
空间与SparkSQL/Python在Synapse火花池使用apache?
提问于 2022-05-04 03:35:20
我想在大型数据集上运行空间查询;例如,地质公园太慢了。我在这里发现的灵感:https://anant-sharma.medium.com/apache-sedona-geospark-using-pyspark-e60485318fbe
在我准备的火花池Synapse分析(通过Azure门户):
Apache火花池/设置/包/需求文件:
requirement.txt:
azure-storage-file-share
geopandas
apache-sedona/ Settings / Packages / Workspace包:
geotools-wrapper-geotools-24.1.jar
sedona-sql-3.0_2.12-1.2.0-incubating.jarApache火花池/设置/包/火花配置
config.txt:
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.kryo.registrator org.apache.sedona.core.serde.SedonaKryoRegistrator在电火花笔记本里
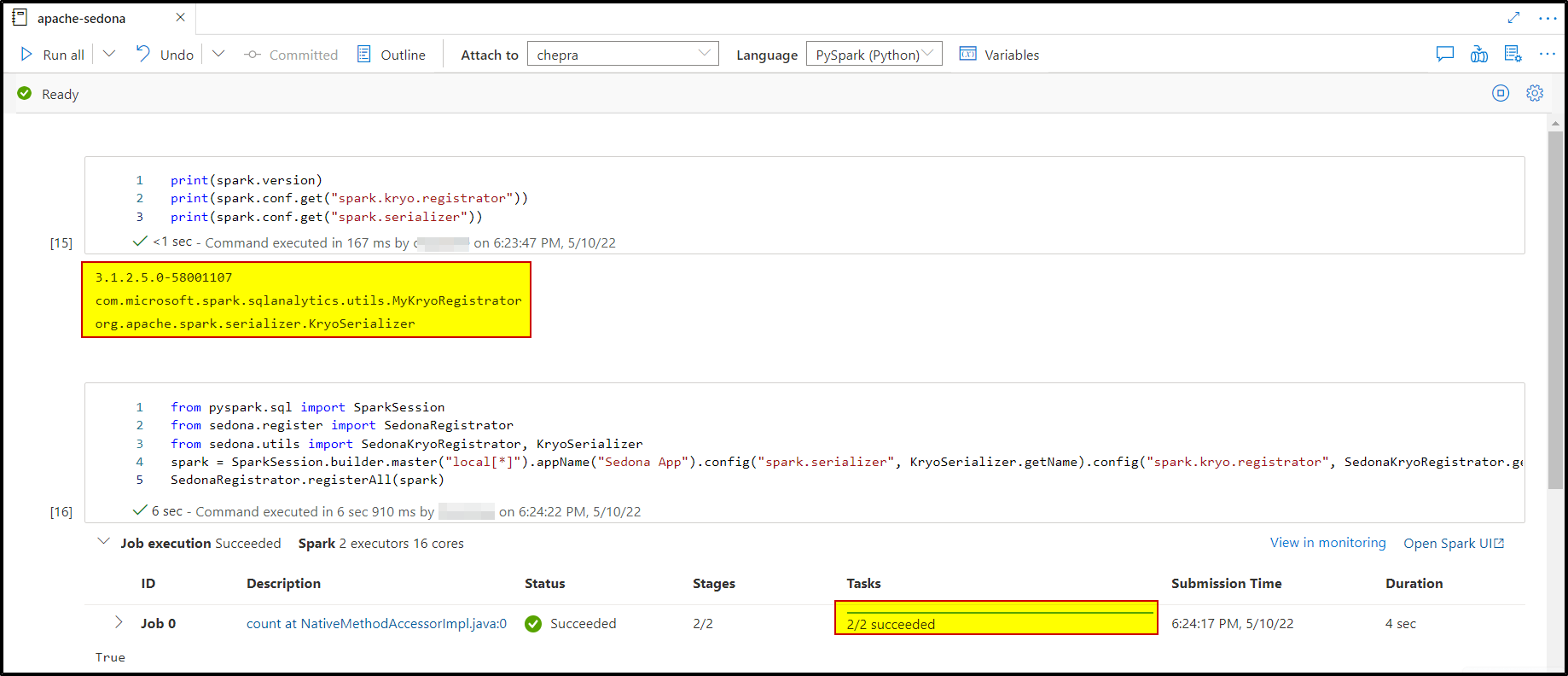
print(spark.version)
print(spark.conf.get("spark.kryo.registrator"))
print(spark.conf.get("spark.serializer"))产出如下:
3.1.2.5.0-58001107
org.apache.sedona.core.serde.SedonaKryoRegistrator
org.apache.spark.serializer.KryoSerializer然后我试着:
from pyspark.sql import SparkSession
from sedona.register import SedonaRegistrator
from sedona.utils import SedonaKryoRegistrator, KryoSerializer
spark = SparkSession.builder.master("local[*]").appName("Sedona App").config("spark.serializer", KryoSerializer.getName).config("spark.kryo.registrator", SedonaKryoRegistrator.getName).getOrCreate()
SedonaRegistrator.registerAll(spark)但是它失败了: Py4JJavaError:调用o636.count时发生了错误。:org.apache.spark.SparkException:由于阶段失败而中止作业:任务序列化失败: org.apache.spark.SparkException:未能向Kryo注册类
只要简单地检查一下是否正确安装了这些东西,就可能允许这样做:
%%sql
SELECT ST_Point(0,0);请帮助将空间函数注册到Synapse笔记本!中运行

回答 1
Stack Overflow用户
发布于 2022-05-11 02:12:23
根据我的报告,我能够成功地运行上面的命令,没有任何问题。
我刚刚安装了包含requirement.txt的apache-sedona文件,并下载了以下两个jar文件:
注意:不需要config.txt文件。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72112285
复制








腾讯云开发者
