带有依从性预测区间的时间序列预测



在进行时间序列预测任务时,我们通常会开发产生未来观测点的点估计的解决方案。这是正确的,如果经过适当验证,它们可能对业务结果产生积极影响。有没有可能做得更好?通过简单添加更多信息,我们能够提供更详细的预测吗?
丰富我们的预测以包含预测区间是关键。从实际角度来看,预测区间由一对数字表示。这些值分别是未来观测可能出现的下限和上限,未来值落入给定区间的可能性由介于0和1之间的浮点数(α)表示。α接近1表示我们更有信心这种情况会发生。
附加预测区间的附加价值很容易理解。提供不确定性估计是一个早期的需求,可以通过各种方式解决。如果正确采用,所有方法都很棒,但有些方法更好。让我们尝试深入了解。
每个人都知道自举法作为一种重采样技术。通常看到将自举法应用于预测残差,以获得未来预测的不确定性度量。尽管残差自举法可能是初次接触不确定性量化时的一个很好的起点,但它可能导致性能不佳,因为它只考虑了数据不确定性。还存在另一种不确定性的来源,我们指的是建模不确定性。建模不确定性关注在x训练阶段遇到的可能知识不足,可能会影响到预测。良好的预测不确定性度量应该包括数据和建模不确定性。
在本文中,我们介绍了一种用于估算不确定性的技术,即依从性预测。
具体来说,我们演示了如何在时间序列预测场景中生成预测区间。使用tspiral(一个用于使用scikit-learn估算器进行时间序列预测的Python包)以及MAPIE(一个用于估算预测区间的与scikit-learn兼容的模块),我们展示了如何解决时间预测任务,提供准确的不确定性估计,而不离开scikit-learn生态系统。
设置预测
生成预测区间的第一步是选择要使用的预测模型。这似乎不合理,但这是依从性预测的主要优点之一,因为它是一种模型无关的技术(即它可以在任何上下文中与任何预测算法一起使用)。
在本文中,我们关注机器学习生态系统中采用的两种最著名的预测技术。我们指的是递归预测和直接预测。它们都是已知的方法,具有适当的优点和缺点,并且可以在scikit-learn格式中使用tspiral(要了解更多信息,建议阅读我的以前的一篇文章)。
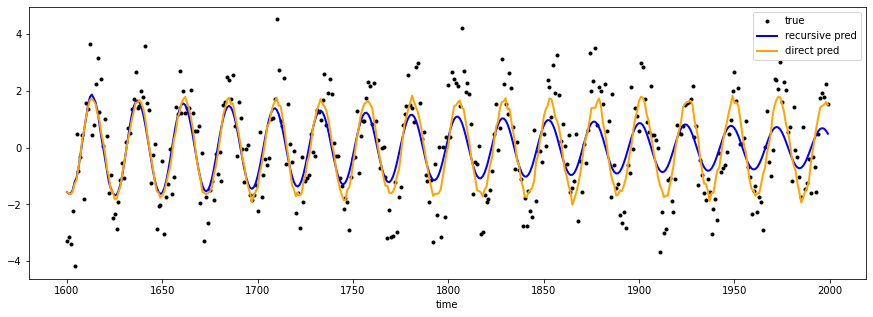
假设我们已经使用模拟的正弦系列生成了下面的预测。如何在我们的预测中添加可靠的预测区间呢?
生成依从性预测区间
为了解决这个问题,我们可以使用依从性预测。依从性预测区间是通过研究残差的分布来构建的。
alpha = 0.95
conformity_scores = np.abs(np.subtract(y_val, y_pred_val))
estimated_distributions = np.add(y_pred_test[:, None], conformity_scores)
lower_q, upper_q = np.quantile(
estimated_distributions,
[(1-alpha)/2, 1-(1-alpha)/2], axis=1
)
给定验证集上的预测和真实值,我们必须:
- 计算绝对残差(conformity_scores)。
- 将一致性得分添加到测试预测中。这会为每个逐点测试预测生成分布(estimated_distributions)。
- 计算每个逐点预测分布的上限和下限分位数,以获得预测区间。
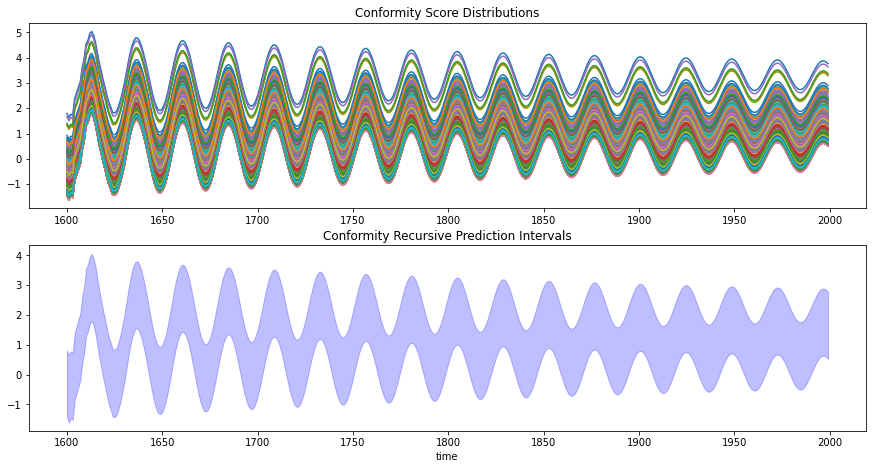
尽管这种方法很简单,但可以使用MAPIE自动化计算依从性预测区间。让我们看看它在递归和直接预测中的实际应用。
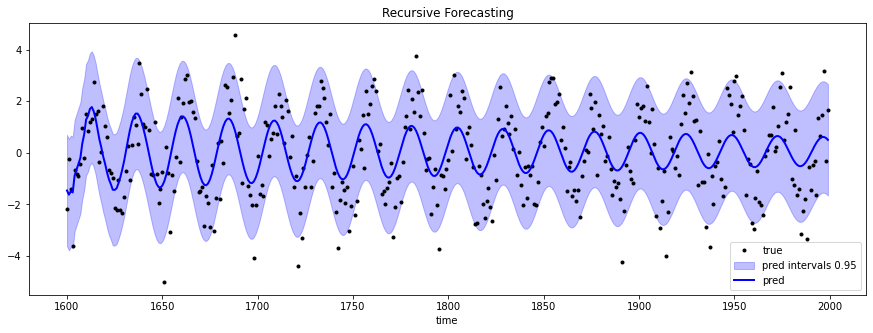
递归预测加上依从性预测区间
forecaster = ForecastingCascade(
Ridge(),
lags=range(1,24+1),
use_exog=False,
)
forecaster.fit(None, y_train)
model = MapieRegressor(
forecaster, cv="prefit",
).fit(X_val, y_val)
forecaster.fit(None, y_train_val)
model.single_estimator_ = forecaster
forecasts = model.predict(X_test, alpha=0.05)
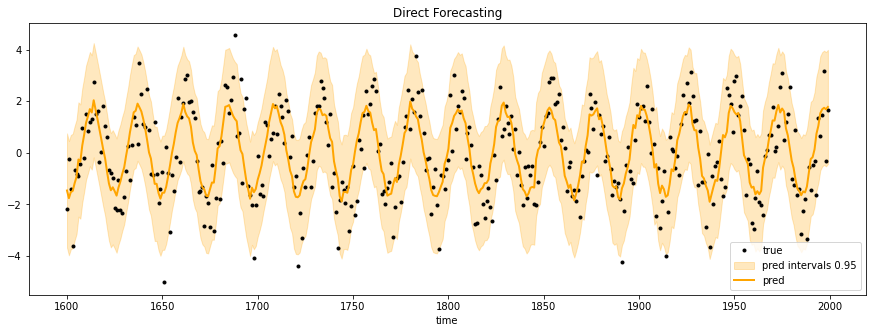
使用直接预测生成的依从性预测区间
forecaster = ForecastingChain(
Ridge(),
n_estimators=len(y_test),
lags=range(1,24+1),
use_exog=False,
)
forecaster.fit(None, y_train)
model = MapieRegressor(
forecaster, cv="prefit",
).fit(X_val, y_val)
forecaster.fit(None, y_train_val)
model.single_estimator_ = forecaster
forecasts = model.predict(X_test, alpha=0.05)
在这种简单形式下,MAPIE可以仅给定验证集和拟合模型(如上图所示)来估计预测区间。为了提供更强大的可靠性,可以使用交叉验证方法或更复杂的技术进行不确定性估计。
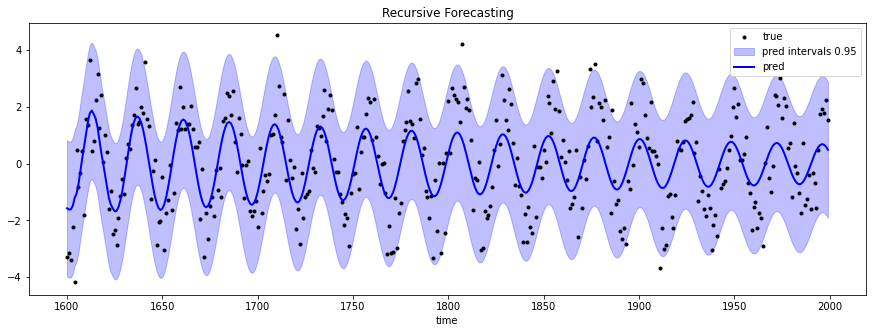
使用交叉验证生成的递归预测加上依从性预测区间
forecaster = ForecastingCascade(
Ridge(),
lags=range(1,24+1),
use_exog=False,
)
model = MapieRegressor(
forecaster,
cv=TemporalSplit(20, test_size=len(y_test)),
method='base', agg_function=None, n_jobs=-1,
).fit(X_train_val, y_train_val)
forecasts = model.predict(X_test, alpha=0.05, ensemble=False)
使用交叉验证生成的直接预测加上依从性预测区间。
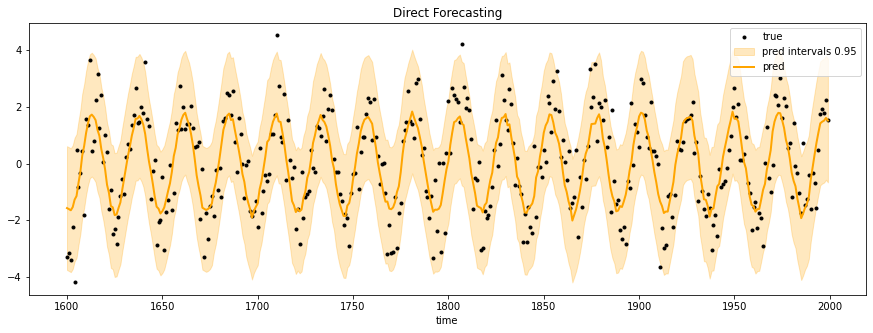
依从性预测生成可信的预测区间,因为经验证明,在估计过程中考虑了数据和建模的不确定性。其他方法显示出很好的响应来解开不确定性来源(我之前的一篇文章中报道了线性模型的示例)。然而,依从性预测的适应性以及通过MAPIE的可访问性使得这种技术在处理不确定性量化时成为必不可少的选择。
总结
在这篇文章中,我们发现了使用依从性预测估计预测区间的强大功能。我们专注于时间序列预测任务,以向我们的预测添加预测区间。通过在递归或直接预测生成的预测中添加可信赖的依从性预测区间是可能且简单的。借助tspiral和MAPIE的结合使用,我们可以通过简单使用scikit-learn完成时间序列预测和不确定性量化。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-04-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号