用Python 3中的unicode字符串替换“\xe9 9”字符
在Python3.4.2中使用SublimeText 2.0.2,我得到一个带有urllib的网页:
response = urllib.request.urlopen(req)
pagehtml = response.read()打印=> qualit\xe9">\r\n\t\t<META HTTP
我在unicode字符串中得到一个“xe9 9”字符!
页面的标题告诉我它是用ISO8859-1 (Content-Type: text/html;charset=ISO-8859-1)编码的。但如果我用ISO-8859-1解码,然后用utf-8编码,只会变得更糟.
resultat = pagehtml.decode('ISO-8859-1').encode('utf-8')打印=> qualit\xc3\xa9">\r\n\t\t<META HTTP
我怎么才能取代所有的“\xe9 9”..。字母对应的字符(“é”.)
编辑1
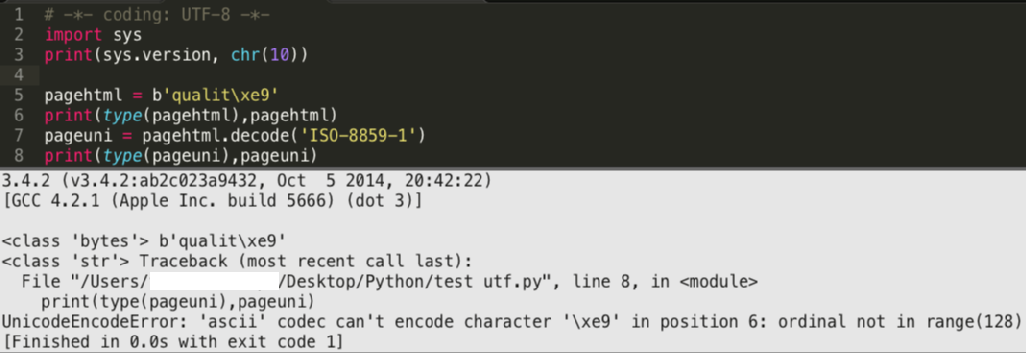
我得到了一个UnicodeEncodeError (这就是为什么我要在‘utf-8’中编码)!
--我应该提到--我正在SublimeText 2.0.2中运行代码。这似乎是我的问题。
编辑2
它在空闲(Python3.4.2)和OSX终端(Python2.5)中工作得很好,但是在SublimeText 2.0.2 (使用Python3.4.2)中不能工作。=>似乎是SublimeText控制台(输出窗口)的问题,而不是我的代码。
我要看看PYTHONIOENCODING env,就像J.F.塞巴斯蒂安建议的那样,看起来我应该能够在sublime-build file中设置它。
编辑3-解决方案
我刚在"env": {"PYTHONIOENCODING": "UTF-8"}中添加了sublime-build file。
好了。谢谢大家;)
回答 3
Stack Overflow用户
发布于 2014-10-22 01:48:37
我得到了一个UnicodeEncodeError (这就是为什么我要在‘utf-8’中编码)!我应该提到我正在SublimeText中运行我的代码。这似乎是我的问题。有解决办法吗?
不要手动编码,而是打印unicode字符串。
适用于Unix
如果输出被重定向,或者没有配置语言(语言、LC_ALL、LC_CTYPE、LANG),则设置LC_ALL(默认为C (ascii))。
Windows操作系统
如果可以使用控制台代码页表示内容,那么设置PYTHONIOENCODING=your_console_cp envvar,例如,PYTHONIOENCODING=cp1252 (只有当它确实是控制台使用的编码时,才将其设置为cp1252,运行chcp检查)。或者使用任何编码SublimeText可以正确显示,如果它没有打开控制台窗口来运行Python。
除非输出被重定向;如果直接从命令行运行脚本,则不需要设置PYTHONIOENCODING envvar。
否则(若要支持无法在控制台编码中表示的字符),请安装 package,使用python3 -mrun your_script.py运行脚本或将其放在脚本的顶部:
import win_unicode_console
win_unicode_console.enable()它使用Win32 API (如WriteConsoleW() )将其打印到控制台。您仍然需要配置正确的字体,以便在控制台中看到任意Unicode文本。
Stack Overflow用户
发布于 2014-10-21 18:33:50
响应是一个编码的字节字符串。只需破译:
>>> pagehtml = b'qualit\xe9'
>>> print(pagehtml)
b'qualit\xe9'
>>> print(pagehtml.decode('ISO-8859-1'))
qualitéStack Overflow用户
发布于 2014-10-21 18:47:51
我非常肯定,除了理解字节和unicode之外,您实际上并没有遇到问题。事情正在按部就班地进行。pagehtml是编码字节。(我在第一行中向req = 'http://python.org'确认了这一点。)当显示字节时,可以解释为可打印的ascii编码的字节被打印为这样,而其他字节则用十六进制转义符打印。b'\xe9'是é的单字节ISO-8859-1编码的十六进制转义编码,而b'\xc3\xa9'是其双字节utf-8编码的十六进制转义编码。
>>> b = b"qualit\xe9"
>>> u = b.decode('ISO-8859-1')
>>> u
'qualité'
>>> b2 = u.encode()
>>> b2
b'qualit\xc3\xa9'
>>> len(b) == 7 and len(b2) == 8
True
>>> b[6]
233
>>> b2[6], b2[7]
(195, 169)因此,pageuni = pagehtml.decode('ISO-8859-1')将页面作为unicode提供给您。这个解码完成了你要求的替换。
https://stackoverflow.com/questions/26497132
复制


![[Python基础06]函数的参数&返回值](https://ask.qcloudimg.com/http-save/yehe-4908043/f050b996b3d4b1b827277d16a40963c7.png)





相似问题
HashMap.values()和HashMap.keySet()如何返回值和键?
如何使用hashmap分配键和值?
根据数组中的值检查值,然后使用PHP返回键
输入的特定键的java hashmap返回键和值
HashMap键和值
领取专属 10元无门槛券
AI混元助手 在线答疑

洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
