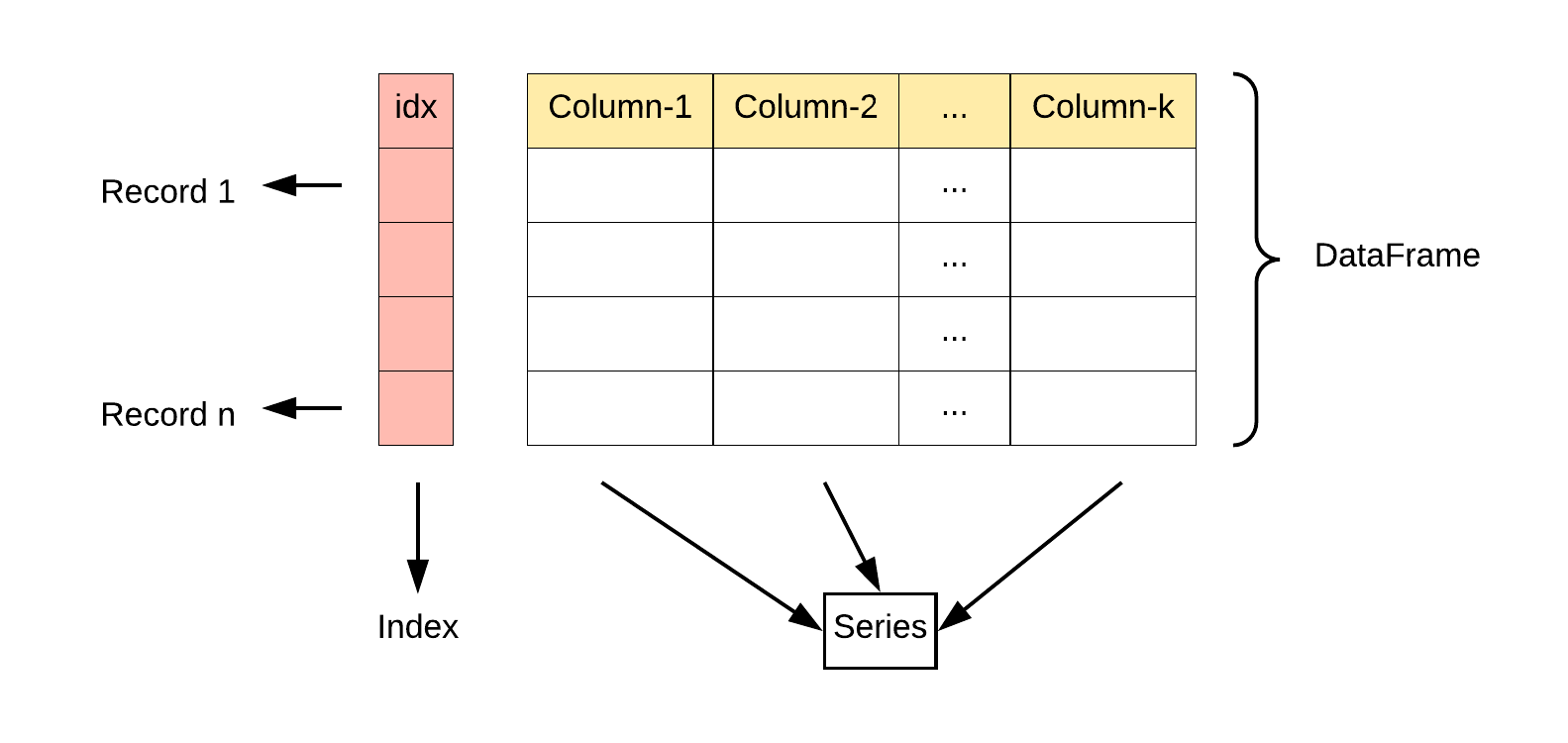
将计数器列表转换为稀疏Pandas DataFrame
将计数器列表转换为稀疏Pandas DataFrame
提问于 2019-10-30 00:30:25
我在构建一个带有稀疏数据类型的熊猫DataFrame时遇到了麻烦。我的输入是一堆存储为字典或计数器的特征向量。对于像文本的词袋表示这样的稀疏数据,将数据存储为密集的文档x术语矩阵通常是不合适和不可行的,并且对于保持数据结构的稀疏性是必要的。
例如,假设输入为:
docs = [{'hello': 1}, {'world': 1, '!': 2}]输出应等于:
import pandas as pd
out = pd.DataFrame(docs).astype(pd.SparseDtype(float))而不会在此过程中创建密集阵列。(我们可以检查out.dtypes和out.sparse.density。)
尝试1:
out = pd.DataFrame(dtype=pd.SparseDtype(float))
out.loc[0, 'hello'] = 1
out.loc[1, 'world'] = 1
out.loc[1, '!'] = 2但这会产生密集的数据结构。
尝试2:
out = pd.DataFrame({"hello": pd.SparseArray([]),
"world": pd.SparseArray([]),
"!": pd.SparseArray([])})
out.loc[0, 'hello'] = 1但这会引起TypeError: SparseArray does not support item assignment via setitem的注意。
我最终在下面找到的解决方案在我尝试过的Pandas的早期版本中不起作用。
回答 1
Stack Overflow用户
发布于 2019-10-30 00:30:25
这似乎适用于Pandas 0.25.1:
out = pd.DataFrame([[0, 'hello', 1], [1, 'world', 1], [1, '!', 2]],
columns=['docid', 'word', 'n'])
out = out.set_index(['docid', 'word'])['n'].astype(pd.SparseDtype(float))
out = out.unstack()或者更一般地说:
def dicts_to_sparse_dataframe(docs):
rows = ((i, k, v)
for i, doc in enumerate(docs)
for k, v in doc.items())
out = pd.DataFrame(rows, columns=['docid', 'word', 'n'])
out = out.set_index(['docid', 'word'])['n'].astype(pd.SparseDtype(float))
out = out.unstack()
return out然后:
>>> docs = [{'hello': 1}, {'world': 1, '!': 2}]
>>> df = dicts_to_sparse_dataframe(docs)
>>> df.sparse.density
0.5我希望这不会在整个过程中创建密集的内存结构……
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/58617185
复制相关文章





点击加载更多
相似问题
将Pandas DataFrame转换为稀疏矩阵
将Pandas DataFrame转换为列表
将列表转换为pandas DataFrame
将列表转换为dataframe pandas
将pandas DataFrame转换为列表列表
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者
