正则表达式从纯文本中获取计算机规范
正则表达式从纯文本中获取计算机规范
提问于 2014-01-14 13:20:03
我有一个数据集,其中包含纯文本、关于计算机的描述,它们看起来类似于以下内容:
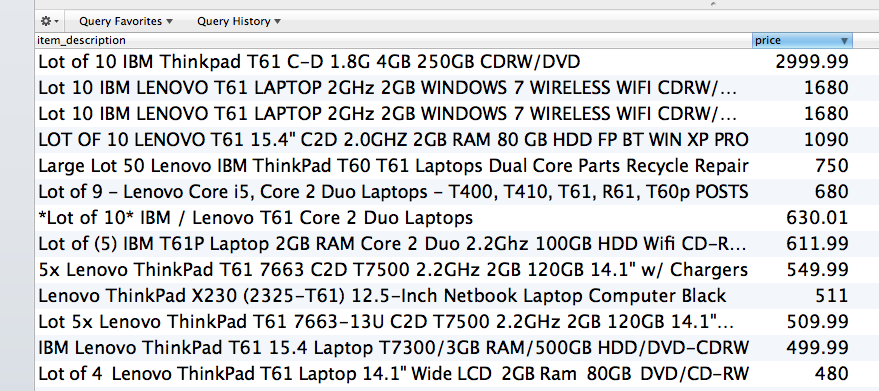
我试图根据文本预测价格,这是我的方法。由于我知道它们都是计算机,我将尝试使用正则表达式来解析CPU频率、内存、磁盘容量和屏幕大小.等等,所以你会有一个有固定列数的矩阵.你可以运行规则算法来预测价格(随机森林,线性回归.)。
然而,我仍然坚持正则表达式部分解析列:假设我试图从文本中解析频率,我想这将是一个数字,后面跟着"GHz“。
>>> re.findall(re.compile('([.\d]+) GHz'), '2.2 GHz 32 GB')
['2.2']这是好的,然而,它的结果是正则表达式不是那么好。下面是我的正则表达式失败的几个条件:
>>> re.findall(re.compile('([.\d]+) GHz'), '2.2 ghz 32 GB')
[]
>>> re.findall(re.compile('([.\d]+) GHz'), '2.2 Ghz 32 GB')
[]
>>> re.findall(re.compile('([.\d]+) GHz'), '2.2GHz 32 GB')
[]我不太擅长正则表达式,我想知道谁能告诉我怎么找到后面跟着"ghz“或”gigaHerz“的号码。在数字和度量单元之间可能有一些空白。。
PS:我知道R,我认为这可能是一个非常普遍的统计问题,即“如何根据一袋袋单词进行预测”。如果有人能给我指点更好的方法,我会非常感激的!
回答 5
Stack Overflow用户
回答已采纳
发布于 2014-01-14 13:24:49
Stack Overflow用户
发布于 2014-01-14 13:47:36
正则表达式不适合处理凌乱的数据。类似于http://openrefine.org/的东西更适合这个任务。
但是,在RegExp中使用快速和肮脏的启发式方法可以很好地度量数据,如下所示:
re.findall(re.compile('([\.\d]+) ?g[^\W\d]*z', re.IGNORECASE), '2.2 gigahERTz 32 GB')Stack Overflow用户
发布于 2014-01-14 13:23:22
试试这个频率:
re.findall(re.compile('([\.\d]+) *[gG][hH][zZ]'), '2.2 GHz 32 GB')一些注释:“。”匹配一个实际的时间段。A‘'.’它本身与单个字符匹配。“*”匹配0或更多空格字符。gGzZ匹配字母'g‘、'h’和'z‘的任意组合,小写和大写。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/21124256
复制





相似问题
为什么+=不将变量的值相加?
为什么不将count作为全局值?(赋值前引用的局部变量'count‘)
为什么gets不将值存储在变量中?
JavaScript不将变量写入数字(循环)
不将值存储到变量
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
