SIGGRAPH 2023 | Attend-and-Excite:基于注意力的文生图扩散模型语义指导

SIGGRAPH 2023 | Attend-and-Excite:基于注意力的文生图扩散模型语义指导

用户1324186
发布于 2023-10-09 13:55:22
发布于 2023-10-09 13:55:22
来源:SIGGRAPH 2023 项目地址:https://github.com/yuval-alaluf/Attend-and-Excite 作者:Hila Chefer, Yuval Alaluf 等 内容整理:王寒 最近文生图模型达到了一种前所未有的图片生成创造力。但是现在的SOTA扩散模型对文字描述的还原仍然不完美。经过对公开的稳定扩散模型的分析,认为它有严重的物体忽视问题。此外,发现模型还存在不能将表述和物体对应的问题。为了帮助减轻以上问题,本文提出了语义生成辅助Generative Semantic Nursing (GSN)的概念,在推理阶段干预生成过程来改善问题。将本文的方法与其他方法进行比较,证明它在一系列文本提示中更忠实地传达了所需的概念。
简介

图1 文生图实例
针对现有的扩散模型在文生图过程中会忽视promp中的一些物体(在多物体的情况下),或者对一些描述缺少约束(对某个物体的描述可能会错误分配到其他物体上)的问题,本文使用一个基于注意力的GSN,称之为Attend-and-Excite,引导模型细化交叉注意力单元,以关注文本提示中的所有主题并加强(或激发)它们的激活,从而鼓励模型生成文本提示中描述的所有主题。
基于交叉注意力的文字条件
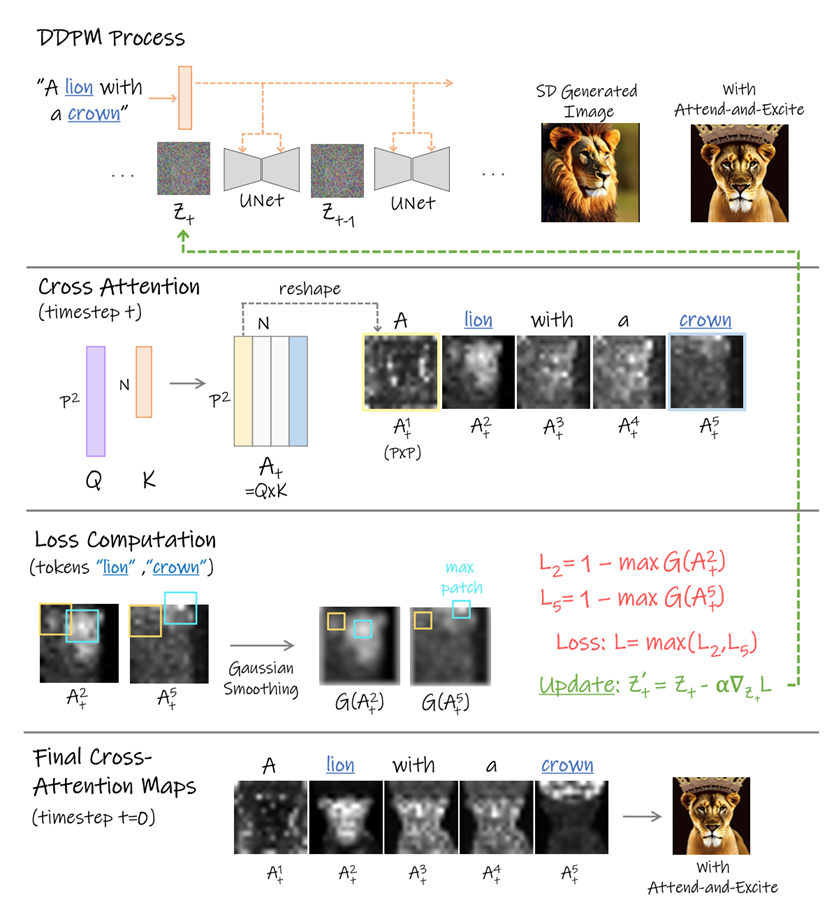
图2 算法示意图
如上图所示,文字信息输入后会计算一个注意力图(attention map),记为
,其中N是文字token的数量,P是空间维度大小,Feature作为Q,text prompt作为K。
表征了每个patch在当前token下的分布,即反映了当前token能提供给这个patch的信息量,其最大值是1。
Generative Semantic Nursing (GSN)
GSN机制是本文的核心,在每一步的更新过程中都生成更加忠于prompt的结果。为了让prompt中的物体呈现在生成的图片中,这个prompt对应的特征图应该对某些patch有很大的影响。
本文设计了一个loss,在更新的时候最大化物体prompt对应的注意力值。因为是在推理过程中更新,此方法无需额外的训练。其算法流程如下图所示。

图3 算法流程
Extracting the Cross-Attention Maps.
首先要计算每一个token对应的feature map,以此来反映该token对图片中每个patch的影响。Step1就是正常的经过 SD 的 Unet 获得
SD对起始 token分配了较高的注意力值,Step2消除了起始点的高权重,并且对其他token加入了softmax Softmax之后的特征图就代表了相应点位与text prompt的对应关系,可以理解为关联的紧密程度
Obtaining Smooth Attention Maps.
经过上述操作之后并不能保证生成的图像里有想要的物体,因为局部高的相关度可能是生成了不完整的物体 为了避免这种情况,在step5 中加入了高斯滤波,这一操作过后每个 patch 与 token 的相关度将受到周边 patch 的影响、
Performing On the Fly Optimization.
优化器鼓励每个 token有至少一个对应的高注意力的patch,所以使用了
Step8 的目的在于加强当前时间t中最被忽视的物体
Step9 将这种加强应用到下一步中 限制在 timestep 在 25-50 之间使用 使用这一更新方式,因为最后的步骤不会更新物体位置信息
如果某个token的注意力值在比较靠前的timestep处很小,那很可能不能生成相应物体,因此,这篇文章设计了一个迭代更新,让所有token的注意力值达到某个大小后再更新
。
实验结果
下图展示了不同模型在多物体提示词条件下生成的图片,Composable Diffusion 生成的是prompt所有词汇的混合物。Structure Diffusion 和Stable Diffusion很像,都不能准确将描述词汇对应到相应的物体上。虽然Attend-and-Excite只针对忽视物体做了优化,但同时也解决了描述分配混乱的问题。

图4
下面的图表是三类prompt下生成的图片与文字描述的CLIP相似度,Attend-and-Excite无论是整体还是物体的相似度都优于其他三种。
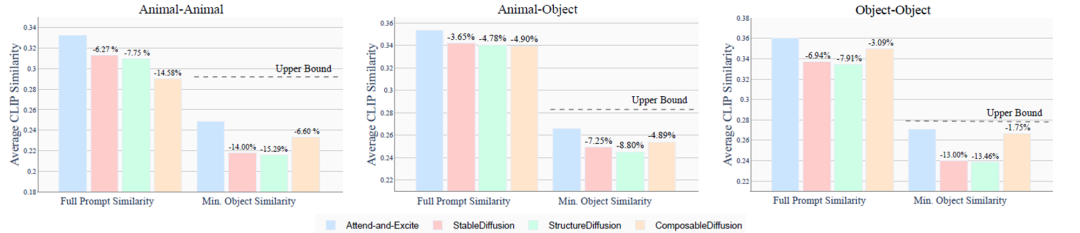
图5
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-10-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号