Pandas DataFrame从另一个DataFrame中查找最常用的字符串
提问于 2021-02-19 21:25:44
我有合并所有名称的代码,并计算它们的统计数据,并统计它们出现的次数。我在其中添加了另一个专栏。如何从不同的数据帧中打印最常见的名称?在我的代码中,它的意思是,我想要找到最常见的汽车品牌。
我像这样抓取数据:
'Mercedes-Benz Klasa S', 4390.0, '(Dolnośląskie)']
['Mitsubishi Carisma 1.8', 3999.0, '(Pomorskie)']
['Audi A4 1.6', 4000.0, '(Łódzkie)'] for offer in all_offers:
# get the interesting data and write to file
title = offer.find('a', class_='offer-title__link').text.strip()
price = offer.find('span', class_='offer-price__number').text.strip().replace(' ', '').replace('\nPLN', '').replace('\nEUR', '')
location = offer.find('span', class_='ds-location-region').text.strip()
item = [title, float(price.replace(",", ".") ),location]
data.append(item)
print(item)for name in [
'Alfa Romeo','Aston Martin', 'Audi',']:
print('---', name,'pojemność od 2000cm3' '---')
cars = df[df['title'].str.contains(name)]
print('count:', len(cars))
print('price min :', cars['price'].min())
print('price average:', cars['price'].mean())
print('price max :', cars['price'].max())
cars.plot.hist(title=name)
plt.show()和voivodships
for voivodships in ['('(Śląskie)', '(Świętokrzyskie)', '(Warmińsko-mazurskie)', '(Wielkopolskie)','(Zachodniopomorskie)']:
locations= df[df['location'].str.contains(voivodships)]
print('---', voivodships, '---')
print('ilość ogłoszeń w :', len(voivodships))回答 1
Stack Overflow用户
发布于 2021-02-19 22:04:49
我认为你不需要循环,而且你可能不应该使用它们。
这里有一个仅使用熊猫的解决方案。我对你的数据集做了一点扩展。
df = pd.DataFrame.from_records([
['Mercedes-Benz Klasa S', 4390.0, '(Dolnośląskie)'],
['Mitsubishi Carisma 1.8', 3999.0, '(Pomorskie)'],
['Audi A4 1.6', 5790.0, '(Łódzkie)'],
['Mercedes-Benz Klasa S', 2390.0, '(Dolnośląskie)'],
['Mitsubishi Carisma 1.8', 3999.0, '(Dolnośląskie)'],
['Audi A6 2.0', 7000.0, '(Łódzkie)'],
['Mercedes-Benz Klasa S', 5390.0, '(Łódzkie)'],
['Audi A3 1.6', 4000.0, '(Dolnośląskie)'],
], columns=['make_model', 'price', 'region'])
df.region = df.region.str.slice(1,-1)
df['make'] = df.make_model.str.split(' ').str[0]
df.pivot_table(
index=['region', 'make'],
aggfunc={'price':['mean', 'min', 'max'], 'make':'count'}
)有关详细说明,请参阅内联注释。结果:
count max mean min
region make
Dolnośląskie Audi 1 4000.0 4000.0 4000.0
Mercedes-Benz 2 4390.0 3390.0 2390.0
Mitsubishi 1 3999.0 3999.0 3999.0
Pomorskie Mitsubishi 1 3999.0 3999.0 3999.0
Łódzkie Audi 2 7000.0 6395.0 5790.0
Mercedes-Benz 1 5390.0 5390.0 5390.0如果你只是想看看最频繁的make by region,这是可以做到的:
df.groupby('region')['make'].agg([
lambda x: x.value_counts().index[0],
lambda x: x.value_counts().values[0]
])在这里,您按区域分组,然后在此组中,计算take的值,并取第一个,也是最频繁的一个。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/66285197
复制相关文章

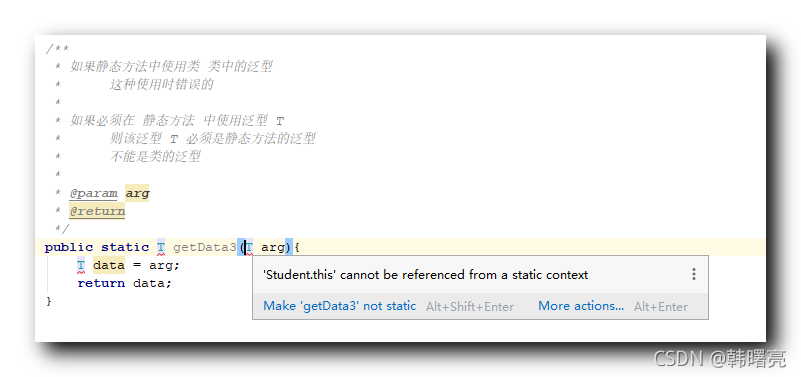





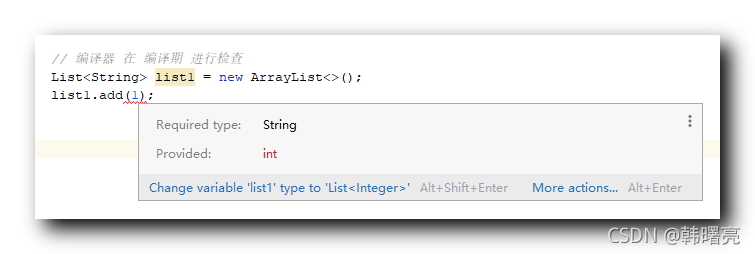
【Kotlin】泛型总结 ★ ( 泛型类 | 泛型参数 | 泛型函数 | 多泛型参数 | 泛型类型约束 | 可变参数结合泛型 | out 协变 | in 逆变 | reified 检查泛型参数类型 )



相似问题
如何使方法返回泛型类型?
使方法返回类型为泛型
如何使方法的返回类型成为泛型?
泛型方法返回泛型类型
如何使方法返回泛型方法?
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
