
包含员工数据的If语句
提问于 2020-07-11 05:05:59
我有一个数据set.Which包含关于company.You中雇员的数据,可以看到下面的数据:
#Data
output_test<-data.frame(
Employees=c(1,2,3,10,15,122,143,150,250,300,500,1000)
)所以下一个陡峭的应该是分类。我需要按company.Rule的大小对员工进行分类,如果员工的数量低于10,即“微型”公司,如果人数大于10,但低于或等于50公司,则为“小”company.For“中型”公司,员工人数大于50但等于或小于250,最后是员工大于250的“大型”公司。为了做到这一点,我写了这行代码,如果其他状态
# Code
library(dplyr)
output_test_final<-output_test%>%
mutate(
Size= if(Employees>=10){
"Micro"
} else {
if(Employees>=50){
"Small"
} else {
if(Employees>=250){
"Medium"
} else {
"Large"
}
}
}
)因此,这段代码的结果不是good.So,有人能帮我修复这段代码并像下面的表格那样得到表吗?
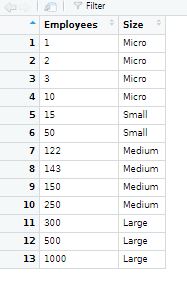

回答 3
Stack Overflow用户
回答已采纳
发布于 2020-07-11 05:12:01
if用于标量输入,您可以在这里使用ifelse,它可以用于向量或更好的case_when。还请注意,您的条件需要被扭转。
library(dplyr)
output_test %>%
mutate(Size = case_when(Employees <= 10 ~ "Micro",
Employees <= 50 ~ "Small",
Employees <= 250 ~ "Medium",
TRUE ~ "Large"))
# Employees Size
#1 1 Micro
#2 2 Micro
#3 3 Micro
#4 10 Micro
#5 15 Small
#6 122 Medium
#7 143 Medium
#8 150 Medium
#9 250 Medium
#10 300 Large
#11 500 Large
#12 1000 Large另一种选择是使用cut指定breaks和labels。
cut(output_test$Employees, breaks = c(-Inf, 10, 50, 250, Inf),
labels = c('Micro', 'Small', 'Medium', 'Large'))Stack Overflow用户
发布于 2020-07-11 05:11:49
试试这个:
library(dplyr)
output_test_final<-output_test%>%
mutate(
Size= if(Employees<=10){
"Micro"
} else {
if(Employees>=11 && Employees<=50){
"Small"
} else {
if(Employees>=51 && Employees<=250){
"Medium"
} else {
"Large"
}
}
}
)Stack Overflow用户
发布于 2020-07-11 10:21:05
我们可以使用ifelse
library(dplyr)
output_test %>%
mutate(Size = ifelse(Employees <= 10, "Micro",
ifelse(Employees <= 50, "Small",
ifelse(Employees <= 250, "Medium",
"Large"))))或在base R中使用findInterval
c('Micro', 'Small', 'Medium', 'Large')[findInterval(output_test$Employees, c(10, 50, 250)) + 1]
#[1] "Micro" "Micro" "Micro" "Small" "Small" "Medium" "Medium" "Medium" "Large" "Large" "Large" "Large" 页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/62849531
复制相关文章














腾讯云开发者
