Elasticsearch索引红色状态
Elasticsearch索引红色状态
提问于 2020-10-30 00:24:29
在我的集群中,一切都很好,今天我发现我没有数据包记录,碎片的健康状况是红色的:
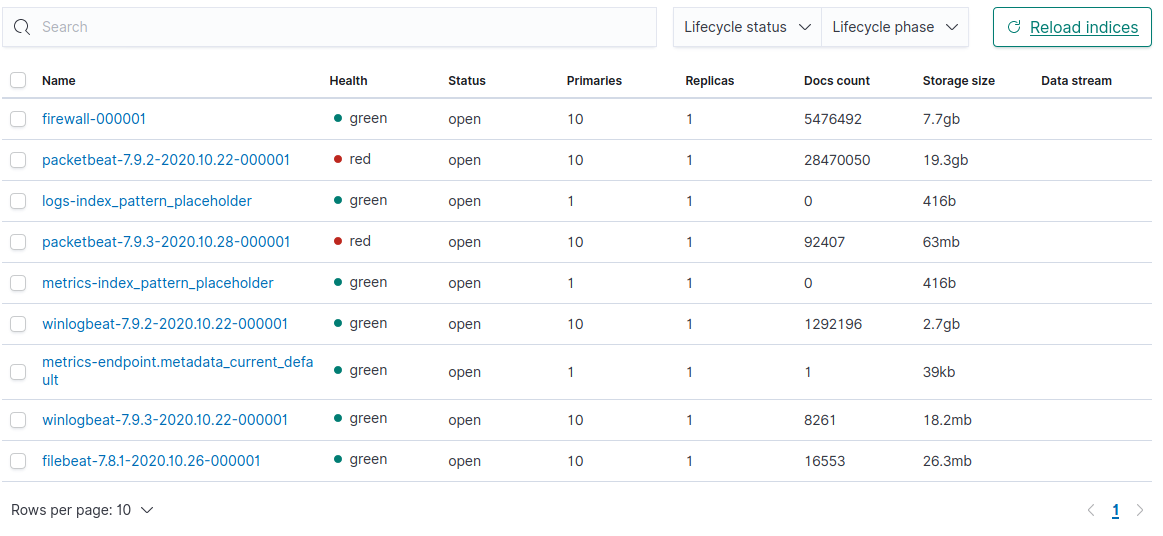
当我运行GET _cat/shards时,我会得到这样的信息:
packetbeat-7.9.3-2020.10.28-000001 2 p STARTED 11428 3.8mb 10.13.81.12 VSELK-MASTER-02
packetbeat-7.9.3-2020.10.28-000001 2 r STARTED 11428 3.8mb 10.13.81.13 VSELK-MASTER-03
packetbeat-7.9.3-2020.10.28-000001 9 r STARTED 11402 3.8mb 10.13.81.12 VSELK-MASTER-02
packetbeat-7.9.3-2020.10.28-000001 9 p STARTED 11402 3.8mb 10.13.81.21 VSELK-DATA-01
packetbeat-7.9.3-2020.10.28-000001 4 p STARTED 11619 4mb 10.13.81.21 VSELK-DATA-01
packetbeat-7.9.3-2020.10.28-000001 4 r STARTED 11619 3.9mb 10.13.81.22 VSELK-DATA-02
packetbeat-7.9.3-2020.10.28-000001 5 r STARTED 11567 3.8mb 10.13.81.21 VSELK-DATA-01
packetbeat-7.9.3-2020.10.28-000001 5 p STARTED 11567 3.9mb 10.13.81.22 VSELK-DATA-02
packetbeat-7.9.3-2020.10.28-000001 1 r STARTED 11553 3.8mb 10.13.81.11 VSELK-MASTER-01
packetbeat-7.9.3-2020.10.28-000001 1 p STARTED 11553 3.9mb 10.13.81.22 VSELK-DATA-02
packetbeat-7.9.3-2020.10.28-000001 7 r UNASSIGNED
packetbeat-7.9.3-2020.10.28-000001 7 p UNASSIGNED
packetbeat-7.9.3-2020.10.28-000001 6 r UNASSIGNED
packetbeat-7.9.3-2020.10.28-000001 6 p UNASSIGNED
packetbeat-7.9.3-2020.10.28-000001 8 r STARTED 11630 4mb 10.13.81.12 VSELK-MASTER-02
packetbeat-7.9.3-2020.10.28-000001 8 p STARTED 11630 3.9mb 10.13.81.21 VSELK-DATA-01
packetbeat-7.9.3-2020.10.28-000001 3 p STARTED 11495 4mb 10.13.81.12 VSELK-MASTER-02
packetbeat-7.9.3-2020.10.28-000001 3 r STARTED 11495 3.7mb 10.13.81.13 VSELK-MASTER-03
packetbeat-7.9.3-2020.10.28-000001 0 r STARTED 11713 4mb 10.13.81.11 VSELK-MASTER-01
packetbeat-7.9.3-2020.10.28-000001 0 p STARTED 11713 4mb 10.13.81.22 VSELK-DATA-02当我运行时,我得到: get /_群集/分配/解释
{
"index" : "packetbeat-7.9.2-2020.10.22-000001",
"shard" : 6,
"primary" : true,
"current_state" : "unassigned",
"unassigned_info" : {
"reason" : "ALLOCATION_FAILED",
"at" : "2020-10-28T13:22:03.006Z",
"failed_allocation_attempts" : 5,
"details" : """failed shard on node [RCeMt0uXQie_ax_Sp22hLw]: failed to create shard, failure java.io.IOException: failed to obtain in-memory shard lock
at org.elasticsearch.index.IndexService.createShard(IndexService.java:489)
at org.elasticsearch.indices.IndicesService.createShard(IndicesService.java:763)
at org.elasticsearch.indices.IndicesService.createShard(IndicesService.java:176)
at org.elasticsearch.indices.cluster.IndicesClusterStateService.createShard(IndicesClusterStateService.java:607)
at org.elasticsearch.indices.cluster.IndicesClusterStateService.createOrUpdateShards(IndicesClusterStateService.java:584)
at org.elasticsearch.indices.cluster.IndicesClusterStateService.applyClusterState(IndicesClusterStateService.java:242)
at org.elasticsearch.cluster.service.ClusterApplierService.callClusterStateAppliers(ClusterApplierService.java:504)
at org.elasticsearch.cluster.service.ClusterApplierService.callClusterStateAppliers(ClusterApplierService.java:494)
at org.elasticsearch.cluster.service.ClusterApplierService.applyChanges(ClusterApplierService.java:471)
at org.elasticsearch.cluster.service.ClusterApplierService.runTask(ClusterApplierService.java:418)
at org.elasticsearch.cluster.service.ClusterApplierService$UpdateTask.run(ClusterApplierService.java:162)
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:674)
at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.runAndClean(PrioritizedEsThreadPoolExecutor.java:252)
at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.run(PrioritizedEsThreadPoolExecutor.java:215)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1130)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630)
at java.lang.Thread.run(Thread.java:832)
Caused by: [packetbeat-7.9.2-2020.10.22-000001/RRAnRZrrRZiihscJ3bymig][[packetbeat-7.9.2-2020.10.22-000001][6]] org.elasticsearch.env.ShardLockObtainFailedException: [packetbeat-7.9.2-2020.10.22-000001][6]: obtaining shard lock for [starting shard] timed out after [5000ms], lock already held for [closing shard] with age [199852ms]
at org.elasticsearch.env.NodeEnvironment$InternalShardLock.acquire(NodeEnvironment.java:869)
at org.elasticsearch.env.NodeEnvironment.shardLock(NodeEnvironment.java:775)
at org.elasticsearch.index.IndexService.createShard(IndexService.java:409)
... 16 more
""",
"last_allocation_status" : "no"
},
"can_allocate" : "no",
"allocate_explanation" : "cannot allocate because allocation is not permitted to any of the nodes that hold an in-sync shard copy",
"node_allocation_decisions" : [
{
"node_id" : "A_nOoYrdSSOAHNQrhfveNA",
"node_name" : "VSELK-DATA-02",
"transport_address" : "10.13.81.22:9300",
"node_attributes" : {
"ml.machine_memory" : "8365424640",
"ml.max_open_jobs" : "20",
"xpack.installed" : "true",
"data" : "cold",
"transform.node" : "true"
},
"node_decision" : "no",
"store" : {
"found" : false
}
},
{
"node_id" : "RCeMt0uXQie_ax_Sp22hLw",
"node_name" : "VSELK-MASTER-03",
"transport_address" : "10.13.81.13:9300",
"node_attributes" : {
"ml.machine_memory" : "8365068288",
"ml.max_open_jobs" : "20",
"xpack.installed" : "true",
"data" : "hot",
"transform.node" : "true"
},
"node_decision" : "no",
"store" : {
"in_sync" : true,
"allocation_id" : "nMvn4c4vQp2efQQtIeKzlg"
},
"deciders" : [
{
"decider" : "max_retry",
"decision" : "NO",
"explanation" : """shard has exceeded the maximum number of retries [5] on failed allocation attempts - manually call [/_cluster/reroute?retry_failed=true] to retry, [unassigned_info[[reason=ALLOCATION_FAILED], at[2020-10-28T13:22:03.006Z], failed_attempts[5], failed_nodes[[hHHRtd5HTCKJgLTBtgDbOw, RCeMt0uXQie_ax_Sp22hLw]], delayed=false, details[failed shard on node [RCeMt0uXQie_ax_Sp22hLw]: failed to create shard, failure java.io.IOException: failed to obtain in-memory shard lock
at org.elasticsearch.index.IndexService.createShard(IndexService.java:489)
at org.elasticsearch.indices.IndicesService.createShard(IndicesService.java:763)
at org.elasticsearch.indices.IndicesService.createShard(IndicesService.java:176)
at org.elasticsearch.indices.cluster.IndicesClusterStateService.createShard(IndicesClusterStateService.java:607)
at org.elasticsearch.indices.cluster.IndicesClusterStateService.createOrUpdateShards(IndicesClusterStateService.java:584)
at org.elasticsearch.indices.cluster.IndicesClusterStateService.applyClusterState(IndicesClusterStateService.java:242)
at org.elasticsearch.cluster.service.ClusterApplierService.callClusterStateAppliers(ClusterApplierService.java:504)
at org.elasticsearch.cluster.service.ClusterApplierService.callClusterStateAppliers(ClusterApplierService.java:494)
at org.elasticsearch.cluster.service.ClusterApplierService.applyChanges(ClusterApplierService.java:471)
at org.elasticsearch.cluster.service.ClusterApplierService.runTask(ClusterApplierService.java:418)
at org.elasticsearch.cluster.service.ClusterApplierService$UpdateTask.run(ClusterApplierService.java:162)
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:674)
at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.runAndClean(PrioritizedEsThreadPoolExecutor.java:252)
at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.run(PrioritizedEsThreadPoolExecutor.java:215)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1130)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630)
at java.lang.Thread.run(Thread.java:832)
Caused by: [packetbeat-7.9.2-2020.10.22-000001/RRAnRZrrRZiihscJ3bymig][[packetbeat-7.9.2-2020.10.22-000001][6]] org.elasticsearch.env.ShardLockObtainFailedException: [packetbeat-7.9.2-2020.10.22-000001][6]: obtaining shard lock for [starting shard] timed out after [5000ms], lock already held for [closing shard] with age [199852ms]
at org.elasticsearch.env.NodeEnvironment$InternalShardLock.acquire(NodeEnvironment.java:869)
at org.elasticsearch.env.NodeEnvironment.shardLock(NodeEnvironment.java:775)
at org.elasticsearch.index.IndexService.createShard(IndexService.java:409)
... 16 more
], allocation_status[deciders_no]]]"""
}
]
},
{
"node_id" : "hHHRtd5HTCKJgLTBtgDbOw",
"node_name" : "VSELK-MASTER-01",
"transport_address" : "10.13.81.11:9300",
"node_attributes" : {
"ml.machine_memory" : "8365068288",
"xpack.installed" : "true",
"data" : "hot",
"transform.node" : "true",
"ml.max_open_jobs" : "20"
},
"node_decision" : "no",
"store" : {
"in_sync" : true,
"allocation_id" : "ByqJGtQSQT-p8dCCfk3VlA"
},
"deciders" : [
{
"decider" : "max_retry",
"decision" : "NO",
"explanation" : """shard has exceeded the maximum number of retries [5] on failed allocation attempts - manually call [/_cluster/reroute?retry_failed=true] to retry, [unassigned_info[[reason=ALLOCATION_FAILED], at[2020-10-28T13:22:03.006Z], failed_attempts[5], failed_nodes[[hHHRtd5HTCKJgLTBtgDbOw, RCeMt0uXQie_ax_Sp22hLw]], delayed=false, details[failed shard on node [RCeMt0uXQie_ax_Sp22hLw]: failed to create shard, failure java.io.IOException: failed to obtain in-memory shard lock
at org.elasticsearch.index.IndexService.createShard(IndexService.java:489)
at org.elasticsearch.indices.IndicesService.createShard(IndicesService.java:763)
at org.elasticsearch.indices.IndicesService.createShard(IndicesService.java:176)
at org.elasticsearch.indices.cluster.IndicesClusterStateService.createShard(IndicesClusterStateService.java:607)
at org.elasticsearch.indices.cluster.IndicesClusterStateService.createOrUpdateShards(IndicesClusterStateService.java:584)
at org.elasticsearch.indices.cluster.IndicesClusterStateService.applyClusterState(IndicesClusterStateService.java:242)
at org.elasticsearch.cluster.service.ClusterApplierService.callClusterStateAppliers(ClusterApplierService.java:504)
at org.elasticsearch.cluster.service.ClusterApplierService.callClusterStateAppliers(ClusterApplierService.java:494)
at org.elasticsearch.cluster.service.ClusterApplierService.applyChanges(ClusterApplierService.java:471)
at org.elasticsearch.cluster.service.ClusterApplierService.runTask(ClusterApplierService.java:418)
at org.elasticsearch.cluster.service.ClusterApplierService$UpdateTask.run(ClusterApplierService.java:162)
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:674)
at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.runAndClean(PrioritizedEsThreadPoolExecutor.java:252)
at org.elasticsearch.common.util.concurrent.PrioritizedEsThreadPoolExecutor$TieBreakingPrioritizedRunnable.run(PrioritizedEsThreadPoolExecutor.java:215)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1130)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:630)
at java.lang.Thread.run(Thread.java:832)
Caused by: [packetbeat-7.9.2-2020.10.22-000001/RRAnRZrrRZiihscJ3bymig][[packetbeat-7.9.2-2020.10.22-000001][6]] org.elasticsearch.env.ShardLockObtainFailedException: [packetbeat-7.9.2-2020.10.22-000001][6]: obtaining shard lock for [starting shard] timed out after [5000ms], lock already held for [closing shard] with age [199852ms]
at org.elasticsearch.env.NodeEnvironment$InternalShardLock.acquire(NodeEnvironment.java:869)
at org.elasticsearch.env.NodeEnvironment.shardLock(NodeEnvironment.java:775)
at org.elasticsearch.index.IndexService.createShard(IndexService.java:409)
... 16 more
], allocation_status[deciders_no]]]"""
}
]
},
{
"node_id" : "k_SgmMDMRfGi-IFLbI-cRw",
"node_name" : "VSELK-MASTER-02",
"transport_address" : "10.13.81.12:9300",
"node_attributes" : {
"ml.machine_memory" : "8365056000",
"ml.max_open_jobs" : "20",
"xpack.installed" : "true",
"data" : "hot",
"transform.node" : "true"
},
"node_decision" : "no",
"store" : {
"found" : false
}
},
{
"node_id" : "r4V_KqZDQ7mYi7AZea5eXQ",
"node_name" : "VSELK-DATA-01",
"transport_address" : "10.13.81.21:9300",
"node_attributes" : {
"ml.machine_memory" : "8365424640",
"ml.max_open_jobs" : "20",
"xpack.installed" : "true",
"data" : "warm",
"transform.node" : "true"
},
"node_decision" : "no",
"store" : {
"found" : false
}
}
]
}有人能告诉我这种错误的原因和解决方法吗?(知道我的集群中有5个节点,3个主节点和2个数据节点,并且它们都已经启动)。
谢谢你的帮助!
回答 1
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64604872
复制相关文章








点击加载更多
相似问题
dc.js重新选择已呈现的图表
dc.js -侦听图表组呈现
仅使用dc.js呈现特定图表
dc.js Vue呈现图表不正确
扩展dc.js以添加"simpleLineChart“图表
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
