【ICML2021】随机森林机器遗忘



来源:专知
本文约1000字,建议阅读5分钟 在本文中,我们引入了数据移除(DaRE)森林,这是随机森林的一种变体,可以在最少的再训练的情况下删除训练数据。
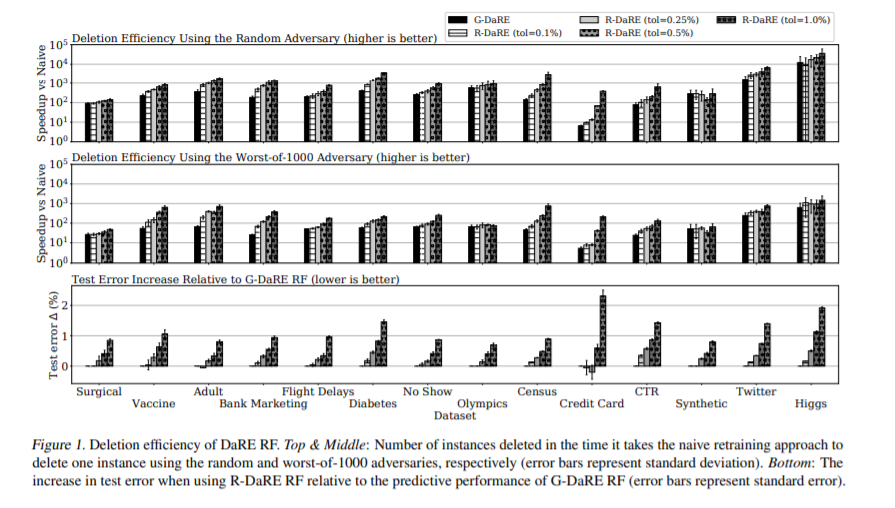
考虑到用户数据删除请求、删除噪声的示例或删除损坏的训练数据,这只是希望从机器学习(ML)模型中删除实例的几个原因。然而,从ML模型中有效地删除这些数据通常是困难的。在本文中,我们引入了数据移除(DaRE)森林,这是随机森林的一种变体,可以在最少的再训练的情况下删除训练数据。森林中每棵DaRE树的模型更新都是精确的,这意味着从DaRE模型中删除实例产生的模型与对更新后的数据进行从头再训练完全相同。
DaRE树利用随机性和缓存来高效删除数据。DaRE树的上层使用随机节点,它均匀随机地选择分割属性和阈值。这些节点很少需要更新,因为它们对数据的依赖性很小。在较低的层次上,选择分割是为了贪婪地优化分割标准,如基尼指数或互信息。DaRE树在每个节点上缓存统计信息,在每个叶子上缓存训练数据,这样当数据被删除时,只更新必要的子树。对于数值属性,贪婪节点在阈值的随机子集上进行优化,以便在逼近最优阈值的同时保持统计量。通过调整贪婪节点的阈值数量和随机节点的数量,DaRE树可以在更准确的预测和更有效的更新之间进行权衡。
在13个真实数据集和一个合成数据集上的实验中,我们发现DaRE森林删除数据的速度比从头开始训练的速度快几个数量级,同时几乎不牺牲预测能力。
https://icml.cc/Conferences/2021/Schedule?showEvent=10523
编辑:文婧

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2021-08-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号