户查询相关。
####
上下文:
{context}
####
用户查询:{query}
选项:
- Yes:如果上下文相关;
- No:如果上下文不相关。
只回答'Yes'或'No'。
"""
relevance_decision_value = get_llm_response(relevance_prompt).strip()
print(f"---相关性决策:{relevance_decision_value}---")
state["is_relevant"] = relevance_decision_value
return state
# 定义条件边的check_context_relevance函数
def relevance_decision(state: GraphState) -> str:
iteration_count = state.get("iteration_count", 0)
iteration_count += 1
state["iteration_count"] = iteration_count
## 最多迭代3次
if iteration_count >= 3:
print("---达到最大迭代次数,强制返回'Yes'---")
state["is_relevant"] = "Yes"
return state["is_relevant"]
# === 构建工作流 ===
## 定义状态结构
class GraphState(TypedDict):
query: str
context: str
prompt: str
response: str
source: str # 使用的检索器/工具
is_relevant: str
iteration_count: int
workflow = StateGraph(GraphState)
# 添加节点
workflow.add_node("Router", router)
workflow.add_node("Retrieve_QnA", retrieve_context_q_n_a)
workflow.add_node("Retrieve_Device", retrieve_context_medical_device)
workflow.add_node("Web_Search", web_search)
workflow.add_node("Relevance_Checker", check_context_relevance)
workflow.add_node("Augment", build_prompt)
workflow.add_node("Generate", call_llm)
# 定义边
workflow.add_edge(START, "Router")
workflow.add_conditional_edges(
"Router",
route_decision, # 这个函数动态决定路径
{
"Retrieve_QnA": "Retrieve_QnA",
"Retrieve_Device": "Retrieve_Device",
"Web_Search": "Web_Search",
}
)
workflow.add_edge("Retrieve_QnA", "Relevance_Checker")
workflow.add_edge("Retrieve_Device", "Relevance_Checker")
workflow.add_edge("Web_Search", "Relevance_Checker")
workflow.add_conditional_edges(
"Relevance_Checker",
relevance_decision, # 这个函数动态决定路径
{
"Yes": "Augment",
"No": "Web_Search",
}
)
workflow.add_edge("Augment", "Generate")
workflow.add_edge("Generate", END)
# 编译动态RAG智能体
agentic_rag = workflow.compile()
# ===================================
# === 可视化工作流(可选)===
# ===================================
# === 运行 ===
from IPython.display import Image, display
display(Image(agentic_rag.get_graph().draw_mermaid_png()))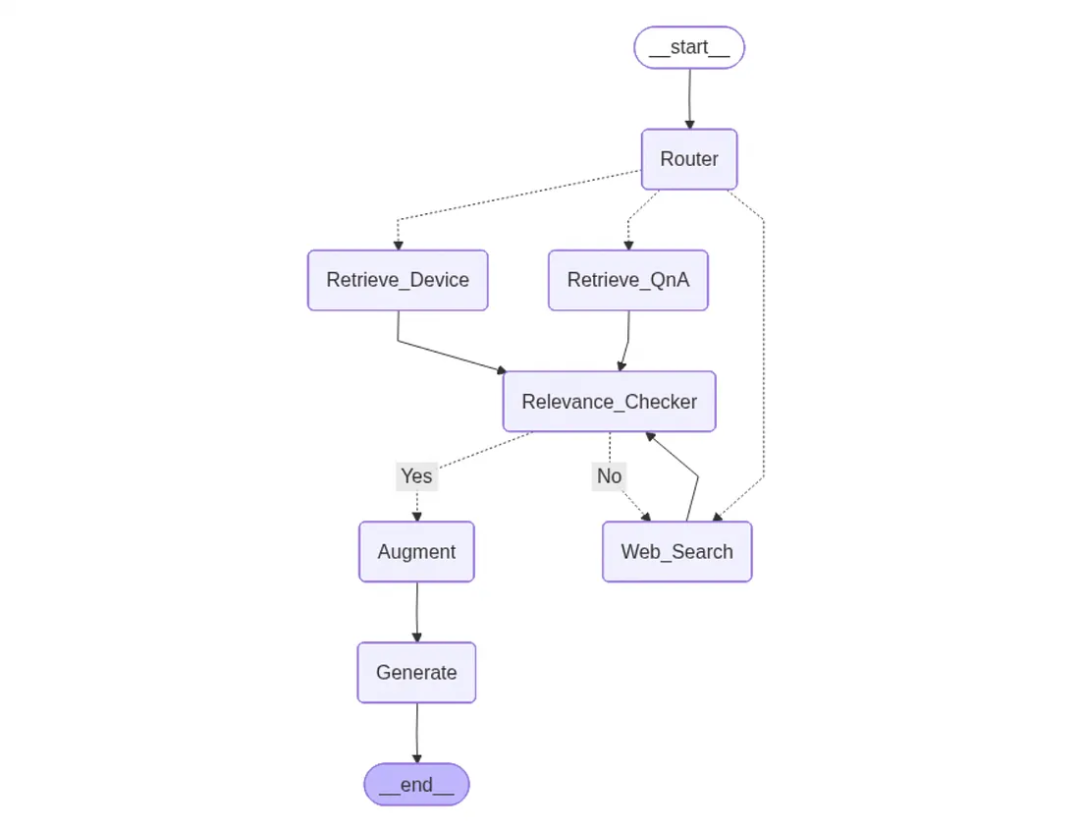
测试 1:(医疗问答数据集相关问题)
input_state = {"query": "川崎病的治疗方法有哪些?"}
from pprint import pprint
for step in agentic_rag.stream(input_state):
for key, value in step.items():
pprint(f"完成运行:{key}:")
pprint(value["response"])输出:
---路由器决策:Retrieve_QnA---
Retrieve_QnA
'完成运行:Router:'
---检索上下文---
问题:川崎病的治疗方法有哪些?。答案:这些资源介绍了川崎病的诊断或治疗: - 辛辛那提儿童医院医疗中心 - 基因检测登记处:急性发热性黏膜皮肤淋巴结综合征 - 美国国家心肺血液研究所:川崎病如何治疗? MedlinePlus的这些资源提供了各种健康状况的诊断和治疗信息: - 诊断测试 - 药物治疗 - 手术和康复 - 遗传咨询 - 姑息治疗。类型:治疗。
问题:克拉伯病的治疗方法有哪些?。答案:克拉伯病目前无法治愈。一项针对婴儿期克拉伯病儿童的小型临床试验结果显示,在症状出现前接受无关供体脐带血干细胞的儿童,神经损伤很小。骨髓移植可能对部分人有帮助。一般来说,这种疾病的治疗是对症和支持性的。物理治疗可能有助于维持或增加肌肉张力和血液循环。类型:治疗。
问题:早衰型埃勒斯-当洛斯综合征的治疗方法有哪些?。答案:早衰型埃勒斯-当洛斯综合征如何治疗?早衰型埃勒斯-当洛斯综合征患者可根据症状从多种治疗中获益。肌肉张力弱、发育迟缓的患病儿童可从物理治疗中获益,以提高肌肉力量和协调性。关节疼痛的患者可从抗炎药中获益。可能建议改变生活方式或在运动或剧烈体力活动时采取预防措施,以减少皮肤和骨骼受伤的机会。建议患者与医疗保健提供者讨论治疗方案。类型:治疗。
'完成运行:Retrieve_QnA:'
---上下文相关性检查器---
---相关性决策:Yes---
'完成运行:Relevance_Checker:'
---增强(构建生成提示词)---
根据下面的上下文回答问题。
上下文:
问题:川崎病的治疗方法有哪些?。答案:这些资源介绍了川崎病的诊断或治疗: - 辛辛那提儿童医院医疗中心 - 基因检测登记处:急性发热性黏膜皮肤淋巴结综合征 - 美国国家心肺血液研究所:川崎病如何治疗? MedlinePlus的这些资源提供了各种健康状况的诊断和治疗信息: - 诊断测试 - 药物治疗 - 手术和康复 - 遗传咨询 - 姑息治疗。类型:治疗。
问题:克拉伯病的治疗方法有哪些?。答案:克拉伯病目前无法治愈。一项针对婴儿期克拉伯病儿童的小型临床试验结果显示,在症状出现前接受无关供体脐带血干细胞的儿童,神经损伤很小。骨髓移植可能对部分人有帮助。一般来说,这种疾病的治疗是对症和支持性的。物理治疗可能有助于维持或增加肌肉张力和血液循环。类型:治疗。
问题:早衰型埃勒斯-当洛斯综合征的治疗方法有哪些?。答案:早衰型埃勒斯-当洛斯综合征如何治疗?早衰型埃勒斯-当洛斯综合征患者可根据症状从多种治疗中获益。肌肉张力弱、发育迟缓的患病儿童可从物理治疗中获益,以提高肌肉力量和协调性。关节疼痛的患者可从抗炎药中获益。可能建议改变生活方式或在运动或剧烈体力活动时采取预防措施,以减少皮肤和骨骼受伤的机会。建议患者与医疗保健提供者讨论治疗方案。类型:治疗。
问题:川崎病的治疗方法有哪些?
回答限制在50字以内。
'完成运行:Augment:'
---生成(调用LLM)---
'完成运行:Generate:'
('川崎病首选静脉注射免疫球蛋白(IVIG)单次输注,急性期联用大剂量阿司匹林抗炎、防冠脉受累;后续小剂量阿司匹林维持数周至数月,定期超声心动图监测心脏,IVIG耐药时需追加治疗。')测试 2:(医疗器械手册数据集相关问题)
input_state = {"query": "透析机设备的用途有哪些?"}
from pprint import pprint
for step in agentic_rag.stream(input_state):
for key, value in step.items():
pprint(f"完成运行:{key}:")
pprint(value["response"])输出:
---路由器决策:Retrieve_Device---
Retrieve_Device
'完成运行:Router:'
---检索上下文---
设备名称:透析机。型号:Model 1703。厂商:爱德华兹生命科学。适用范围:用于复杂肿瘤手术中的术中测量监测。禁忌:不建议用于外周血管疾病患者或开放伤口部位。
设备名称:透析机。型号:Plus593。厂商:西门子医疗。适用范围:用于需要即时护理的急性糖尿病情况下的紧急组织活检。禁忌:无
设备名称:透析机。型号:Max384。厂商:生物梅里埃。适用范围:专为老年护理机构的老年患者设计的持续监测辅助。禁忌:避免用于心肌病患者或接受放射性物质的患者。
'完成运行:Retrieve_Device:'
---上下文相关性检查器---
---相关性决策:Yes---
'完成运行:Relevance_Checker:'
---增强(构建生成提示词)---
根据下面的上下文回答问题。
上下文:
设备名称:透析机。型号:Model 1703。厂商:爱德华兹生命科学。适用范围:用于复杂肿瘤手术中的术中测量监测。禁忌:不建议用于外周血管疾病患者或开放伤口部位。
设备名称:透析机。型号:Plus593。厂商:西门子医疗。适用范围:用于需要即时护理的急性糖尿病情况下的紧急组织活检。禁忌:无
设备名称:透析机。型号:Max384。厂商:生物梅里埃。适用范围:专为老年护理机构的老年患者设计的持续监测辅助。禁忌:避免用于心肌病患者或接受放射性物质的患者。
问题:透析机设备的用途有哪些?
回答限制在50字以内。
'完成运行:Augment:'
---生成(调用LLM)---
'完成运行:Generate:'
('透析机设备用途:\n'
'- Model 1703(爱德华兹生命科学):复杂肿瘤手术术中测量监测;\n'
'- Model Plus593(西门子医疗):急性糖尿病紧急组织活检;\n'
'- Model Max384(生物梅里埃):老年护理机构患者持续监测辅助。')测试 3:(需要网页搜索的超纲问题)
input_state = {"query": "2025年美国对印度医疗片剂的出口关税是多少?"}
from pprint import pprint
for step in agentic_rag.stream(input_state):
for key, value in step.items():
pprint(f"完成运行:{key}:")
pprint(value["response"])输出:
---路由器决策:Web_Search---
Web_Search
'完成运行:Router:'
---执行网页搜索---
以下是对印度出口到美国的药品征收100%关税可能意味着什么的详细分析——对印度制药行业而言…… DGCI&S统计数据显示,2025财年印度对美药品制剂出口达98亿美元,占其总出口的39.8%…… 从2025年8月27日起,美国对印度的关税将提高到50%,是特朗普政府时期最严厉的措施之一。特朗普已对印度进口商品征收50%的关税,其中还包括对继续购买……的25%“惩罚性”关税。美国于2025年8月29日终止了800美元的小额免税豁免。了解新的进口规则如何影响处方药…… 美国总统唐纳德·特朗普周四宣布,名牌或专利药品将从……开始征收100%的关税。据估计,2025财年这一数字将达到8501.1亿卢比。2024年印度制药出口收入的三分之一来自美国,达300亿美元…… 100%的进口税将使印度药品的竞争力大幅下降,可能导致市场份额流失、销售额下降和利润率萎缩。美国总统唐纳德·特朗普周四宣布,名牌或专利药品将从……开始征收100%的关税。2024年印度向美国出口了36亿美元(3162.6亿卢比)的药品,2025年又出口了37亿美元(3250.5亿卢比)……
'完成运行:Web_Search:'
---上下文相关性检查器---
---相关性决策:Yes---
'完成运行:Relevance_Checker:'
---构建提示词---
根据下面的上下文回答问题。
上下文:
以下是对印度出口到美国的药品征收100%关税可能意味着什么的详细分析——对印度制药行业而言…… DGCI&S统计数据显示,2025财年印度对美药品制剂出口达98亿美元,占其总出口的39.8%…… 从2025年8月27日起,美国对印度的关税将提高到50%,是特朗普政府时期最严厉的措施之一。特朗普已对印度进口商品征收50%的关税,其中还包括对继续购买……的25%“惩罚性”关税。美国于2025年8月29日终止了800美元的小额免税豁免。了解新的进口规则如何影响处方药…… 美国总统唐纳德·特朗普周四宣布,名牌或专利药品将从……开始征收100%的关税。据估计,2025财年这一数字将达到8501.1亿卢比。2024年印度制药出口收入的三分之一来自美国,达300亿美元…… 100%的进口税将使印度药品的竞争力大幅下降,可能导致市场份额流失、销售额下降和利润率萎缩。美国总统唐纳德·特朗普周四宣布,名牌或专利药品将从……开始征收100%的关税。2024年印度向美国出口了36亿美元(3162.6亿卢比)的药品,2025年又出口了37亿美元(3250.5亿卢比)……
问题:2025年美国对印度医疗片剂的出口关税是多少?
回答限制在50字以内。
'完成运行:PromptBuilder:'
---调用LLM---
'完成运行:LLM:'
('100%关税。上下文显示,2025年美国对印度药品(包括专利/名牌药品)征收100%关税。')测试 4:(陷阱问题 —— 看似属于问答数据集,实则不在其中)
这里 RAG 智能体一开始以为问题属于问答数据集,但发现检索到的内容不相关后,就跑去调用网页搜索 API 了。
input_state = {"query": "COVID的药物/治疗方法有哪些?"}
from pprint import pprint
for step in agentic_rag.stream(input_state):
for key, value in step.items():
pprint(f"完成运行:{key}:")
pprint(value["response"])输出:
---路由器决策:Retrieve_QnA---
Retrieve_QnA
'完成运行:Router:'
---检索上下文---
问题:棘阿米巴-肉芽肿性阿米巴脑炎(GAE);角膜炎的治疗方法有哪些?。答案:棘阿米巴角膜炎的有效治疗关键在于早期诊断。有几种处方眼药水可用于治疗。然而,这种感染可能难以治疗。每位患者的最佳治疗方案应由眼科医生确定。如果您怀疑您的眼睛可能感染了棘阿米巴,请立即去看眼科医生。
由棘阿米巴引起但未扩散到中枢神经系统的皮肤感染可以成功治疗。由于这是一种严重的感染,而且受影响的人通常免疫系统较弱,早期诊断提供了最好的治愈机会。
大多数大脑和脊髓感染棘阿米巴(肉芽肿性阿米巴脑炎)的病例是致命的。类型:治疗。
问题:结节病的治疗方法有哪些?。答案:结节病有哪些治疗方法?结节病的治疗取决于:出现的症状症状的严重程度是否有重要器官(例如,您的肺、眼睛、心脏或大脑)受到影响器官如何受到影响。有些器官必须治疗,无论您的症状如何。其他可能不需要治疗。通常,如果患者没有症状,他或她不需要治疗,可能会及时康复。目前,最常用的治疗结节病的药物是泼尼松。 当患者服用泼尼松时病情恶化或泼尼松的副作用对患者严重时,医生可能会开其他药物。这些其他药物大多通过抑制免疫系统来减轻炎症。这些其他药物包括:羟氯喹(羟氯喹)、甲氨蝶呤、硫唑嘌呤(依木兰)和环磷酰胺(环磷酰胺)。研究人员继续寻找新的和更好的结节病治疗方法。抗肿瘤坏死因子药物和抗生素目前正在研究中。有关结节病治疗的更多详细信息,可以在以下链接找到:https://www.stopsarcoidosis.org/awareness/treatment-options/ http://emedicine.medscape.com/article/301914-treatment
#showall
。类型:治疗。
问题:CADASIL的治疗方法有哪些?。答案:没有治疗可以阻止这种遗传疾病。为个人提供支持性护理。偏头痛可能通过不同的药物治疗,每日服用阿司匹林可能降低中风和心脏病发作的风险。可以给予抑郁症的药物治疗。受影响的吸烟个体应该戒烟,因为它会增加CADASIL中风的风险。其他中风风险因素,如高血压、高脂血症、糖尿病、凝血障碍和阻塞性睡眠呼吸暂停也应积极治疗……类型:治疗。
'完成运行:Retrieve_QnA:'
---上下文相关性检查器---
---相关性决策:No---
'完成运行:Relevance_Checker:'
---执行网页搜索---
FDA已授权或批准几种抗病毒药物用于治疗可能病情加重的轻中度COVID-19患者。这些药物可防止轻症恶化。它们可包括奈玛特韦/利托那韦(Paxlovid)、瑞德西韦(Veklury)或莫努匹韦…… 为COVID-19最高风险人群提供的治疗方法有:奈玛特韦加利托那韦和莫努匹韦…… 服用非处方药,如对乙酰氨基酚或布洛芬。这些可用于退烧或治疗头痛、喉咙痛或身体疼痛。授权用于治疗COVID-19的口服抗病毒药物 · Paxlovid · Lagevrio(也称为莫努匹韦)。这些药物阻止病毒…… 作者:SS Jean · 2020 · 引用94次 ——瑞德西韦、替考拉宁、羟氯喹(不与阿奇霉素联用)和伊维菌素可能是有效的抗病毒药物,被认为有前景…… 口服抗病毒药是一种口服药片,用于治疗某些人的COVID-19。它们仅可凭处方获得。口服…… PAXLOVID是一种处方药,用于治疗有进展为重症COVID‑19高风险的成人轻中度冠状病毒病2019(COVID‑19)…… 对于某些COVID-19住院成人,FDA也批准了Olumiant(巴瑞替尼)和Actemra(托珠单抗)。在某些情况下…… PaxlovidQuizMolnupiravirRemdesivirHospital medicationsPreventative medicationsCurrently unavailablePipeline medications ...
'完成运行:Web_Search:'
---上下文相关性检查器---
---相关性决策:Yes---
'完成运行:Relevance_Checker:'
---构建提示词---
根据下面的上下文回答问题。
上下文:
FDA已授权或批准几种抗病毒药物用于治疗可能病情加重的轻中度COVID-19患者。这些药物可防止轻症恶化。它们可包括奈玛特韦/利托那韦(Paxlovid)、瑞德西韦(Veklury)或莫努匹韦…… 为COVID-19最高风险人群提供的治疗方法有:奈玛特韦加利托那韦和莫努匹韦…… 服用非处方药,如对乙酰氨基酚或布洛芬。这些可用于退烧或治疗头痛、喉咙痛或身体疼痛。授权用于治疗COVID-19的口服抗病毒药物 · Paxlovid · Lagevrio(也称为莫努匹韦)。这些药物阻止病毒…… 作者:SS Jean · 2020 · 引用94次 ——瑞德西韦、替考拉宁、羟氯喹(不与阿奇霉素联用)和伊维菌素可能是有效的抗病毒药物,被认为有前景…… 口服抗病毒药是一种口服药片,用于治疗某些人的COVID-19。它们仅可凭处方获得。口服…… PAXLOVID是一种处方药,用于治疗有进展为重症COVID‑19高风险的成人轻中度冠状病毒病2019(COVID‑19)…… 对于某些COVID-19住院成人,FDA也批准了Olumiant(巴瑞替尼)和Actemra(托珠单抗)。在某些情况下…… PaxlovidQuizMolnupiravirRemdesivirHospital medicationsPreventative medicationsCurrently unavailablePipeline medications ...
问题:COVID的药物/治疗方法有哪些?
回答限制在50字以内。
'完成运行:PromptBuilder:'
---调用LLM---
'完成运行:LLM:'
('药物包括口服抗病毒药Paxlovid(奈玛特韦-利托那韦)、Lagevrio(莫努匹韦);静脉抗病毒药瑞德西韦;部分住院患者可用巴瑞替尼(Olumiant)、托珠单抗(Actemra)。非处方退烧药/止痛药可缓解症状。')最后唠两句
这篇文章实操性拉满,聚焦医疗内容的 RAG 和 Agentic RAG 实验。展示了一个小小的路由智能体和条件工作流,就能让 RAG 系统更灵活、更懂上下文,还能控制迭代成本。
Agentic RAG 是传统 RAG 的升级版 —— 加了一层推理和决策能力,让检索流程更会变通、更懂上下文。
就算用轻量级工具和小数据集,也能设计出智能路由查询、验证结果、生成有依据且可审计答案的系统 —— 这可是打造靠谱 AI 的关键一步。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号