在PyTorch中寻找具有反向传播和梯度下降的参数
在PyTorch中寻找具有反向传播和梯度下降的参数
提问于 2020-01-13 21:20:46
我正在试验PyTorch,自我分化和梯度下降。
为此,我要估计参数,这些参数将产生参数函数中任意线性的某个值。
我的密码在这里:
import torch
X = X.astype(float)
X = np.array([[3.], [4.], [5.]])
X = torch.from_numpy(X)
X.requires_grad = True
W = np.random.randn(3,3)
W = np.triu(W, k=0)
W = torch.from_numpy(W)
W.requires_grad = True
out = 10 - (X@torch.transpose(X, 1,0) * W).sum()out是:

我的目标是通过使用out的梯度来调整W,使W接近0(在[-.00001 , 0.0001]的间隔内)。
从这里开始,我该如何用火把来达到这个目的呢?
更新
@Umang:当我运行您建议的代码时,这就是我得到的结果:
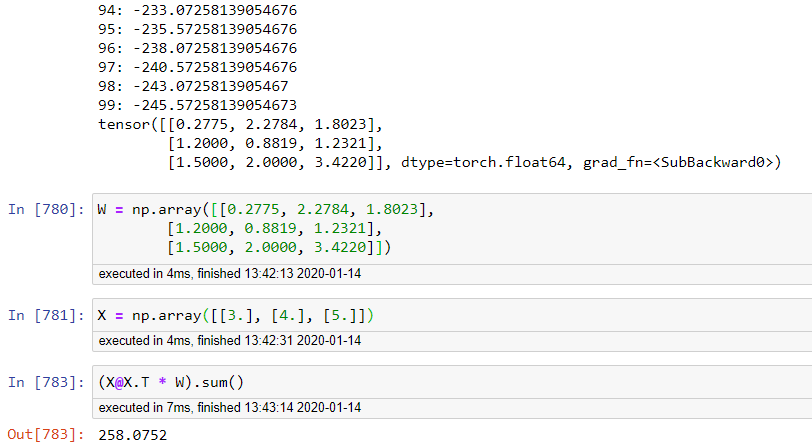
事实上,算法是有分歧的。
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-01-14 01:18:00
# your code as it is
import torch
import numpy as np
X = np.array([[3.], [4.], [5.]])
X = torch.from_numpy(X)
X.requires_grad = True
W = np.random.randn(3,3)
W = np.triu(W, k=0)
W = torch.from_numpy(W)
W.requires_grad = True
# define parameters for gradient descent
max_iter=100
lr_rate = 1e-3
# we will do gradient descent for max_iter iteration, or convergence till the criteria is met.
i=0
out = compute_out(X,W)
while (i<max_iter) and (torch.abs(out)>0.01):
loss = (out-0)**2
W = W - lr_rate*torch.autograd.grad(loss, W)[0]
i+=1
print(f"{i}: {out}")
out = compute_out(X,W)
print(W)我们定义了一个损失函数,使得它的最小值在期望的点上,并运行梯度下降。在这里,我使用了平方误差,但您也可以使用其他损失函数与期望的最小。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/59727904
复制相关文章


![php对‘[{“id“:“1“,“name“:“cyg”},{“id“:“2“,“name“:“liwen“}]json数据进行修改删除操作](https://ask.qcloudimg.com/http-save/yehe-7873631/aa2103fe768ee32808222fe9105d00f7.png)


点击加载更多
相似问题
JSON PHP服务器已修改
用PHP修改JSON数据
修改PHP代码以返回JSON值
修改已返回的对象
修改php laravel中的json数据
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
