【源头活水】顶刊解读!Nature子刊 Machine Intelligence(IF 23.8)2024年第6卷第5期(2)
【源头活水】顶刊解读!Nature子刊 Machine Intelligence(IF 23.8)2024年第6卷第5期(2)

“问渠那得清如许,为有源头活水来”,通过前沿领域知识的学习,从其他研究领域得到启发,对研究问题的本质有更清晰的认识和理解,是自我提高的不竭源泉。为此,我们特别精选论文阅读笔记,开辟“源头活水”专栏,帮助你广泛而深入的阅读科研文献,敬请关注!
大语言模型(LLM)在化学领域的增强、能力涌现
1. M. Bran, A., Cox, S., Schilter, O. et al.
Augmenting large language models with chemistry tools.
Nat Mach Intell 6,525–535(2024).
https://doi.org/10.1038/s42256-024-00832-8
大语言模型(LLM)在化学领域的增强、能力涌现
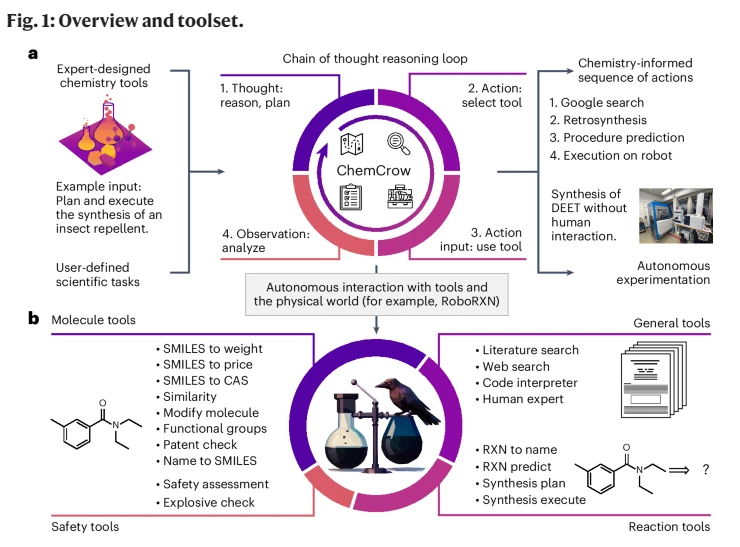
大型语言模型(LLMs)在各个领域的表现都非常出色,但在化学相关问题上却遇到了困难。这些模型还缺乏访问外部知识源的能力,限制了它们在科学应用中的实用性。我们介绍了ChemCrow,这是一个为完成有机合成、药物发现和材料设计任务而设计的化学大模型。通过整合18个专家设计的工貝并使用GPT-4作为LLM,ChemCrow增强了LLM在化学方面的表现,并出现了新的能力。我们的代理自主规划并执行了一种驱虫剂和三种有机催化剂的合成,并指导发现了一种新型的色团。我们的评估,包括LLM和专家评估,证明了ChemCrow在自动化多样化化学任务方面的有效性。我们的工作不仅帮助了化学领域专家并降低了非领域专家的障碍,而且还通过弥合实验化学和计算化学之间的差距,促进了科学的进步。

蛋白质序列设计、AlphaFold
2.Ren, M., Yu, C., Bu, D. et al.
Accurate and robust protein sequence design with CarbonDesign.
Nat Mach Intell 6, 536–547 (2024).
https://doi.org/10.1038/s42256-024-00838-2
蛋白质序列设计、AlphaFold
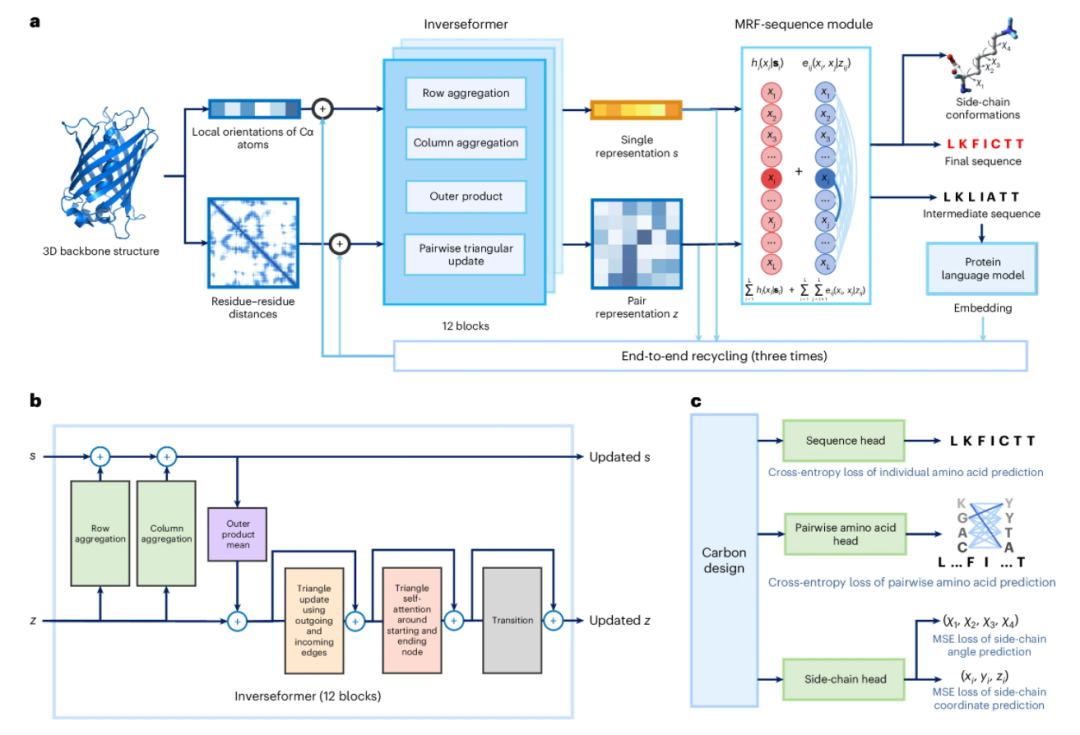
蛋白质序列设计对于蛋白质工程至关重要。尽管基于深度学习的方法取得了最新进展,但实现准确和稳健的序列设计仍然是一个挑战。在这里,我们介绍了CarbonDesign,这是一种从AlphaFold成功要素中获得灵感的方法,专门为蛋白质序列设计而开发。CarbonDesign的核心是引入了Inverseformer,它从骨架结构中学习表示,并使用摊销的马尔可夫随机场模型进行序列解码。此外,我们将其他AlphaFold的核心概念整合到CarbonDesign中:一种端到端的网络回收技术,利用蛋白质语言模型中的进化约束,以及一种多任务学习技术,用于生成侧链结构和设计的序列。CarbonDesign在独立测试集上的表现优于其他方法,包括第15届蛋白质结构预测的批判性评估(CASP15)数据集、连续自动模型评估(CAMEO)数据集以及RFDiffusion的从零设计蛋白质。此外,它支持零样本预测序列变体的功能效应,使其成为生物工程应用的有希望的工具。
专注于RNA的预训练模型
3.Wang, N., Bian, J., Li, Y. et al.
Multi-purpose RNA language modelling with motif-aware pretraining and type-guided fine-tuning.
Nat Mach Intell 6, 548–557 (2024).
https://doi.org/10.1038/s42256-024-00836-4
专注于RNA的预训练模型
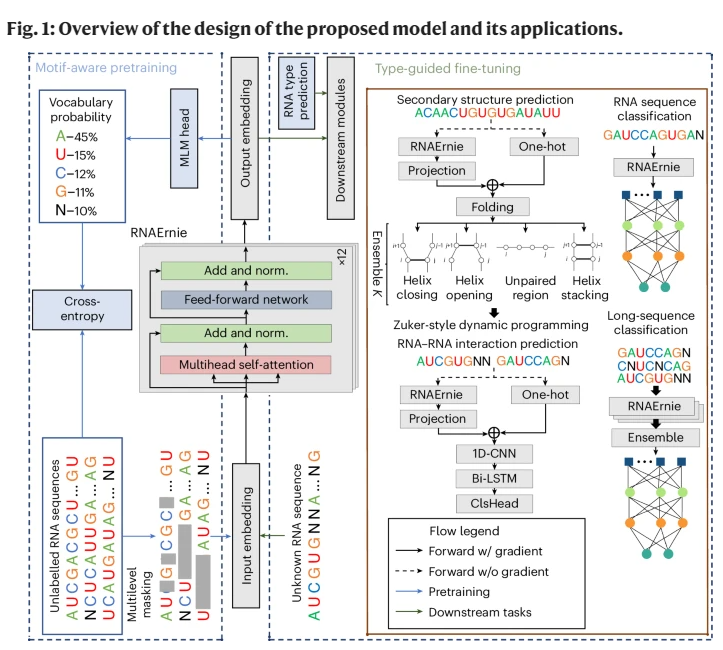
预训练语言模型在分析核苷酸序列方面显示出了潜力,然而,一个能够在单一预训练权重集上跨多个任务表现出色的通用模型仍然难以捉摸。在这里,我们介绍了RNAErnie,这是一个基于transformer架构构建的专注于RNA的预训练模型,并采用了两种简单但有效的策略。首先,RNAErnie通过将RNA基序作为生物学先验纳入预训练,并在基础/子序列级别的掩蔽语言建模之外引入基序级别的随机掩蔽,从而增强了预训练。它还将RNA类型(例如,miRNA,lnRNA)作为停用词进行标记,在预训练期间将其附加到序列上。其次,针对在预训练阶段未见过的RNA序列的分布外任务,RNAErnie提出了一种类型引导的微调策略,该策略首先使用RNA序列预测可能的RNA类型,然后将预测的类型附加到序列的尾部,以事后方式细化特征嵌入。我们在七个数据集和五个任务上的广泛评估证明了RNAErnie在监督学习和无监督学习中的优越性。它在分类上比基线高出1.8%的准确率,在相互作用预测上提高了2.2%的准确率,在结构预测中提高了3.3%的F1分数,展示了其在统一预训练基础上的鲁棒性和适应性。
分子体系平衡分布预测
4.Zheng, S., He, J., Liu, C. et al.
Predicting equilibrium distributions for molecular systems with deep learning.
Nat Mach Intell 6, 558–567 (2024).
https://doi.org/10.1038/s42256-024-00837-3
分子体系平衡分布预测
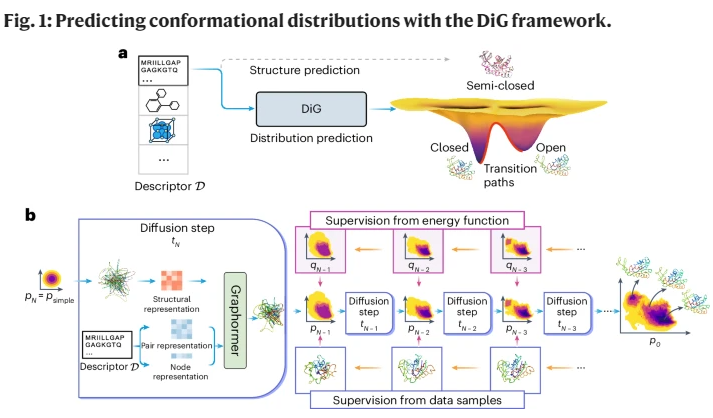
深度学习的进步极大地改善了分子结构预测。然而,许多对现实世界应用至关重要的宏观观察并不是单一分子结构的功能,而是从结构的平衡分布中确定的。获取这些分布的传统方法,如分子动力学模拟,计算成本高昂,通常难以处理。在这里,我们介绍了一个名为分布图变换器(Distributional Graphormer,简称DiG)的深度学习框架,旨在预测分子系统的平衡分布。DiG受到热力学中退火过程的启发,使用深度神经网络将简单分布转化为平衡分布,条件是分子系统的描述符,例如化学图或蛋白质序列。该框架能够高效地生成多样化的构象,并提供状态密度的估计,速度比传统方法快几个数量级。我们在几个分子任务上展示了DiG的应用,包括蛋白质构象采样、配体结构采样、催化剂-吸附物采样和属性引导的结构生成。DiG在统计理解分子系统的方法论上取得了重大进展,为分子科学领域的新研究机会铺平了道路。
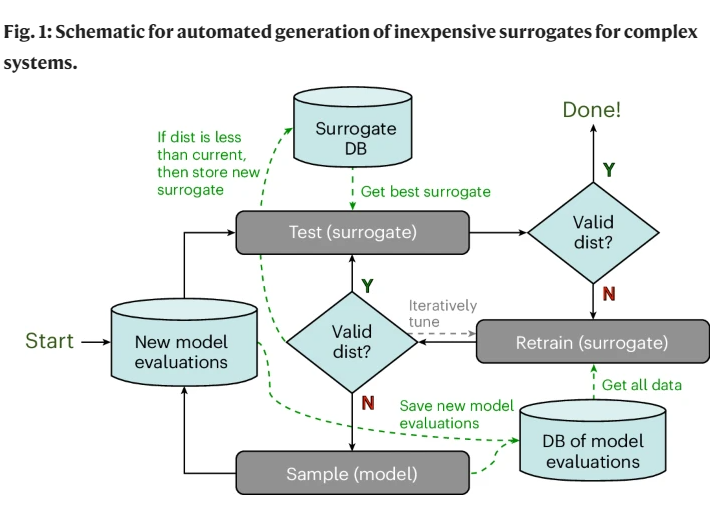
复杂物理系统、代理模型学习
5.Diaw, A., McKerns, M., Sagert, I. et al.
Efficient learning of accurate surrogates for simulations of complex systems.
Nat Mach Intell 6, 568–577 (2024).
https://doi.org/10.1038/s42256-024-00839-1
复杂物理系统、代理模型学习
机器学习方法正在越来越多地被部署来构建复杂物理系统的代理模型,以降低计算成本。然而,当存在噪声、稀疏或动态数据时,这些代理模型的预测能力会下降。我们引入了一种在线学习方法,该方法由优化器驱动的采样支持,它比现有方法有两个优势:它确保模型响应面的所有局部极值(包括端点)都被包含在训练数据中,并且它采用连续的验证和更新过程,当代理模型的性能低于有效性阈值时,会进行重新训练。我们通过使用基准函数发现,优化器指导的采样在局部极值附近的准确性方面通常优于传统采样方法,即使评分指标偏向于评估整体准确性。最后,将该方法应用于密集核物质,证明了可以可靠地从昂贵的计算中使用少量模型评估自动生成高度准确的核状态方程模型的代理。
腾讯云开发者
