同时检查多个分类列的值
同时检查多个分类列的值
提问于 2021-01-17 03:09:06
我有多个分类列,如婚姻状况、教育、性别、城市和我想一次检查这些列中的所有唯一值,而不是每次都编写这段代码。
df['Education'].value_counts()我只能给出几个特性的例子,但是当有那么多分类特性并且不可能一次又一次地编写代码来检查它们时,我需要一个解决方案。
Maritial_Status Education City
Married UG LA
Single PHD CA
Single UG Ca预期产出:
Maritial_Status Education City
Married 1 UG 2 LA 1
Single 2 PHD 1 CA 2在Python中有什么方法可以做到这一点吗?谢谢
回答 3
Stack Overflow用户
回答已采纳
发布于 2021-01-17 03:38:49
是的,您可以使用以下方法获得所需的数据(此外,您也不必担心df的数据是否比指定的4列更多):
- 从
df获取(仅)list中的所有分类列
cat_cols = [i for i in df.columns if df[i].dtypes == 'O']- 然后,在分类列上对分组对象运行一个执行
loop的.size(),并将每个结果(即df对象)存储在一个空的list中。
li = []
for col in cat_cols:
li.append(df.groupby([col]).size().reset_index(name=col+'_count'))- 最后,将列表中新创建的
concat转换为1。
dat = pd.concat(li,axis=1)全在1块中
cat_cols = [i for i in df.columns if df[i].dtypes == 'O']
li = []
for col in cat_cols:
li.append(df.groupby([col]).size().reset_index(name=col+'_count'))
dat = pd.concat(li,axis=1)# use axis=1, so that the concatenation is column-wise
Marital Status Marital Status_count ... City City_count
0 Divorced 4.0 ... Athens 4
1 Married 3.0 ... Berlin 2
2 Single 3.0 ... London 2
3 Widowed 2.0 ... New York 2
4 NaN NaN ... Singapore 2Stack Overflow用户
发布于 2021-01-17 03:41:43
使用value_counts,您可以执行以下操作
res = (df
.apply(lambda x: x.value_counts()) # column by column value_counts would be applied
.stack()
.reset_index(level=0).sort_index(axis=0)
.rename(columns={'level_0': 'Value', 0: 'value_counts'}))
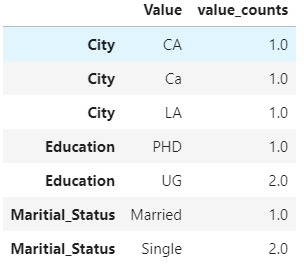
输出的另一种格式:
res['Id'] = res.groupby(level=0).cumcount()
res.set_index('Id', append=True)
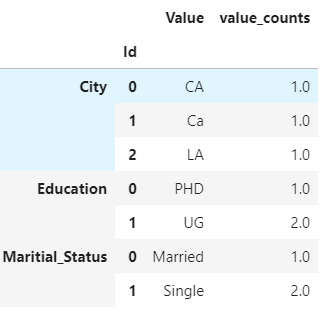
解释:
应用value_counts之后,您将得到以下内容:
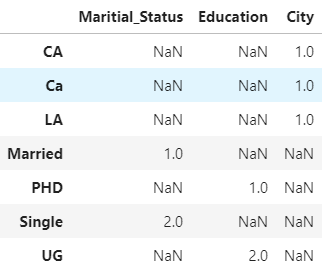
然后使用堆栈,您可以删除NAN并将所有东西“堆叠起来”,然后您可以对输出进行格式化/排序。
Stack Overflow用户
发布于 2021-01-17 03:18:03
要知道每个列有多少重复的唯一值,可以尝试drop_duplicates()方法:
dataset.drop_duplicates()页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65759870
复制






相似问题
如何同时对多个分类列进行编码
Postgresql:检查列是否同时等于多个值的最佳方法
同时替换分类列和数字列中缺少的值
检查多个列值
极性:在保持分类类型的同时将分类列设置为特定值
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
